
GlaDOS
This is the Personality Core for GLaDOS, the first steps towards a real-life implementation of the AI from the Portal series by Valve.
Stars: 4246

This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
README:
This is a project dedicated to building a real-life version of GLaDOS!
NEW: If you want to chat or join the community, Join our discord! If you want to support, sponsor the project here!
https://github.com/user-attachments/assets/c22049e4-7fba-4e84-8667-2c6657a656a0
https://github.com/user-attachments/assets/99e599bb-4701-438a-a311-8e6cd595796c
This is really tricky, so only for hardcore geeks! Checkout the 'rock5b' branch, and my OpenAI API for the RK3588 NPU system Don't expect support for this, it's in active development, and requires lots of messing about in armbian linux etc.
This is a hardware and software project that will create an aware, interactive, and embodied GLaDOS.
This will entail:
- [x] Train GLaDOS voice generator
- [x] Generate a prompt that leads to a realistic "Personality Core"
- [ ] Generate a medium- and long-term memory for GLaDOS (Probably a custom vector DB in a simpy Numpy array!)
- [ ] Give GLaDOS vision via a VLM (either a full VLM for everything, or a 'vision module' using a tiny VLM the GLaDOS can function call!)
- [ ] Create 3D-printable parts
- [ ] Design the animatronics system
The initial goals are to develop a low-latency platform, where GLaDOS can respond to voice interactions within 600ms.
To do this, the system constantly records data to a circular buffer, waiting for voice to be detected. When it's determined that the voice has stopped (including detection of normal pauses), it will be transcribed quickly. This is then passed to streaming local Large Language Model, where the streamed text is broken by sentence, and passed to a text-to-speech system. This means further sentences can be generated while the current is playing, reducing latency substantially.
- The other aim of the project is to minimize dependencies, so this can run on constrained hardware. That means no PyTorch or other large packages.
- As I want to fully understand the system, I have removed a large amount of redirection: which means extracting and rewriting code.
This will be based on servo- and stepper-motors. 3D printable STL will be provided to create GlaDOS's body, and she will be given a set of animations to express herself. The vision system will allow her to track and turn toward people and things of interest.
Try this simplified process, but be aware it's still in the experimental stage! For all operating systems, you'll first need to install Ollama to run the LLM.
If you are an Nvidia system with CUDA, make sure you install the necessary drivers and CUDA, info here: https://onnxruntime.ai/docs/install/
If you are using another accelerator (ROCm, DirectML etc.), after following the instructions below for you platform, follow up with installing the best onnxruntime version for your system.
- Download and install Ollama for your operating system.
- Once installed, download a small 2B model for testing, at a terminal or command prompt use:
ollama pull llama3.2
Note: You can use any OpenAI or Ollama compatible server, local or cloud based. Just edit the glados_config.yaml and update the completion_url, model and the api_key if necessary.
- Open the Microsoft Store, search for
pythonand install Python 3.12 - Download this repository, either:
- Download and unzip this repository somewhere in your home folder, or
- If you have Git set up,
git clonethis repository usinggit clone github.com/dnhkng/glados.git
- In the repository folder, run the
install_windows.bat, and wait until the installation in complete. - Double click
start_windows.batto start GLaDOS!
This is still experimental. Any issues can be addressed in the Discord server. If you create an issue related to this, you will be referred to the Discord server. Note: I was getting Segfaults! Please leave feedback!
-
Download this repository, either:
- Download and unzip this repository somewhere in your home folder, or
- In a terminal,
git clonethis repository usinggit clone github.com/dnhkng/glados.git
-
In a terminal, go to the repository folder and run these commands:
chmod +x install_mac.command chmod +x start_mac.command -
In the Finder, double click
install_mac.command, and wait until the installation in complete. -
Double click
start_mac.commandto start GLaDOS!
This is still experimental. Any issues can be addressed in the Discord server. If you create an issue related to this, you will be referred to the Discord server. This has been tested on Ubuntu 24.04.1 LTS
-
Install the PortAudio library, if you don't yet have it installed:
sudo apt update sudo apt install libportaudio2 -
Download this repository, either:
- Download and unzip this repository somewhere in your home folder, or
- In a terminal,
git clonethis repository usinggit clone github.com/dnhkng/glados.git
-
In a terminal, go to the repository folder and run these commands:
chmod +x install_ubuntu.sh chmod +x start_ubuntu.sh -
In the a terminal in the GLaODS folder, run
./install_ubuntu.sh, and wait until the installation in complete. -
Run
./start_ubuntu.shto start GLaDOS!
To use other models, use the command:
ollama pull {modelname}
and then add {modelname} to glados_config.yaml as the model. You can find more models here!
