
reverse-engineering-assistant
An AI assistant for reverse engineering tasks 👩💻
Stars: 219

ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.
README:
Updated demo coming soon!
The reverse engineering assistant (ReVA) is a project to build a disassembler agnostic AI assistant for reverse engineering tasks. This includes both offline and online inference and a simple architecture.
ReVa is different from other efforts at building AI assistants for RE tasks because it uses a tool driven approach. ReVa aims to provide a variety of small tools to the LLM, just as your RE environment provides a set of small tools to you. ReVa combines this approach with chain-of-reasoning techniques to empower the LLM to complete complex tasks.
Each of the tools given to the LLM are constructed to be easy for the LLM to use and to tolerate a variety of inputs and to reduce hallucination by the LLM. We do this by providing the LLM with a schema but tolerating other input, including descriptions that guide the LLM,and redirecting correctable mistakes back to the LLM, and including extra output to guide the next decision by the LLM.
For example, when the LLM requests decompilation from your RE tool, we will accept a raw address in hex, a raw address in base 10, a symbol name with a namespace, or a symbol. If the LLM gives us bad input we report this to the LLM along with instructions to correct the input (maybe encouraging it to use the function list for example). To encourage exploration as a human would, we report additional context like the namespace and cross references along with the decompilation, this is a small nudge to make the LLM explore the binary in the same way a human would.
Using this technique you can ask general questions and get relevant answers. The model prioritises information from the tools, but when there is no information it can still respond to generic questions from its training.
You can ask questions like:
- What are the interesting strings in this program?
- Does this program use encryption? Write a markdown report on the encryption and where it is used.
- Draw a class diagram using plantuml syntax.
- Start from main, examine the program in detail. Rename variables as you go and provide a summary of the program.
- Explain the purpose of the
__mod_initsegment. - What does
mmapreturn? - What does the function at address 0x80000 do?
- This is a CTF problem. Write a pwntools script to get the flag.
An important part of reverse engineering is the process. Many other tools simply ask a single question of the LLM, this means it is difficult to determine why a thing happened. In ReVa we break all actions down into small parts and include the LLMs thoughts in the output. This allows the analyst to monitor the LLMs actions and reasoning, aborting and changing the prompt if required.
RevA is based on langchain, which supports a number of models.
Built in support is provided for:
- OpenAI for online inference and easy setup (Needs an OpenAI API key)
- Ollama and any model it supports for local on-device inference or connecting to a self hosted remote inference server.
See Configuration for more information about settings for the providers.
Adding additional inference servers is easy if it is supported by langchain.
Configuration for ReVa is in the CodeBrowser Tool options. Open a program and go to Edit -> Tool Options -> ReVa.
There are options for:
- Selecting a provider (OpenAI or Ollama, others coming soon!)
- Enabling "Follow", this will move the Ghidra view to the location of things ReVa is examining or changing.
- Enabling "Auto-allow", ReVa will log her actions for the user to accept in the "ReVa Actions Log" window.
There are sections for the providers.
By default, the OpenAI key is loaded from the environment variable OPENAI_API_KEY. You can also set your key inside Ghidra. Setting the key back to the OPENAI_API_KEY value will clear the key from the Ghidra configuration and load it from the environment.
You can also select the model. By default gpt-4o is selected. This model works best with the tools and the prompt provided by ReVa.
gpt-4 also works well, but is slow and needs more prompting by the user to explore a binary.
Ollama is a local inference server. The default server is set to localhost, with the default Ollama port. You can change this to a remote server if you want to perform inference on a remote machine. This is useful for organisations that self host.
You can also select a model. The model must alread be loaded on the server. Good performance has been seen with:
mixtralllama3phi
RevA has a two step workflow.
- Open your RE tool and the program you want to examine
- Open the chat session.
ReVa uses an extension for your RE tool to perform analysis. See Ghidra Support below.
