
blurt
Gnome shell extension for accurate speech to text input in Linux using whisper.cpp. Input text from speech anywhere.
Stars: 72
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.
README:

(For a leaner tool working across all desktop environments, check also Blah Speech to Text.)
Blurt is a simple Gnome shell extension based on the command line utility NoteWhispers, which itself, is built around the great whisper.cpp.
The current code in main is tested on and supports ver. 48 (and likely 46 and 47) of the Gnome shell. For older versions, see the respective folders (releases) or go to the GNOME extensions website.
![]() Features:
Features:
- Can use local whisper.cpp installation
- Or transcribe with a whisper.cpp server -speedier and recommended.
- Right click for preferences and setup
- Start/Stop speech-to-text input with a set of key bindings
- Start/Stop speech-to-text input with a left click on the icon
- Icon color shows status during operation
UPDATE: GNOME SHELL version 48 is now supported in the main branch.
When the extension is installed and enabled (indicated with Ḅ in the top bar), one can input text from speech into any window that allows input (such as the text editor in the screencast below). This is done by pressing a key combination (<CTRL+ALT+a> is the default), triggering a speech recognizer process that records a speech clip from the microphone, transcribes it with whisper.cpp and sends the result to the PRIMARY selection or Clipboard under X11 or Wayland. When recording speech, a microphone indicator appears in the top bar and the color of the extension indicator Ɓ becomes yellow. The disappearance of the microphone icon from the top bar indicates that the recognizer has "blurted" a snippet of text that can be pasted with the middle mouse button. (Note that on slower systems there may be a slight delay after the microphone icon disappears and before the text reaches the clipboard due to the time needed for transcription. On my computer it is less than 300 ms for an average paragraph of spoken text).
The convenience that this extension affords is demonstrated in this screencast (note the microphone icon at the top when recording):
- zsh or bash command line shell installation on a Linux system running GNOME.
- working whisper.cpp installation (see https://github.com/ggerganov/whisper.cpp
- recent versions of
sox,xsel,curl(orwl-copyfor Wayland) command-line tools from your system's repositories. - A working microphone
DISCLAIMER: Some of the proposed actions, if implemented, will alter how your system works internally (e.g. systemwide temporary file storage and memory management). The author neither takes credit nor assumes any responsibility for any outcome that may or may not result from interacting with the contents of this document. Suggestions in this section are based on the author's choice and opinion and may not fit the taste or the particular situation of everyone; please, adjust as you like.
(Assuming whisper.cpp is installed and the "main" and "server" executables compiled with 'make' in the cloned whisper.cpp repo. See Prerequisites section)
- Place the orchestrator script wsi in $HOME/.local/bin/ (also handles connection to a wisper.cpp server)
cp -t $HOME/.local/bin wsi
- Make it executable:
cd $HOME/.local/bin; chmod +x wsi - Configure the script to match your environment (see CONFIGURATION section below).
- Run once from the command line to let the script check for required dependencies.
- If using local whisper.cpp, create a symbolic link (the code expects 'transcribe' in your $PATH) to the compiled "main" executable in the whisper.cpp directory.
For example, create it in your
$HOME/.local/bin/(part of your $PATH) with
ln -s /full/path/to/whisper.cpp/main $HOME/.local/bin/transcribe
If transcribe is not in your $PATH, either edit the call to it in wsi to include the absolute path, or add its location to the $PATH variable. Otherwise the script and by extension, the extension:-) will fail.
- The extension can then be installed either from https://extensions.gnome.org/extension/6742/blurt/ with one-click install, or manually by clonning this repository (or just grabbing the zip archive).
If you are installing the Blurt GNOME extension manually, place the extracted folder
[email protected]into$HOME/.local/share/gnome-shell/extensionsand enable it from yourExtensionssystem app or from the command line with
gnome-extensions enable [email protected]
provided that it is detected by the system, which can be checked by inspecting the output of
gnome-extensions list
Inside the wsi script, near the begining, there is a clearly marked section, named "USER CONFIGURATION BLOCK" where all the user-configurable variables (described in the following section) have been collected.