- If you find you are getting stuck in loops, as GLaDOS is hearing herself speak, you have two options:
- Solve this by upgrading your hardware. You need to you either headphone, so she can't physically hear herself speak, or a conference-style room microphone/speaker. These have hardware sound cancellation, and prevent these loops.
- Disable voice interruption. This means neither you nor GLaDOS can interrupt when GLaDOS is speaking. To accomplish this, edit the
glados_config.yaml, and changeinterruptible:tofalse.
- If you want to the the Text UI, you should use the glados-ui.py file instead of glado.py
You can test the systems by exploring the 'demo.ipynb'.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for GlaDOS
Similar Open Source Tools
GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
GLaDOS
GLaDOS Personality Core is a project dedicated to building a real-life version of GLaDOS, an aware, interactive, and embodied AI system. The project aims to train GLaDOS voice generator, create a 'Personality Core,' develop medium- and long-term memory, provide vision capabilities, design 3D-printable parts, and build an animatronics system. The software architecture focuses on low-latency voice interactions and minimal dependencies. The hardware system includes servo- and stepper-motors, 3D printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions involve setting up a local LLM server, installing drivers, and running GLaDOS on different operating systems.
tau
Tau is a framework for building low maintenance & highly scalable cloud computing platforms that software developers will love. It aims to solve the high cost and time required to build, deploy, and scale software by providing a developer-friendly platform that offers autonomy and flexibility. Tau simplifies the process of building and maintaining a cloud computing platform, enabling developers to achieve 'Local Coding Equals Global Production' effortlessly. With features like auto-discovery, content-addressing, and support for WebAssembly, Tau empowers users to create serverless computing environments, host frontends, manage databases, and more. The platform also supports E2E testing and can be extended using a plugin system called orbit.

reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.
godot_rl_agents
Godot RL Agents is an open-source package that facilitates the integration of Machine Learning algorithms with games created in the Godot Engine. It provides interfaces for popular RL frameworks, support for memory-based agents, 2D and 3D games, AI sensors, and is licensed under MIT. Users can train agents in the Godot editor, create custom environments, export trained agents in ONNX format, and utilize advanced features like different RL training frameworks.
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
llmap
LLMap is a CLI code search tool designed to automatically find context in large codebases by evaluating the relevance of each source file using DeepSeek-V3 and DeepSeek-R1. It optimizes analysis by performing multi-stage analysis and caching results for faster searches. Currently supports Java and Python files, with potential for extension to other languages. Install with 'pip install llmap-ai' and use with a DeepSeek API key to search for specific context in code.
chord-seq-ai-app
ChordSeqAI Web App is a user-friendly interface for composing chord progressions using deep learning models. The app allows users to interact with suggestions, customize signatures, specify durations, select models and styles, transpose, import, export, and utilize chord variants. It supports keyboard shortcuts, automatic local saving, and playback features. The app is designed for desktop use and offers features for both beginners and advanced users in music composition.
qlora-pipe
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.

agno
Agno is a lightweight library for building multi-modal Agents. It is designed with core principles of simplicity, uncompromising performance, and agnosticism, allowing users to create blazing fast agents with minimal memory footprint. Agno supports any model, any provider, and any modality, making it a versatile container for AGI. Users can build agents with lightning-fast agent creation, model agnostic capabilities, native support for text, image, audio, and video inputs and outputs, memory management, knowledge stores, structured outputs, and real-time monitoring. The library enables users to create autonomous programs that use language models to solve problems, improve responses, and achieve tasks with varying levels of agency and autonomy.
trackmania_rl_public
This repository contains the reinforcement learning training code for Trackmania AI with Reinforcement Learning. It is a research work-in-progress project that aims to apply reinforcement learning principles to play Trackmania. The code is constantly evolving and may not be clean or easily usable. The training hyperparameters are intentionally changed in the public repository to encourage understanding of reinforcement learning principles. The project may not receive active support for setup or usage at the moment.
boxcars
Boxcars is a Ruby gem that enables users to create new systems with AI composability, incorporating concepts such as LLMs, Search, SQL, Rails Active Record, Vector Search, and more. It allows users to work with Boxcars, Trains, Prompts, Engines, and VectorStores to solve problems and generate text results. The gem is designed to be user-friendly for beginners and can be extended with custom concepts. Boxcars is actively seeking ways to enhance security measures to prevent malicious actions. Users can use Boxcars for tasks like running calculations, performing searches, generating Ruby code for math operations, and interacting with APIs like OpenAI, Anthropic, and Google SERP.