To ask questions and run the inference a command line tool is provided. Run reva-chat to begin the chat session. This command will find your open Ghidra
and connect to it. To open a new chat, run the command again in another terminal.
If you have more than one Ghidra open, you can select the right one with
reva-chat --project ${project-name}, if it is not set, reva-chat will
ask you which project you want to connect to.
To communicate between reva-server and the extension, gRPC is used. You can read more about that (here)[./DEVELOPER.md]. Building the source files from those protocol definitions is driven from the Makefile. To build the protocol source code files, run this command in the project's root:
make protocolFirst install the python component, I like to use pipx. Install it with something like:
pip install pipxIn the reverse-engineering-assistant folder, run:
pipx install .After installing the python project, pipx may warn you that you need to add a folder to your PATH environment variable. Make sure that the folder (now containing reva-server and reva-chat) are in your PATH variable. pipx can do it for you with this command:
pipx ensurepathThe extension will need to start reva-server, and you will need to run reva-chat. In case you do not want to add them to your PATH, see the Configuration section for how to set the path to the executables.
Once the reva-server has been started by the extension the chat can be started with:
reva-chatThe Python package must be installed for the Ghidra extension to work!
Follow the instructions in the ghidra-assistant plugin.
After installation, enable the ReVa Plugin extension in the CodeBrowser tool (Open a file and click: File -> Configure -> Miscellaneous).
If you want ReVa enabled by default, click File -> Save Tool to save the configuration.
If everything is working correctly you will see a ReVa menu on your menu bar.
You can modify the plugin configuration in Edit -> Tool Options -> ReVa.
Whenever ReVa performs an action it will create an undo point for each action. If ReVa renames 5 variables, this will be one undo.
