Best AI tools for< Transcribe Speech >
21 - AI tool Sites
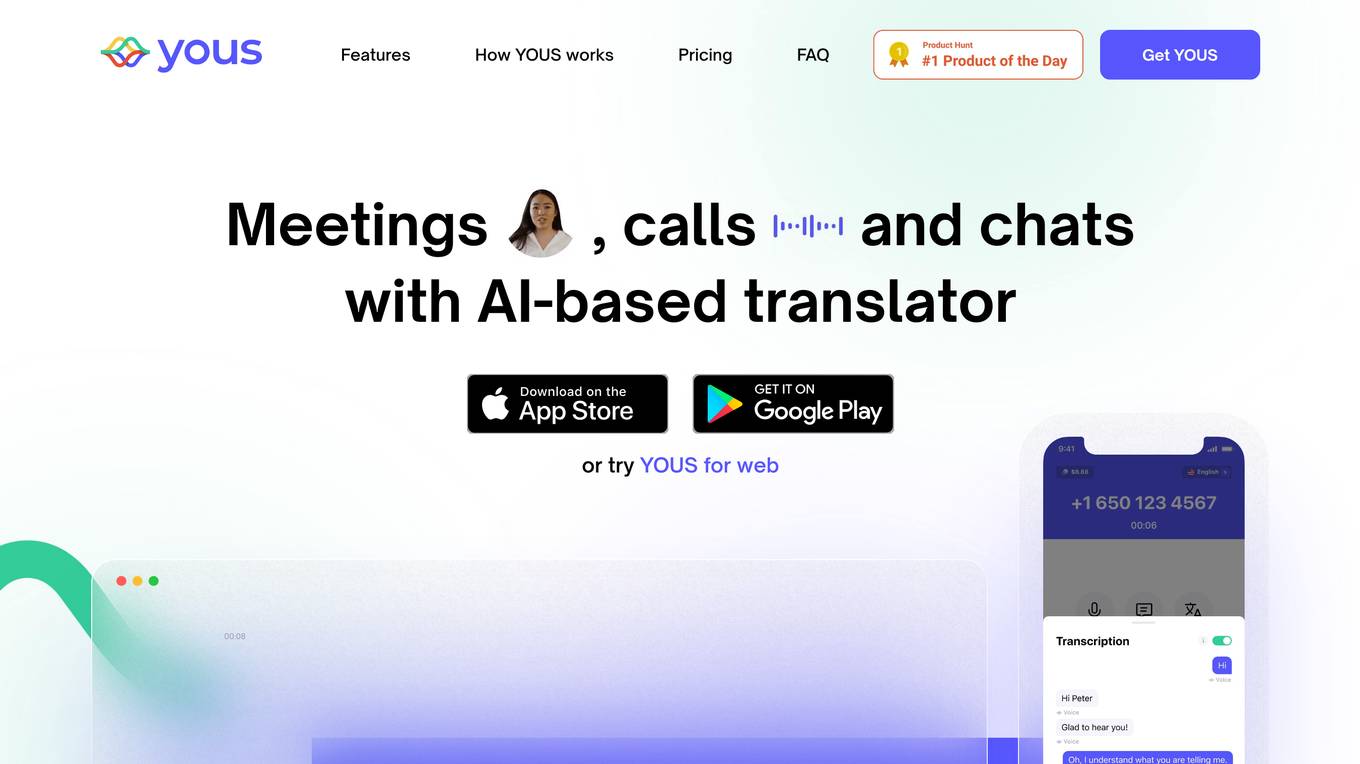
YOUS
YOUS is a messenger application with an AI-based translator that facilitates communication between individuals who speak different languages. The app allows users to have meetings, phone calls, and chats with built-in AI translation capabilities. YOUS aims to bridge language barriers and enable seamless communication in 17 languages. The platform prioritizes security and offers both free and paid subscription plans for users to access various features.
