
open-webui
User-friendly AI Interface (Supports Ollama, OpenAI API, ...)
Stars: 123335
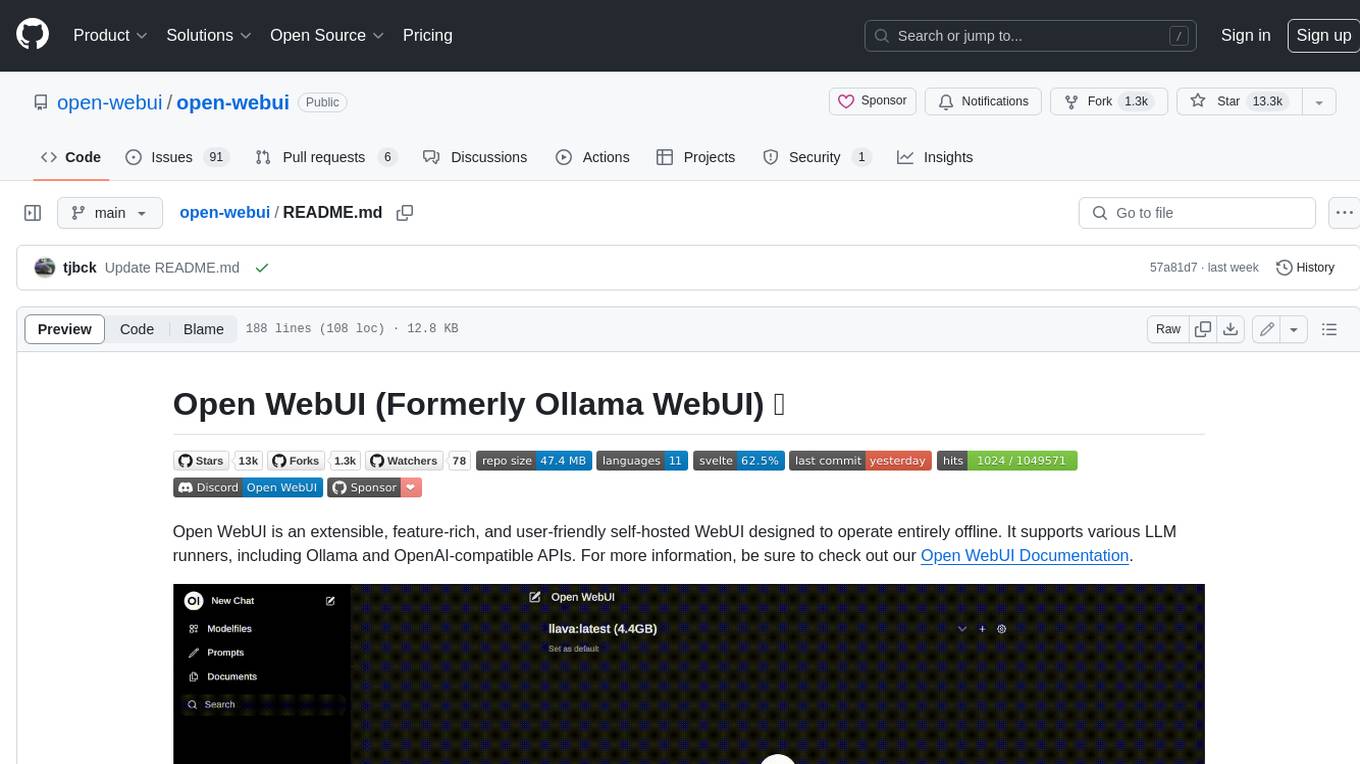
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. For more information, be sure to check out our Open WebUI Documentation.
README:









Open WebUI is an extensible, feature-rich, and user-friendly self-hosted AI platform designed to operate entirely offline. It supports various LLM runners like Ollama and OpenAI-compatible APIs, with built-in inference engine for RAG, making it a powerful AI deployment solution.
