Best AI tools for< Audiobook Producer >
Infographic
10 - AI tool Sites
OddBooks
OddBooks is an AI-powered tool that transforms books into scenarios, enabling users to create various content types such as audiobooks, webtoons, animations, and movies. It simplifies the process of producing derivative works by extracting character names, emotions, spatial and sound keywords, and inferring character personalities from the text. With OddBooks, users can easily generate scripts for secondary works in a fraction of the time it would traditionally take, revolutionizing the scenario creation process.
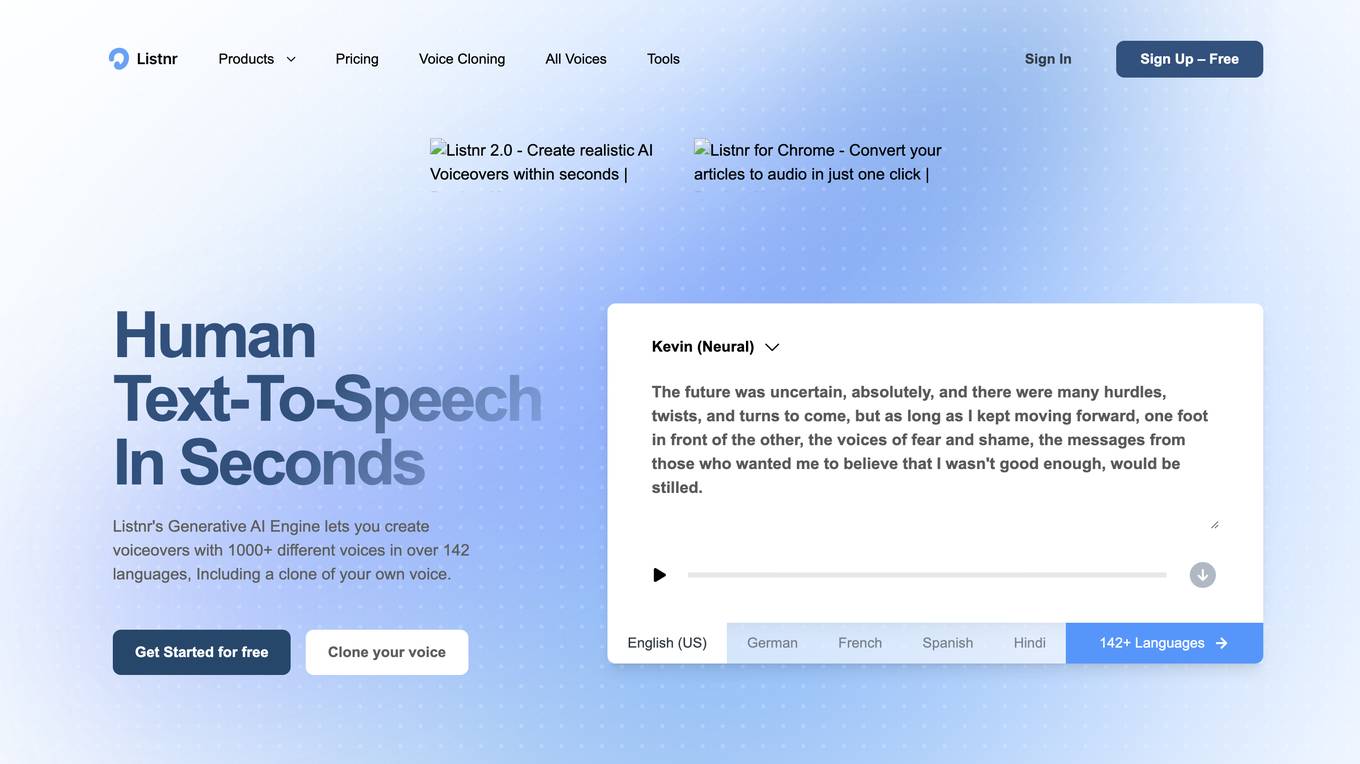
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
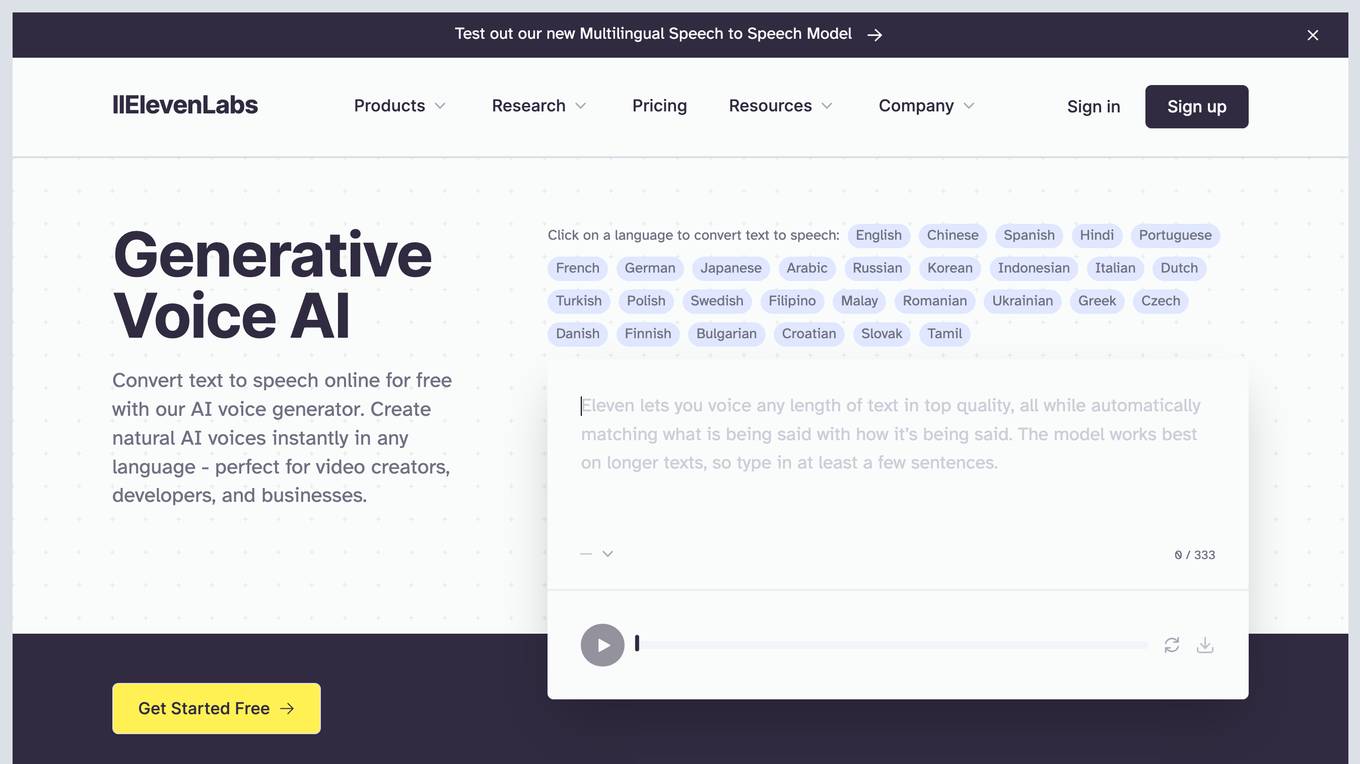
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
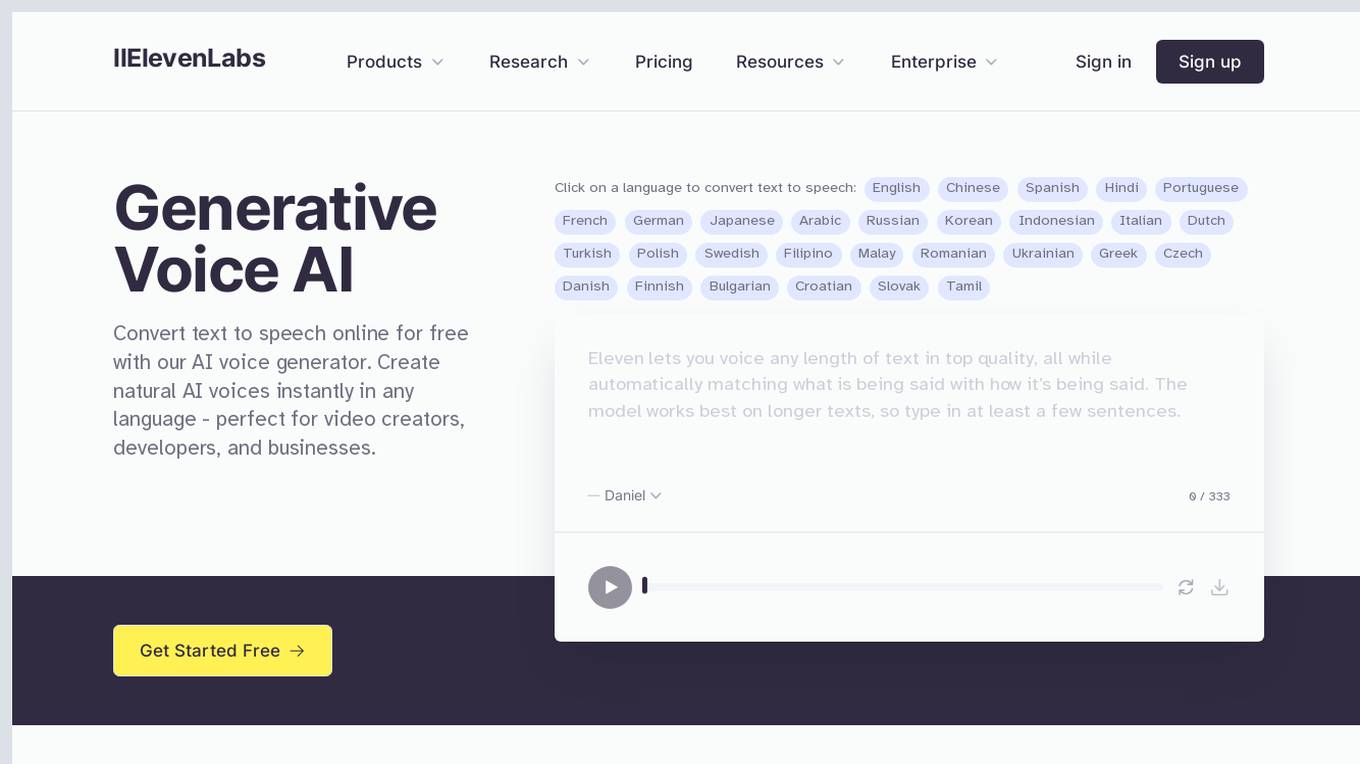
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
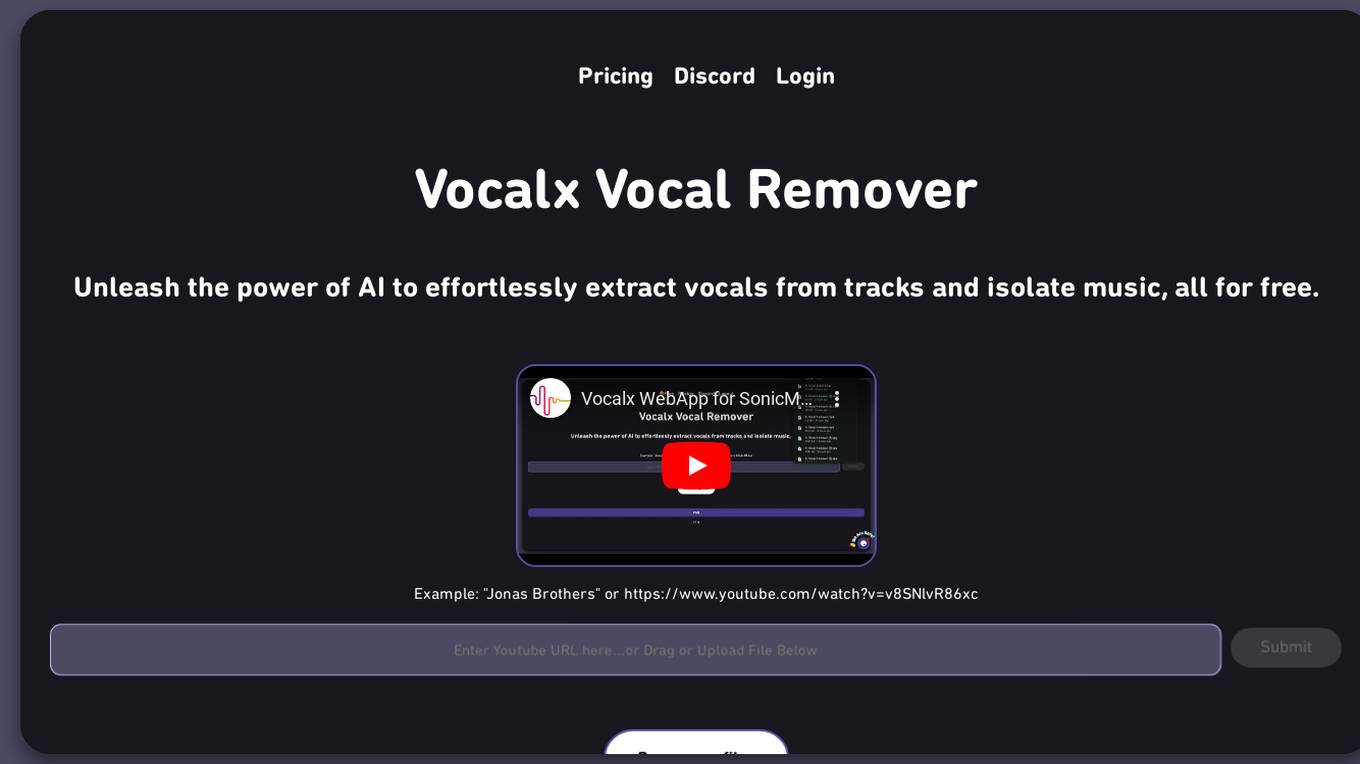
Vocalx