ReVa adds an option to the CodeBrowser Tool's Window menu. Select Window -> ReVa Action Log to open the ReVa Action Log window.
This window shows actions ReVa has performed and would like to perform. You can accept or reject a change by double clicking the ✅ or ❌ icon. You can also go to the location the action will be performed by double clicking the address.
If you reject an action, ReVa will be told and she will move on.
You can also enable "Auto-allow" in the ReVa options. This will automatically accept all actions ReVa wants to perform.
ReVa also adds some elements to the Ghidra UI. You can either ask ReVa to do something in the chat window,
"Examine the variable usage in main in detail, rename the variables with more descriptive names.",
or use the menu system.
For example you can right click a variable in the decompilation, select Reva -> Rename variable and ReVa will perform the action.
Do you like my work? Want to support this project and others? Interested in how this project was designed and built? This project and many others are built live on my stream at https://twitch.tv/cyberkaida !
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for reverse-engineering-assistant
Similar Open Source Tools
reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
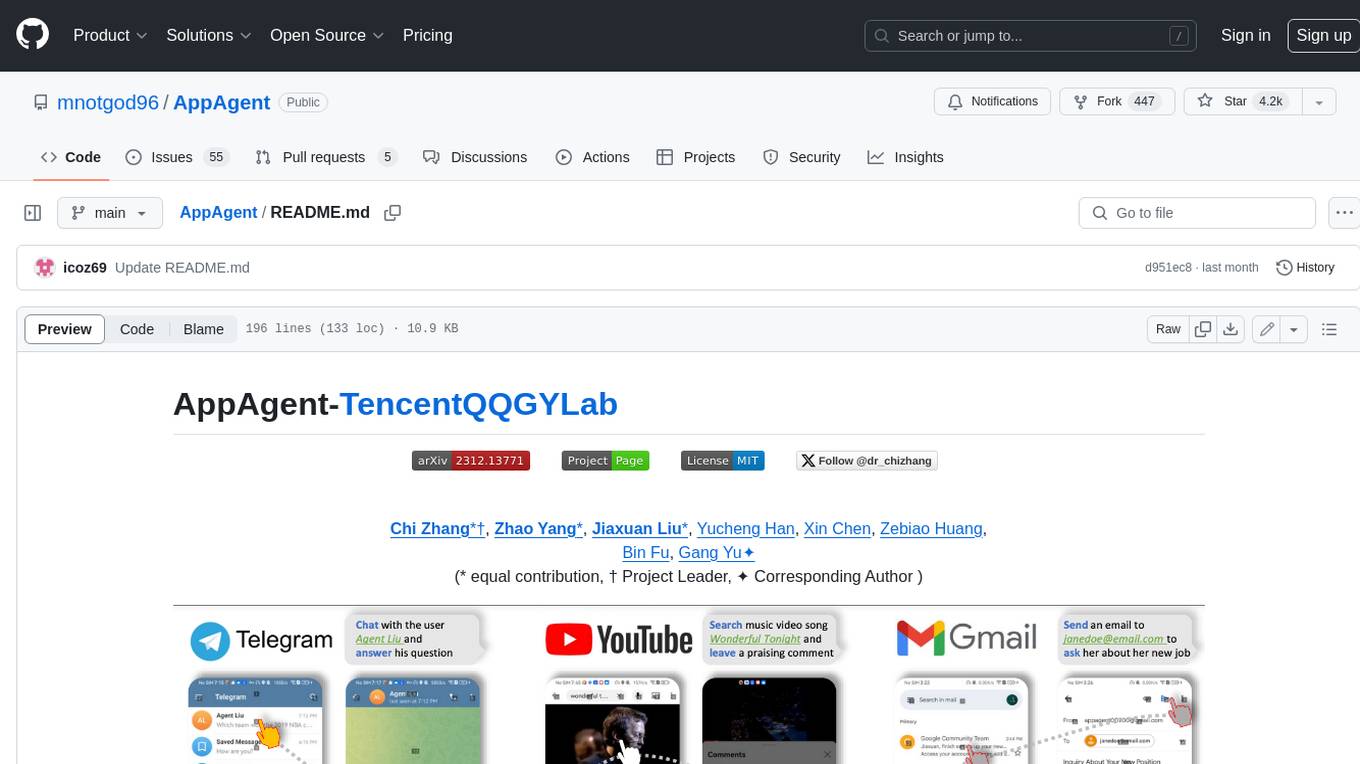
AppAgent
AppAgent is a novel LLM-based multimodal agent framework designed to operate smartphone applications. Our framework enables the agent to operate smartphone applications through a simplified action space, mimicking human-like interactions such as tapping and swiping. This novel approach bypasses the need for system back-end access, thereby broadening its applicability across diverse apps. Central to our agent's functionality is its innovative learning method. The agent learns to navigate and use new apps either through autonomous exploration or by observing human demonstrations. This process generates a knowledge base that the agent refers to for executing complex tasks across different applications.
