
LLM_Web_search
An extension for oobabooga/text-generation-webui that enables the LLM to search the web
Stars: 276
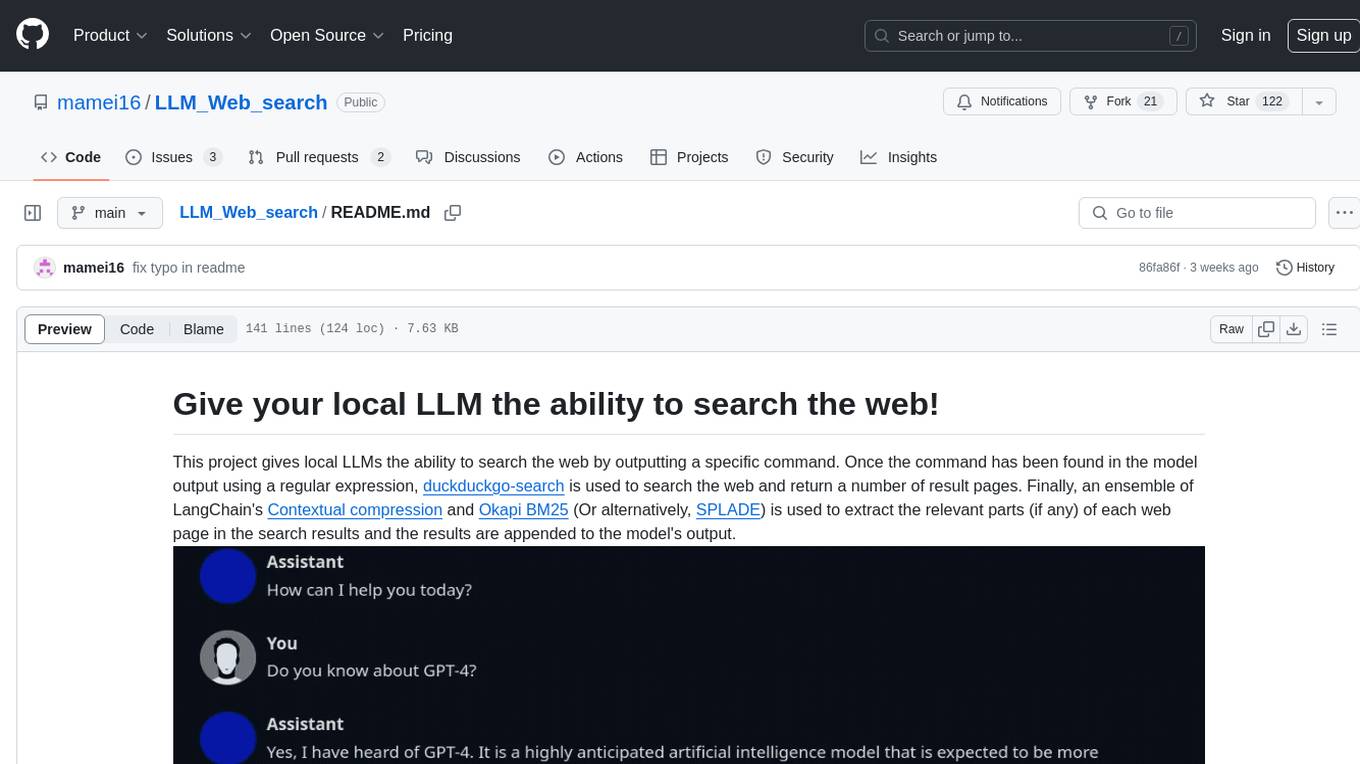
LLM_Web_search project gives local LLMs the ability to search the web by outputting a specific command. It uses regular expressions to extract search queries from model output and then utilizes duckduckgo-search to search the web. LangChain's Contextual compression and Okapi BM25 or SPLADE are used to extract relevant parts of web pages in search results. The extracted results are appended to the model's output.
README:
![]()
This project gives local LLMs the ability to search the web by outputting a specific
command. Once the command has been found in the model output using a regular expression, a web search is issued, returning a number of result pages. Finally, an
ensemble of a dense embedding model and
Okapi BM25 (Or alternatively, SPLADE)
is used to extract the relevant parts (if any) of each web page in the search results
and the results are appended to the model's output.
- Table of Contents
- Go to the "Session" tab of the web UI and use "Install or update an extension" to download the latest code for this extension.
- Run the appropriate
update_wizardscript inside the text-generation-webui folder and chooseInstall/update extensions requirements, then choose the name of this extension. - Launch the Web UI by running the appropriate
startscript and enable the extension under the session tab.
Alternatively, you can also start the server directly using the following command (assuming you have activated your conda/virtual environment):
python server.py --extension LLM_Web_search
If the installation was successful and the extension was loaded, a new tab with the title "LLM Web Search" should be visible in the web UI.
See https://github.com/oobabooga/text-generation-webui/wiki/07-%E2%80%90-Extensions for more information about extensions.
