
Chinese-LLaMA-Alpaca-2
中文LLaMA-2 & Alpaca-2大模型二期项目 + 64K超长上下文模型 (Chinese LLaMA-2 & Alpaca-2 LLMs with 64K long context models)
Stars: 6777

Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.
README:
🇨🇳中文 | 🌐English | 📖文档/Docs | ❓提问/Issues | 💬讨论/Discussions | ⚔️竞技场/Arena




本项目基于Meta发布的可商用大模型Llama-2开发,是中文LLaMA&Alpaca大模型的第二期项目,开源了中文LLaMA-2基座模型和Alpaca-2指令精调大模型。这些模型在原版Llama-2的基础上扩充并优化了中文词表,使用了大规模中文数据进行增量预训练,进一步提升了中文基础语义和指令理解能力,相比一代相关模型获得了显著性能提升。相关模型支持FlashAttention-2训练。标准版模型支持4K上下文长度,长上下文版模型支持16K、64k上下文长度。RLHF系列模型为标准版模型基础上进行人类偏好对齐精调,相比标准版模型在正确价值观体现方面获得了显著性能提升。
- 🚀 针对Llama-2模型扩充了新版中文词表,开源了中文LLaMA-2和Alpaca-2大模型
- 🚀 开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型
- 🚀 使用个人电脑的CPU/GPU快速在本地进行大模型量化和部署体验
- 🚀 支持🤗transformers, llama.cpp, text-generation-webui, LangChain, privateGPT, vLLM等LLaMA生态
- 基座模型(4K上下文):Chinese-LLaMA-2 (1.3B, 7B, 13B)
- 聊天模型(4K上下文):Chinese-Alpaca-2 (1.3B, 7B, 13B)
- 长上下文模型(16K/64K):
- Chinese-LLaMA-2-16K (7B, 13B) 、Chinese-Alpaca-2-16K (7B, 13B)
- Chinese-LLaMA-2-64K (7B)、Chinese-Alpaca-2-64K (7B)
- 偏好对齐模型:Chinese-Alpaca-2-RLHF (1.3B, 7B)

中文LLaMA&Alpaca大模型 | 多模态中文LLaMA&Alpaca大模型 | 多模态VLE | 中文MiniRBT | 中文LERT | 中英文PERT | 中文MacBERT | 中文ELECTRA | 中文XLNet | 中文BERT | 知识蒸馏工具TextBrewer | 模型裁剪工具TextPruner | 蒸馏裁剪一体化GRAIN
[2024/03/27] 本项目已入驻机器之心SOTA!模型平台,欢迎关注:https://sota.jiqizhixin.com/project/chinese-llama-alpaca-2
[2024/01/23] 添加新版GGUF模型(imatrix量化)、AWQ量化模型,支持vLLM下加载YaRN长上下文模型。详情查看📚 v4.1版本发布日志
[2023/12/29] 发布长上下文模型Chinese-LLaMA-2-7B-64K和Chinese-Alpaca-2-7B-64K,同时发布经过人类偏好对齐(RLHF)的Chinese-Alpaca-2-RLHF(1.3B/7B)。详情查看📚 v4.0版本发布日志
[2023/09/01] 发布长上下文模型Chinese-Alpaca-2-7B-16K和Chinese-Alpaca-2-13B-16K,该模型可直接应用于下游任务,例如privateGPT等。详情查看📚 v3.1版本发布日志
[2023/08/25] 发布长上下文模型Chinese-LLaMA-2-7B-16K和Chinese-LLaMA-2-13B-16K,支持16K上下文,并可通过NTK方法进一步扩展至24K+。详情查看📚 v3.0版本发布日志
[2023/08/14] 发布Chinese-LLaMA-2-13B和Chinese-Alpaca-2-13B,添加text-generation-webui/LangChain/privateGPT支持,添加CFG Sampling解码方法等。详情查看📚 v2.0版本发布日志
[2023/08/02] 添加FlashAttention-2训练支持,基于vLLM的推理加速支持,提供长回复系统提示语模板等。详情查看📚 v1.1版本发布日志
[2023/07/31] 正式发布Chinese-LLaMA-2-7B(基座模型),使用120G中文语料增量训练(与一代Plus系列相同);进一步通过5M条指令数据精调(相比一代略微增加),得到Chinese-Alpaca-2-7B(指令/chat模型)。详情查看📚 v1.0版本发布日志
[2023/07/19] 🚀启动中文LLaMA-2、Alpaca-2开源大模型项目
| 章节 | 描述 |
|---|---|
| 💁🏻♂️模型简介 | 简要介绍本项目相关模型的技术特点 |
| ⏬模型下载 | 中文LLaMA-2、Alpaca-2大模型下载地址 |
| 💻推理与部署 | 介绍了如何对模型进行量化并使用个人电脑部署并体验大模型 |
| 💯系统效果 | 介绍了模型在部分任务上的效果 |
| 📝训练与精调 | 介绍了如何训练和精调中文LLaMA-2、Alpaca-2大模型 |
| ❓常见问题 | 一些常见问题的回复 |
本项目推出了基于Llama-2的中文LLaMA-2以及Alpaca-2系列模型,相比一期项目其主要特点如下:
- 在一期项目中,我们针对一代LLaMA模型的32K词表扩展了中文字词(LLaMA:49953,Alpaca:49954)
- 在本项目中,我们重新设计了新词表(大小:55296),进一步提升了中文字词的覆盖程度,同时统一了LLaMA/Alpaca的词表,避免了因混用词表带来的问题,以期进一步提升模型对中文文本的编解码效率
- FlashAttention-2是高效注意力机制的一种实现,相比其一代技术具有更快的速度和更优化的显存占用
- 当上下文长度更长时,为了避免显存爆炸式的增长,使用此类高效注意力技术尤为重要
- 本项目的所有模型均使用了FlashAttention-2技术进行训练
- 在一期项目中,我们实现了基于NTK的上下文扩展技术,可在不继续训练模型的情况下支持更长的上下文
- 基于位置插值PI和NTK等方法推出了16K长上下文版模型,支持16K上下文,并可通过NTK方法最高扩展至24K-32K
- 基于YaRN方法进一步推出了64K长上下文版模型,支持64K上下文
- 进一步设计了方便的自适应经验公式,无需针对不同的上下文长度设置NTK超参,降低了使用难度
- 在一期项目中,中文Alpaca系列模型使用了Stanford Alpaca的指令模板和系统提示语
- 初步实验发现,Llama-2-Chat系列模型的默认系统提示语未能带来统计显著的性能提升,且其内容过于冗长
- 本项目中的Alpaca-2系列模型简化了系统提示语,同时遵循Llama-2-Chat指令模板,以便更好地适配相关生态
- 在一期项目中,中文Alpaca系列模型仅完成预训练和指令精调,获得了基本的对话能力
- 通过基于人类反馈的强化学习(RLHF)实验,发现可显著提升模型传递正确价值观的能力
- 本项目推出了Alpaca-2-RLHF系列模型,使用方式与SFT模型一致
下图展示了本项目以及一期项目推出的所有大模型之间的关系。

以下是中文LLaMA-2和Alpaca-2模型的对比以及建议使用场景。如需聊天交互,请选择Alpaca而不是LLaMA。
| 对比项 | 中文LLaMA-2 | 中文Alpaca-2 |
|---|---|---|
