
ollama-autocoder
A simple to use Ollama autocompletion engine with options exposed and streaming functionality
Stars: 92
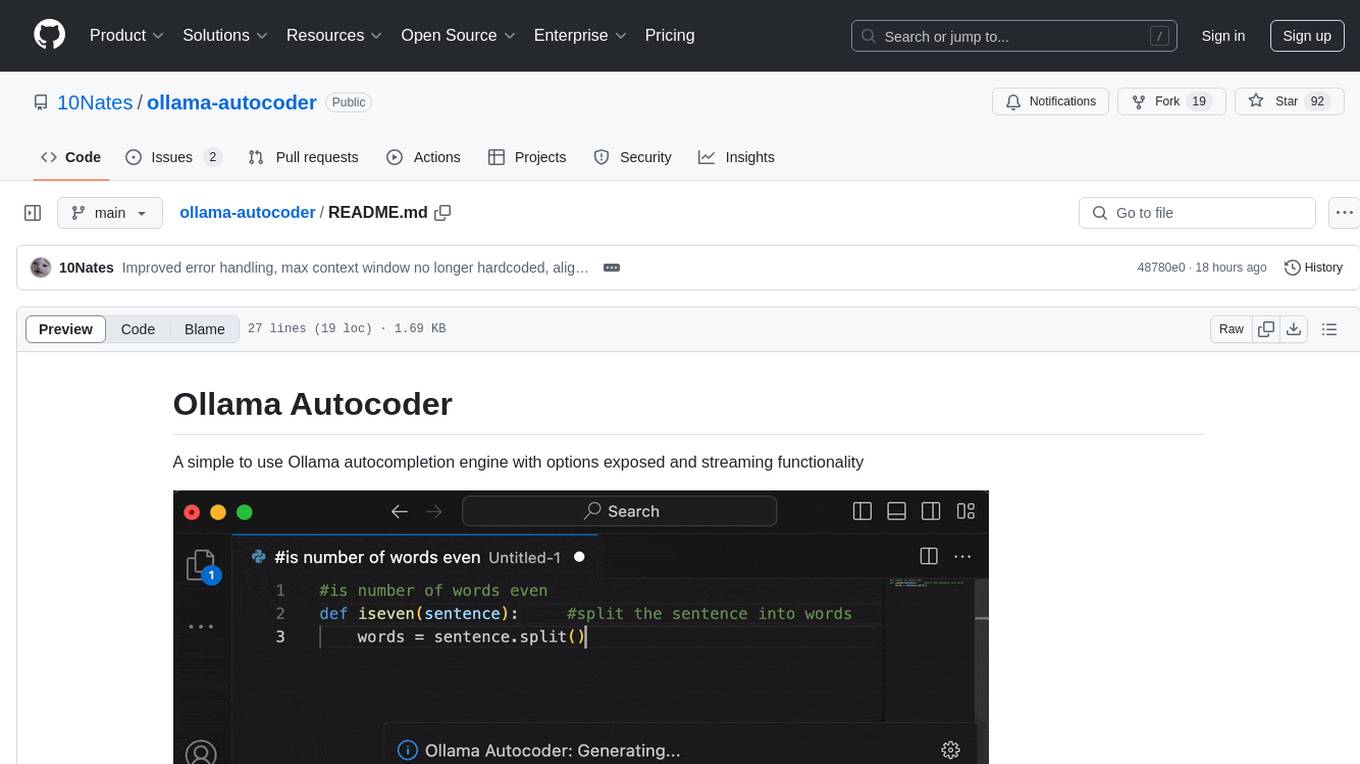
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
README:
A simple to use Ollama autocompletion engine with options exposed and streaming functionality

- Ollama must be serving on the API endpoint applied in settings
- For installation of Ollama, visit ollama.ai
- Ollama must have the
modelapplied in settings installed. The current default isqwen2.5-coder:latest. - The
prompt window sizeshould align with the maximum context window of the model.
- In a text document, press space (or any character in the
completion keyssetting). The optionAutocomplete with Ollamaor a preview of the first line of autocompletion will appear. Pressenterto start generation.- Alternatively, you can run the
Autocomplete with Ollamacommand from the command pallete (or set a keybind).
