
audiobook-creator
Audiobook Creator is an open-source tool that converts books (EPUB, PDF, TXT) into fully voiced audiobooks with intelligent character voice attribution. It uses NLP, LLMs, and Kokoro TTS to generate engaging, multi-voice audiobooks. Features include text cleaning, character identification, and customizable narration. Licensed under GPL-3.0.
Stars: 211
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.
README:
Audiobook Creator is an open-source project designed to convert books in various text formats (e.g., EPUB, PDF, etc.) into fully voiced audiobooks with intelligent character voice attribution. It leverages modern Natural Language Processing (NLP), Large Language Models (LLMs), and Text-to-Speech (TTS) technologies to create an engaging and dynamic audiobook experience. The project is licensed under the GNU General Public License v3.0 (GPL-3.0), ensuring that it remains free and open for everyone to use, modify, and distribute.
Sample multi voice audio for a short story : https://audio.com/prakhar-sharma/audio/generated-sample-multi-voice-audiobook
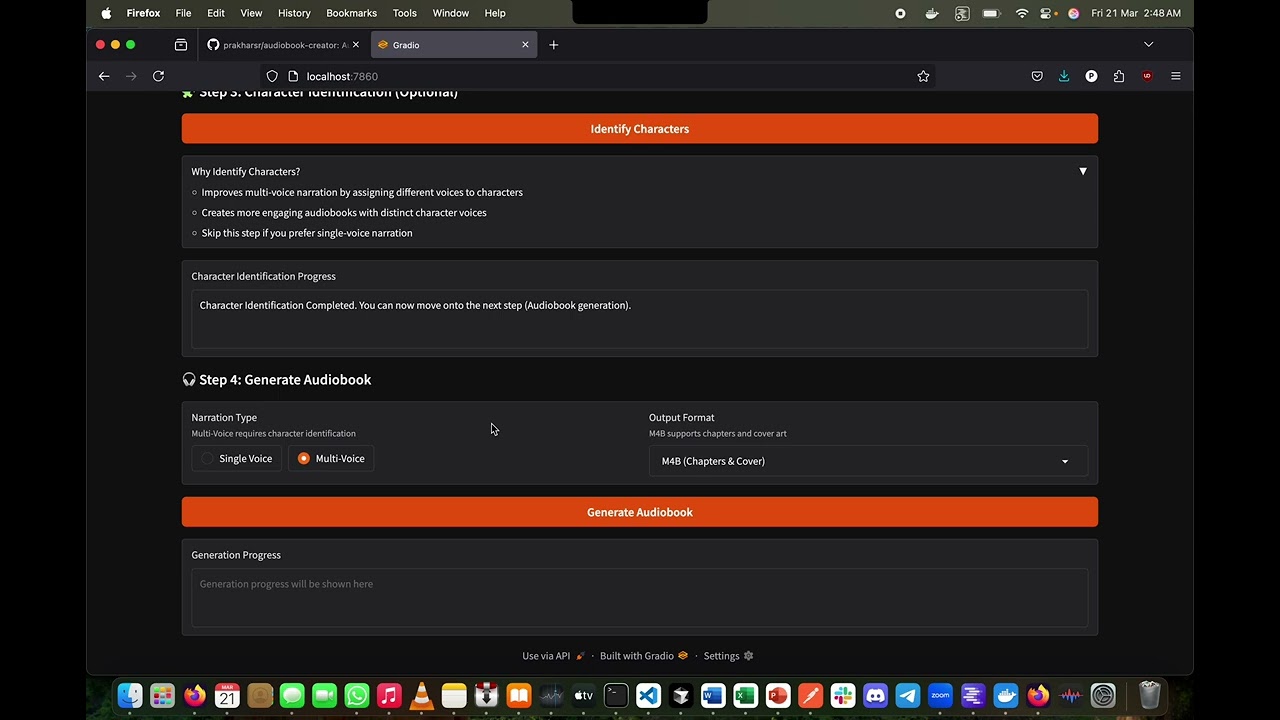
Watch the demo video:
The project consists of three main components:
-
Text Cleaning and Formatting (
book_to_txt.py):- Extracts and cleans text from a book file (e.g.,
book.epub). - Normalizes special characters, fixes line breaks, and corrects formatting issues such as unterminated quotes or incomplete lines.