Most can be left as is but the important ones are the location of the whisper.cpp model file that you would like to use during transcription and/or the fallback network address and port of the whisper.cpp server.
The location of the wsi script (should be in your $PATH) can be changed from the "Preferences" dialog, accessible by the system Extensions app or by clicking on the Blurt (Ɓ) top bar indicator label.
 The keyboard shortcut to initiate speech input can also be modified if necessary. Check the gschema.xml file for the key combination and adjust as desired. The schema then has to be recompiled with
The keyboard shortcut to initiate speech input can also be modified if necessary. Check the gschema.xml file for the key combination and adjust as desired. The schema then has to be recompiled with
glib-compile-schemas schemas/ from the command line in the extension folder
Sox is recording in wav format at 16k rate, the only currently accepted by whisper.cpp. This is done in wsi with this command:
rec -t wav $ramf rate 16k silence 1 0.1 3% 1 2.0 6%
It will attempt to stop on silence of 2s with signal level threshold of 6%. A very noisy environment will prevent the detection of silence and the recording (of noise) will continue. This is a problem and a remedy that may not work in all cases is to adjust the duration and silence threshold in the sox filter in the wsi script.
You can use the manual interuption method below if preferred - now built in the extension itself
You can't raise the threshold arbitrarily because, if you consistently lower your voice (fadeout) at the end of your speech, it may get cut off if the threshold is high. Lower it in that case to a few %.
It is best to try to make the speech distinguishable from noise by amplitude (speak clearly, close to the microphone), while minimizing external noise (sheltered location of the microphone, noise canceling hardware etc.)
With good speech signal level, the threshold can then be more effective, since SNR (speech-to-noise ratio:-) is effectively increased.
Manual speech recording interuption (built-in in the latest version of Blurt - no need to set up, CTRL+ALT+z is default)
For those who want to be able to interupt the recording manually with a key combination, in the spirit of great hacks, we will not even try to rewrite the extension code because... "kiss". Instead of writing javascript to fight with shell setups and edge cases when transfering signals from the GNOME shell to a Gio.subprocess in a new bash or zsh shell etc., we are going to, again, use the system built-in features:
- Open your GNOME system settings and find "Keyboard".
- Under "Keyboard shortcuts", "View and customize shortcuts"
- In the new window, scroll down to "Custom Shortcuts" and press it.
- Press "+" to add a new shortcut and give it a name: "Blurt it already!"
- In the "Command" field type
pkill --signal 2 rec - Then press "Set Shortcut" and select a (unused) key combination. For example CTRL+ALT+x
- Click Add and you are done. That Simple. Just make sure that the new key binding has not been set-up already for something else. Now when the extension is recording speech, it can be stopped with the new key combo and transcription will start immediatelly.
For the minimalists, it is trivial to extrapolate from this hack to a complete CLI solution, without a single pixel of GUI video buffering. (A simple Adwaita widget window can cost MBs of video memory) Enter BlahST - this more universal, lightweight tool configured for client-server transcription, has replaced Blurt completely for me.
After the speech is captured, it will be passed to transcribe (whisper.cpp) for speech recognition. This will happen faster than real time (especially with a fast CPU or if your whisper.cpp installation uses CUDA). One can adjust the number of processing threads used by adding -t n to the command line parameters of transcribe (please, see whisper.cpp documentation).
The script will then parse the text to remove non-speech artifacts, format it and send it to the PRIMARY selection (clipboard) using either X11 or Wayland tools.
In principle, whisper (whisper.cpp) is multilingual and with the correct model file, this extension will "blurt" out UTF-8 text transcribed in the correct language. In the wsi script, the language choice can be made permanent by using -l LC in the transcribe call, where LC stands for the language code of choice, for example -l fr for french.
Speech-to-text transcription is memory- and CPU-intensive task and fast storage for read and write access can only help. That is why wsi stores temporary and resource files in memory, for speed and to reduce SSD/HDD "grinding": TEMPD='/dev/shm'.
