
ai-voice-cloning
None
Stars: 268

This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
README:
Note I do not plan on actively working on improvements/enhancements for this project, this is mainly meant to keep the repo in a working state in the case the original git.ecker goes down or necessary package changes need to be made.
That being said, some enhancements added compared to the original repo:
✔️ Possible to train in other languages
✔️ Hifigan added, allowing for faster inference at the cost of quality.
✔️ whisper-v3 added as a chooseable option for whisperx
✔️ Output conversion using RVC
This is a fork of the repo originally located here: https://git.ecker.tech/mrq/ai-voice-cloning. All of the work that was put into it to incoporate training with DLAS and inference with Tortoise belong to mrq, the author of the original ai-voice-cloning repo.
This repo works on Windows with NVIDIA GPUs and Linux running Docker with NVIDIA GPUs.
- Optional, but recommended: Install 7zip on your computer: https://www.7-zip.org/
- If you run into any extraction issues, most likely it's due to your 7zip being out-of-date OR you're using a different extractor.
- Head over to the releases tab and download the latest package on Hugging Face: https://github.com/JarodMica/ai-voice-cloning/releases/tag/v3.0
- Extract the 7zip archive.
- Open up ai-voice-cloning and then run
start.bat
If you are installing this manually, you will need:
- Python 3.11: https://www.python.org/downloads/release/python-311/
- Git: https://www.git-scm.com/downloads
- Clone the repository
git clone https://github.com/JarodMica/ai-voice-cloning.git
- Run the
setup-cuda.batfile and it will start running through all of the python packages needed- If you don't have python 3.11, it won't work and you'll need to go download it
- After it finishes, run
start.batand this will start downloading most of the models you'll need.- Some models are downloaded when you first use them. You'll incur additional downloads during generation and when training (for whisper). However, once they are finished, you won't ever have to download them again as long as you don't delete them. They are located in the
modelsfolder of the root.
- Some models are downloaded when you first use them. You'll incur additional downloads during generation and when training (for whisper). However, once they are finished, you won't ever have to download them again as long as you don't delete them. They are located in the
-
(Optional) You can opt to install whisperx for training by running
setup-whipserx.bat- Check out the whisperx github page for more details, but it's much faster for longer audio files. If you're processing one-by-one with an already split dataset, it doesn't improve speeds that much.
- Make sure the latest nvidia drivers are installed:
sudo ubuntu-drivers install - Install Docker your preferred way
Make sure your Nvidia drivers are up to date: https://www.nvidia.com/download/index.aspx
- Install WSL2 in PowerShell with
wsl --installand restart - Open PowerShell, type and enter
ubuntu. It should now load you into wsl2 - Remove the original nvidia cache key:
sudo apt-key del 7fa2af80 - Download CUDA toolkit keyring:
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb - Install keyring:
sudo dpkg -i cuda-keyring_1.1-1_all.deb - Update package list:
sudo apt-get update - Install CUDA toolkit:
sudo apt-get -y install cuda-toolkit-12-4 - Install Docker Desktop using WSL2 as the backend
- Restart
- If you wish to monitor the terminal remotely via SSH, follow this guide.
- Open PowerShell, type
ubuntu, then follow below
- Open a terminal (or Ubuntu WSL)
- Clone the repository:
git clone https://github.com/JarodMica/ai-voice-cloning.git && cd ai-voice-cloning - Build the image with
./setup-docker.sh - Start the container with
./start-docker.sh - Visit
http://localhost:7860or remotely withhttp://<ip>:7860
Checkout the YouTube video:
Watch First: https://youtu.be/WWhNqJEmF9M?si=RhUZhYersAvSZ4wf
Watch Second (RVC update): https://www.youtube.com/watch?v=7tpWH8_S8es&t=504s
Everything is pretty much the same as before if you've used this repository in the past, however, there is a new option to convert text output using rvc. Before you can use it, you will need a trained RVC .pth file that you get from RVC or online, and then you will need to place it in models/rvc_models/. Both .index and .pth files can be placed in here and they'll show up correctly in their respective dropdown menus.