- Extracts the main content between specified markers (e.g., "PROLOGUE" and "ABOUT THE AUTHOR").
- Outputs the cleaned text to
converted_book.txt.
- Extracts and cleans text from a book file (e.g.,
-
Character Identification and Metadata Generation (
identify_characters_and_output_book_to_jsonl.py):- Identifies characters in the text using Named Entity Recognition (NER) with the GLiNER model.
- Assigns gender and age scores to characters using an LLM via an OpenAI-compatible API.
- Outputs two files:
-
speaker_attributed_book.jsonl: Each line of text annotated with the identified speaker. -
character_gender_map.json: Metadata about characters, including name, age, gender, and gender score.
-
-
Audiobook Generation (
generate_audiobook.py):- Converts the cleaned text (
converted_book.txt) or speaker-attributed text (speaker_attributed_book.jsonl) into an audiobook using the Kokoro TTS model (Hexgrad/Kokoro-82M). - Offers two narration modes:
- Single-Voice: Uses a single voice for narration and another voice for dialogues for the entire book.
- Multi-Voice: Assigns different voices to characters based on their gender scores.
- Saves the audiobook in the selected output format to
generated_audiobooks/audiobook.{output_format}.
- Converts the cleaned text (
- Gradio UI App: Create audiobooks easily with an easy to use, intuitive UI made with Gradio.
- M4B Audiobook Creation: Creates compatible audiobooks with covers, metadata, chapter timestamps etc. in M4B format.
- Multi-Format Input Support: Converts books from various formats (EPUB, PDF, etc.) into plain text.
- Multi-Format Output Support: Supports various output formats: AAC, M4A, MP3, WAV, OPUS, FLAC, PCM, M4B.
- Docker Support: Use pre-built docker images/ build using docker compose to save time and for a smooth user experience.
- Text Cleaning: Ensures the book text is well-formatted and readable.
- Character Identification: Identifies characters and infers their attributes (gender, age) using advanced NLP techniques.
- Customizable Audiobook Narration: Supports single-voice or multi-voice narration for enhanced listening experiences.
- Progress Tracking: Includes progress bars and execution time measurements for efficient monitoring.
- Open Source: Licensed under GPL v3.
Expand
-
sample_book_and_audio/The Adventure of the Lost Treasure - Prakhar Sharma.epub: A sample short story in epub format as a starting point. -
sample_book_and_audio/The Adventure of the Lost Treasure - Prakhar Sharma.pdf: A sample short story in pdf format as a starting point. -
sample_book_and_audio/The Adventure of the Lost Treasure - Prakhar Sharma.txt: A sample short story in txt format as a starting point. -
sample_book_and_audio/converted_book.txt: The cleaned output after text processing. -
sample_book_and_audio/speaker_attributed_book.jsonl: The generated speaker-attributed JSONL file. -
sample_book_and_audio/character_gender_map.json: The generated character metadata. -
sample_book_and_audio/sample_multi_voice_audiobook.m4b: The generated sample multi-voice audiobook in M4B format with cover and chapters from the story. -
sample_book_and_audio/sample_multi_voice_audio.mp3: The generated sample multi-voice MP3 audio file from the story. -
sample_book_and_audio/sample_single_voice_audio.mp3: The generated sample single-voice MP3 audio file from the story.