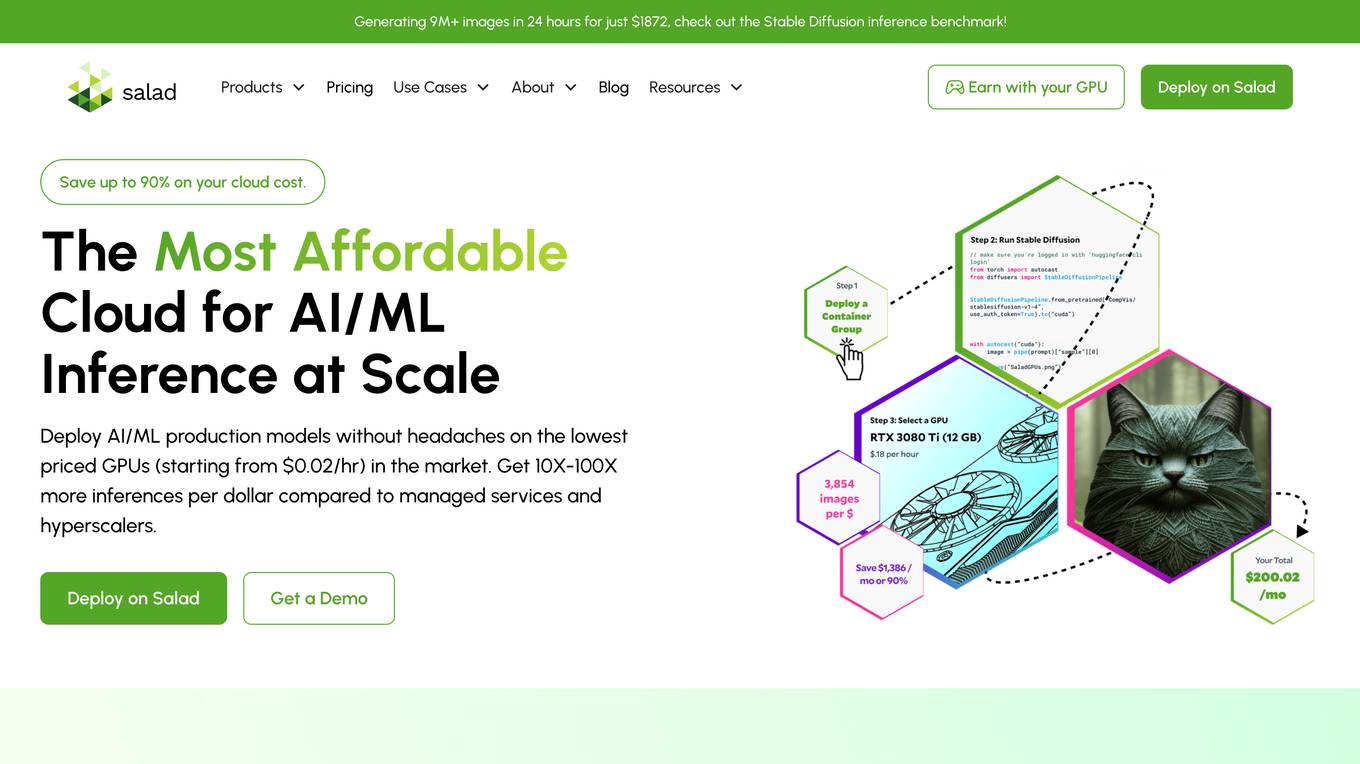
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
Typingflow
Typingflow is an AI-powered content generator and chatbot assistant that helps users create high-quality content, images, code, and more. It offers a range of features, including an advanced dashboard, payment gateways, multilingual ability, custom templates, and a support platform. Typingflow is designed to help users save time and effort while creating engaging and effective content.
Lingvanex
Lingvanex is a cloud-based machine translation and speech recognition platform that provides businesses with a variety of tools to translate text, documents, and speech in over 100 languages. The platform is powered by artificial intelligence (AI) and machine learning (ML) technologies, which enable it to deliver high-quality translations that are both accurate and fluent. Lingvanex also offers a variety of features that make it easy for businesses to integrate translation and speech recognition into their workflows, including APIs, SDKs, and plugins for popular programming languages and platforms.