Passionate about open-source AI? Join our team →

[!TIP]
Looking for an Enterprise Plan? – Speak with Our Sales Team Today!Get enhanced capabilities, including custom theming and branding, Service Level Agreement (SLA) support, Long-Term Support (LTS) versions, and more!
For more information, be sure to check out our Open WebUI Documentation.
-
🚀 Effortless Setup: Install seamlessly using Docker or Kubernetes (kubectl, kustomize or helm) for a hassle-free experience with support for both
:ollamaand:cudatagged images. -
🤝 Ollama/OpenAI API Integration: Effortlessly integrate OpenAI-compatible APIs for versatile conversations alongside Ollama models. Customize the OpenAI API URL to link with LMStudio, GroqCloud, Mistral, OpenRouter, and more.
-
🛡️ Granular Permissions and User Groups: By allowing administrators to create detailed user roles and permissions, we ensure a secure user environment. This granularity not only enhances security but also allows for customized user experiences, fostering a sense of ownership and responsibility amongst users.
-
📱 Responsive Design: Enjoy a seamless experience across Desktop PC, Laptop, and Mobile devices.
-
📱 Progressive Web App (PWA) for Mobile: Enjoy a native app-like experience on your mobile device with our PWA, providing offline access on localhost and a seamless user interface.
-
✒️🔢 Full Markdown and LaTeX Support: Elevate your LLM experience with comprehensive Markdown and LaTeX capabilities for enriched interaction.
-
🎤📹 Hands-Free Voice/Video Call: Experience seamless communication with integrated hands-free voice and video call features using multiple Speech-to-Text providers (Local Whisper, OpenAI, Deepgram, Azure) and Text-to-Speech engines (Azure, ElevenLabs, OpenAI, Transformers, WebAPI), allowing for dynamic and interactive chat environments.
-
🛠️ Model Builder: Easily create Ollama models via the Web UI. Create and add custom characters/agents, customize chat elements, and import models effortlessly through Open WebUI Community integration.
-
🐍 Native Python Function Calling Tool: Enhance your LLMs with built-in code editor support in the tools workspace. Bring Your Own Function (BYOF) by simply adding your pure Python functions, enabling seamless integration with LLMs.
-
💾 Persistent Artifact Storage: Built-in key-value storage API for artifacts, enabling features like journals, trackers, leaderboards, and collaborative tools with both personal and shared data scopes across sessions.
-
📚 Local RAG Integration: Dive into the future of chat interactions with groundbreaking Retrieval Augmented Generation (RAG) support using your choice of 9 vector databases and multiple content extraction engines (Tika, Docling, Document Intelligence, Mistral OCR, External loaders). Load documents directly into chat or add files to your document library, effortlessly accessing them using the
#command before a query. -
🔍 Web Search for RAG: Perform web searches using 15+ providers including
SearXNG,Google PSE,Brave Search,Kagi,Mojeek,Tavily,Perplexity,serpstack,serper,Serply,DuckDuckGo,SearchApi,SerpApi,Bing,Jina,Exa,Sougou,Azure AI Search, andOllama Cloud, injecting results directly into your chat experience. -
🌐 Web Browsing Capability: Seamlessly integrate websites into your chat experience using the
#command followed by a URL. This feature allows you to incorporate web content directly into your conversations, enhancing the richness and depth of your interactions. -
🎨 Image Generation & Editing Integration: Create and edit images using multiple engines including OpenAI's DALL-E, Gemini, ComfyUI (local), and AUTOMATIC1111 (local), with support for both generation and prompt-based editing workflows.
-
⚙️ Many Models Conversations: Effortlessly engage with various models simultaneously, harnessing their unique strengths for optimal responses. Enhance your experience by leveraging a diverse set of models in parallel.
-
🔐 Role-Based Access Control (RBAC): Ensure secure access with restricted permissions; only authorized individuals can access your Ollama, and exclusive model creation/pulling rights are reserved for administrators.
-
🗄️ Flexible Database & Storage Options: Choose from SQLite (with optional encryption), PostgreSQL, or configure cloud storage backends (S3, Google Cloud Storage, Azure Blob Storage) for scalable deployments.