Vocalx is an AI-powered online tool that converts text into natural-sounding speech. It utilizes advanced speech synthesis technology to generate lifelike voices for various applications. Users can easily create audio content from written text, making it ideal for content creators, educators, and businesses looking to enhance their multimedia offerings. With Vocalx, you can customize the voice, tone, and speed of the generated speech to suit your needs. The tool supports multiple languages and accents, providing a versatile solution for voiceover projects, audiobooks, podcasts, and more.
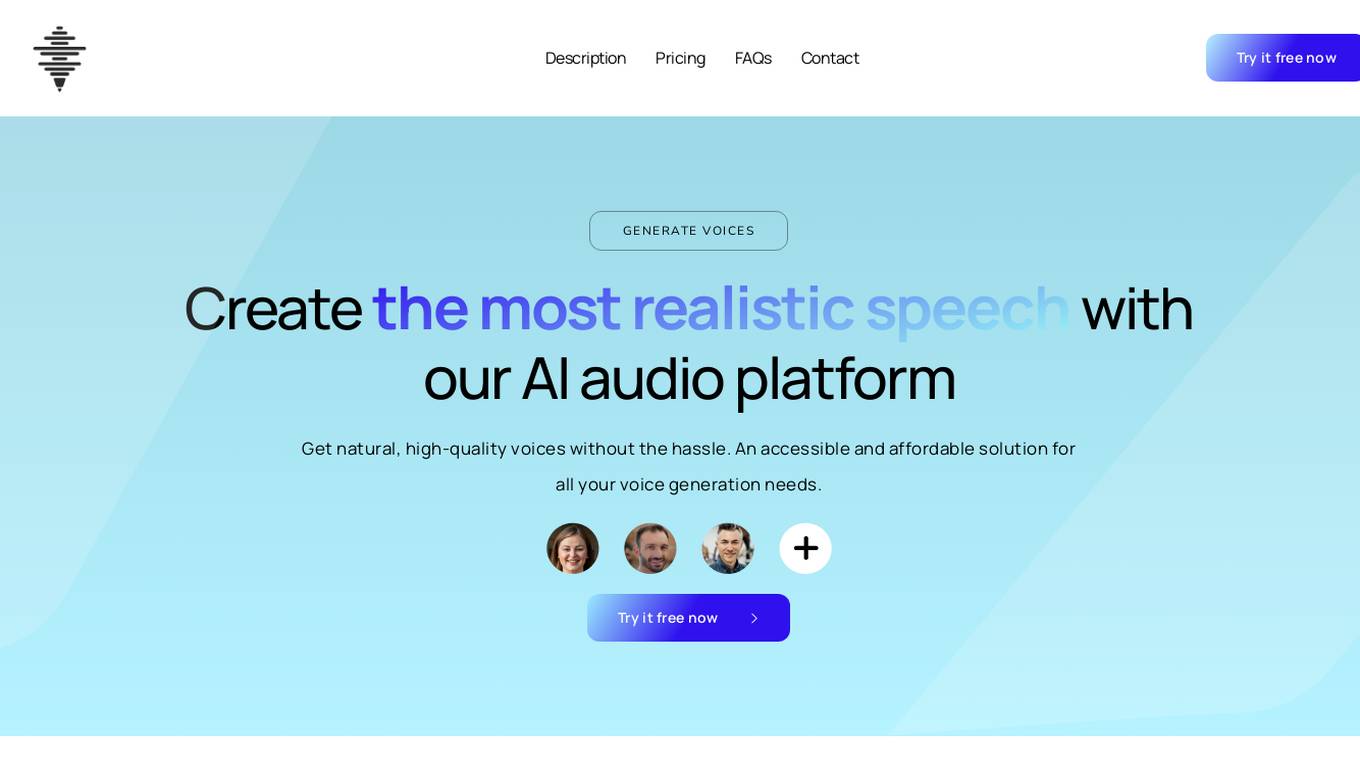
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
Auphonic
Auphonic is an AI-powered audio post-production web tool designed to help users achieve professional-quality audio results effortlessly. It offers a range of features such as Intelligent Leveler, Noise & Reverb Reduction, Filtering & AutoEQ, Cut Filler Words and Silence, Multitrack Algorithms, Loudness Specifications, Speech2Text & Automatic Shownotes, Video Support, Metadata & Chapters, and