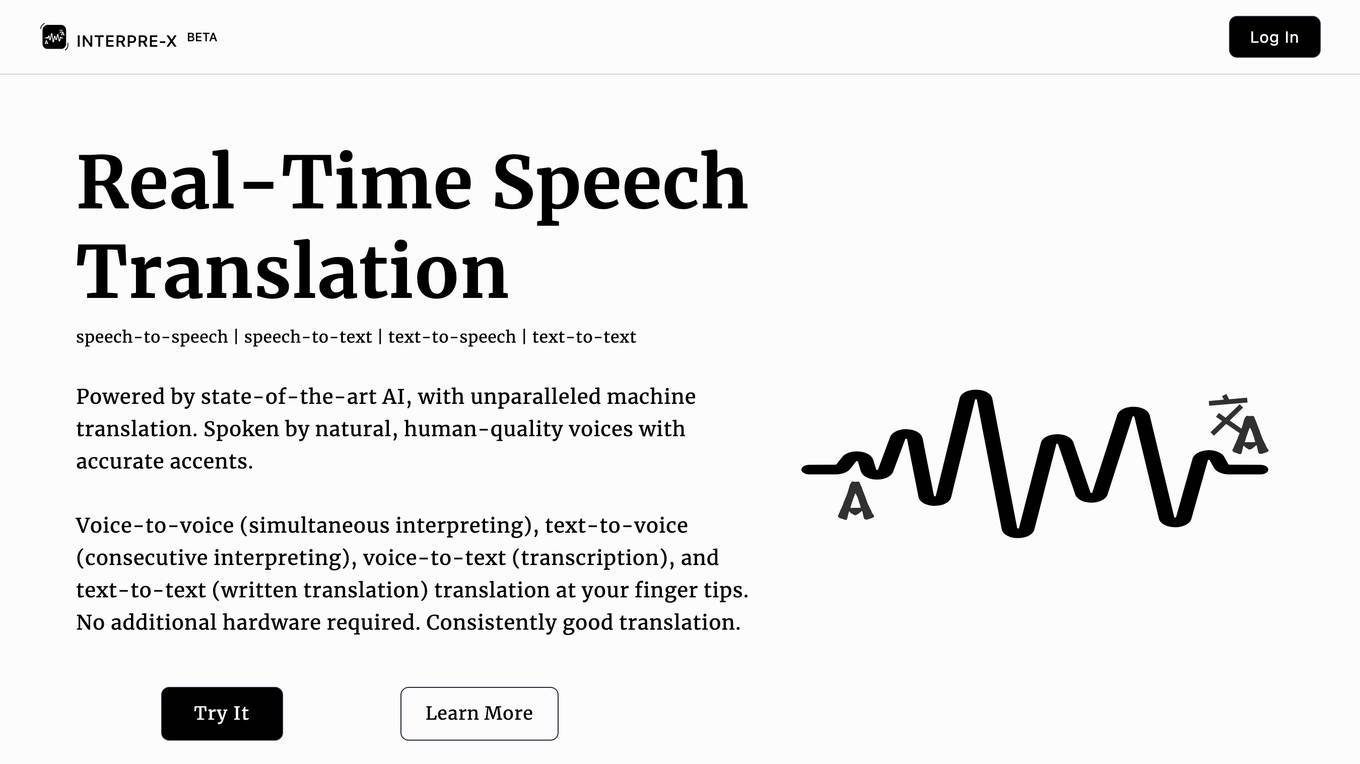
Interpre-X
Interpre-X is a real-time speech translation tool powered by AI. It offers speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation in over 10 languages. Interpre-X is designed to break down language barriers and facilitate communication between people who speak different languages. It is suitable for both personal and professional use, and it can be used in a variety of settings, such as travel, business meetings, and language learning.
UncensorGPT
UncensorGPT is an all-in-one platform that allows users to generate AI content and start making money in minutes. It offers a variety of features, including an AI text generator, AI image generator, AI code generator, AI chatbot, and AI speech-to-text converter. UncensorGPT is designed to be easy to use, even for beginners, and it offers a variety of pricing plans to fit any budget.