-
🔍 Advanced Vector Database Support: Select from 9 vector database options including ChromaDB, PGVector, Qdrant, Milvus, Elasticsearch, OpenSearch, Pinecone, S3Vector, and Oracle 23ai for optimal RAG performance.
-
🔐 Enterprise Authentication: Full support for LDAP/Active Directory integration, SCIM 2.0 automated provisioning, and SSO via trusted headers alongside OAuth providers. Enterprise-grade user and group provisioning through SCIM 2.0 protocol, enabling seamless integration with identity providers like Okta, Azure AD, and Google Workspace for automated user lifecycle management.
-
☁️ Cloud-Native Integration: Native support for Google Drive and OneDrive/SharePoint file picking, enabling seamless document import from enterprise cloud storage.
-
📊 Production Observability: Built-in OpenTelemetry support for traces, metrics, and logs, enabling comprehensive monitoring with your existing observability stack.
-
⚖️ Horizontal Scalability: Redis-backed session management and WebSocket support for multi-worker and multi-node deployments behind load balancers.
-
🌐🌍 Multilingual Support: Experience Open WebUI in your preferred language with our internationalization (i18n) support. Join us in expanding our supported languages! We're actively seeking contributors!
-
🧩 Pipelines, Open WebUI Plugin Support: Seamlessly integrate custom logic and Python libraries into Open WebUI using Pipelines Plugin Framework. Launch your Pipelines instance, set the OpenAI URL to the Pipelines URL, and explore endless possibilities. Examples include Function Calling, User Rate Limiting to control access, Usage Monitoring with tools like Langfuse, Live Translation with LibreTranslate for multilingual support, Toxic Message Filtering and much more.
-
🌟 Continuous Updates: We are committed to improving Open WebUI with regular updates, fixes, and new features.
Want to learn more about Open WebUI's features? Check out our Open WebUI documentation for a comprehensive overview!
We are incredibly grateful for the generous support of our sponsors. Their contributions help us to maintain and improve our project, ensuring we can continue to deliver quality work to our community. Thank you!
Open WebUI can be installed using pip, the Python package installer. Before proceeding, ensure you're using Python 3.11 to avoid compatibility issues.
-
Install Open WebUI: Open your terminal and run the following command to install Open WebUI:
pip install open-webui
-
Running Open WebUI: After installation, you can start Open WebUI by executing:
open-webui serve
This will start the Open WebUI server, which you can access at http://localhost:8080
[!NOTE]
Please note that for certain Docker environments, additional configurations might be needed. If you encounter any connection issues, our detailed guide on Open WebUI Documentation is ready to assist you.
[!WARNING] When using Docker to install Open WebUI, make sure to include the
-v open-webui:/app/backend/datain your Docker command. This step is crucial as it ensures your database is properly mounted and prevents any loss of data.
[!TIP]
If you wish to utilize Open WebUI with Ollama included or CUDA acceleration, we recommend utilizing our official images tagged with either:cudaor:ollama. To enable CUDA, you must install the Nvidia CUDA container toolkit on your Linux/WSL system.
-
If Ollama is on your computer, use this command:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
-
If Ollama is on a Different Server, use this command:
To connect to Ollama on another server, change the
OLLAMA_BASE_URLto the server's URL:docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
-
To run Open WebUI with Nvidia GPU support, use this command:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
-
If you're only using OpenAI API, use this command:
docker run -d -p 3000:8080 -e OPENAI_API_KEY=your_secret_key -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
This installation method uses a single container image that bundles Open WebUI with Ollama, allowing for a streamlined setup via a single command. Choose the appropriate command based on your hardware setup:
-
With GPU Support: Utilize GPU resources by running the following command:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
-
For CPU Only: If you're not using a GPU, use this command instead:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Both commands facilitate a built-in, hassle-free installation of both Open WebUI and Ollama, ensuring that you can get everything up and running swiftly.
After installation, you can access Open WebUI at http://localhost:3000. Enjoy! 😄
We offer various installation alternatives, including non-Docker native installation methods, Docker Compose, Kustomize, and Helm. Visit our Open WebUI Documentation or join our Discord community for comprehensive guidance.