For similar tasks
GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
GLaDOS
GLaDOS Personality Core is a project dedicated to building a real-life version of GLaDOS, an aware, interactive, and embodied AI system. The project aims to train GLaDOS voice generator, create a 'Personality Core,' develop medium- and long-term memory, provide vision capabilities, design 3D-printable parts, and build an animatronics system. The software architecture focuses on low-latency voice interactions and minimal dependencies. The hardware system includes servo- and stepper-motors, 3D printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions involve setting up a local LLM server, installing drivers, and running GLaDOS on different operating systems.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
orcish-ai-nextjs-framework
The Orcish AI Next.js Framework is a powerful tool that leverages OpenAI API to seamlessly integrate AI functionalities into Next.js applications. It allows users to generate text, images, and text-to-speech based on specified input. The framework provides an easy-to-use interface for utilizing AI capabilities in application development.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
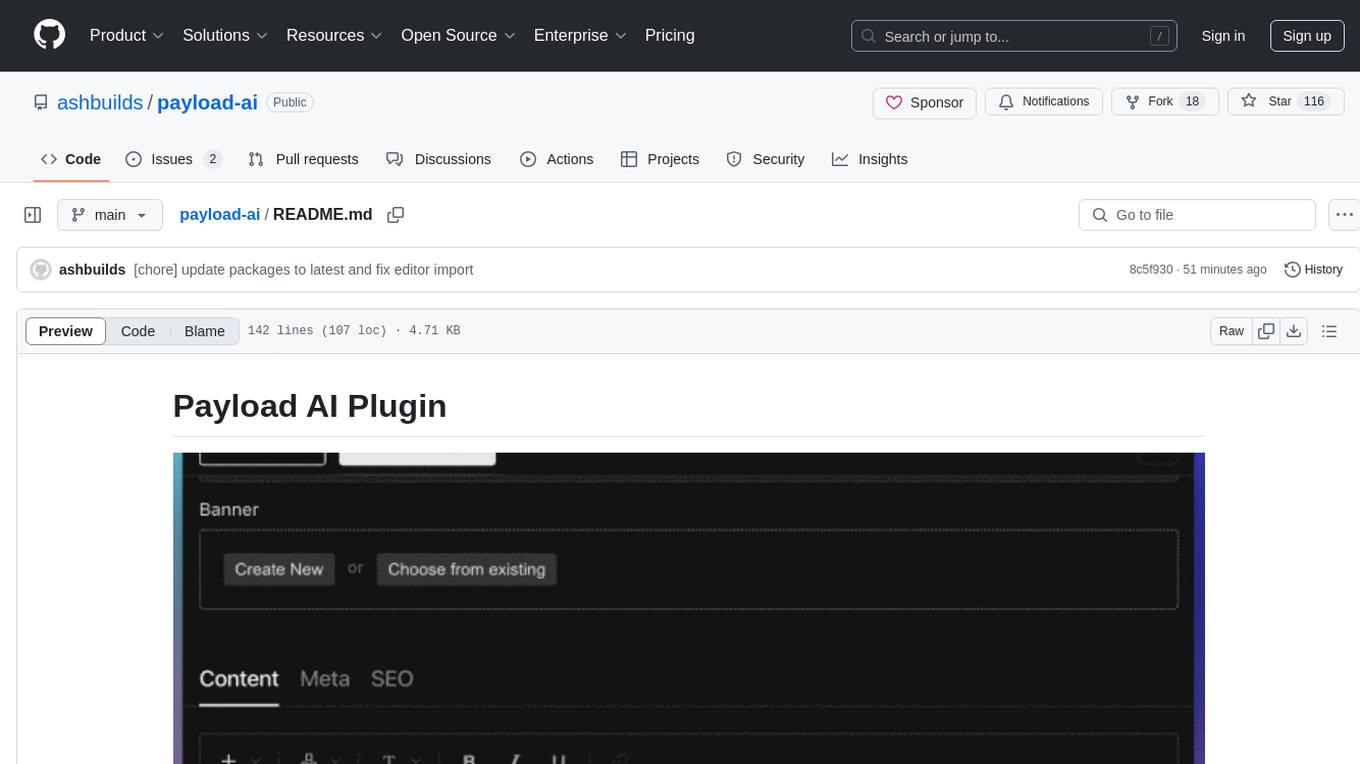
payload-ai
The Payload AI Plugin is an advanced extension that integrates modern AI capabilities into your Payload CMS, streamlining content creation and management. It offers features like text generation, voice and image generation, field-level prompt customization, prompt editor, document analyzer, fact checking, automated content workflows, internationalization support, editor AI suggestions, and AI chat support. Users can personalize and configure the plugin by setting environment variables. The plugin is actively developed and tested with Payload version v3.2.1, with regular updates expected.
QFurina
QFurina is a powerful and easily extensible Python QQ robot backend service that provides a range of automation and interactive features. It supports multiple messaging platforms and has a robust plugin system, allowing users to easily expand and customize functionality.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.