VoiceCheap
VoiceCheap is an AI-powered application that offers dubbing, transcription, and speech synthesis services. It enables users to translate videos into multiple languages, clone voices, generate subtitles, remove background noise, and more. With features like SmartSync Technology and multi-speaker dubbing, VoiceCheap helps content creators produce professional-quality dubbed videos efficiently. The application uses advanced AI technology to provide cost-effective dubbing solutions and seamless integration with various platforms. VoiceCheap is trusted by professionals and loved by users worldwide for its innovative tools and services.
MeduzaAi
MeduzaAi is an all-in-one platform that leverages the power of AI to generate text, images, code, chat, and more with multi-lingual abilities. It offers various tools such as AI Text Generator, AI Image Generator, AI Code Generator, AI Chat Bot, and AI Speech To Text to empower users in content creation and communication. The platform aims to help users unleash their creativity, streamline their coding process, transcribe speech into text, and provide human-like chatbot assistance. MeduzaAi caters to digital agencies, product designers, entrepreneurs, copywriters, digital marketers, and developers, offering a range of features to enhance productivity and creativity.
Instructly
Instructly is a revolutionary AI tool designed to help users create high-quality content effortlessly and affordably. It offers a range of features such as AI Writer for generating SEO-optimized content, AI Code Generator for streamlining coding experience, AI Image Generator for creating engaging visuals, AI Chat for interactive assistance, Speech to Text for transcription, and Text to Voice for lifelike speech conversion. With Instructly, users can save time, boost productivity, and enhance their content strategy with ease.
AITurbos
AITurbos is an AI-powered platform that offers a suite of tools designed to revolutionize content creation and marketing strategies. With a focus on boosting engagement, saving time, and enhancing productivity, AITurbos provides advanced AI models for generating text, images, code, chatbots, and more. Users can access features like AI text generation, image generation, code generation, chatbot creation, and speech-to-text conversion. The platform supports multiple languages, custom templates, and data-driven customization to meet diverse content creation needs.
Dewagear CreateAI
Dewagear CreateAI is an advanced AI tool that serves as a platform for creating AI Virtual Assistants and generating various AI content, including AI Voiceovers, AI Images, AI Speech to Text, and AI Codes. It offers a diverse range of features and templates to assist users in creating high-quality content efficiently and effectively. With a focus on personalization, security, and user experience, Dewagear CreateAI aims to empower individuals in the digital space by providing cutting-edge AI solutions.
Onyxium
Onyxium is an AI platform that provides a comprehensive collection of AI tools for various tasks such as image recognition, text analysis, and speech recognition. It offers users the ability to access and utilize the latest AI technologies in one place, empowering them to enhance their projects and workflows with advanced AI capabilities. With a user-friendly interface and affordable pricing plans, Onyxium aims to make AI tools accessible to everyone, from individuals to large-scale businesses.
Producti Ai
Producti Ai is an all-in-one AI platform designed to unleash the power of AI by offering a range of tools such as text generator, image generator, code generator, chatbot assistant, speech to text transcriber, and more. With intuitive interface and powerful features, Producti Ai helps users generate high-quality texts, eye-catching images, efficient code, and accurate transcriptions effortlessly. Powered by OpenAI and Dall-E, Producti Ai aims to empower creativity, streamline development, and provide virtual assistance across various tasks and industries.
Content Render
Content Render is an all-in-one online AI content generator tool that leverages the power of AI to create unique, engaging, and high-quality content in seconds. From blog posts to digital ads, the platform offers advanced AI tools for content creation, coding assistance, image generation, speech-to-text conversion, and more. With a user-friendly interface and a range of AI models, Content Render aims to revolutionize content creation and boost productivity for businesses and individuals alike.
Neurahub
Neurahub is a single generative AI suite designed for daily creation tasks. It offers a central hub with essential and task-specific AI tools for tailored content creation and thinking tasks. Users can access leading AI tools, create and analyze various content and media effortlessly in seconds, generate unlimited templates and chatbot personas, and engage with a wider audience in over 30 languages. The platform also ensures data security with 256-bit SSL encryption and allows collaboration among team members to maximize AI benefits.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.