This mount point of type "tmpfs" is created in RAM (let's assume that you have enough, say, at least 8GB) and is made available by the kernel for user-space applications. When the computer is shut down it is automatically wiped out, which is fine since we do not need the intermediate files.
In fact, for some types of applications (looking at you Electron), it would be beneficial (IMHO) to have the systemwide /tmp mount point also kept in RAM. Moving /tmp to RAM may speed up application startup a bit. A welcome speedup for any Electron app. In its simplest form, this transition is easy, just run:
echo "tmpfs /tmp tmpfs rw,nosuid,nodev" | sudo tee -a /etc/fstab
and then restart your Linux computer.
For the aforementioned reasons, especially if HDD is the main storage media, one can also move the ASR model files needed by whisper.cpp in the same location (/dev/shm). These are large files, that can be transferred to this location at the start of a terminal session (or at system startup). This can be done using your .profile file by placing something like this in it:
([ -f /dev/shm/ggml-base.en.bin ] || cp /path/to/your/local/whisper.cpp/models/ggml* /dev/shm/)
At this stage the extension, while useful, is somewhat of a "convenience hack" and can be improved by a seasoned GNOME developer who may find a better way to invoke whisper.cpp and fill the clipboard.
A virtual keyboard device implementing a legitimate IBus input method to send the text to a target text field is another direction for improvement, although I have no idea how to spy the field in focus, outside of the hacky nature of xdotoll and such.
- Open AI (for Whisper)
- Georgi Gerganov and community ( for Whisper's C/C++ port whisper.cpp)
- The sox developers (for the venerable "Swiss Army knife of sound processing tools")
- The creators and maintainers of GNOME and utilities such as xsel, xclip, wl-copy, the heaviweight ffmpeg and others that make the Linux environment (CLI and GUI) such a powerful paradigm.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for blurt
Similar Open Source Tools
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
audioseal
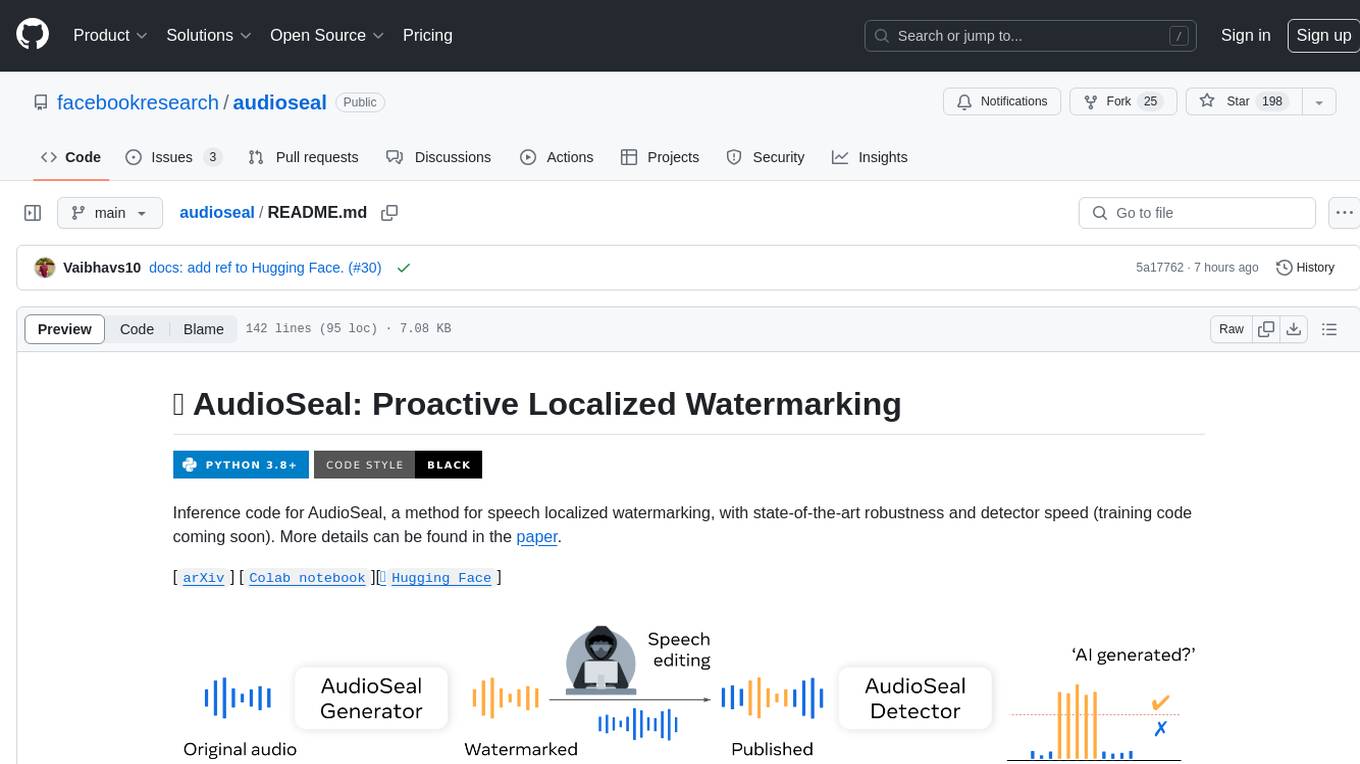
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.
vigenair
ViGenAiR is a tool that harnesses the power of Generative AI models on Google Cloud Platform to automatically transform long-form Video Ads into shorter variants, targeting different audiences. It generates video, image, and text assets for Demand Gen and YouTube video campaigns. Users can steer the model towards generating desired videos, conduct A/B testing, and benefit from various creative features. The tool offers benefits like diverse inventory, compelling video ads, creative excellence, user control, and performance insights. ViGenAiR works by analyzing video content, splitting it into coherent segments, and generating variants following Google's best practices for effective ads.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.