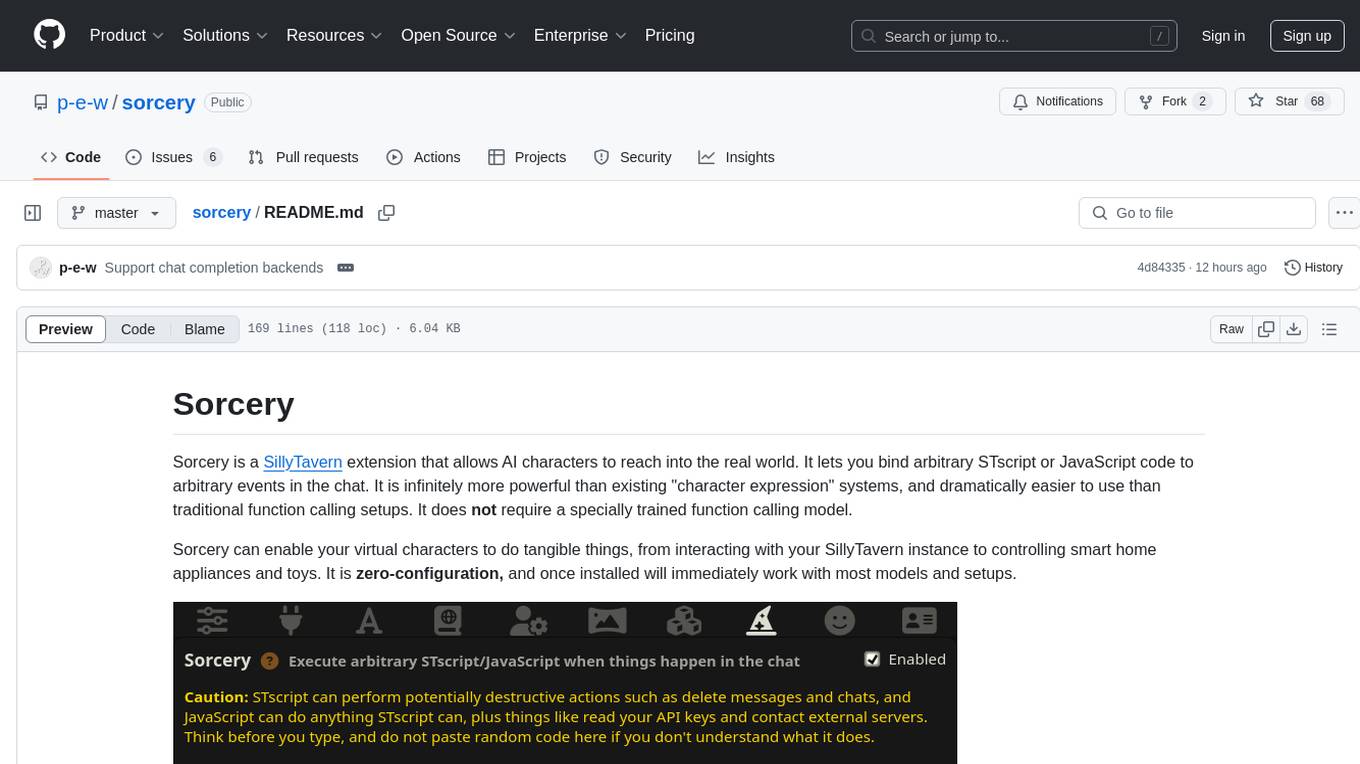
sorcery
Sorcery is a SillyTavern extension that allows AI characters to interact with the real world by executing user-defined scripts at specific events in the chat. It is easy to use and does not require a specially trained function calling model. Sorcery can be used to control smart home appliances, interact with virtual characters, and perform various tasks in the chat environment. It works by injecting instructions into the system prompt and intercepting markers to run associated scripts, providing a seamless user experience.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.
llmap
LLMap is a CLI code search tool designed to automatically find context in large codebases by evaluating the relevance of each source file using DeepSeek-V3 and DeepSeek-R1. It optimizes analysis by performing multi-stage analysis and caching results for faster searches. Currently supports Java and Python files, with potential for extension to other languages. Install with 'pip install llmap-ai' and use with a DeepSeek API key to search for specific context in code.
aicodeguide
AI Code Guide is a comprehensive guide that covers everything you need to know about using AI to help you code or even code for you. It provides insights into the changing landscape of coding with AI, new tools, editors, and practices. The guide aims to consolidate information on AI coding and AI-assisted code generation in one accessible place. It caters to both experienced coders looking to leverage AI tools and beginners interested in 'vibe coding' to build software products. The guide covers various topics such as AI coding practices, different ways to use AI in coding, recommended resources, tools for AI coding, best practices for structuring prompts, and tips for using specific tools like Claude Code.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.
LLocalSearch
LLocalSearch is a completely locally running search aggregator using LLM Agents. The user can ask a question and the system will use a chain of LLMs to find the answer. The user can see the progress of the agents and the final answer. No OpenAI or Google API keys are needed.