Witlly
Witlly is an all-in-one AI platform that offers various tools such as a text generator, chatbot, code generator, image generator, speech-to-text, text-to-speech, web browser, and more. It provides users with the ability to generate high-quality content quickly and efficiently, including product descriptions, blog posts, email newsletters, social media updates, high-quality images, graphics, and code. Witlly also features an advanced editor for editing AI-generated content and offers flexible subscription plans tailored to different user needs.
Auphonic
Auphonic is an AI-powered audio post-production web tool designed to help users achieve professional-quality audio results effortlessly. It offers a range of features such as Intelligent Leveler, Noise & Reverb Reduction, Filtering & AutoEQ, Cut Filler Words and Silence, Multitrack Algorithms, Loudness Specifications, Speech2Text & Automatic Shownotes, Video Support, Metadata & Chapters, and more. Auphonic is widely used by podcasters, educators, content creators, and audiobook producers to enhance their audio content and streamline their workflows. With its intuitive interface and advanced algorithms, Auphonic simplifies the audio editing process and ensures consistent audio quality across different platforms.

Tilde.ai
Tilde.ai is a language technology platform that offers a wide range of AI-powered solutions for translation, speech technologies, and conversational AI. It combines human and artificial intelligence to help people connect and work efficiently. The platform provides machine translation, speech-to-text conversion, text-to-speech synthesis, real-time transcription, AI chatbots, internal knowledge assistants, and meeting support services. Tilde.ai aims to bridge language barriers and enhance communication by leveraging advanced language technologies.
ElevateAI by NICE
ElevateAI by NICE is a market-leading AI-powered speech-to-text application that offers transcription models, Generative AI, Enlighten AI, and CX AI features. It provides insights by pairing free Generative AI with NICE's transcription models to uncover hidden insights in data. ElevateAI aims to make AI-powered technology accessible for all, with easy integration, deployment, and user-friendly APIs. The application is designed to help contact centers leverage the power of AI for enhanced customer experiences and innovation.
AiGalaxy