| 模型类型 | 基座模型 | 指令/Chat模型(类ChatGPT) |
| 已开源大小 | 1.3B、7B、13B | 1.3B、7B、13B |
| 训练类型 | Causal-LM (CLM) | 指令精调 |
| 训练方式 | 7B、13B:LoRA + 全量emb/lm-head 1.3B:全量 |
7B、13B:LoRA + 全量emb/lm-head 1.3B:全量 |
| 基于什么模型训练 | 原版Llama-2(非chat版) | 中文LLaMA-2 |
| 训练语料 | 无标注通用语料(120G纯文本) | 有标注指令数据(500万条) |
| 词表大小[1] | 55,296 | 55,296 |
| 上下文长度[2] | 标准版:4K(12K-18K) 长上下文版(PI):16K(24K-32K) 长上下文版(YaRN):64K |
标准版:4K(12K-18K) 长上下文版(PI):16K(24K-32K) 长上下文版(YaRN):64K |
| 输入模板 | 不需要 | 需要套用特定模板[3],类似Llama-2-Chat |
| 适用场景 | 文本续写:给定上文,让模型生成下文 | 指令理解:问答、写作、聊天、交互等 |
| 不适用场景 | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| 偏好对齐 | 无 | RLHF版本(1.3B、7B) |
[!NOTE] [1] 本项目一代模型和二代模型的词表不同,请勿混用。二代LLaMA和Alpaca的词表相同。 [2] 括号内表示基于NTK上下文扩展支持的最大长度。 [3] Alpaca-2采用了Llama-2-chat系列模板(格式相同,提示语不同),而不是一代Alpaca的模板,请勿混用。 [4] 不建议单独使用1.3B模型,而是通过投机采样搭配更大的模型(7B、13B)使用。
以下是完整版模型,直接下载即可使用,无需其他合并步骤。推荐网络带宽充足的用户。
| 模型名称 | 类型 | 大小 | 下载地址 | GGUF |
|---|---|---|---|---|
| Chinese-LLaMA-2-13B | 基座模型 | 24.7 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-LLaMA-2-7B | 基座模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-LLaMA-2-1.3B | 基座模型 | 2.4 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-13B | 指令模型 | 24.7 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-7B | 指令模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-1.3B | 指令模型 | 2.4 GB | [百度] [Google][🤗HF] | [🤗HF] |
以下是长上下文版模型,推荐以长文本为主的下游任务使用,否则建议使用上述标准版。
| 模型名称 | 类型 | 大小 | 下载地址 | GGUF |
|---|---|---|---|---|
| Chinese-LLaMA-2-7B-64K 🆕 | 基座模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-7B-64K 🆕 | 指令模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-LLaMA-2-13B-16K | 基座模型 | 24.7 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-LLaMA-2-7B-16K | 基座模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-13B-16K | 指令模型 | 24.7 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-7B-16K | 指令模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
以下是人类偏好对齐版模型,对涉及法律、道德的问题较标准版有更优的价值导向。
| 模型名称 | 类型 | 大小 | 下载地址 | GGUF |
|---|---|---|---|---|
| Chinese-Alpaca-2-7B-RLHF 🆕 | 指令模型 | 12.9 GB | [百度] [Google] [🤗HF] | [🤗HF] |
| Chinese-Alpaca-2-1.3B-RLHF 🆕 | 指令模型 | 2.4 GB | [百度] [Google] [🤗HF] | [🤗HF] |
AWQ(Activation-aware Weight Quantization)是一种高效的模型量化方案,目前可兼容🤗transformers、llama.cpp等主流框架。
本项目模型的AWQ预搜索结果可通过以下链接获取:https://huggingface.co/hfl/chinese-llama-alpaca-2-awq
- 生成AWQ量化模型(AWQ官方目录):https://github.com/mit-han-lab/llm-awq
- llama.cpp中使用AWQ:https://github.com/ggerganov/llama.cpp/tree/master/awq-py
以下是LoRA模型(含emb/lm-head),与上述完整模型一一对应。需要注意的是LoRA模型无法直接使用,必须按照教程与重构模型进行合并。推荐网络带宽不足,手头有原版Llama-2且需要轻量下载的用户。
| 模型名称 | 类型 | 合并所需基模型 | 大小 | LoRA下载地址 |
|---|---|---|---|---|
| Chinese-LLaMA-2-LoRA-13B | 基座模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-LoRA-7B | 基座模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-13B | 指令模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-7B | 指令模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
以下是长上下文版模型,推荐以长文本为主的下游任务使用,否则建议使用上述标准版。
| 模型名称 | 类型 | 合并所需基模型 | 大小 | LoRA下载地址 |
|---|---|---|---|---|
| Chinese-LLaMA-2-LoRA-7B-64K 🆕 | 基座模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-7B-64K 🆕 | 指令模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-LoRA-13B-16K | 基座模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-LoRA-7B-16K | 基座模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-13B-16K | 指令模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-7B-16K | 指令模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