Look at the Local Development Guide for instructions on setting up a local development environment.
Encountering connection issues? Our Open WebUI Documentation has got you covered. For further assistance and to join our vibrant community, visit the Open WebUI Discord.
If you're experiencing connection issues, it’s often due to the WebUI docker container not being able to reach the Ollama server at 127.0.0.1:11434 (host.docker.internal:11434) inside the container . Use the --network=host flag in your docker command to resolve this. Note that the port changes from 3000 to 8080, resulting in the link: http://localhost:8080.
Example Docker Command:
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainCheck our Updating Guide available in our Open WebUI Documentation.
[!WARNING] The
:devbranch contains the latest unstable features and changes. Use it at your own risk as it may have bugs or incomplete features.
If you want to try out the latest bleeding-edge features and are okay with occasional instability, you can use the :dev tag like this:
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --add-host=host.docker.internal:host-gateway --restart always ghcr.io/open-webui/open-webui:devIf you are running Open WebUI in an offline environment, you can set the HF_HUB_OFFLINE environment variable to 1 to prevent attempts to download models from the internet.
export HF_HUB_OFFLINE=1Discover upcoming features on our roadmap in the Open WebUI Documentation.
This project contains code under multiple licenses. The current codebase includes components licensed under the Open WebUI License with an additional requirement to preserve the "Open WebUI" branding, as well as prior contributions under their respective original licenses. For a detailed record of license changes and the applicable terms for each section of the code, please refer to LICENSE_HISTORY. For complete and updated licensing details, please see the LICENSE and LICENSE_HISTORY files.
If you have any questions, suggestions, or need assistance, please open an issue or join our Open WebUI Discord community to connect with us! 🤝
Created by Timothy Jaeryang Baek - Let's make Open WebUI even more amazing together! 💪
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for open-webui
Similar Open Source Tools
open-webui
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. For more information, be sure to check out our Open WebUI Documentation.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
clearml-server
ClearML Server is a backend service infrastructure for ClearML, facilitating collaboration and experiment management. It includes a web app, RESTful API, and file server for storing images and models. Users can deploy ClearML Server using Docker, AWS EC2 AMI, or Kubernetes. The system design supports single IP or sub-domain configurations with specific open ports. ClearML-Agent Services container allows launching long-lasting jobs and various use cases like auto-scaler service, controllers, optimizer, and applications. Advanced functionality includes web login authentication and non-responsive experiments watchdog. Upgrading ClearML Server involves stopping containers, backing up data, downloading the latest docker-compose.yml file, configuring ClearML-Agent Services, and spinning up docker containers. Community support is available through ClearML FAQ, Stack Overflow, GitHub issues, and email contact.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.