CustomSuggestionServiceForCopilotForXcode
This repository provides a custom suggestion service for Copilot for Xcode, allowing users to enhance code suggestions using chat models. It supports different suggestion services and strategies for generating code suggestions. Users can customize prompt formats and utilize local models for code completion.
For similar tasks
reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.
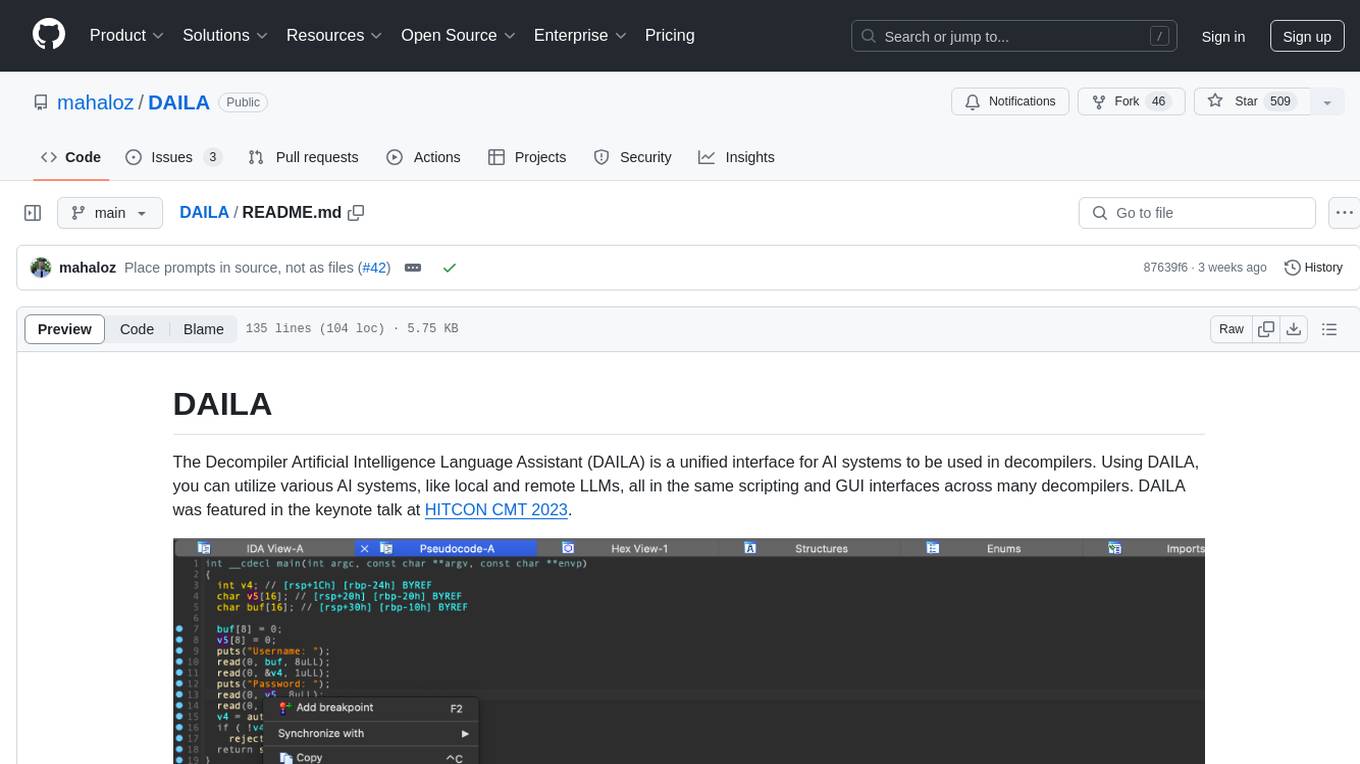
DAILA
DAILA is a unified interface for AI systems in decompilers, supporting various decompilers and AI systems. It allows users to utilize local and remote LLMs, like ChatGPT and Claude, and local models such as VarBERT. DAILA can be used as a decompiler plugin with GUI or as a scripting library. It also provides a Docker container for offline installations and supports tasks like summarizing functions and renaming variables in decompilation.