[!IMPORTANT] LoRA模型无法单独使用,必须与原版Llama-2进行合并才能转为完整模型。请通过以下方法对模型进行合并。
本项目中的相关模型主要支持以下量化、推理和部署方式,具体内容请参考对应教程。
| 工具 | 特点 | CPU | GPU | 量化 | GUI | API | vLLM§ | 16K‡ | 64K‡ | 投机采样 | 教程 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| llama.cpp | 丰富的量化选项和高效本地推理 | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ | link |
| 🤗Transformers | 原生transformers推理接口 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | link |
| Colab Demo | 在Colab中启动交互界面 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | link |
| 仿OpenAI API调用 | 仿OpenAI API接口的服务器Demo | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | ❌ | link |
| text-generation-webui | 前端Web UI界面的部署方式 | ✅ | ✅ | ✅ | ✅ | ✅† | ❌ | ✅ | ❌ | ❌ | link |
| LangChain | 适合二次开发的大模型应用开源框架 | ✅† | ✅ | ✅† | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | link |
| privateGPT | 基于LangChain的多文档本地问答框架 | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | link |
[!NOTE] † 工具支持该特性,但教程中未实现,详细说明请参考对应官方文档
‡ 指是否支持长上下文版本模型(需要第三方库支持自定义RoPE)
§ vLLM后端不支持长上下文版本模型
为了评测相关模型的效果,本项目分别进行了生成效果评测和客观效果评测(NLU类),从不同角度对大模型进行评估。需要注意的是,综合评估大模型能力仍然是亟待解决的重要课题,单个数据集的结果并不能综合评估模型性能。推荐用户在自己关注的任务上进行测试,选择适配相关任务的模型。
为了更加直观地了解模型的生成效果,本项目仿照Fastchat Chatbot Arena推出了模型在线对战平台,可浏览和评测模型回复质量。对战平台提供了胜率、Elo评分等评测指标,并且可以查看两两模型的对战胜率等结果。题库来自于一期项目人工制作的200题,以及在此基础上额外增加的题目。生成回复具有随机性,受解码超参、随机种子等因素影响,因此相关评测并非绝对严谨,结果仅供晾晒参考,欢迎自行体验。部分生成样例请查看examples目录。
⚔️ 模型竞技场:http://llm-arena.ymcui.com
| 系统 | 对战胜率(无平局) ↓ | Elo评分 |
|---|---|---|
| Chinese-Alpaca-2-13B-16K | 86.84% | 1580 |
| Chinese-Alpaca-2-13B | 72.01% | 1579 |
| Chinese-Alpaca-Pro-33B | 64.87% | 1548 |
| Chinese-Alpaca-2-7B | 64.11% | 1572 |
| Chinese-Alpaca-Pro-7B | 62.05% | 1500 |
| Chinese-Alpaca-2-7B-16K | 61.67% | 1540 |
| Chinese-Alpaca-Pro-13B | 61.26% | 1567 |
| Chinese-Alpaca-Plus-33B | 31.29% | 1401 |
| Chinese-Alpaca-Plus-13B | 23.43% | 1329 |
| Chinese-Alpaca-Plus-7B | 20.92% | 1379 |
[!NOTE] 以上结果截至2023年9月1日。最新结果请进入⚔️竞技场进行查看。
C-Eval是一个全面的中文基础模型评估套件,其中验证集和测试集分别包含1.3K和12.3K个选择题,涵盖52个学科。实验结果以“zero-shot / 5-shot”进行呈现。C-Eval推理代码请参考本项目:📖GitHub Wiki
| LLaMA Models | Valid | Test | Alpaca Models | Valid | Test |
|---|---|---|---|---|---|
| Chinese-LLaMA-2-13B | 40.6 / 42.7 | 38.0 / 41.6 | Chinese-Alpaca-2-13B | 44.3 / 45.9 | 42.6 / 44.0 |
| Chinese-LLaMA-2-7B | 28.2 / 36.0 | 30.3 / 34.2 | Chinese-Alpaca-2-7B | 41.3 / 42.9 | 40.3 / 39.5 |
| Chinese-LLaMA-Plus-33B | 37.4 / 40.0 | 35.7 / 38.3 | Chinese-Alpaca-Plus-33B | 46.5 / 46.3 | 44.9 / 43.5 |
| Chinese-LLaMA-Plus-13B | 27.3 / 34.0 | 27.8 / 33.3 | Chinese-Alpaca-Plus-13B | 43.3 / 42.4 | 41.5 / 39.9 |
| Chinese-LLaMA-Plus-7B | 27.3 / 28.3 | 26.9 / 28.4 | Chinese-Alpaca-Plus-7B | 36.7 / 32.9 | 36.4 / 32.3 |
CMMLU是另一个综合性中文评测数据集,专门用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的67个主题,共计11.5K个选择题。CMMLU推理代码请参考本项目:📖GitHub Wiki
| LLaMA Models | Test (0/few-shot) | Alpaca Models | Test (0/few-shot) |
|---|---|---|---|
| Chinese-LLaMA-2-13B | 38.9 / 42.5 | Chinese-Alpaca-2-13B | 43.2 / 45.5 |
| Chinese-LLaMA-2-7B | 27.9 / 34.1 | Chinese-Alpaca-2-7B | 40.0 / 41.8 |
| Chinese-LLaMA-Plus-33B | 35.2 / 38.8 | Chinese-Alpaca-Plus-33B | 46.6 / 45.3 |
| Chinese-LLaMA-Plus-13B | 29.6 / 34.0 | Chinese-Alpaca-Plus-13B | 40.6 / 39.9 |
| Chinese-LLaMA-Plus-7B | 25.4 / 26.3 | Chinese-Alpaca-Plus-7B | 36.8 / 32.6 |
LongBench是一个大模型长文本理解能力的评测基准,由6大类、20个不同的任务组成,多数任务的平均长度在5K-15K之间,共包含约4.75K条测试数据。以下是本项目长上下文版模型在该中文任务(含代码任务)上的评测效果。LongBench推理代码请参考本项目:📖GitHub Wiki