nextjs-ollama-llm-ui
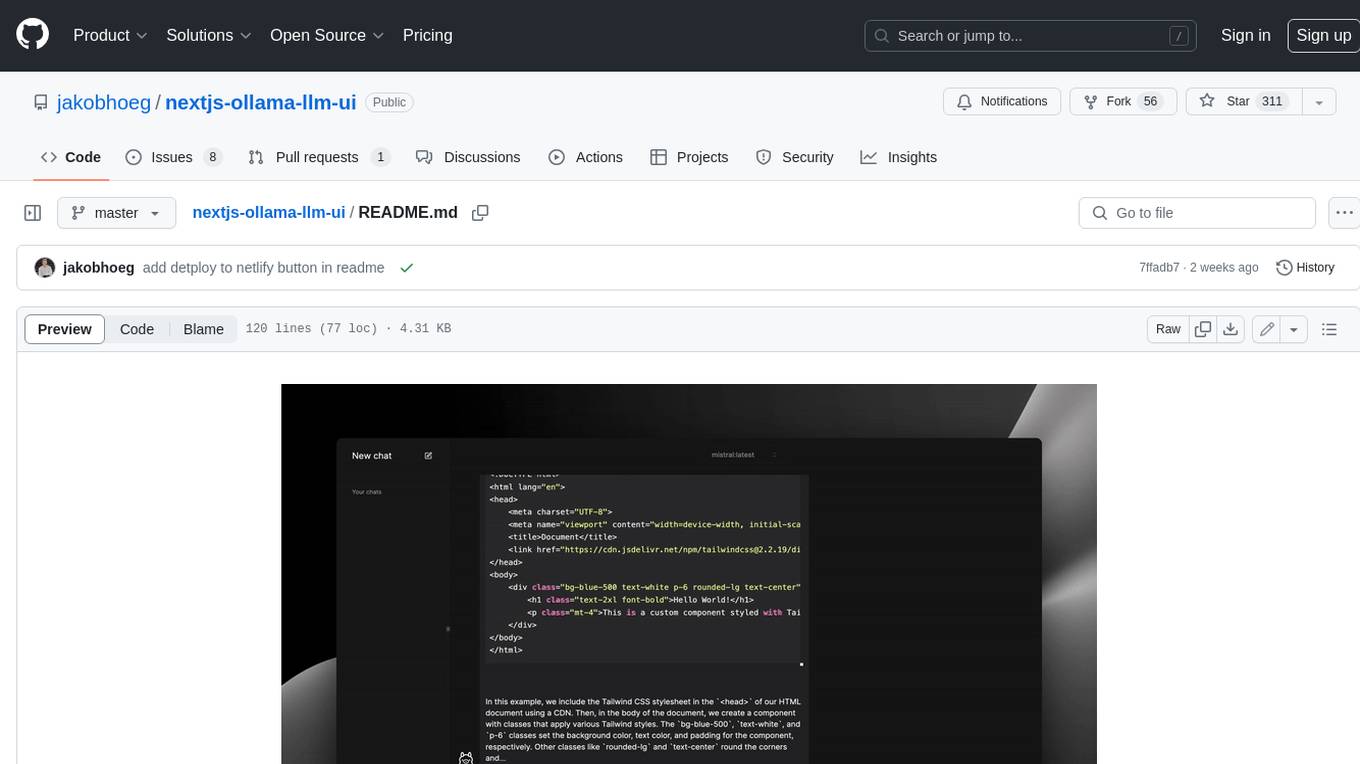
This web interface provides a user-friendly and feature-rich platform for interacting with Ollama Large Language Models (LLMs). It offers a beautiful and intuitive UI inspired by ChatGPT, making it easy for users to get started with LLMs. The interface is fully local, storing chats in local storage for convenience, and fully responsive, allowing users to chat on their phones with the same ease as on a desktop. It features easy setup, code syntax highlighting, and the ability to easily copy codeblocks. Users can also download, pull, and delete models directly from the interface, and switch between models quickly. Chat history is saved and easily accessible, and users can choose between light and dark mode. To use the web interface, users must have Ollama downloaded and running, and Node.js (18+) and npm installed. Installation instructions are provided for running the interface locally. Upcoming features include the ability to send images in prompts, regenerate responses, import and export chats, and add voice input support.

kestra
Kestra is an open-source event-driven orchestration platform that simplifies building scheduled and event-driven workflows. It offers Infrastructure as Code best practices for data, process, and microservice orchestration, allowing users to create reliable workflows using YAML configuration. Key features include everything as code with Git integration, event-driven and scheduled workflows, rich plugin ecosystem for data extraction and script running, intuitive UI with syntax highlighting, scalability for millions of workflows, version control friendly, and various features for structure and resilience. Kestra ensures declarative orchestration logic management even when workflows are modified via UI, API calls, or other methods.
trigger.dev
Trigger.dev is an open source platform and SDK for creating long-running background jobs. It provides features like JavaScript and TypeScript SDK, no timeouts, retries, queues, schedules, observability, React hooks, Realtime API, custom alerts, elastic scaling, and works with existing tech stack. Users can create tasks in their codebase, deploy tasks using the SDK, manage tasks in different environments, and have full visibility of job runs. The platform offers a trace view of every task run for detailed monitoring. Getting started is easy with account creation, project setup, and onboarding instructions. Self-hosting and development guides are available for users interested in contributing or hosting Trigger.dev.