Search queries are extracted from the model's output using a regular expression. This is made easier by prompting the model
to use a fixed search command (see system_prompts/ for example prompts).
An example workflow of using this extension could be:
- Load a model
- Head over to the "LLM Web search" tab
- Load a custom system message/prompt
- Ensure that the query part of the command mentioned in the system message can be matched using the current "Search command regex string" (see "Using a custom regular expression" below)
- Pick a generation parameter preset that works well for you. You can read more about generation parameters here
- Choose "chat-instruct" or "instruct" mode and start chatting
The default regular expression is:
Search_web\("(.*)"\)Where Search_web is the search command and everything between the quotation marks
inside the parentheses will be used as the search query. Every custom regular expression must use a
capture group to extract the search
query. I recommend https://www.debuggex.com/ to try out custom regular expressions. If a regex
fulfills the requirement above, the search query should be matched by "Group 1" in Debuggex.
Here is an example of a more flexible, but more complex, regex that works for several different models:
[Ss]earch_web\((?:["'])(.*)(?:["'])\)Basic support exists for extracting the full text content from a webpage. The default regex to use this functionality is:
Download_webpage\("(.*)"\)Note: The full content of a web page is likely to exceed the maximum context length of your average local LLM.
This is the default web search backend.
To use a local or remote SearXNG instance instead of DuckDuckGo, simply paste the URL into the
"SearXNG URL" text field of the "LLM Web Search" settings tab (be sure to include http:// or https://). The instance must support
returning results in JSON format.
To modify the categories, engines, languages etc. that should be used for a specific query, it must follow the SearXNG search syntax. Currently, automatic redirect and Special Queries are not supported.
Quickly finds answers using just the highlighted snippets from websites returned by the search engine. If you simply want results fast, choose this search type.
Note: Some advanced options in the UI will be hidden when simple search is enabled, as they have no effect in this case.
Note2: The snippets returned by SearXNG are often much more useful than those returned by DuckDuckGo, so consider using SearXNG as the search backend if you use simple search.
Scans entire websites in the results for a more comprehensive search. Ideally, this search type should be able to find "needle in the haystack" information hidden somewhere in the website text. Hence, choose this option if you want to trade a more resource intensive search process for generally more relevant search results.
For the best possible search results, also enable semantic chunking and use SPLADE as the keyword retriever.
This extension comes out of the box with Okapi BM25 enabled, which is widely used and very popular for keyword based document retrieval. It runs on the CPU and, for the purpose of this extension, it is fast.
If you don't run the extension in "CPU only" mode and have some VRAM to spare, you can also select SPLADE in the "Advanced settings" section as an alternative. It has been shown to outperform BM25 in multiple benchmarks and uses a technique called "query expansion" to add additional contextually relevant words to the original query. However, it is slower than BM25. You can read more about it here.
To improve performance, documents are embedded in batches and in parallel. Increasing the "SPLADE batch size" parameter setting improves performance up to a certain point, but VRAM usage ramps up quickly with increasing batch size. A batch size of 8 appears to be a good trade-off, but the default value is 2 to avoid running out of memory on smaller GPUs.
Naively partitions a website's text into fixed sized chunks without any regard for the text content. This is the default, since it is fast and requires no GPU.
Tries to partition a website's text into chunks based on semantics. If two consecutive sentences have very different embeddings (based on the cosine distance between their embeddings), a new chunk will be started. How different two consecutive sentences have to be for them to end up in different chunks can be tuned using the sentence split threshold parameter in the UI.
For natural language, this method generally produces much better results than character-based chunking. However, it is noticeably slower, even when using the GPU.
This chunking method employs a fine-tune of the DistilBERT transformer model, which has been trained to classify tokens (see chonky). If a token is classified as the positive class, a new paragraph (or a new chunk) is meant to be started after the token.
While semantic chunking only compares pairs of consecutive sentences when deciding on where to start a new chunk, the token classification model can utilize a much longer context. However, the need to process this context means that this chunking method is slower than semantic chunking.
If you (like me) have ≤ 12 GB VRAM, I recommend using one of:
- Llama-3.1-8B-instruct
- Gemma-2-9b-it
- Mistral-Nemo-Instruct-2407
- Gemma-3-it
-
Qwen3
Since the Qwen3 family consists of reasoning models, some unique problems arise:- It seems that Qwen3 models are harder to prompt to use the search command. I have uploaded the system prompt that has worked most reliably under the name "reasoning_enforce_search".