| Models | 单文档QA | 多文档QA | 摘要 | Few-shot学习 | 代码补全 | 合成任务 | Avg |
|---|---|---|---|---|---|---|---|
| Chinese-Alpaca-2-7B-64K | 44.7 | 28.1 | 14.4 | 39.0 | 44.6 | 5.0 | 29.3 |
| Chinese-LLaMA-2-7B-64K | 27.2 | 16.4 | 6.5 | 33.0 | 7.8 | 5.0 | 16.0 |
| Chinese-Alpaca-2-13B-16K | 47.9 | 26.7 | 13.0 | 22.3 | 46.6 | 21.5 | 29.7 |
| Chinese-Alpaca-2-13B | 38.4 | 20.0 | 11.9 | 17.3 | 46.5 | 8.0 | 23.7 |
| Chinese-Alpaca-2-7B-16K | 46.4 | 23.3 | 14.3 | 29.0 | 49.6 | 9.0 | 28.6 |
| Chinese-Alpaca-2-7B | 34.0 | 17.4 | 11.8 | 21.3 | 50.3 | 4.5 | 23.2 |
| Chinese-LLaMA-2-13B-16K | 36.7 | 17.7 | 3.1 | 29.8 | 13.8 | 3.0 | 17.3 |
| Chinese-LLaMA-2-13B | 28.3 | 14.4 | 4.6 | 16.3 | 10.4 | 5.4 | 13.2 |
| Chinese-LLaMA-2-7B-16K | 33.2 | 15.9 | 6.5 | 23.5 | 10.3 | 5.3 | 15.8 |
| Chinese-LLaMA-2-7B | 19.0 | 13.9 | 6.4 | 11.0 | 11.0 | 4.7 | 11.0 |
以Chinese-LLaMA-2-7B为例,对比不同精度下的模型大小、PPL(困惑度)、C-Eval效果,方便用户了解量化精度损失。PPL以4K上下文大小计算,C-Eval汇报的是valid集合上zero-shot和5-shot结果。
| 精度 | 模型大小 | PPL | C-Eval |
|---|---|---|---|
| FP16 | 12.9 GB | 9.373 | 28.2 / 36.0 |
| 8-bit量化 | 6.8 GB | 9.476 | 26.8 / 35.4 |
| 4-bit量化 | 3.7 GB | 10.132 | 25.5 / 32.8 |
特别地,以下是在llama.cpp下不同量化方法的评测数据,供用户参考,速度以ms/tok计,测试设备为M1 Max。具体细节见📖GitHub Wiki
| llama.cpp | F16 | Q2_K | Q3_K | Q4_0 | Q4_1 | Q4_K | Q5_0 | Q5_1 | Q5_K | Q6_K | Q8_0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PPL | 9.128 | 11.107 | 9.576 | 9.476 | 9.576 | 9.240 | 9.156 | 9.213 | 9.168 | 9.133 | 9.129 |
| Size | 12.91G | 2.41G | 3.18G | 3.69G | 4.08G | 3.92G | 4.47G | 4.86G | 4.59G | 5.30G | 6.81G |
| CPU Speed | 117 | 42 | 51 | 39 | 44 | 43 | 48 | 51 | 50 | 54 | 65 |
| GPU Speed | 53 | 19 | 21 | 17 | 18 | 20 | x | x | 25 | 26 | x |
通过投机采样方法并借助Chinese-LLaMA-2-1.3B和Chinese-Alpaca-2-1.3B,可以分别加速7B、13B的LLaMA和Alpaca模型的推理速度。以下是使用投机采样脚本在1*A40-48G上解码生成效果评测中的问题测得的平均速度(速度以ms/token计,模型均为fp16精度),供用户参考。详细说明见📖GitHub Wiki。
| 草稿模型 | 草稿模型速度 | 目标模型 | 目标模型速度 | 投机采样速度(加速比) |
|---|---|---|---|---|
| Chinese-LLaMA-2-1.3B | 7.6 | Chinese-LLaMA-2-7B | 49.3 | 36.0(1.37x) |
| Chinese-LLaMA-2-1.3B | 7.6 | Chinese-LLaMA-2-13B | 66.0 | 47.1(1.40x) |
| Chinese-Alpaca-2-1.3B | 8.1 | Chinese-Alpaca-2-7B | 50.2 | 34.9(1.44x) |
| Chinese-Alpaca-2-1.3B | 8.2 | Chinese-Alpaca-2-13B | 67.0 | 41.6(1.61x) |
为评估中文模型与人类价值偏好对齐程度,我们自行构建了评测数据集,覆盖了道德、色情、毒品、暴力等人类价值偏好重点关注的多个方面。实验结果以价值体现正确率进行呈现(体现正确价值观题目数 / 总题数)。
| Alpaca Models | Accuracy | Alpaca Models | Accuracy |
|---|---|---|---|
| Chinese-Alpaca-2-1.3B | 79.3% | Chinese-Alpaca-2-7B | 88.3% |
| Chinese-Alpaca-2-1.3B-RLHF | 95.8% | Chinese-Alpaca-2-7B-RLHF | 97.5% |
| Alpaca Models | C-Eval (0/few-shot) | CMMLU (0/few-shot) |
|---|---|---|
| Chinese-Alpaca-2-1.3B | 23.8 / 26.8 | 24.8 / 25.1 |
| Chinese-Alpaca-2-7B | 42.1 / 41.0 | 40.0 / 41.8 |
| Chinese-Alpaca-2-1.3B-RLHF | 23.6 / 27.1 | 24.9 / 25.0 |
| Chinese-Alpaca-2-7B-RLHF | 40.6 / 41.2 | 39.5 / 41.0 |
- 在原版Llama-2的基础上,利用大规模无标注数据进行增量训练,得到Chinese-LLaMA-2系列基座模型
- 训练数据采用了一期项目中Plus版本模型一致的数据,其总量约120G纯文本文件
- 训练代码参考了🤗transformers中的run_clm.py,使用方法见📖预训练脚本Wiki
- 在Chinese-LLaMA-2的基础上,利用有标注指令数据进行进一步精调,得到Chinese-Alpaca-2系列模型
- 训练数据采用了一期项目中Pro版本模型使用的指令数据,其总量约500万条指令数据(相比一期略增加)
- 训练代码参考了Stanford Alpaca项目中数据集处理的相关部分,使用方法见📖指令精调脚本Wiki
- 在Chinese-Alpaca-2系列模型基础上,利用偏好数据和PPO算法进行人类偏好对齐精调,得到Chinese-Alpaca-2-RLHF系列模型
- 训练数据基于多个开源项目中的人类偏好数据和本项目指令精调数据进行采样,奖励模型阶段、强化学习阶段分别约69.5K、25.6K条样本
- 训练代码基于DeepSpeed-Chat开发,具体流程见📖奖励模型Wiki和📖强化学习Wiki
请在提Issue前务必先查看FAQ中是否已存在解决方案。具体问题和解答请参考本项目 📖GitHub Wiki
问题1:本项目和一期项目的区别?
