
openvino-plugins-ai-audacity
A set of AI-enabled effects, generators, and analyzers for Audacity®.
Stars: 885

OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
README:
A set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC 💻 -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU.
- Music Separation🎵 -- Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments.
- Noise Suppression🧹 -- Removes background noise from an audio sample.
- Music Generation & Continuation🎶 -- Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music.
- Whisper Transcription🎤 -- Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
Go here to find installation packages & instructions for the latest Windows release.
We welcome you to submit an issue here for
- Questions
- Bug Reports
- Feature Requests
- Feedback of any kind -- how can we improve this project?
Your contributions are welcome and valued, no matter how big or small. Feel free to submit a pull-request!
- Audacity® development team & Muse Group-- Thank you for your support!
- Audacity® GitHub -- https://github.com/audacity/audacity
- Whisper transcription & translation analyzer uses whisper.cpp (with OpenVINO™ backend): https://github.com/ggerganov/whisper.cpp
- Music Generation & Continuation use MusicGen model, from Meta.
- We currently have support for MusicGen-Small, and MusicGen-Small-Stereo
- The txt-to-music pipelines were ported from python to C++, referencing logic from the Hugging Face transformers project: https://github.com/huggingface/transformers
- Music Separation effect uses Meta's Demucs v4 model (https://github.com/facebookresearch/demucs), which has been ported to work with OpenVINO™
- Noise Suppression:
- noise-suppression-denseunet-ll: from OpenVINO™'s Open Model Zoo: https://github.com/openvinotoolkit/open_model_zoo
- DeepFilterNet2 & DeepFilterNet3:
- Ported the models & pipeline from here: https://github.com/Rikorose/DeepFilterNet
- We also made use of @grazder's fork / branch (https://github.com/grazder/DeepFilterNet/tree/torchDF-changes) to better understand the Rust implementation, and so we also based some of our C++ implementation on
torch_df_offline.pyfound here. - Citations:
@inproceedings{schroeter2022deepfilternet2, title = {{DeepFilterNet2}: Towards Real-Time Speech Enhancement on Embedded Devices for Full-Band Audio}, author = {Schröter, Hendrik and Escalante-B., Alberto N. and Rosenkranz, Tobias and Maier, Andreas}, booktitle={17th International Workshop on Acoustic Signal Enhancement (IWAENC 2022)}, year = {2022}, } @inproceedings{schroeter2023deepfilternet3, title = {{DeepFilterNet}: Perceptually Motivated Real-Time Speech Enhancement}, author = {Schröter, Hendrik and Rosenkranz, Tobias and Escalante-B., Alberto N. and Maier, Andreas}, booktitle={INTERSPEECH}, year = {2023}, }
- OpenVINO™ Notebooks -- We have learned a lot from this awesome set of python notebooks, and are still using it to learn latest / best practices for implementing AI pipelines using OpenVINO™!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for openvino-plugins-ai-audacity
Similar Open Source Tools
openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

YuE
YuE (乐) is an open-source foundation model designed for music generation, specifically transforming lyrics into full songs. It can generate complete songs in various genres and vocal styles, ensuring a polished and cohesive result. The model requires significant GPU memory for generating long sequences and recommends specific configurations for optimal performance. Users can customize the number of sessions for memory usage. The tool provides a quickstart guide for generating music using Transformers and includes tips for execution time and tag selection. The project is licensed under Creative Commons Attribution Non Commercial 4.0.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.
