
UglyFeed
Retrieve, aggregate, filter, evaluate, rewrite and serve RSS feeds using Large Language Models for fun, research and learning purposes.
Stars: 111
UglyFeed is a simple Python application designed to retrieve, aggregate, filter, rewrite, evaluate, and serve content (RSS feeds) written by a large language model. It provides features such as retrieving RSS feeds, aggregating feed items by similarity, rewriting content using various APIs, saving rewritten feeds to JSON files, converting JSON to valid RSS feed, serving XML feed via an HTTP server, deploying XML feed to GitHub or GitLab, and evaluating generated content. The tool can be used for smart content curation, dynamic blog generation, interactive educational tools, personalized reading experiences, brand monitoring, multilingual content delivery, enhanced RSS feeds, creative writing assistance, content repurposing, and fake news detection datasets. It is modular, extensible, and aims to empower users in content manipulation and delivery.
README:
UglyFeed is a simple application designed to retrieve, aggregate, filter, rewrite, evaluate and serve content (RSS feeds) written by a large language model. This repository provides the code, the documentation, a FAQ page and some optional scripts to evaluate the generated content.


![]()
![]()



- 📡 Retrieve RSS feeds
- 🧮 Aggregate feeds items by similarity
- ✨ Rewrite content using LLM API
- 💾 Save rewritten feeds to JSON files
- 🔁 Convert JSON to valid RSS feed
- 🌐 Serve XML feed via HTTP server
- 🌎 Deploy XML feed to GitHub or GitLab
- 📈 Evaluate generated content
- 🖥️ Web UI based on Streamlit
- 📰 RSS test feeds available
- 🤖 Same codebase for all releases
- 🛑 Simple post-filter moderation
- ➡️ Translate feeds into your own language
- 📝 Tons of prompts ready to use
- 🌎 Internet connection
- 🐳 Docker
- ✨ LLM API
- 📲 RSS reader
Supported API and models
- OpenAI API (
gpt-3.5-turbo,gpt-4,gpt-4o) - Ollama API (all models like
llama3,phi3,qwen2) - Groq API (
llama3-8b-8192,llama3-70b-8192,gemma-7b-it,mixtral-8x7b-32768) - Anthropic API (
claude-3-haiku-20240307,claude-3-sonnet-20240229,claude-3-opus-20240229)
You can use your own models by running a compatible OpenAI LLM server. You must change the OpenAI API url parameter.
To start the UglyFeed app, use the following docker run command:
docker run -p 8001:8001 -p 8501:8501 -v /path/to/local/feeds.txt:/app/input/feeds.txt -v /path/to/local/config.yaml:/app/config.yaml fabriziosalmi/uglyfeed:latestIn the Configuration page (or by manually editing the config.yaml file) you will find all configuration options. You must change at least the source feeds you want to aggregate, the LLM API and model to use to rewrite the aggregated feeds. You can then retrieve the final uglyfeed.xml feed in many ways:
- local filesystem
- download from web UI
- HTTP server url
- HTTPS GitHub CDN url
You can easily extend it to send it to cms, notification or messaging systems.
Execute all scripts in the Run scripts page easily by clicking on the button Run main.py, llm_processor.py, json2rss.py sequentially.
You can check for logs, errors and informational messages.
Once all scripts completed go to the View and Serve XML page where you can view and download the generated XML feed. If you start the HTTP server you can access to the XML url at http://container_ip:8001/uglyfeed.xml
Once all scripts completed go to the Deploy page where you can push the final rewritten XML file to the configured GitHub/GitLab repository, the public XML URL to use by RSS readers is returned for each enabled platform.
Please refer to the extended documentation to better understand how to get the best from this application.
The project can be easily customized to fit several use cases:
- Smart Content Curation: Create bespoke newsfeeds tailored to niche interests, blending articles from diverse sources into a captivating, engaging narrative.
- Dynamic Blog Generation: Automate blog post creation by rewriting and enhancing existing articles, optimizing them for readability and SEO.
- Interactive Educational Tools: Develop AI-driven study aids that summarize and rephrase academic papers or textbooks, making complex topics more accessible and fun.
- Personalized Reading Experiences: Craft custom reading lists that adapt to user preferences, offering fresh perspectives on favorite topics.
- Brand Monitoring: Aggregate and summarize brand mentions across the web, providing concise, actionable insights for marketing teams.
- Multilingual Content Delivery: Automatically translate and rewrite content from international sources, broadening the scope of accessible information.
- Enhanced RSS Feeds: Offer enriched RSS feeds that summarize, evaluate, and filter content, providing users with high-quality, relevant updates.
- Creative Writing Assistance: Assist writers by generating rewritten drafts of their work, helping overcome writer's block and sparking new ideas.