问题2:模型能否商用?
问题3:接受第三方Pull Request吗?
问题4:为什么不对模型做全量预训练而是用LoRA?
问题5:二代模型支不支持某些支持一代LLaMA的工具?
问题6:Chinese-Alpaca-2是Llama-2-Chat训练得到的吗?
问题7:为什么24G显存微调Chinese-Alpaca-2-7B会OOM?
问题8:可以使用16K长上下文版模型替代标准版模型吗?
问题9:如何解读第三方公开榜单的结果?
问题10:会出34B或者70B级别的模型吗?
问题11:为什么长上下文版模型是16K,不是32K或者100K?
问题12:为什么Alpaca模型会回复说自己是ChatGPT?
问题13:为什么pt_lora_model或者sft_lora_model下的adapter_model.bin只有几百k?
如果您使用了本项目的相关资源,请参考引用本项目的技术报告:https://arxiv.org/abs/2304.08177
@article{Chinese-LLaMA-Alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
本项目主要基于以下开源项目二次开发,在此对相关项目和研究开发人员表示感谢。
同时感谢Chinese-LLaMA-Alpaca(一期项目)的contributor以及关联项目和人员。
本项目基于由Meta发布的Llama-2模型进行开发,使用过程中请严格遵守Llama-2的开源许可协议。如果涉及使用第三方代码,请务必遵从相关的开源许可协议。模型生成的内容可能会因为计算方法、随机因素以及量化精度损失等影响其准确性,因此,本项目不对模型输出的准确性提供任何保证,也不会对任何因使用相关资源和输出结果产生的损失承担责任。如果将本项目的相关模型用于商业用途,开发者应遵守当地的法律法规,确保模型输出内容的合规性,本项目不对任何由此衍生的产品或服务承担责任。
局限性声明
虽然本项目中的模型具备一定的中文理解和生成能力,但也存在局限性,包括但不限于:
- 可能会产生不可预测的有害内容以及不符合人类偏好和价值观的内容
- 由于算力和数据问题,相关模型的训练并不充分,中文理解能力有待进一步提升
- 暂时没有在线可互动的demo(注:用户仍然可以自行在本地部署和体验)
如有疑问,请在GitHub Issue中提交。礼貌地提出问题,构建和谐的讨论社区。
- 在提交问题之前,请先查看FAQ能否解决问题,同时建议查阅以往的issue是否能解决你的问题。
- 提交问题请使用本项目设置的Issue模板,以帮助快速定位具体问题。
- 重复以及与本项目无关的issue会被stable-bot处理,敬请谅解。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Chinese-LLaMA-Alpaca-2
Similar Open Source Tools
Chinese-LLaMA-Alpaca-2
Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.
Chinese-LLaMA-Alpaca
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.
sanic-web
Sanic-Web is a lightweight, end-to-end, and easily customizable large model application project built on technologies such as Dify, Ollama & Vllm, Sanic, and Text2SQL. It provides a one-stop solution for developing large model applications, supporting graphical data-driven Q&A using ECharts, handling table-based Q&A with CSV files, and integrating with third-party RAG systems for general knowledge Q&A. As a lightweight framework, Sanic-Web enables rapid iteration and extension to facilitate the quick implementation of large model projects.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.
yudao-ui-admin-vue3
The yudao-ui-admin-vue3 repository is an open-source project focused on building a fast development platform for developers in China. It utilizes Vue3 and Element Plus to provide features such as configurable themes, internationalization, dynamic route permission generation, common component encapsulation, and rich examples. The project supports the latest front-end technologies like Vue3 and Vite4, and also includes tools like TypeScript, pinia, vueuse, vue-i18n, vue-router, unocss, iconify, and wangeditor. It offers a range of development tools and features for system functions, infrastructure, workflow management, payment systems, member centers, data reporting, e-commerce systems, WeChat public accounts, ERP systems, and CRM systems.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
yudao-boot-mini
yudao-boot-mini is an open-source project focused on developing a rapid development platform for developers in China. It includes features like system functions, infrastructure, member center, data reports, workflow, mall system, WeChat official account, CRM, ERP, etc. The project is based on Spring Boot with Java backend and Vue for frontend. It offers various functionalities such as user management, role management, menu management, department management, workflow management, payment system, code generation, API documentation, database documentation, file service, WebSocket integration, message queue, Java monitoring, and more. The project is licensed under the MIT License, allowing both individuals and enterprises to use it freely without restrictions.
teaching-boyfriend-llm
The 'teaching-boyfriend-llm' repository contains study notes on LLM (Large Language Models) for the purpose of advancing towards AGI (Artificial General Intelligence). The notes are a collaborative effort towards understanding and implementing LLM technology.

XiaoFeiShu
XiaoFeiShu is a specialized automation software developed closely following the quality user rules of Xiaohongshu. It provides a set of automation workflows for Xiaohongshu operations, avoiding the issues of traditional RPA being mechanical, rule-based, and easily detected. The software is easy to use, with simple operation and powerful functionality.