- By ticking the checkbox "Enable thinking after searching" in the extension's settings, the model will resume thinking after each search. However, the main webUI only expects the model to think once at the start of the message, and so only the first thinking output will be put into a collapsible UI block. You can download a patch here that fixes this. Download and extract it, then navigate to your
text-generation-webuidirectory, put the patch file there and finally rungit apply ooba_multi_thinking.patch
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM_Web_search
Similar Open Source Tools
LLM_Web_search
LLM_Web_search project gives local LLMs the ability to search the web by outputting a specific command. It uses regular expressions to extract search queries from model output and then utilizes duckduckgo-search to search the web. LangChain's Contextual compression and Okapi BM25 or SPLADE are used to extract relevant parts of web pages in search results. The extracted results are appended to the model's output.
llmap
LLMap is a CLI code search tool designed to automatically find context in large codebases by evaluating the relevance of each source file using DeepSeek-V3 and DeepSeek-R1. It optimizes analysis by performing multi-stage analysis and caching results for faster searches. Currently supports Java and Python files, with potential for extension to other languages. Install with 'pip install llmap-ai' and use with a DeepSeek API key to search for specific context in code.
roam-extension-live-ai-assistant
Live AI is an AI Assistant tailor-made for Roam, providing access to the latest LLMs directly in Roam blocks. Users can interact with AI to extend their thinking, explore their graph, and chat with structured responses. The tool leverages Roam's features to write prompts, query graph parts, and chat with content. Users can dictate, translate, transform, and enrich content easily. Live AI supports various tasks like audio and video analysis, PDF reading, image generation, and web search. The tool offers features like Chat panel, Live AI context menu, and Ask Your Graph agent for versatile usage. Users can control privacy levels, compare AI models, create custom prompts, and apply styles for response formatting. Security concerns are addressed by allowing users to control data sent to LLMs.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
llms-txt
The llms-txt repository proposes a standardization on using an `/llms.txt` file to provide information to help large language models (LLMs) use a website at inference time. The `llms.txt` file is a markdown file that offers brief background information, guidance, and links to more detailed information in markdown files. It aims to provide concise and structured information for LLMs to access easily, helping users interact with websites via AI helpers. The repository also includes tools like a CLI and Python module for parsing `llms.txt` files and generating LLM context from them, along with a sample JavaScript implementation. The proposal suggests adding clean markdown versions of web pages alongside the original HTML pages to facilitate LLM readability and access to essential information.
ai-video-search-engine
AI Video Search Engine (AVSE) is a video search engine powered by the latest tools in AI. It allows users to search for specific answers within millions of videos by indexing video content. The tool extracts video transcription, elements like thumbnail and description, and generates vector embeddings using AI models. Users can search for relevant results based on questions, view timestamped transcripts, and get video summaries. AVSE requires a paid Supabase & Fly.io account for hosting and can handle millions of videos with the current setup.
For similar tasks
LLM_Web_search
LLM_Web_search project gives local LLMs the ability to search the web by outputting a specific command. It uses regular expressions to extract search queries from model output and then utilizes duckduckgo-search to search the web. LangChain's Contextual compression and Okapi BM25 or SPLADE are used to extract relevant parts of web pages in search results. The extracted results are appended to the model's output.
node-llama-cpp
node-llama-cpp is a tool that allows users to run AI models locally on their machines. It provides pre-built bindings with the option to build from source using cmake. Users can interact with text generation models, chat with models using a chat wrapper, and force models to generate output in a parseable format like JSON. The tool supports Metal and CUDA, offers CLI functionality for chatting with models without coding, and ensures up-to-date compatibility with the latest version of llama.cpp. Installation includes pre-built binaries for macOS, Linux, and Windows, with the option to build from source if binaries are not available for the platform.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
elmer
Elmer is a user-friendly wrapper over common APIs for calling llm’s, with support for streaming and easy registration and calling of R functions. Users can interact with Elmer in various ways, such as interactive chat console, interactive method call, programmatic chat, and streaming results. Elmer also supports async usage for running multiple chat sessions concurrently, useful for Shiny applications. The tool calling feature allows users to define external tools that Elmer can request to execute, enhancing the capabilities of the chat model.
mlx-lm
MLX LM is a Python package designed for generating text and fine-tuning large language models on Apple silicon using MLX. It offers integration with the Hugging Face Hub for easy access to thousands of LLMs, support for quantizing and uploading models to the Hub, low-rank and full model fine-tuning capabilities, and distributed inference and fine-tuning with `mx.distributed`. Users can interact with the package through command line options or the Python API, enabling tasks such as text generation, chatting with language models, model conversion, streaming generation, and sampling. MLX LM supports various Hugging Face models and provides tools for efficient scaling to long prompts and generations, including a rotating key-value cache and prompt caching. It requires macOS 15.0 or higher for optimal performance.

mini-sglang
Mini-SGLang is a lightweight yet high-performance inference framework for Large Language Models. With a compact codebase of ~5,000 lines of Python, it serves as both a capable inference engine and a transparent reference for researchers and developers. It achieves state-of-the-art throughput and latency with advanced optimizations such as Radix Cache, Chunked Prefill, Overlap Scheduling, Tensor Parallelism, and Optimized Kernels integrating FlashAttention and FlashInfer for maximum efficiency. Mini-SGLang is designed to demystify the complexities of modern LLM serving systems, providing a clean, modular, and fully type-annotated codebase that is easy to understand and modify.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.