AiGalaxy is an all-in-one AI solution that offers a wide range of user-friendly AI tools in a single app. Users can easily generate images, remove backgrounds, change clothing, create hidden messages, generate QR codes, change ages, extract music and vocals, create voice models, convert images to videos, transcribe speech to text, convert text to speech, turn tunes into music tracks, change voices, unblur images, add sound to videos, create slow-motion videos, restore old images, and more. The app is designed to be easy enough for beginners while also offering powerful features for professionals. AiGalaxy constantly adds new AI tools to its platform, making it a versatile and evolving tool for various tasks.
25 - Open Source AI Tools
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
OpenAI-Api-Unreal
The OpenAIApi Plugin provides access to the OpenAI API in Unreal Engine, allowing users to generate images, transcribe speech, and power NPCs using advanced AI models. It offers blueprint nodes for making API calls, setting parameters, and accessing completion values. Users can authenticate using an API key directly or as an environment variable. The plugin supports various tasks such as generating images, transcribing speech, and interacting with NPCs through chat endpoints.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
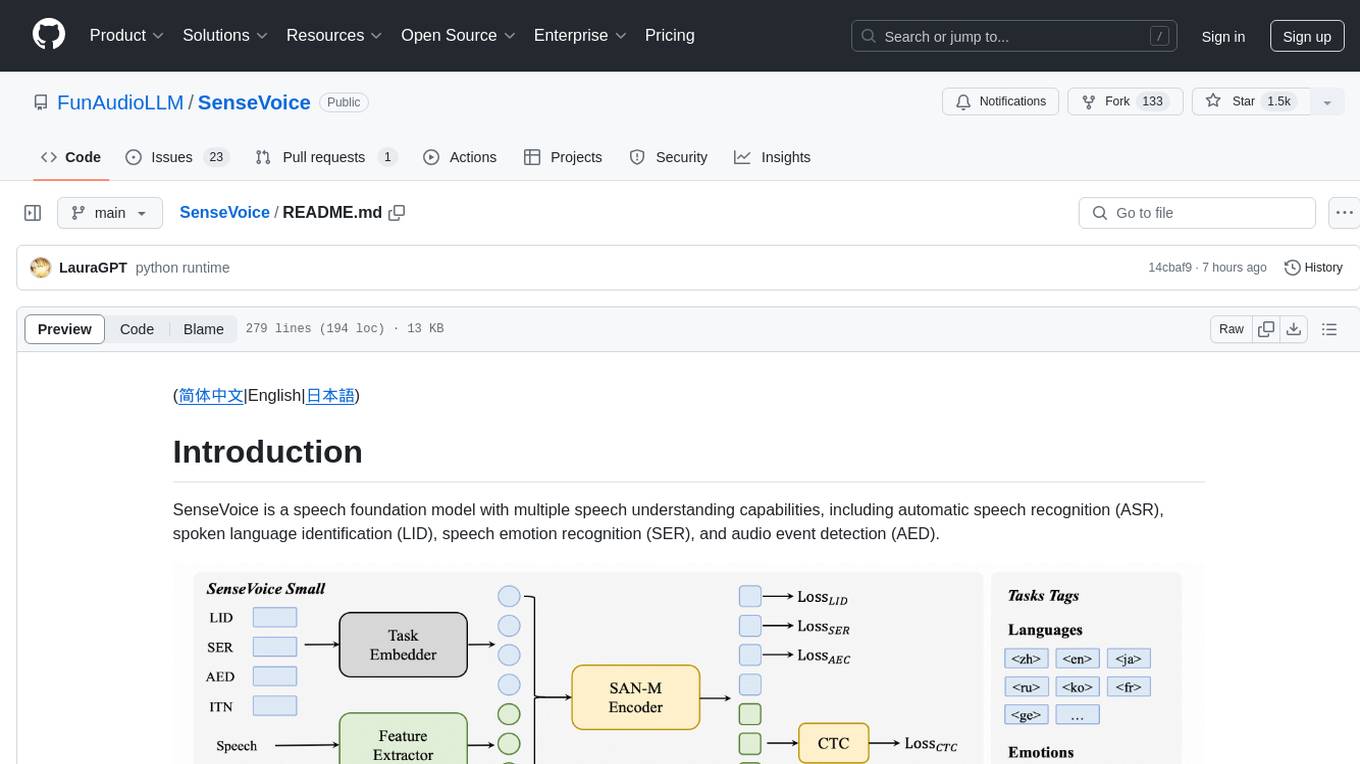
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
local-talking-llm
The 'local-talking-llm' repository provides a tutorial on building a voice assistant similar to Jarvis or Friday from Iron Man movies, capable of offline operation on a computer. The tutorial covers setting up a Python environment, installing necessary libraries like rich, openai-whisper, suno-bark, langchain, sounddevice, pyaudio, and speechrecognition. It utilizes Ollama for Large Language Model (LLM) serving and includes components for speech recognition, conversational chain, and speech synthesis. The implementation involves creating a TextToSpeechService class for Bark, defining functions for audio recording, transcription, LLM response generation, and audio playback. The main application loop guides users through interactive voice-based conversations with the assistant.
openai-kit
OpenAIKit is a Swift package designed to facilitate communication with the OpenAI API. It provides methods to interact with various OpenAI services such as chat, models, completions, edits, images, embeddings, files, moderations, and speech to text. The package encourages the use of environment variables to securely inject the OpenAI API key and organization details. It also offers error handling for API requests through the `OpenAIKit.APIErrorResponse`.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.