trinityX
TrinityX is an open-source HPC, AI, and cloud platform designed to provide all services required in a modern system, with full customization options. It includes default services like Luna node provisioner, OpenLDAP, SLURM or OpenPBS, Prometheus, Grafana, OpenOndemand, and more. TrinityX also sets up NFS-shared directories, OpenHPC applications, environment modules, HA, and more. Users can install TrinityX on Enterprise Linux, configure network interfaces, set up passwordless authentication, and customize the installation using Ansible playbooks. The platform supports HA, OpenHPC integration, and provides detailed documentation for users to contribute to the project.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.
mercure
mercure DICOM Orchestrator is a flexible solution for routing and processing DICOM files. It offers a user-friendly web interface and extensive monitoring functions. Custom processing modules can be implemented as Docker containers. Written in Python, it uses the DCMTK toolkit for DICOM communication. It can be deployed as a single-server installation using Docker Compose or as a scalable cluster installation using Nomad. mercure consists of service modules for receiving, routing, processing, dispatching, cleaning, web interface, and central monitoring.
gptauthor
GPT Author is a command-line tool designed to help users write long form, multi-chapter stories by providing a story prompt and generating a synopsis and subsequent chapters using ChatGPT. Users can review and make changes to the generated content before finalizing the story output in Markdown and HTML formats. The tool aims to unleash storytelling genius by combining human input with AI-generated content, offering a seamless writing experience for creating engaging narratives.
For similar tasks
vinux
Vinux is a Vim configuration tool designed for customization with over 5000+ lines of code, offering a modular approach, Spacemacs-like keymap, lazy loading, and compatibility with Vim 7.3. It is optimized for Linux kernel and uboot development, aiming to provide a comprehensive and intricate setup for Vim users.
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
OpenAI-Api-Unreal
The OpenAIApi Plugin provides access to the OpenAI API in Unreal Engine, allowing users to generate images, transcribe speech, and power NPCs using advanced AI models. It offers blueprint nodes for making API calls, setting parameters, and accessing completion values. Users can authenticate using an API key directly or as an environment variable. The plugin supports various tasks such as generating images, transcribing speech, and interacting with NPCs through chat endpoints.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.