- Content Repurposing: Transform long-form content into shorter, more digestible formats like infographics, slideshows, and social media snippets.
- Fake News Detection Datasets: Generate datasets by rewriting news articles for use in training models to recognize and combat fake news.
Feel free to open issues or submit pull requests. Any contributions are welcome!
I started this project to experiment, learn, and contribute to the open-source community. I am grateful for the support received so far 🙏
Here some improvements I am still working on:
- overall code improvements and tests
- generate media from rewritten content
- here something i forgot 😅
It is crucial to acknowledge the potential misuse of AI language models by this tool. The use of adversarial prompts and models can easily lead to the creation of misleading content. This application should not be used with the intent to deceive or mislead others. Be a responsible user and prioritize ethical practices when utilizing language models and AI technologies.
This project is licensed under the AGPL3 License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for UglyFeed
Similar Open Source Tools
UglyFeed
UglyFeed is a simple Python application designed to retrieve, aggregate, filter, rewrite, evaluate, and serve content (RSS feeds) written by a large language model. It provides features such as retrieving RSS feeds, aggregating feed items by similarity, rewriting content using various APIs, saving rewritten feeds to JSON files, converting JSON to valid RSS feed, serving XML feed via an HTTP server, deploying XML feed to GitHub or GitLab, and evaluating generated content. The tool can be used for smart content curation, dynamic blog generation, interactive educational tools, personalized reading experiences, brand monitoring, multilingual content delivery, enhanced RSS feeds, creative writing assistance, content repurposing, and fake news detection datasets. It is modular, extensible, and aims to empower users in content manipulation and delivery.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

Director
Director is a framework to build video agents that can reason through complex video tasks like search, editing, compilation, generation, etc. It enables users to summarize videos, search for specific moments, create clips instantly, integrate GenAI projects and APIs, add overlays, generate thumbnails, and more. Built on VideoDB's 'video-as-data' infrastructure, Director is perfect for developers, creators, and teams looking to simplify media workflows and unlock new possibilities.
LLM-Zero-to-Hundred
LLM-Zero-to-Hundred is a repository showcasing various applications of LLM chatbots and providing insights into training and fine-tuning Language Models. It includes projects like WebGPT, RAG-GPT, WebRAGQuery, LLM Full Finetuning, RAG-Master LLamaindex vs Langchain, open-source-RAG-GEMMA, and HUMAIN: Advanced Multimodal, Multitask Chatbot. The projects cover features like ChatGPT-like interaction, RAG capabilities, image generation and understanding, DuckDuckGo integration, summarization, text and voice interaction, and memory access. Tutorials include LLM Function Calling and Visualizing Text Vectorization. The projects have a general structure with folders for README, HELPER, .env, configs, data, src, images, and utils.