Cerebr
Cerebr is an intelligent AI assistant browser extension designed to enhance work efficiency and learning experience. It integrates powerful AI capabilities from various sources to provide features such as smart sidebar, multiple API support, cross-browser API configuration synchronization, comprehensive Q&A support, elegant rendering, real-time response, theme switching, and more. With a minimalist design and focus on delivering a seamless, distraction-free browsing experience, Cerebr aims to be your second brain for deep reading and understanding.
MyDeviceAI
MyDeviceAI is a personal AI assistant app for iPhone that brings the power of artificial intelligence directly to the device. It focuses on privacy, performance, and personalization by running AI models locally and integrating with privacy-focused web services. The app offers seamless user experience, web search integration, advanced reasoning capabilities, personalization features, chat history access, and broad device support. It requires macOS, Xcode, CocoaPods, Node.js, and a React Native development environment for installation. The technical stack includes React Native framework, AI models like Qwen 3 and BGE Small, SearXNG integration, Redux for state management, AsyncStorage for storage, Lucide for UI components, and tools like ESLint and Prettier for code quality.

nanobrowser
Nanobrowser is an open-source AI web automation tool that runs in your browser. It is a free alternative to OpenAI Operator with flexible LLM options and a multi-agent system. Nanobrowser offers premium web automation capabilities while keeping users in complete control, with features like a multi-agent system, interactive side panel, task automation, follow-up questions, and multiple LLM support. Users can easily download and install Nanobrowser as a Chrome extension, configure agent models, and accomplish tasks such as news summary, GitHub research, and shopping research with just a sentence. The tool uses a specialized multi-agent system powered by large language models to understand and execute complex web tasks. Nanobrowser is actively developed with plans to expand LLM support, implement security measures, optimize memory usage, enable session replay, and develop specialized agents for domain-specific tasks. Contributions from the community are welcome to improve Nanobrowser and build the future of web automation.
Foxel
Foxel is a highly extensible private cloud storage solution for individuals and teams, featuring AI-powered semantic search. It offers unified file management, pluggable storage backends, semantic search capabilities, built-in file preview, permissions and sharing options, and a task processing center. Users can easily manage files, search content within unstructured data, preview various file types, share files, and process tasks asynchronously. Foxel is designed to centralize file management and enhance search capabilities for users.
higress
Higress is an open-source cloud-native API gateway built on the core of Istio and Envoy, based on Alibaba's internal practice of Envoy Gateway. It is designed for AI-native API gateway, serving AI businesses such as Tongyi Qianwen APP, Bailian Big Model API, and Machine Learning PAI platform. Higress provides capabilities to interface with LLM model vendors, AI observability, multi-model load balancing/fallback, AI token flow control, and AI caching. It offers features for AI gateway, Kubernetes Ingress gateway, microservices gateway, and security protection gateway, with advantages in production-level scalability, stream processing, extensibility, and ease of use.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.

mattermost-plugin-agents
The Mattermost Agents Plugin integrates AI capabilities directly into your Mattermost workspace, allowing users to run local LLMs on their infrastructure or connect to cloud providers. It offers multiple AI assistants with specialized personalities, thread and channel summarization, action item extraction, meeting transcription, semantic search, smart reactions, direct conversations with AI assistants, and flexible LLM support. The plugin comes with comprehensive documentation, installation instructions, system requirements, and development guidelines for users to interact with AI features and configure LLM providers.