-
Install Docker
-
Make sure host networking is enabled in your docker setup : https://docs.docker.com/engine/network/drivers/host/. Host networking is currently supported in Linux and in docker desktop. To use with docker desktop, follow these steps
-
Set up your LLM and expose an OpenAI-compatible endpoint (e.g., using LM Studio with
phi-4). -
Set up the Kokoro TTS model via Kokoro-FastAPI. To get started, run the docker image using the following command:
For CUDA based GPU inference (Apple Silicon GPUs currently not supported, use CPU based inference instead)
docker run \ --name kokoro_service \ --restart always \ --network host \ --gpus all \ ghcr.io/remsky/kokoro-fastapi-gpu:v0.2.2
For CPU based inference
docker run \ --name kokoro_service \ --restart always \ --network host \ ghcr.io/remsky/kokoro-fastapi-cpu:v0.2.2
-
Create a .env file from .env_sample and configure it with the correct values. Make sure you follow the instructions mentioned at the top of .env_sample to avoid errors.
cp .env_sample .env
-
After this, choose between the below options for the next step to run the audiobook creator app:
Quickest Start (docker run)
-
Make sure your .env is configured correctly and your LLM and Kokoro FastAPI are running. In the same folder where .env is present, run the below command
-
Choose between the types of inference:
For CUDA based GPU inference (Apple Silicon GPUs currently not supported, use CPU based inference instead)
docker run \ --name audiobook_creator \ --restart always \ --network host \ --gpus all \ --env-file .env \ -v model_cache:/app/model_cache \ ghcr.io/prakharsr/audiobook_creator_gpu:v1.1
For CPU based inference
docker run \ --name audiobook_creator \ --restart always \ --network host \ --env-file .env \ -v model_cache:/app/model_cache \ ghcr.io/prakharsr/audiobook_creator_cpu:v1.1
-
Wait for the models to download and then navigate to http://localhost:7860 for the Gradio UI
Quick Start (docker compose)
-
Clone the repository
git clone https://github.com/prakharsr/audiobook-creator.git cd audiobook-creator -
Make sure your .env is configured correctly and your LLM is running
-
If Kokoro docker container is already running, you can either stop and remove it or comment the kokoro_fastapi service in docker compose. If its not running then it will automatically start when you run docker compose up command
-
Copy the .env file into the audiobook-creator folder
-
Choose between the types of inference:
For CUDA based GPU inference (Apple Silicon GPUs currently not supported, use CPU based inference instead)
cd docker/gpu docker compose up --buildFor CPU based inference
cd docker/cpu docker compose up --build -
Wait for the models to download and then navigate to http://localhost:7860 for the Gradio UI
Direct run (via uv)
- Clone the repository
git clone https://github.com/prakharsr/audiobook-creator.git cd audiobook-creator - Make sure your .env is configured correctly and your LLM and Kokoro FastAPI are running
- Copy the .env file into the audiobook-creator folder
- Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh - Create a virtual environment with Python 3.12:
uv venv --python 3.12
- Activate the virtual environment:
source .venv/bin/activate - Install Pip 24.0:
uv pip install pip==24.0
- Install dependencies (choose CPU or GPU version):
uv pip install -r requirements_cpu.txt
uv pip install -r requirements_gpu.txt
- Upgrade version of six to avoid errors:
uv pip install --upgrade six==1.17.0
- Install calibre (Optional dependency, needed if you need better text decoding capabilities, wider compatibility and want to create M4B audiobook). Also make sure that calibre is present in your PATH. For MacOS, do the following to add it to the PATH:
deactivate echo 'export PATH="/Applications/calibre.app/Contents/MacOS:$PATH"' >> .venv/bin/activate source .venv/bin/activate
- Install ffmpeg (Needed for audio output format conversion and if you want to create M4B audiobook)
- In the activated virtual environment, run
uvicorn app:app --host 0.0.0.0 --port 7860to run the Gradio app. After the app has started, navigate tohttp://127.0.0.1:7860in the browser.
-
Planned future enhancements:
- ⏳ Add support for choosing between various languages which are currently supported by Kokoro.
- ⏳ Add support for Zonos, Models: https://huggingface.co/Zyphra/Zonos-v0.1-hybrid, https://huggingface.co/Zyphra/Zonos-v0.1-transformer. Zonos supports voices with a wide range of emotions so adding that as a feature will greatly enhance the listening experience.