- Alternatively, you can run the
- After startup, the tokens will be streamed to your cursor.
- To stop the generation early, press the "Cancel" button on the "Ollama Autocoder" notification or type something.
- Once generation stops, the notification will disappear.
- For fastest results, an Nvidia GPU or Apple Silicon is recommended. CPU still works on small models.
- The prompt only sees behind the cursor. The model is unaware of text in front of its position.
- For CPU-only, low end, or battery powered devices, it is highly recommended to disable the
response previewoption, as it automatically triggers the model. This will causecontinue inlineto be always on. You can also increase thepreview delaytime. - If you don't want inline generation to continue beyond the response preview, change the
continue inlineoption in settings to false. This doesn't apply to the command pallete.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ollama-autocoder
Similar Open Source Tools
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
vigenair
ViGenAiR is a tool that harnesses the power of Generative AI models on Google Cloud Platform to automatically transform long-form Video Ads into shorter variants, targeting different audiences. It generates video, image, and text assets for Demand Gen and YouTube video campaigns. Users can steer the model towards generating desired videos, conduct A/B testing, and benefit from various creative features. The tool offers benefits like diverse inventory, compelling video ads, creative excellence, user control, and performance insights. ViGenAiR works by analyzing video content, splitting it into coherent segments, and generating variants following Google's best practices for effective ads.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.