JiwuChat
JiwuChat is a lightweight multi-platform chat application built on Tauri2 and Nuxt3, with various real-time messaging features, AI group chat bots (such as 'iFlytek Spark', 'KimiAI' etc.), WebRTC audio-video calling, screen sharing, and AI shopping functions. It supports seamless cross-device communication, covering text, images, files, and voice messages, also supporting group chats and customizable settings. It provides light/dark mode for efficient social networking.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.
PaddleScience
PaddleScience is a scientific computing suite developed based on the deep learning framework PaddlePaddle. It utilizes the learning ability of deep neural networks and the automatic (higher-order) differentiation mechanism of PaddlePaddle to solve problems in physics, chemistry, meteorology, and other fields. It supports three solving methods: physics mechanism-driven, data-driven, and mathematical fusion, and provides basic APIs and detailed documentation for users to use and further develop.
For similar tasks
blog
这是一个程序员关于 ChatGPT 学习过程的记录,其中包括了 ChatGPT 的使用技巧、相关工具和资源的整理,以及一些个人见解和思考。 **使用技巧** * **充值 OpenAI API**:可以通过 https://beta.openai.com/account/api-keys 进行充值,支持信用卡和 PayPal。 * **使用专梯**:推荐使用稳定的专梯,可以有效提高 ChatGPT 的访问速度和稳定性。 * **使用魔法**:可以通过 https://my.x-air.app:666/#/register?aff=32853 访问 ChatGPT,无需魔法即可访问。 * **下载各种 apk**:可以通过 https://apkcombo.com 下载各种安卓应用的 apk 文件。 * **ChatGPT 官网**:ChatGPT 的官方网站是 https://ai.com。 * **Midjourney**:Midjourney 是一个生成式 AI 图像平台,可以通过 https://midjourney.com 访问。 * **文本转视频**:可以通过 https://www.d-id.com 将文本转换为视频。 * **国内大模型**:国内也有很多大模型,如阿里巴巴的通义千问、百度文心一言、讯飞星火、阿里巴巴通义听悟等。 * **查看 OpenAI 状态**:可以通过 https://status.openai.com/ 查看 OpenAI 的服务状态。 * **Canva 画图**:Canva 是一个在线平面设计平台,可以通过 https://www.canva.cn 进行画图。 **相关工具和资源** * **文字转语音**:可以通过 https://modelscope.cn/models?page=1&tasks=text-to-speech&type=audio 找到文字转语音的模型。 * **可好好玩玩的项目**: * https://github.com/sunner/ChatALL * https://github.com/labring/FastGPT * https://github.com/songquanpeng/one-api * **个人博客**: * https://baoyu.io/ * https://gorden-sun.notion.site/527689cd2b294e60912f040095e803c5?v=4f6cc12006c94f47aee4dc909511aeb5 * **srt 2 lrc 歌词**:可以通过 https://gotranscript.com/subtitle-converter 将 srt 格式的字幕转换为 lrc 格式的歌词。 * **5 种速率限制**:OpenAI API 有 5 种速率限制:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟 tokens 数量)、TPD(每天 tokens 数量)、IPM(每分钟图像数量)。 * **扣子平台**:coze.cn 是一个扣子平台,可以提供各种扣子。 * **通过云函数免费使用 GPT-3.5**:可以通过 https://juejin.cn/post/7353849549540589587 免费使用 GPT-3.5。 * **不蒜子 统计网页基数**:可以通过 https://busuanzi.ibruce.info/ 统计网页的基数。 * **视频总结和翻译网页**:可以通过 https://glarity.app/zh-CN 总结和翻译视频。 * **视频翻译和配音工具**:可以通过 https://github.com/jianchang512/pyvideotrans 翻译和配音视频。 * **文字生成音频**:可以通过 https://www.cnblogs.com/jijunjian/p/18118366 将文字生成音频。 * **memo ai**:memo.ac 是一个多模态 AI 平台,可以将视频链接、播客链接、本地音视频转换为文字,支持多语言转录后翻译,还可以将文字转换为新的音频。 * **视频总结工具**:可以通过 https://summarize.ing/ 总结视频。 * **可每天免费玩玩**:可以通过 https://www.perplexity.ai/ 每天免费玩玩。 * **Suno.ai**:Suno.ai 是一个 AI 语言模型,可以通过 https://bibigpt.co/ 访问。 * **CapCut**:CapCut 是一个视频编辑软件,可以通过 https://www.capcut.cn/ 下载。 * **Valla.ai**:Valla.ai 是一个多模态 AI 模型,可以通过 https://www.valla.ai/ 访问。 * **Viggle.ai**:Viggle.ai 是一个 AI 视频生成平台,可以通过 https://viggle.ai 访问。 * **使用免费的 GPU 部署文生图大模型**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 部署文生图大模型。 * **语音转文字**:可以通过 https://speech.microsoft.com/portal 将语音转换为文字。 * **投资界的 ai**:可以通过 https://reportify.cc/ 了解投资界的 ai。 * **抓取小视频 app 的各种信息**:可以通过 https://github.com/NanmiCoder/MediaCrawler 抓取小视频 app 的各种信息。 * **马斯克 Grok1 开源**:马斯克的 Grok1 模型已经开源,可以通过 https://github.com/xai-org/grok-1 访问。 * **ChatALL**:ChatALL 是一个跨端支持的聊天机器人,可以通过 https://github.com/sunner/ChatALL 访问。 * **零一万物**:零一万物是一个 AI 平台,可以通过 https://www.01.ai/cn 访问。 * **智普**:智普是一个 AI 语言模型,可以通过 https://chatglm.cn/ 访问。 * **memo ai 下载**:可以通过 https://memo.ac/ 下载 memo ai。 * **ffmpeg 学习**:可以通过 https://www.ruanyifeng.com/blog/2020/01/ffmpeg.html 学习 ffmpeg。 * **自动生成文章小工具**:可以通过 https://www.cognition-labs.com/blog 生成文章。 * **简易商城**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 搭建简易商城。 * **物联网**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 学习物联网。 * **自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 实现自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表。 **个人见解和思考** * ChatGPT 是一个强大的工具,可以用来提高工作效率和创造力。 * ChatGPT 的使用门槛较低,即使是非技术人员也可以轻松上手。 * ChatGPT 的发展速度非常快,未来可能会对各个行业产生深远的影响。 * 我们应该理性看待 ChatGPT,既要看到它的优点,也要意识到它的局限性。 * 我们应该积极探索 ChatGPT 的应用场景,为社会创造价值。

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.