- ✅ Give choice to the user to select the voice in which they want the book to be read (male voice/ female voice)
- ✅ Add support for running the app through docker.
- ✅ Create UI using Gradio.
- ✅ Try different voice combinations using
generate_audio_samples.pyand update thekokoro_voice_map.jsonto use better voices. - ✅ Add support for the these output formats: AAC, M4A, MP3, WAV, OPUS, FLAC, PCM, M4B.
- ✅ Add support for using calibre to extract the text and metadata for better formatting and wider compatibility.
- ✅ Add artwork and chapters, and convert audiobooks to M4B format for better compatibility.
- ✅ Give option to the user for selecting the audio generation format.
- ✅ Add extended pause when chapters end once chapter recognition is in place.
- ✅ Improve single-voice narration with a different dialogue voice from the narrator's voice.
- ✅ Read out only the dialogue in a different voice instead of the entire line in that voice.
For issues or questions, open an issue on the GitHub repository.
This project is licensed under the GNU General Public License v3.0 (GPL-3.0). See the LICENSE file for more details.
Contributions are welcome! Please open an issue or pull request to fix a bug or add features.
If you find this project useful and would like to support my work, consider donating:
PayPal
Enjoy creating audiobooks with this project! If you find it helpful, consider giving it a ⭐ on GitHub.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for audiobook-creator
Similar Open Source Tools
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.

bedrock-claude-chatbot
Bedrock Claude ChatBot is a Streamlit application that provides a conversational interface for users to interact with various Large Language Models (LLMs) on Amazon Bedrock. Users can ask questions, upload documents, and receive responses from the AI assistant. The app features conversational UI, document upload, caching, chat history storage, session management, model selection, cost tracking, logging, and advanced data analytics tool integration. It can be customized using a config file and is extensible for implementing specialized tools using Docker containers and AWS Lambda. The app requires access to Amazon Bedrock Anthropic Claude Model, S3 bucket, Amazon DynamoDB, Amazon Textract, and optionally Amazon Elastic Container Registry and Amazon Athena for advanced analytics features.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
TypeGPT
TypeGPT is a Python application that enables users to interact with ChatGPT or Google Gemini from any text field in their operating system using keyboard shortcuts. It provides global accessibility, keyboard shortcuts for communication, and clipboard integration for larger text inputs. Users need to have Python 3.x installed along with specific packages and API keys from OpenAI for ChatGPT access. The tool allows users to run the program normally or in the background, manage processes, and stop the program. Users can use keyboard shortcuts like `/ask`, `/see`, `/stop`, `/chatgpt`, `/gemini`, `/check`, and `Shift + Cmd + Enter` to interact with the application in any text field. Customization options are available by modifying files like `keys.txt` and `system_prompt.txt`. Contributions are welcome, and future plans include adding support for other APIs and a user-friendly GUI.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
voice-chat-ai
Voice Chat AI is a project that allows users to interact with different AI characters using speech. Users can choose from various characters with unique personalities and voices, and have conversations or role play with them. The project supports OpenAI, xAI, or Ollama language models for chat, and provides text-to-speech synthesis using XTTS, OpenAI TTS, or ElevenLabs. Users can seamlessly integrate visual context into conversations by having the AI analyze their screen. The project offers easy configuration through environment variables and can be run via WebUI or Terminal. It also includes a huge selection of built-in characters for engaging conversations.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.
aiogram_dialog
Aiogram Dialog is a framework for developing interactive messages and menus in Telegram bots, inspired by Android SDK. It allows splitting data retrieval, rendering, and action processing, creating reusable widgets, and designing bots with a focus on user experience. The tool supports rich text rendering, automatic message updating, multiple dialog stacks, inline keyboard widgets, stateful widgets, various button layouts, media handling, transitions between windows, and offline HTML-preview for messages and transitions diagram.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.