Foxel
Foxel is a highly extensible private cloud storage solution for individuals and teams, featuring AI-powered semantic search. It offers unified file management, pluggable storage backends, semantic search capabilities, built-in file preview, permissions and sharing options, and a task processing center. Users can easily manage files, search content within unstructured data, preview various file types, share files, and process tasks asynchronously. Foxel is designed to centralize file management and enhance search capabilities for users.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
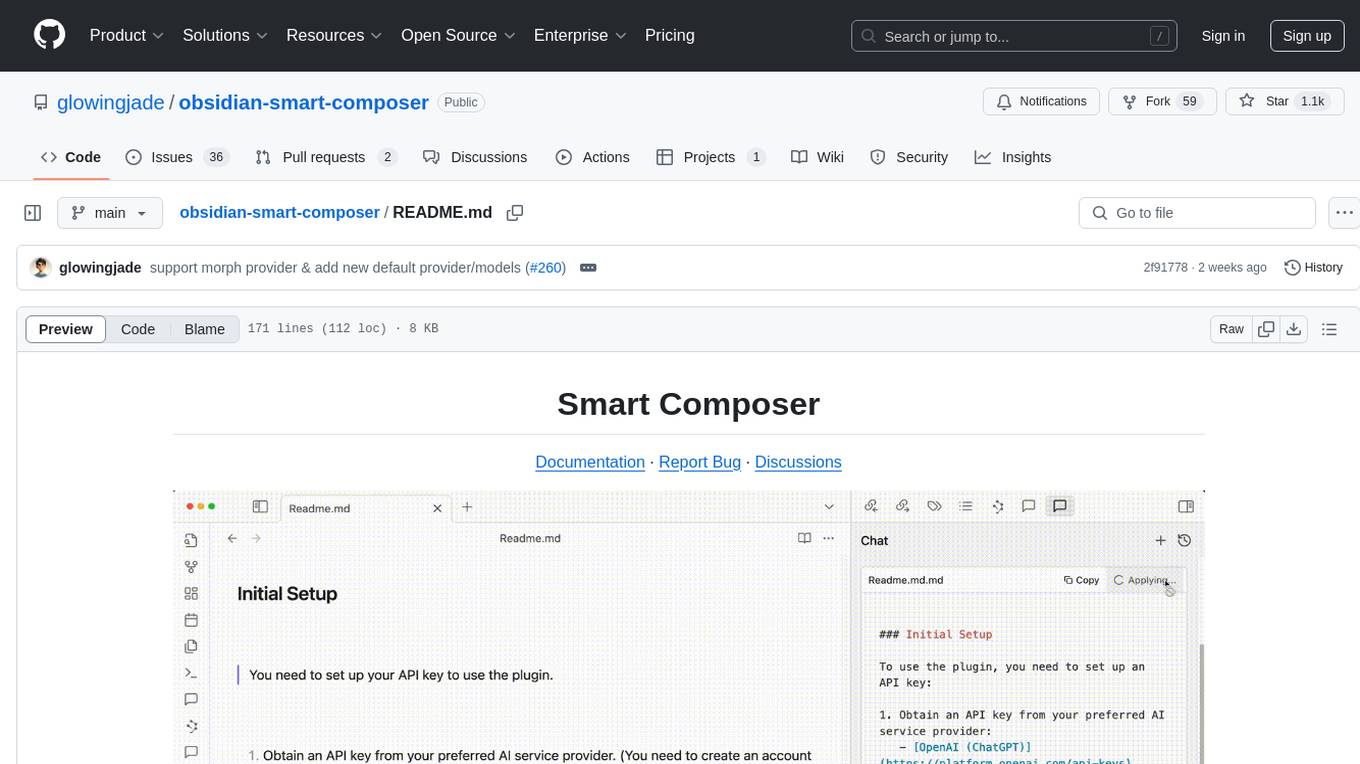
obsidian-smart-composer
Smart Composer is an Obsidian plugin that enhances note-taking and content creation by integrating AI capabilities. It allows users to efficiently write by referencing their vault content, providing contextual chat with precise context selection, multimedia context support for website links and images, document edit suggestions, and vault search for relevant notes. The plugin also offers features like custom model selection, local model support, custom system prompts, and prompt templates. Users can set up the plugin by installing it through the Obsidian community plugins, enabling it, and configuring API keys for supported providers like OpenAI, Anthropic, and Gemini. Smart Composer aims to streamline the writing process by leveraging AI technology within the Obsidian platform.
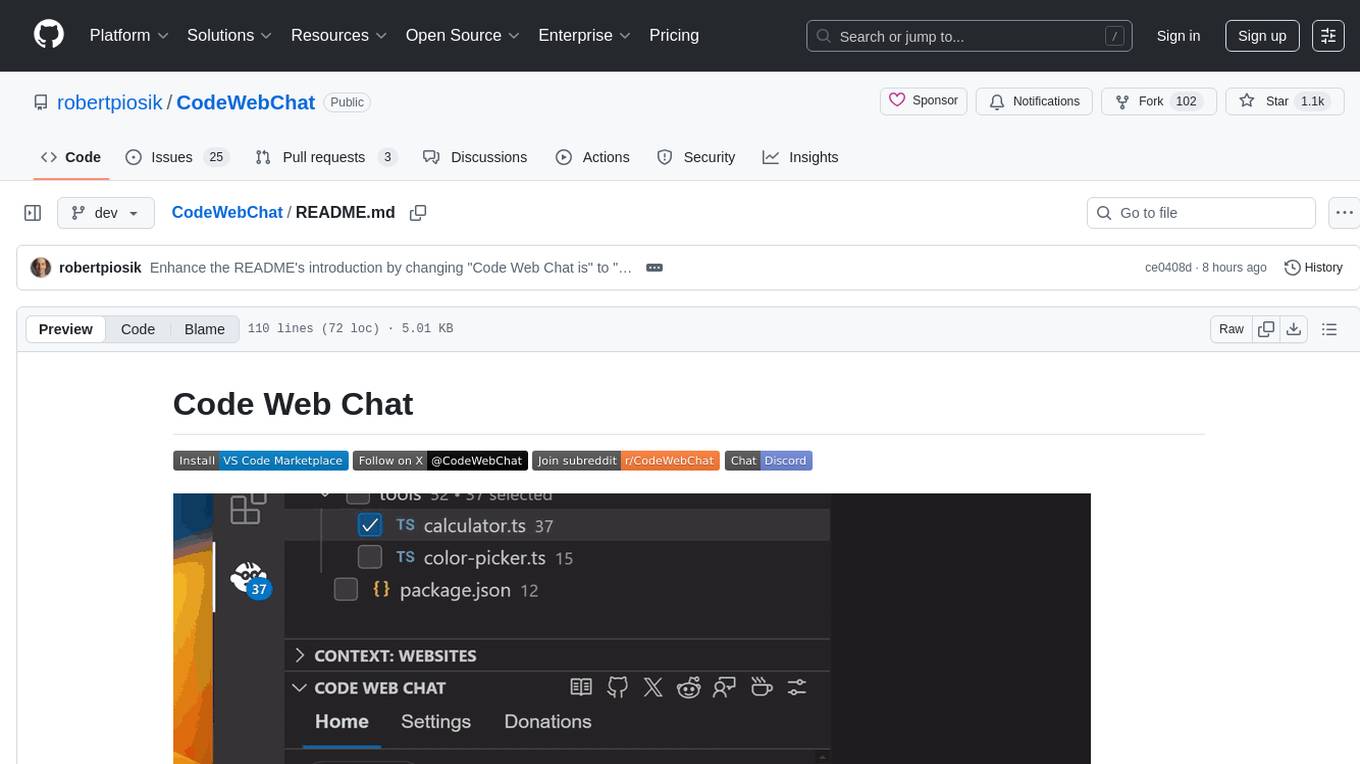
CodeWebChat
Code Web Chat is a versatile, free, and open-source AI pair programming tool with a unique web-based workflow. Users can select files, type instructions, and initialize various chatbots like ChatGPT, Gemini, Claude, and more hands-free. The tool helps users save money with free tiers and subscription-based billing and save time with multi-file edits from a single prompt. It supports chatbot initialization through the Connector browser extension and offers API tools for code completions, editing context, intelligent updates, and commit messages. Users can handle AI responses, code completions, and version control through various commands. The tool is privacy-focused, operates locally, and supports any OpenAI-API compatible provider for its utilities.
wordlift-plugin
WordLift is a plugin that helps online content creators organize posts and pages by adding facts, links, and media to build beautifully structured websites for both humans and search engines. It allows users to create, own, and publish their own knowledge graph, and publishes content as Linked Open Data following Tim Berners-Lee's Linked Data Principles. The plugin supports writers by providing trustworthy and contextual facts, enriching content with images, links, and interactive visualizations, keeping readers engaged with relevant content recommendations, and producing content compatible with schema.org markup for better indexing and display on search engines. It also offers features like creating a personal Wikipedia, publishing metadata to share and distribute content, and supporting content tagging for better SEO.