To enable rvc:
- Check and enable
Show Experimental Settingsto reveal more options - Check and enable
Run the outputter audio through RVC. You will now have access to parameters you could adjust in RVC for the RVC voice model you're using.
Below are how you can update the package for the latest updates
NOTE: If there are major feature change, check the latest release to see if
update_package.batwill work. If NOT, you will need to re-download and re-extract the package from Hugging Face.
- Run the
update_package.batfile- It will clone the repo and will copy the src folder from the repo to the package.
You should be able to navigate into the folder and then pull the repo to update it.
cd ai-voice-cloning
git pull
If there are large features added, you may need to delete the venv and the re-run the setup-cuda script to make sure there are no package issues
You should be able to navigate into the folder and then pull the repo to update it, then rebuild your Docker image.
cd ai-voice-cloning
git pull
./setup-docker.sh
The terminal is your friend. Any errors or issues will pop-up in the terminal when you go to try and run, and then you can start debugging from there.
- If somewhere in the process, torch gets messed up, you may have to reinstall it. You will have to uninstall it, then reinstall it like the following. Make sure to type (Y) to confirm deletion.
.\venv\Scripts\activate.bat
pip uninstall torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
If you run into any problems, please open up a new issue on the issues tab.
setup-cuda.bat should have everything that you need for the packages to be installed. All of the different requirements files make it quite a mess in the script, but each repo has their requirements installed, and then at the end, the requirements.txt in the root is needed to change the version back to compatible versions for this repo.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-voice-cloning
Similar Open Source Tools
ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
aiarena-web
aiarena-web is a website designed for running the aiarena.net infrastructure. It consists of different modules such as core functionality, web API endpoints, frontend templates, and a module for linking users to their Patreon accounts. The website serves as a platform for obtaining new matches, reporting results, featuring match replays, and connecting with Patreon supporters. The project is licensed under GPLv3 in 2019.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.
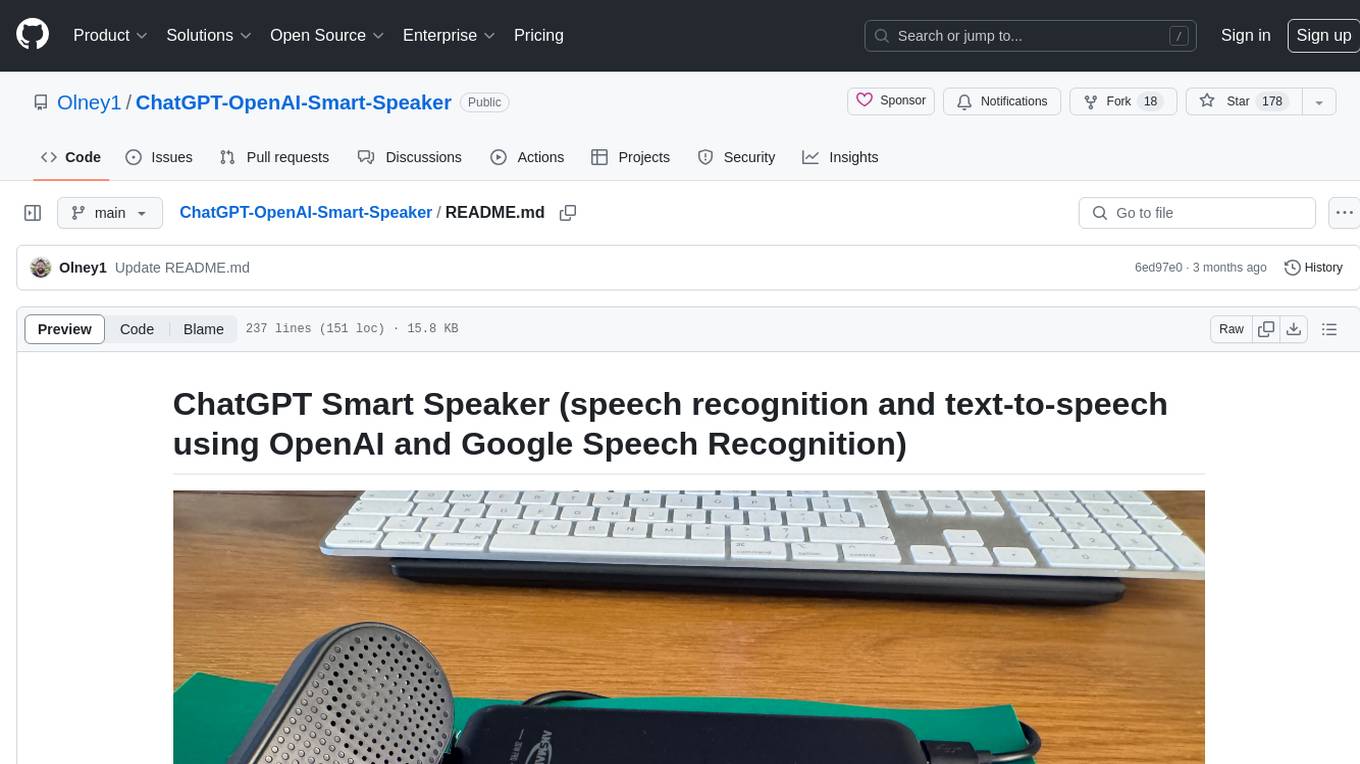
ChatGPT-OpenAI-Smart-Speaker
ChatGPT Smart Speaker is a project that enables speech recognition and text-to-speech functionalities using OpenAI and Google Speech Recognition. It provides scripts for running on PC/Mac and Raspberry Pi, allowing users to interact with a smart speaker setup. The project includes detailed instructions for setting up the required hardware and software dependencies, along with customization options for the OpenAI model engine, language settings, and response randomness control. The Raspberry Pi setup involves utilizing the ReSpeaker hardware for voice feedback and light shows. The project aims to offer an advanced smart speaker experience with features like wake word detection and response generation using AI models.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.
AI-Horde-Worker