more. Auphonic is widely used by podcasters, educators, content creators, and audiobook producers to enhance their audio content and streamline their workflows. With its intuitive interface and advanced algorithms, Auphonic simplifies the audio editing process and ensures consistent audio quality across different platforms.
Pozotron Studio
Pozotron Studio is an AI-powered software suite designed to simplify scripted audio production processes for audiobooks, voiceovers, and other audio projects. It leverages state-of-the-art technology to enhance efficiency and accuracy in audio production, while allowing users to focus on creativity and core features. The tool automates tasks such as generating DAW marker files, pronunciation research, and script preparation, providing peace of mind about accuracy and highlighting errors for easy correction.

VO3 AI
VO3 AI is an innovative AI video generator powered by Veo3 AI technology. It transforms scripts, ideas, or prompts into immersive videos with high-fidelity motion and storytelling. Users can create cinematic videos in minutes, customize visuals, and download finished clips in popular formats. The platform offers advanced features like high-fidelity visuals, multi-style rendering, dynamic scene understanding, and fine-grained controls. VO3 AI caters to various industries such as marketing, education, and entertainment, providing a user-centric interface for both creatives and non-technical users.
FlowSpeech
FlowSpeech is an AI-powered Text To Speech studio that offers lifelike human voices, emotion and pause control, and seamless multi-speaker casting for professional audio generation. It understands context, integrates pause and emotion control, and delivers TTS audio that sounds like a real human. The AI-driven engine analyzes sentiment, timing, and nuance of scripts, allowing for precise emotion delivery. Users can add custom emotions and accents, control pauses, and select from 30 distinct voices across different styles. With support for 70+ languages and the ability to process up to 200k characters per render, FlowSpeech is a versatile tool for content creators, marketers, and educators.
4 - Open Source Tools

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.
alexandria-audiobook
Alexandria Audiobook Generator is a tool that transforms any book or novel into a fully-voiced audiobook using AI-powered script annotation and text-to-speech. It features a built-in Qwen3-TTS engine with batch processing and a browser-based editor for fine-tuning every line before final export. The tool offers AI-powered pipeline for automatic script annotation, smart chunking, and context preservation. It also provides voice generation capabilities with built-in TTS engine, multi-language support, custom voices, voice cloning, and LoRA voice training. The web UI editor allows users to edit, preview, and export the audiobook. Export options include combined audiobook, individual voicelines, and Audacity export for DAW editing.
2 - OpenAI Gpts