Cerebr
Cerebr is an intelligent AI assistant browser extension designed to enhance work efficiency and learning experience. It integrates powerful AI capabilities from various sources to provide features such as smart sidebar, multiple API support, cross-browser API configuration synchronization, comprehensive Q&A support, elegant rendering, real-time response, theme switching, and more. With a minimalist design and focus on delivering a seamless, distraction-free browsing experience, Cerebr aims to be your second brain for deep reading and understanding.

crawlee
Crawlee is a web scraping and browser automation library that helps you build reliable scrapers quickly. Your crawlers will appear human-like and fly under the radar of modern bot protections even with the default configuration. Crawlee gives you the tools to crawl the web for links, scrape data, and store it to disk or cloud while staying configurable to suit your project's needs.
For similar tasks
UglyFeed
UglyFeed is a simple Python application designed to retrieve, aggregate, filter, rewrite, evaluate, and serve content (RSS feeds) written by a large language model. It provides features such as retrieving RSS feeds, aggregating feed items by similarity, rewriting content using various APIs, saving rewritten feeds to JSON files, converting JSON to valid RSS feed, serving XML feed via an HTTP server, deploying XML feed to GitHub or GitLab, and evaluating generated content. The tool can be used for smart content curation, dynamic blog generation, interactive educational tools, personalized reading experiences, brand monitoring, multilingual content delivery, enhanced RSS feeds, creative writing assistance, content repurposing, and fake news detection datasets. It is modular, extensible, and aims to empower users in content manipulation and delivery.
For similar jobs
UglyFeed
UglyFeed is a simple Python application designed to retrieve, aggregate, filter, rewrite, evaluate, and serve content (RSS feeds) written by a large language model. It provides features such as retrieving RSS feeds, aggregating feed items by similarity, rewriting content using various APIs, saving rewritten feeds to JSON files, converting JSON to valid RSS feed, serving XML feed via an HTTP server, deploying XML feed to GitHub or GitLab, and evaluating generated content. The tool can be used for smart content curation, dynamic blog generation, interactive educational tools, personalized reading experiences, brand monitoring, multilingual content delivery, enhanced RSS feeds, creative writing assistance, content repurposing, and fake news detection datasets. It is modular, extensible, and aims to empower users in content manipulation and delivery.

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.