AI-Horde-Worker is a repository containing the original reference implementation for a worker that turns your graphics card(s) into a worker for the AI Horde. It allows users to generate or alchemize images for others. The repository provides instructions for setting up the worker on Windows and Linux, updating the worker code, running with multiple GPUs, and stopping the worker. Users can configure the worker using a WebUI to connect to the horde with their username and API key. The repository also includes information on model usage and running the Docker container with specified environment variables.
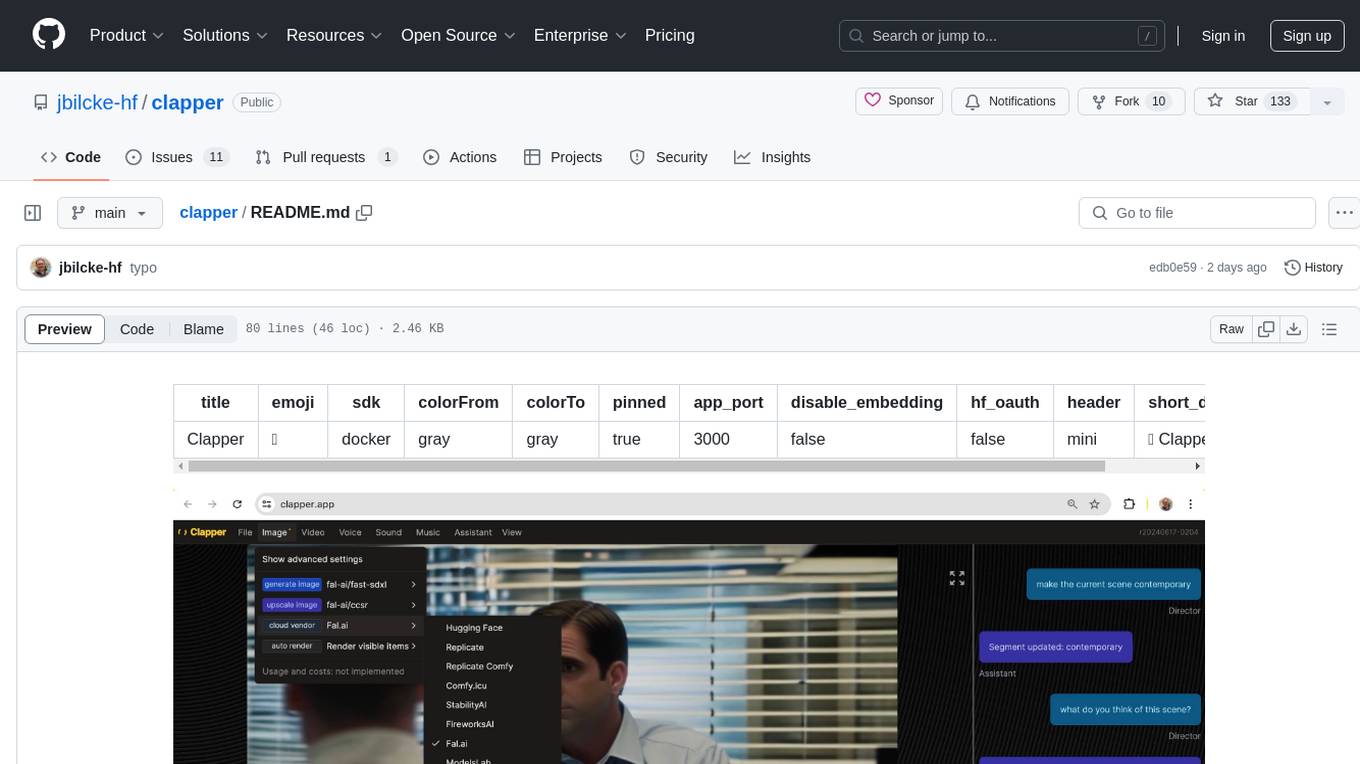
clapper
Clapper is an open-source AI story visualization tool that can interpret screenplays and render them into storyboards, videos, voice, sound, and music. It is currently in early development stages and not recommended for general use due to some non-functional features and lack of tutorials. A public alpha version is available on Hugging Face's platform. Users can sponsor specific features through bounties and developers can contribute to the project under the GPL v3 license. The tool lacks automated tests and code conventions like Prettier or a Linter.
concierge
Concierge is a versatile automation tool designed to streamline repetitive tasks and workflows. It provides a user-friendly interface for creating custom automation scripts without the need for extensive coding knowledge. With Concierge, users can automate various tasks across different platforms and applications, increasing efficiency and productivity. The tool offers a wide range of pre-built automation templates and allows users to customize and schedule their automation processes. Concierge is suitable for individuals and businesses looking to automate routine tasks and improve overall workflow efficiency.