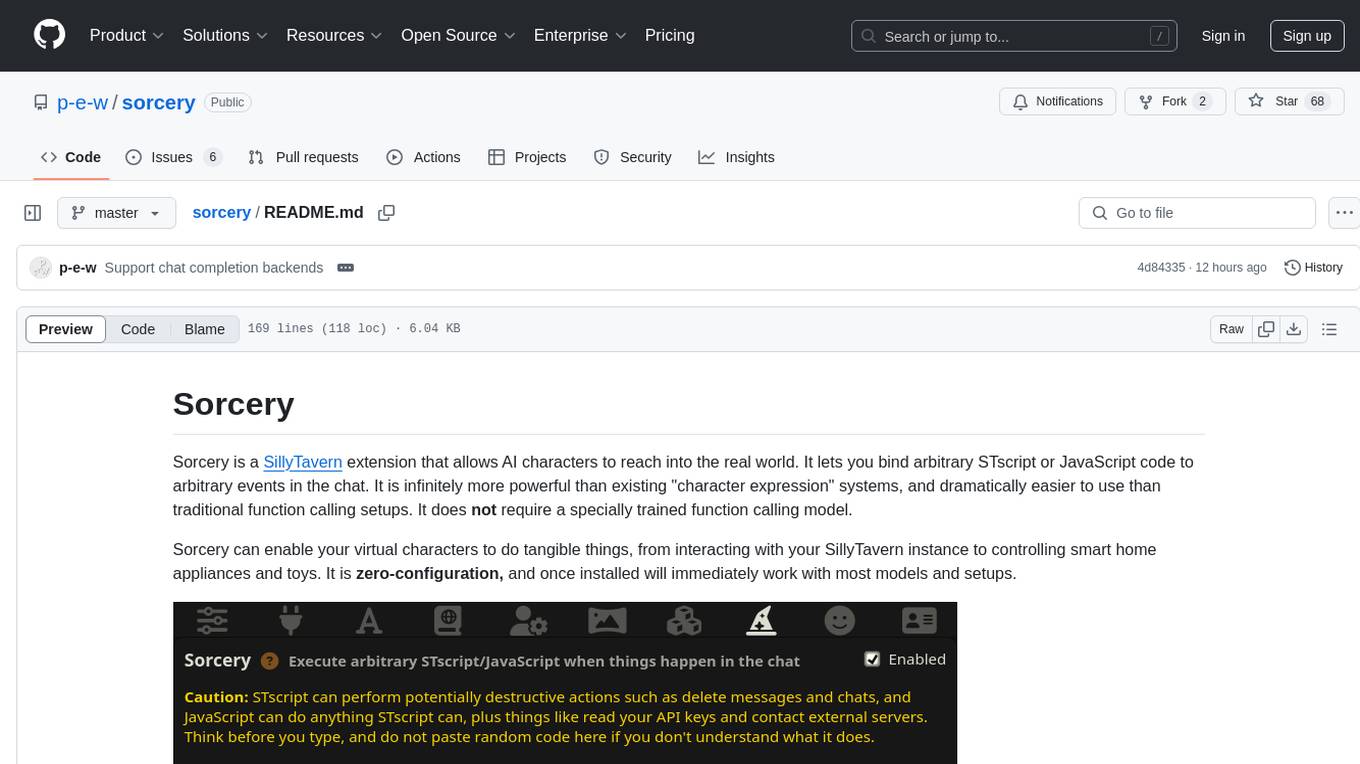
sorcery
Sorcery is a SillyTavern extension that allows AI characters to interact with the real world by executing user-defined scripts at specific events in the chat. It is easy to use and does not require a specially trained function calling model. Sorcery can be used to control smart home appliances, interact with virtual characters, and perform various tasks in the chat environment. It works by injecting instructions into the system prompt and intercepting markers to run associated scripts, providing a seamless user experience.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
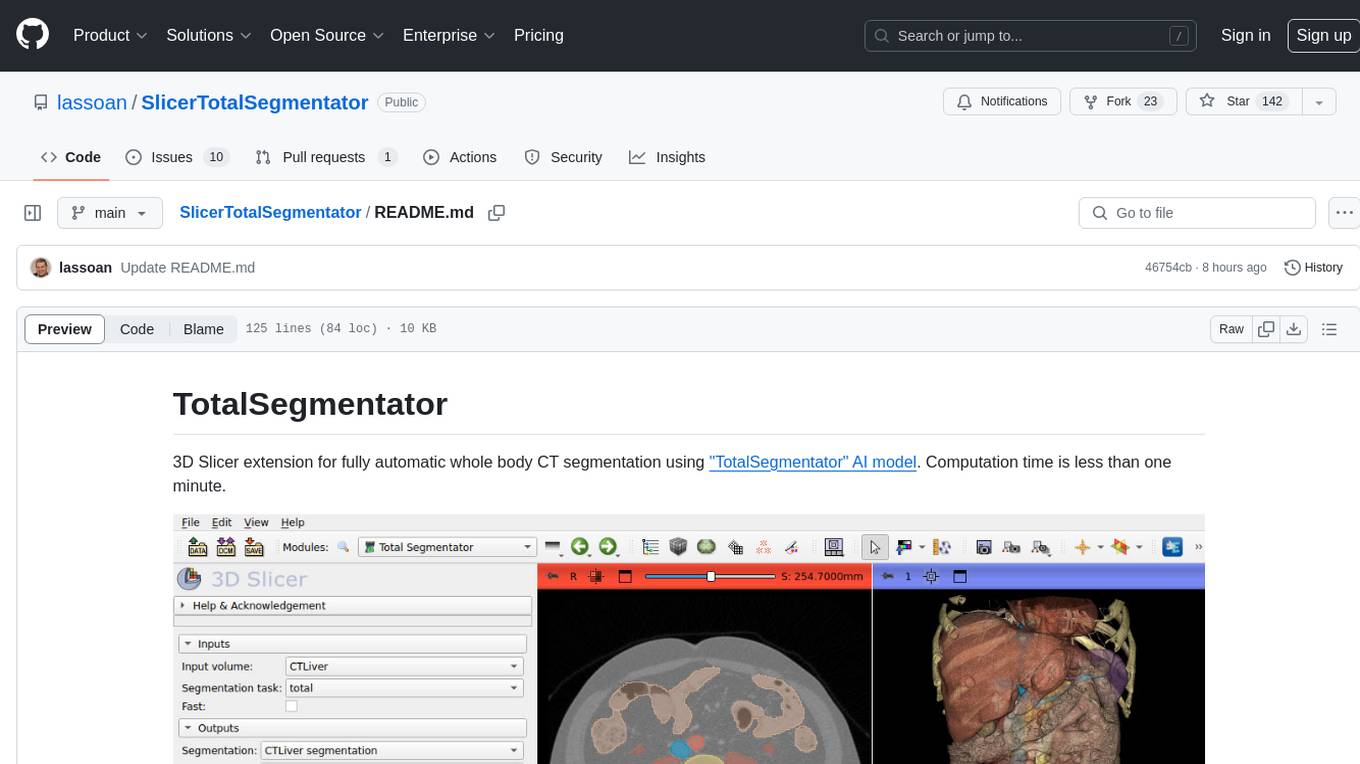
SlicerTotalSegmentator
TotalSegmentator is a 3D Slicer extension designed for fully automatic whole body CT segmentation using the 'TotalSegmentator' AI model. The computation time is less than one minute, making it efficient for research purposes. Users can set up GPU acceleration for faster segmentation. The tool provides a user-friendly interface for loading CT images, creating segmentations, and displaying results in 3D. Troubleshooting steps are available for common issues such as failed computation, GPU errors, and inaccurate segmentations. Contributions to the extension are welcome, following 3D Slicer contribution guidelines.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.