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
For similar tasks
open-webui
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. For more information, be sure to check out our Open WebUI Documentation.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

baml
BAML is a config file format for declaring LLM functions that you can then use in TypeScript or Python. With BAML you can Classify or Extract any structured data using Anthropic, OpenAI or local models (using Ollama) ## Resources  [Discord Community](https://discord.gg/boundaryml)  [Follow us on Twitter](https://twitter.com/boundaryml) * Discord Office Hours - Come ask us anything! We hold office hours most days (9am - 12pm PST). * Documentation - Learn BAML * Documentation - BAML Syntax Reference * Documentation - Prompt engineering tips * Boundary Studio - Observability and more #### Starter projects * BAML + NextJS 14 * BAML + FastAPI + Streaming ## Motivation Calling LLMs in your code is frustrating: * your code uses types everywhere: classes, enums, and arrays * but LLMs speak English, not types BAML makes calling LLMs easy by taking a type-first approach that lives fully in your codebase: 1. Define what your LLM output type is in a .baml file, with rich syntax to describe any field (even enum values) 2. Declare your prompt in the .baml config using those types 3. Add additional LLM config like retries or redundancy 4. Transpile the .baml files to a callable Python or TS function with a type-safe interface. (VSCode extension does this for you automatically). We were inspired by similar patterns for type safety: protobuf and OpenAPI for RPCs, Prisma and SQLAlchemy for databases. BAML guarantees type safety for LLMs and comes with tools to give you a great developer experience:  Jump to BAML code or how Flexible Parsing works without additional LLM calls. | BAML Tooling | Capabilities | | ----------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | BAML Compiler install | Transpiles BAML code to a native Python / Typescript library (you only need it for development, never for releases) Works on Mac, Windows, Linux  | | VSCode Extension install | Syntax highlighting for BAML files Real-time prompt preview Testing UI | | Boundary Studio open (not open source) | Type-safe observability Labeling |

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

intel-extension-for-transformers
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples: * Seamless user experience of model compressions on Transformer-based models by extending [Hugging Face transformers](https://github.com/huggingface/transformers) APIs and leveraging [Intel® Neural Compressor](https://github.com/intel/neural-compressor) * Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper [Fast Distilbert on CPUs](https://arxiv.org/abs/2211.07715) and [QuaLA-MiniLM: a Quantized Length Adaptive MiniLM](https://arxiv.org/abs/2210.17114), and NeurIPS 2021's paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754)) * Optimized Transformer-based model packages such as [Stable Diffusion](examples/huggingface/pytorch/text-to-image/deployment/stable_diffusion), [GPT-J-6B](examples/huggingface/pytorch/text-generation/deployment), [GPT-NEOX](examples/huggingface/pytorch/language-modeling/quantization#2-validated-model-list), [BLOOM-176B](examples/huggingface/pytorch/language-modeling/inference#BLOOM-176B), [T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), [Flan-T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), and end-to-end workflows such as [SetFit-based text classification](docs/tutorials/pytorch/text-classification/SetFit_model_compression_AGNews.ipynb) and [document level sentiment analysis (DLSA)](workflows/dlsa) * [NeuralChat](intel_extension_for_transformers/neural_chat), a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of [plugins](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/docs/advanced_features.md) such as [Knowledge Retrieval](./intel_extension_for_transformers/neural_chat/pipeline/plugins/retrieval/README.md), [Speech Interaction](./intel_extension_for_transformers/neural_chat/pipeline/plugins/audio/README.md), [Query Caching](./intel_extension_for_transformers/neural_chat/pipeline/plugins/caching/README.md), and [Security Guardrail](./intel_extension_for_transformers/neural_chat/pipeline/plugins/security/README.md). This framework supports Intel Gaudi2/CPU/GPU. * [Inference](https://github.com/intel/neural-speed/tree/main) of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting [GPT-NEOX](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox), [LLAMA](https://github.com/intel/neural-speed/tree/main/neural_speed/models/llama), [MPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/mpt), [FALCON](https://github.com/intel/neural-speed/tree/main/neural_speed/models/falcon), [BLOOM-7B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/bloom), [OPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/opt), [ChatGLM2-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/chatglm), [GPT-J-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptj), and [Dolly-v2-3B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox). Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed [Sapphire Rapids](https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html).

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

sourcegraph
Sourcegraph is a code search and navigation tool that helps developers read, write, and fix code in large, complex codebases. It provides features such as code search across all repositories and branches, code intelligence for navigation and refactoring, and the ability to fix and refactor code across multiple repositories at once.
open-webui
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. For more information, be sure to check out our Open WebUI Documentation.

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.