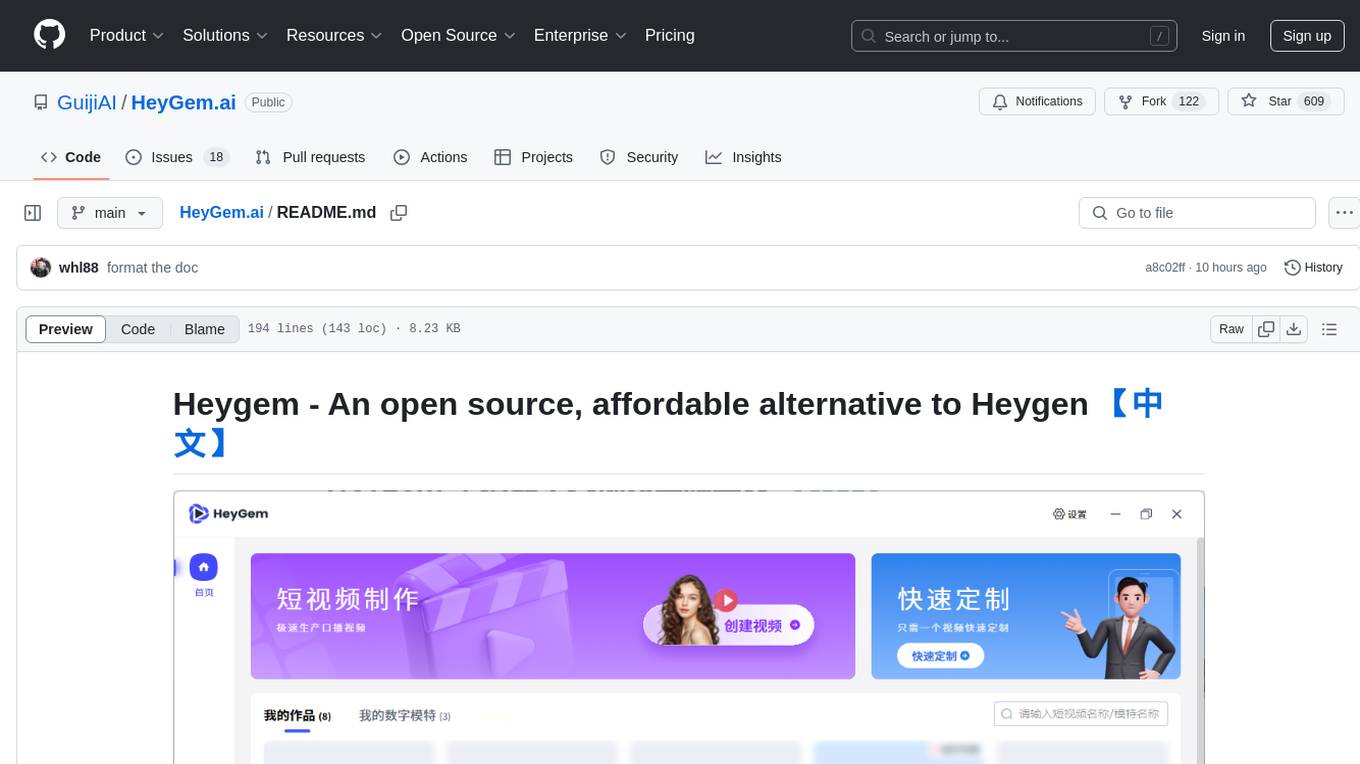
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
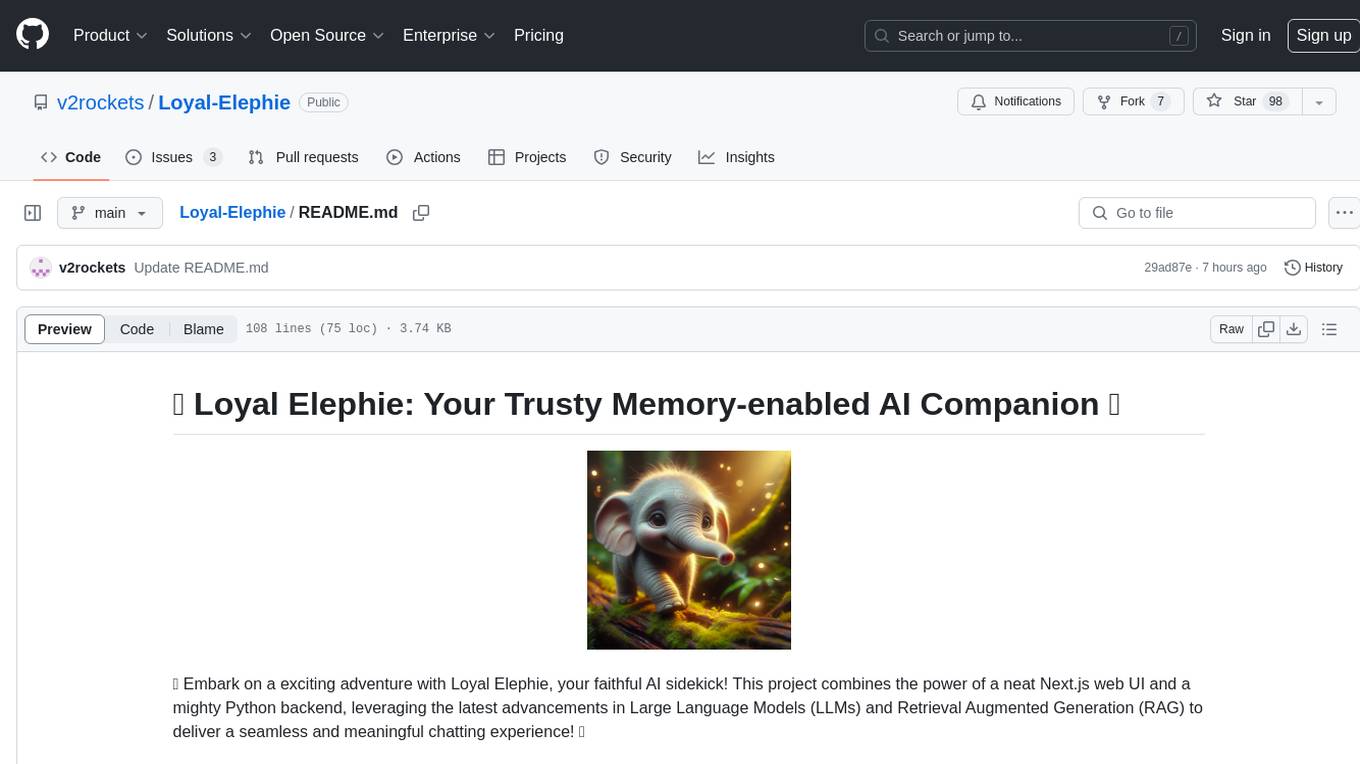
Loyal-Elephie
Embark on an exciting adventure with Loyal Elephie, your faithful AI sidekick! This project combines the power of a neat Next.js web UI and a mighty Python backend, leveraging the latest advancements in Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) to deliver a seamless and meaningful chatting experience. Features include controllable memory, hybrid search, secure web access, streamlined LLM agent, and optional Markdown editor integration. Loyal Elephie supports both open and proprietary LLMs and embeddings serving as OpenAI compatible APIs.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.