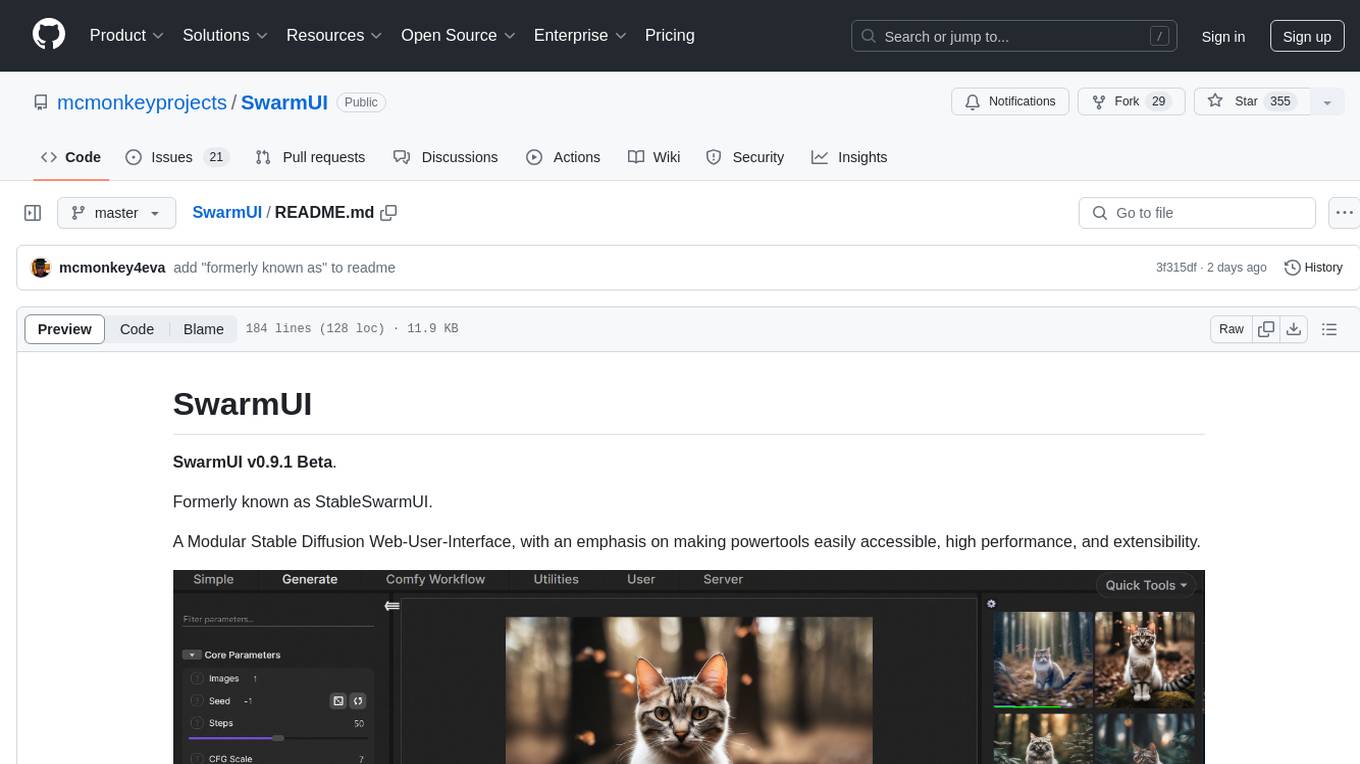
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.
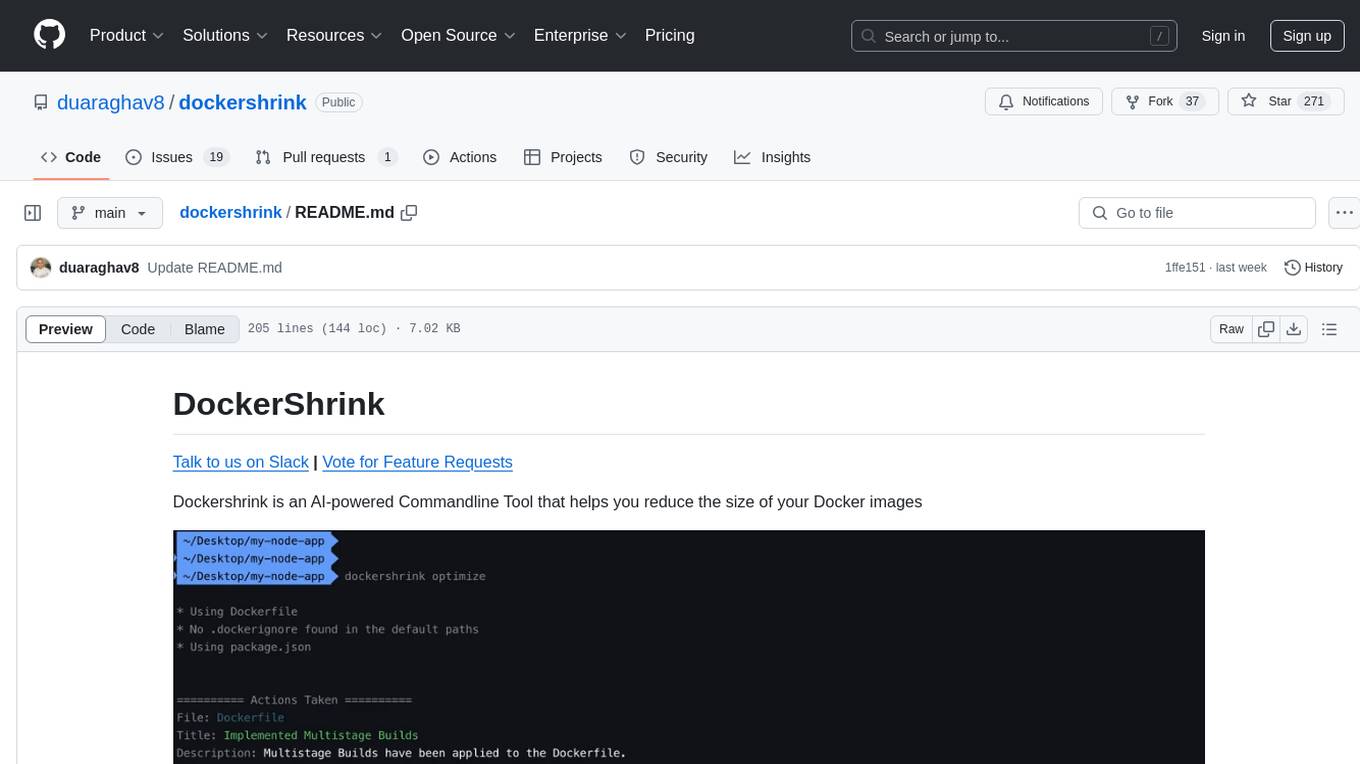
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
tracking-aircraft
This repository provides a demo that tracks aircraft using Redis and Node.js by receiving aircraft transponder broadcasts through a software-defined radio (SDR) and storing them in Redis. The demo includes instructions for setting up the hardware and software components required for tracking aircraft. It consists of four main components: Radio Ingestor, Flight Server, Flight UI, and Redis. The Radio Ingestor captures transponder broadcasts and writes them to a Redis event stream, while the Flight Server consumes the event stream, enriches the data, and provides APIs to query aircraft status. The Flight UI presents flight data to users in map and detail views. Users can run the demo by setting up the hardware, installing SDR software, and running the components using Docker or Node.js.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
n8n-docs
n8n is an extendable workflow automation tool that enables you to connect anything to everything. It is open-source and can be self-hosted or used as a service. n8n provides a visual interface for creating workflows, which can be used to automate tasks such as data integration, data transformation, and data analysis. n8n also includes a library of pre-built nodes that can be used to connect to a variety of applications and services. This makes it easy to create complex workflows without having to write any code.
For similar tasks
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.
open-dubbing
Open dubbing is an AI dubbing system that uses machine learning models to automatically translate and synchronize audio dialogue into different languages. It is designed as a command line tool. The project is experimental and aims to explore speech-to-text, text-to-speech, and translation systems combined. It supports multiple text-to-speech engines, translation engines, and gender voice detection. The tool can automatically dub videos, detect source language, and is built on open-source models. The roadmap includes better voice control, optimization for long videos, and support for multiple video input formats. Users can post-edit dubbed files by manually adjusting text, voice, and timings. Supported languages vary based on the combination of systems used.
AivisSpeech-Engine
AivisSpeech-Engine is a powerful open-source tool for speech recognition and synthesis. It provides state-of-the-art algorithms for converting speech to text and text to speech. The tool is designed to be user-friendly and customizable, allowing developers to easily integrate speech capabilities into their applications. With AivisSpeech-Engine, users can transcribe audio recordings, create voice-controlled interfaces, and generate natural-sounding speech output. Whether you are building a virtual assistant, developing a speech-to-text application, or experimenting with voice technology, AivisSpeech-Engine offers a comprehensive solution for all your speech processing needs.
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
For similar jobs
metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.