InterPilot
InterPilot is an AI-based assistant tool that captures audio from Windows input/output devices, transcribes it into text, and then calls the Large Language Model (LLM) API to provide answers. The project includes recording, transcription, and AI response modules, aiming to provide support for personal legitimate learning, work, and research. It may assist in scenarios like interviews, meetings, and learning, but it is strictly for learning and communication purposes only. The tool can hide its interface using third-party tools to prevent screen recording or screen sharing, but it does not have this feature built-in. Users bear the risk of using third-party tools independently.
sdk
Varg is an AI video generation SDK that extends Vercel's AI SDK with capabilities for video, music, and lipsync. It allows users to generate images, videos, music, and more using familiar patterns and declarative JSX syntax. The SDK supports various models for image and video generation, speech synthesis, music generation, and background removal. Users can create reusable elements for character consistency, handle files from disk, URL, or buffer, and utilize layout helpers, transitions, and caption styles. Varg also offers a visual editor for video workflows with a code editor and node-based interface.
runanywhere-sdks
RunAnywhere is an on-device AI tool for mobile apps that allows users to run LLMs, speech-to-text, text-to-speech, and voice assistant features locally, ensuring privacy, offline functionality, and fast performance. The tool provides a range of AI capabilities without relying on cloud services, reducing latency and ensuring that no data leaves the device. RunAnywhere offers SDKs for Swift (iOS/macOS), Kotlin (Android), React Native, and Flutter, making it easy for developers to integrate AI features into their mobile applications. The tool supports various models for LLM, speech-to-text, and text-to-speech, with detailed documentation and installation instructions available for each platform.
push-2-talk
PushToTalk is a high-performance desktop voice input tool with large language model (LLM) capabilities. It supports two working modes: dictation mode and AI assistant mode. The tool offers features like real-time transcription, LLM intelligent post-processing, custom hotkeys, multiple ASR engines support, visual feedback, audio feedback, history records, system tray support, automatic updates, multiple configuration management, personal glossary, automatic glossary learning, LLM configuration center, theme switching, mute during recording, VAD silence detection, AGC automatic gain, multi-screen support, and more.
willow-inference-server
Willow Inference Server (WIS) is a highly optimized language inference server implementation focused on enabling performant, cost-effective self-hosting of state-of-the-art models for speech and language tasks. It supports ASR and TTS tasks, runs on CUDA with low-end device support, and offers various transport options like REST, WebRTC, and Web Sockets. WIS is memory optimized, leverages CTranslate2 for Whisper support, and enables custom TTS voices. The server automatically detects available CUDA VRAM and optimizes functionality accordingly. Users can programmatically select Whisper models and parameters for each request to balance speed and quality.
openwhispr
OpenWhispr is an open source desktop dictation application that converts speech to text using OpenAI Whisper. It features both local and cloud processing options for maximum flexibility and privacy. The application supports multiple AI providers, customizable hotkeys, agent naming, and various AI processing models. It offers a modern UI built with React 19, TypeScript, and Tailwind CSS v4, and is optimized for speed using Vite and modern tooling. Users can manage settings, view history, configure API keys, and download/manage local Whisper models. The application is cross-platform, supporting macOS, Windows, and Linux, and offers features like automatic pasting, draggable interface, global hotkeys, and compound hotkeys.
LLM-Hub
LLM Hub is an open-source Android app optimized for mobile usage, supporting multiple model formats for on-device LLM chat and image generation. It offers six AI tools including chat, writing aid, image generator, translator, transcriber, and scam detector. Privacy-first with on-device processing and zero data collection. Advanced capabilities include GPU/NPU acceleration, text-to-speech, RAG with global memory, and custom model import. Developed using Kotlin + Jetpack Compose, LLM Runtime, and various model runtimes.
react-native-nitro-mlx
The react-native-nitro-mlx repository allows users to run LLMs, Text-to-Speech, and Speech-to-Text on-device in React Native using MLX Swift. It provides functionalities for downloading models, loading and generating responses, streaming audio, text-to-speech, and speech-to-text capabilities. Users can interact with various MLX-compatible models from Hugging Face, with pre-defined models available for convenience. The repository supports iOS 26.0+ and offers detailed API documentation for each feature.
20 - OpenAI Gpts
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.



Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.





Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.

Transcript to Social Post
Transforms transcripts (from Whatsapp voice memos) into engaging social media content.
User Interview Product Manager
Transforms user interview transcripts into a list of tasks [Asana compatible CSV file]. Send feedback to https://x.com/kireet_agrawal

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)