binary_ninja_mcp
This repository contains a Binary Ninja plugin, MCP server, and bridge that enables seamless integration of Binary Ninja's capabilities with your favorite LLM client. It provides real-time integration, AI assistance for reverse engineering, multi-binary support, and various MCP tools for tasks like decompiling functions, getting IL code, managing comments, renaming variables, and more.
For similar jobs
last_layer
last_layer is a security library designed to protect LLM applications from prompt injection attacks, jailbreaks, and exploits. It acts as a robust filtering layer to scrutinize prompts before they are processed by LLMs, ensuring that only safe and appropriate content is allowed through. The tool offers ultra-fast scanning with low latency, privacy-focused operation without tracking or network calls, compatibility with serverless platforms, advanced threat detection mechanisms, and regular updates to adapt to evolving security challenges. It significantly reduces the risk of prompt-based attacks and exploits but cannot guarantee complete protection against all possible threats.
aircrack-ng
Aircrack-ng is a comprehensive suite of tools designed to evaluate the security of WiFi networks. It covers various aspects of WiFi security, including monitoring, attacking (replay attacks, deauthentication, fake access points), testing WiFi cards and driver capabilities, and cracking WEP and WPA PSK. The tools are command line-based, allowing for extensive scripting and have been utilized by many GUIs. Aircrack-ng primarily works on Linux but also supports Windows, macOS, FreeBSD, OpenBSD, NetBSD, Solaris, and eComStation 2.
reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.
AutoAudit
AutoAudit is an open-source large language model specifically designed for the field of network security. It aims to provide powerful natural language processing capabilities for security auditing and network defense, including analyzing malicious code, detecting network attacks, and predicting security vulnerabilities. By coupling AutoAudit with ClamAV, a security scanning platform has been created for practical security audit applications. The tool is intended to assist security professionals with accurate and fast analysis and predictions to combat evolving network threats.
aif
Arno's Iptables Firewall (AIF) is a single- & multi-homed firewall script with DSL/ADSL support. It is a free software distributed under the GNU GPL License. The script provides a comprehensive set of configuration files and plugins for setting up and managing firewall rules, including support for NAT, load balancing, and multirouting. It offers detailed instructions for installation and configuration, emphasizing security best practices and caution when modifying settings. The script is designed to protect against hostile attacks by blocking all incoming traffic by default and allowing users to configure specific rules for open ports and network interfaces.

watchtower
AIShield Watchtower is a tool designed to fortify the security of AI/ML models and Jupyter notebooks by automating model and notebook discoveries, conducting vulnerability scans, and categorizing risks into 'low,' 'medium,' 'high,' and 'critical' levels. It supports scanning of public GitHub repositories, Hugging Face repositories, AWS S3 buckets, and local systems. The tool generates comprehensive reports, offers a user-friendly interface, and aligns with industry standards like OWASP, MITRE, and CWE. It aims to address the security blind spots surrounding Jupyter notebooks and AI models, providing organizations with a tailored approach to enhancing their security efforts.
Academic_LLM_Sec_Papers
Academic_LLM_Sec_Papers is a curated collection of academic papers related to LLM Security Application. The repository includes papers sorted by conference name and published year, covering topics such as large language models for blockchain security, software engineering, machine learning, and more. Developers and researchers are welcome to contribute additional published papers to the list. The repository also provides information on listed conferences and journals related to security, networking, software engineering, and cryptography. The papers cover a wide range of topics including privacy risks, ethical concerns, vulnerabilities, threat modeling, code analysis, fuzzing, and more.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.