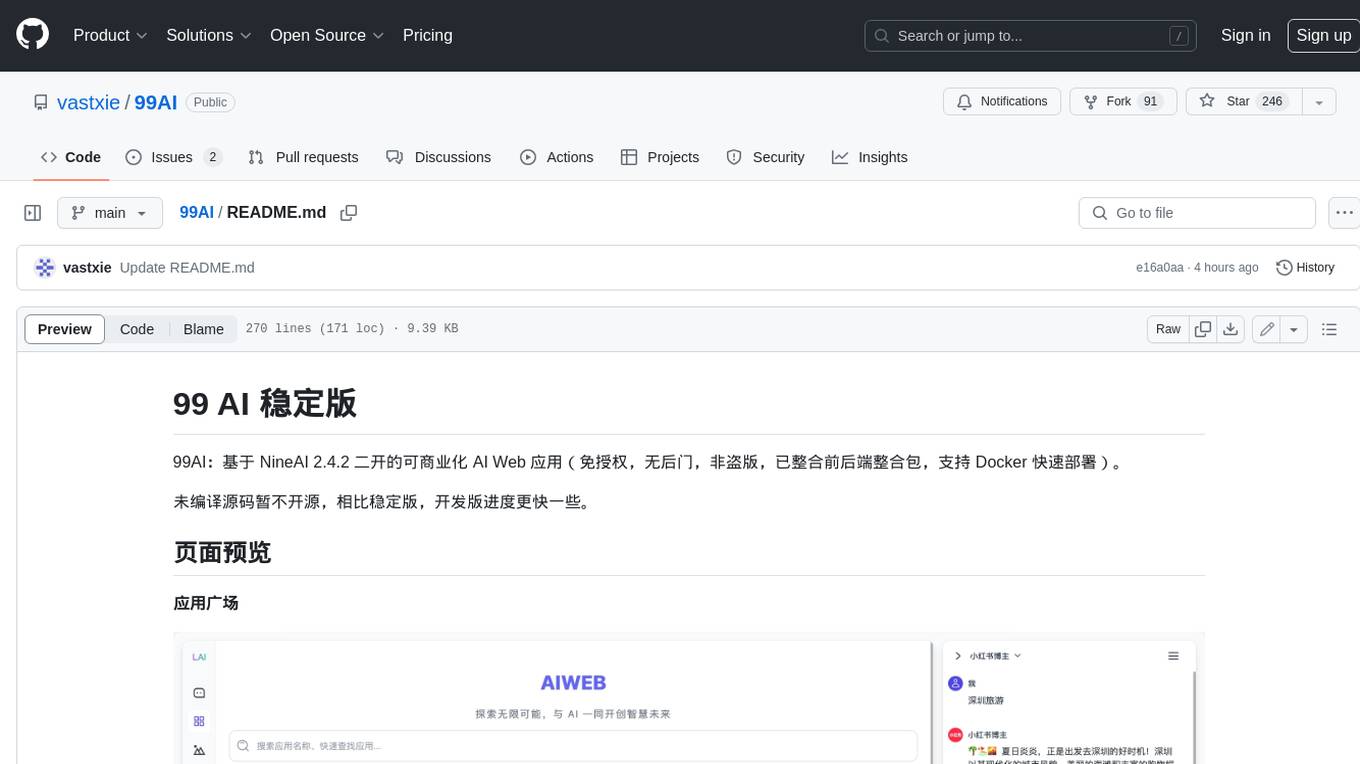
99AI
99AI is a commercializable AI web application based on NineAI 2.4.2 (no authorization, no backdoors, no piracy, integrated front-end and back-end integration packages, supports Docker rapid deployment). The uncompiled source code is temporarily closed. Compared with the stable version, the development version is faster.
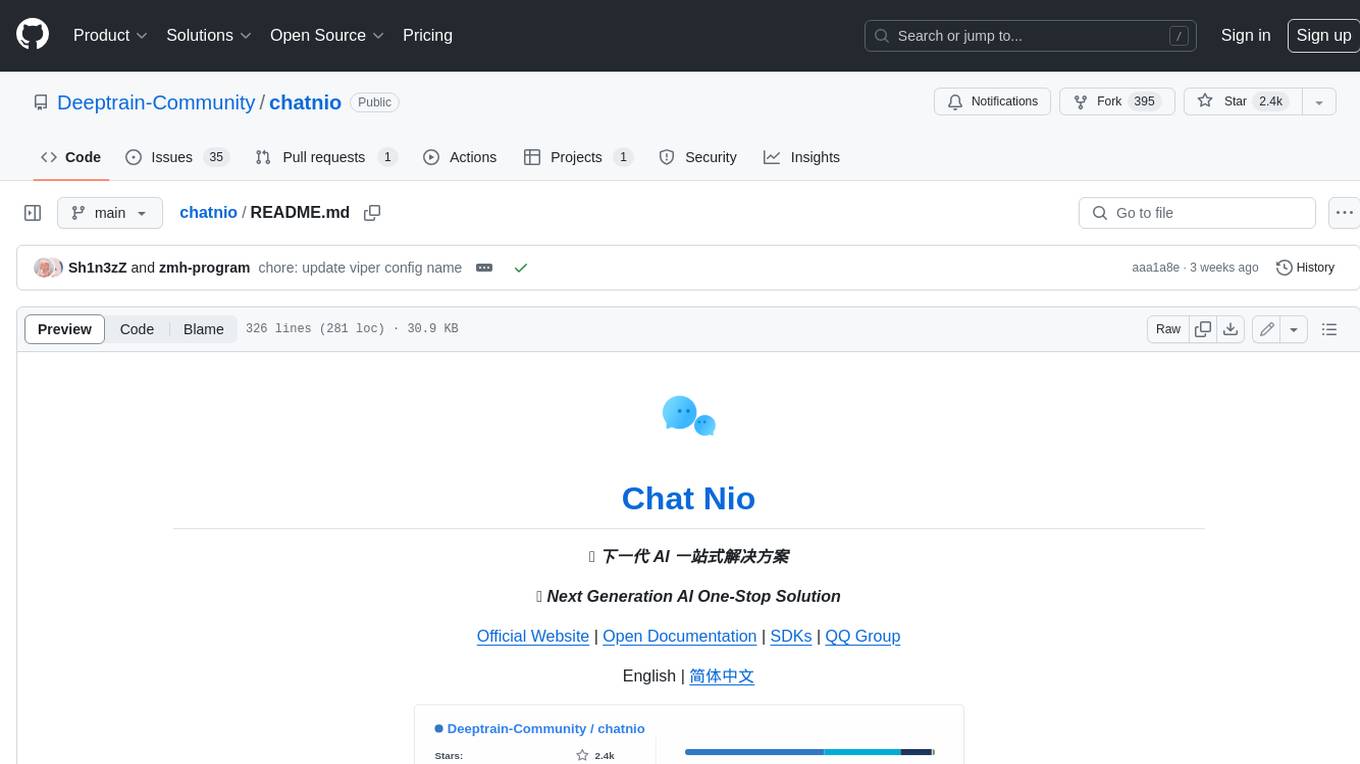
chatnio
Chat Nio is a next-generation AI one-stop solution that provides a rich and user-friendly interface for interacting with various AI models. It offers features such as AI chat conversation, rich format compatibility, markdown support, message menu support, multi-platform adaptation, dialogue memory, full-model file parsing, full-model DuckDuckGo online search, full-screen large text editing, model marketplace, preset support, site announcements, preference settings, internationalization support, and a rich admin system. Chat Nio also boasts a powerful channel management system that utilizes a self-developed channel distribution algorithm, supports multi-channel management, is compatible with multiple formats, allows for custom models, supports channel retries, enables