PolyMind
PolyMind is a multimodal, function calling powered LLM webui designed for various tasks such as internet searching, image generation, port scanning, Wolfram Alpha integration, Python interpretation, and semantic search. It offers a plugin system for adding extra functions and supports different models and endpoints. The tool allows users to interact via function calling and provides features like image input, image generation, and text file search. The application's configuration is stored in a `config.json` file with options for backend selection, compatibility mode, IP address settings, API key, and enabled features.
reai-ida
RevEng.AI IDA Pro Plugin is a tool that integrates with the RevEng.AI platform to provide various features such as uploading binaries for analysis, downloading analysis logs, renaming function names, generating AI summaries, synchronizing functions between local analysis and the platform, and configuring plugin settings. Users can upload files for analysis, synchronize function names, rename functions, generate block summaries, and explain function behavior using this plugin. The tool requires IDA Pro v8.0 or later with Python 3.9 and higher. It relies on the 'reait' package for functionality.
For similar tasks
chatflow
Chatflow is a tool that provides a chat interface for users to interact with systems using natural language. The engine understands user intent and executes commands for tasks, allowing easy navigation of complex websites/products. This approach enhances user experience, reduces training costs, and boosts productivity.
AiR
AiR is an AI tool built entirely in Rust that delivers blazing speed and efficiency. It features accurate translation and seamless text rewriting to supercharge productivity. AiR is designed to assist non-native speakers by automatically fixing errors and polishing language to sound like a native speaker. The tool is under heavy development with more features on the horizon.
awesome-ai-newsletters
Awesome AI Newsletters is a curated list of AI-related newsletters that provide the latest news, trends, tools, and insights in the field of Artificial Intelligence. It includes a variety of newsletters covering general AI news, prompts for marketing and productivity, AI job opportunities, and newsletters tailored for professionals in the AI industry. Whether you are a beginner looking to stay updated on AI advancements or a professional seeking to enhance your knowledge and skills, this repository offers a collection of valuable resources to help you navigate the world of AI.
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
witsy
Witsy is a generative AI desktop application that supports various models like OpenAI, Ollama, Anthropic, MistralAI, Google, Groq, and Cerebras. It offers features such as chat completion, image generation, scratchpad for content creation, prompt anywhere functionality, AI commands for productivity, expert prompts for specialization, LLM plugins for additional functionalities, read aloud capabilities, chat with local files, transcription/dictation, Anthropic Computer Use support, local history of conversations, code formatting, image copy/download, and more. Users can interact with the application to generate content, boost productivity, and perform various AI-related tasks.
codegate
CodeGate is a local gateway that enhances the safety of AI coding assistants by ensuring AI-generated recommendations adhere to best practices, safeguarding code integrity, and protecting individual privacy. Developed by Stacklok, CodeGate allows users to confidently leverage AI in their development workflow without compromising security or productivity. It works seamlessly with coding assistants, providing real-time security analysis of AI suggestions. CodeGate is designed with privacy at its core, keeping all data on the user's machine and offering complete control over data.

cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.