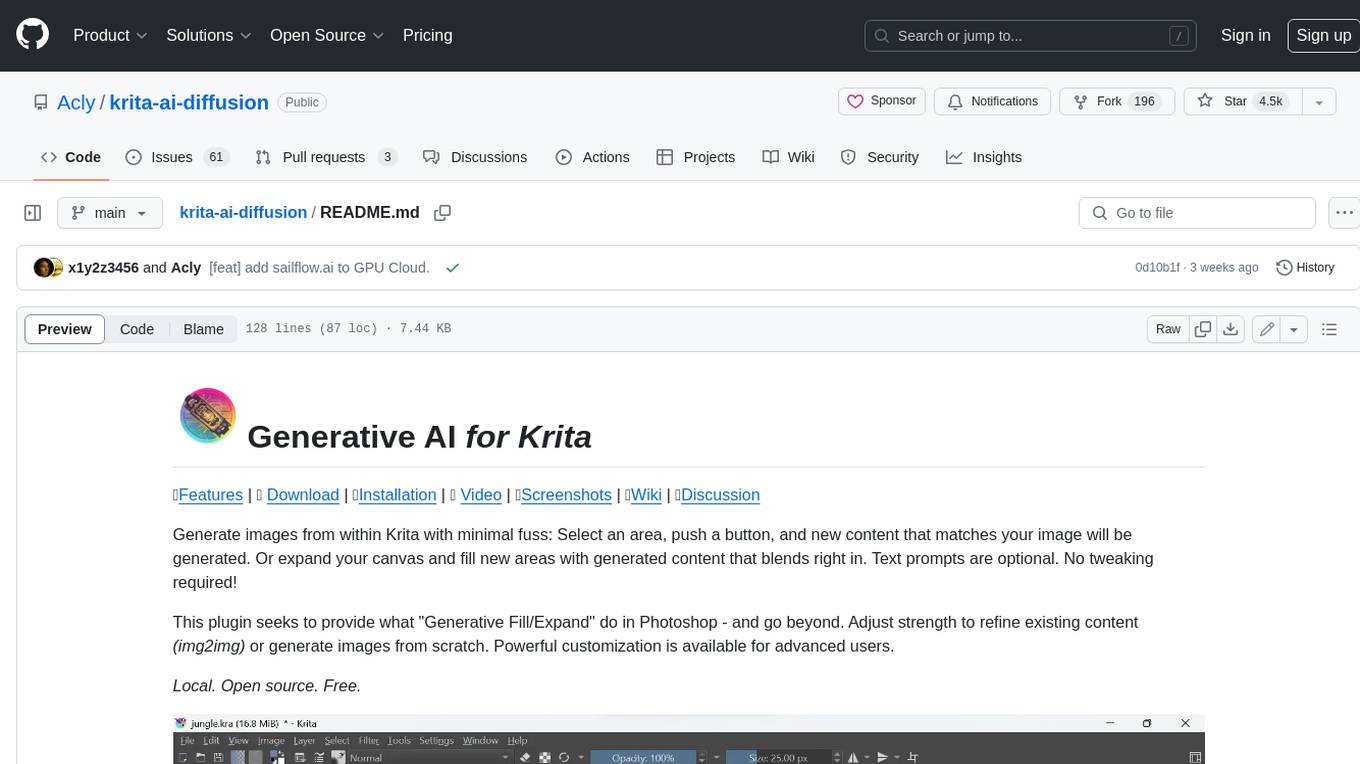
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
For similar tasks

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.
openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
SunoApi
SunoAPI is an unofficial client for Suno AI, built on Python and Streamlit. It supports functions like generating music and obtaining music information. Users can set up multiple account information to be saved for use. The tool also features built-in maintenance and activation functions for tokens, eliminating concerns about token expiration. It supports multiple languages and allows users to upload pictures for generating songs based on image content analysis.
awesome-generative-ai
Awesome Generative AI is a curated list of modern Generative Artificial Intelligence projects and services. Generative AI technology creates original content like images, sounds, and texts using machine learning algorithms trained on large data sets. It can produce unique and realistic outputs such as photorealistic images, digital art, music, and writing. The repo covers a wide range of applications in art, entertainment, marketing, academia, and computer science.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
YuE
YuE (乐) is an open-source foundation model designed for music generation, specifically transforming lyrics into full songs. It can generate complete songs in various genres and vocal styles, ensuring a polished and cohesive result. The model requires significant GPU memory for generating long sequences and recommends specific configurations for optimal performance. Users can customize the number of sessions for memory usage. The tool provides a quickstart guide for generating music using Transformers and includes tips for execution time and tag selection. The project is licensed under Creative Commons Attribution Non Commercial 4.0.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.