balanced load within the same channel, and provides channel model mapping and user grouping. Additionally, Chat Nio offers forwarding API services that are compatible with multiple formats in the OpenAI universal format and support multiple model compatible layers. It also provides a custom build and install option for highly customizable deployments. Chat Nio is an open-source project licensed under the Apache License 2.0 and welcomes contributions from the community.

Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document
Chinese-LLaMA-Alpaca-2
Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

sourcegraph
Sourcegraph is a code search and navigation tool that helps developers read, write, and fix code in large, complex codebases. It provides features such as code search across all repositories and branches, code intelligence for navigation and refactoring, and the ability to fix and refactor code across multiple repositories at once.
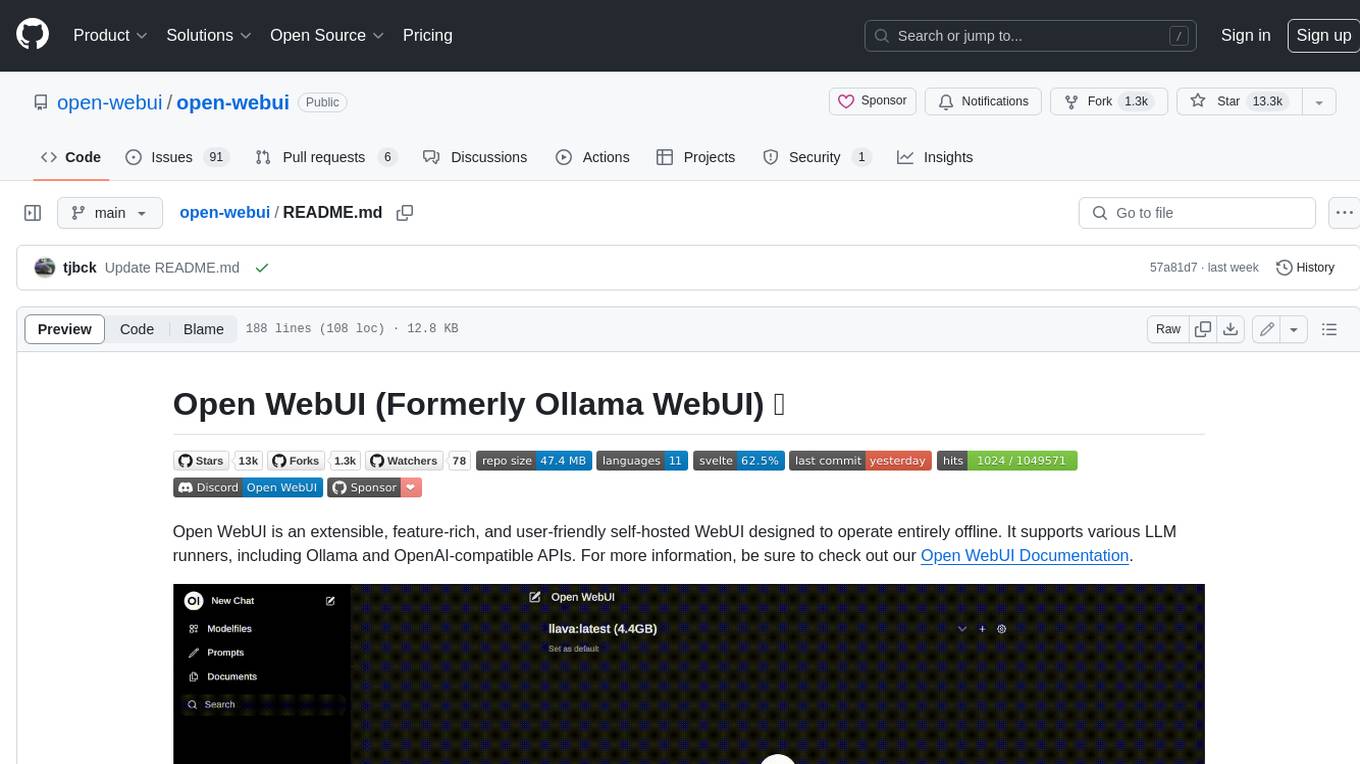
open-webui
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. For more information, be sure to check out our Open WebUI Documentation.

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.