testzeus-hercules
Hercules is the world’s first open-source testing agent designed to handle the toughest testing tasks for modern web applications. It turns simple Gherkin steps into fully automated end-to-end tests, making testing simple, reliable, and efficient. Hercules adapts to various platforms like Salesforce and is suitable for CI/CD pipelines. It aims to democratize and disrupt test automation, making top-tier testing accessible to everyone. The tool is transparent, reliable, and community-driven, empowering teams to deliver better software. Hercules offers multiple ways to get started, including using PyPI package, Docker, or building and running from source code. It supports various AI models, provides detailed installation and usage instructions, and integrates with Nuclei for security testing and WCAG for accessibility testing. The tool is production-ready, open core, and open source, with plans for enhanced LLM support, advanced tooling, improved DOM distillation, community contributions, extensive documentation, and a bounty program.
langfuse-docs
Langfuse Docs is a repository for langfuse.com, built on Nextra. It provides guidelines for contributing to the documentation using GitHub Codespaces and local development setup. The repository includes Python cookbooks in Jupyter notebooks format, which are converted to markdown for rendering on the site. It also covers media management for images, videos, and gifs. The stack includes Nextra, Next.js, shadcn/ui, and Tailwind CSS. Additionally, there is a bundle analysis feature to analyze the production build bundle size using @next/bundle-analyzer.
For similar tasks

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.
metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
alexandria-audiobook
Alexandria Audiobook Generator is a tool that transforms any book or novel into a fully-voiced audiobook using AI-powered script annotation and text-to-speech. It features a built-in Qwen3-TTS engine with batch processing and a browser-based editor for fine-tuning every line before final export. The tool offers AI-powered pipeline for automatic script annotation, smart chunking, and context preservation. It also provides voice generation capabilities with built-in TTS engine, multi-language support, custom voices, voice cloning, and LoRA voice training. The web UI editor allows users to edit, preview, and export the audiobook. Export options include combined audiobook, individual voicelines, and Audacity export for DAW editing.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
AivisSpeech-Engine
AivisSpeech-Engine is a powerful open-source tool for speech recognition and synthesis. It provides state-of-the-art algorithms for converting speech to text and text to speech. The tool is designed to be user-friendly and customizable, allowing developers to easily integrate speech capabilities into their applications. With AivisSpeech-Engine, users can transcribe audio recordings, create voice-controlled interfaces, and generate natural-sounding speech output. Whether you are building a virtual assistant, developing a speech-to-text application, or experimenting with voice technology, AivisSpeech-Engine offers a comprehensive solution for all your speech processing needs.
learnhouse
LearnHouse is an open-source platform that allows anyone to easily provide world-class educational content. It supports various content types, including dynamic pages, videos, and documents. The platform is still in early development and should not be used in production environments. However, it offers several features, such as dynamic Notion-like pages, ease of use, multi-organization support, support for uploading videos and documents, course collections, user management, quizzes, course progress tracking, and an AI-powered assistant for teachers and students. LearnHouse is built using various open-source projects, including Next.js, TailwindCSS, Radix UI, Tiptap, FastAPI, YJS, PostgreSQL, LangChain, and React.
For similar jobs

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.
pyht
pyht is a Python SDK for the PlayHT's AI Text-to-Speech API, allowing users to convert text into high-quality audio streams in humanlike voice. It supports real-time text-to-speech streaming, pre-built and custom voices, various audio formats, and different sample rates.
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.
alexandria-audiobook
Alexandria Audiobook Generator is a tool that transforms any book or novel into a fully-voiced audiobook using AI-powered script annotation and text-to-speech. It features a built-in Qwen3-TTS engine with batch processing and a browser-based editor for fine-tuning every line before final export. The tool offers AI-powered pipeline for automatic script annotation, smart chunking, and context preservation. It also provides voice generation capabilities with built-in TTS engine, multi-language support, custom voices, voice cloning, and LoRA voice training. The web UI editor allows users to edit, preview, and export the audiobook. Export options include combined audiobook, individual voicelines, and Audacity export for DAW editing.
Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.