
tts-generation-webui
TTS Generation Web UI (Bark, MusicGen + AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, MAGNet, StyleTTS2, MMS)
Stars: 1593

TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
README:
Download ||
Upgrading ||
Manual installation ||
Docker Setup || Configuration Guide || Discord Server || || Feedback / Bug reports
List of models: Bark, MusicGen + AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, MAGNeT, Stable Audio, Maha TTS, MMS, and more.
Note: Not all models support all platforms. For example, MusicGen and AudioGen are not supported on MacOS as of yet.
| Bark TTS, Seamless Translation, RVC, Music Generation and More | TTS Generation WebUI - A Tool for Text to Speech and Voice Cloning | Text to speech and voice cloning - TTS Generation WebUI |
|---|---|---|
 |
 |
 |
Aug 5:
- Fix Bark in React UI, add Max Generation Duration.
- Change AudioCraft Plus extension models directory to ./data/models/audiocraft_plus/
- Improve model unloading for MusicGen and AudioGen. Add unload models button to MusicGen and AudioGen.
- Add Huggingface Cache Manager extension.
Aug 4:
- Add XTTS-RVC-UI extension, XTTS Fine-tuning demo extension.
Aug 3:
- Add Riffusion extension, AudioCraft Mac extension, Bark Legacy extension.
Aug 2:
- Add deprecation warning to old installer.
- Unify error handling and simplify tab loading.
Aug 1:
- Add "Attempt Update" button for external extensions.
- Skip reinstalling packages when pip_packages version is not changed.
- Synchronize Gradio Port with React UI.
- Change default Gradio port to 7770 from 7860.
Click to expand
July 31:
- Fix React UI's MusicGen after the Gradio changes.
- Add unload button to Whisper extension.
July 29:
- Change FFMpeg to 4.4.2 from conda-forge in order to support more platforms, including Mac M1.
- Disable tortoise CVVP.
July 26:
- Whisper extension
- Experimental AMD ROCM install support. (Linux only)
July 25:
- Add diagnostic scripts for MacOS and Linux.
- Add better error details for tabs.
- Fix .sh script execution permissions for the installers on Linux and MacOS.
July 21:
- Add Gallery History extension (adapted from the old gallery view)
- Convert Simple Remixer to extension
- Fix update.py to use the newer torch versions (update.py is only for legacy purposes and will likely break)
- Add Diagnostic script and Force Reinstall scripts for Windows.
July 20:
- Fix Discord join link
- Simplify Bark further, removing excessive complexity in code.
- Add UI/Modular extensions, these extensions allow installing new models and features to the UI. In the future, models will start as extensions before being added permamently.
- Disable Gallery view in outputs
- Known issue: Firefox fails at showing outputs in Gradio, it fails at fetching them from backend. Within React UI this works fine.
July 15:
- Comment - As the React UI has been out for a long time now, Gradio UI is going to have the role of serving only the functions to the user, without the extremely complicated UI that it cannot handle. There is a real shortage of development time to add new models and features, but the old style of integration was not viable. As the new APIs and 'the role of the model' is defined, it will be possible to have extensions for entire models, enabling a lot more flexibility and lighter installations.
- Start scaling back Gradio UI complexity - removed send to RVC/Demucs/Voice buttons. (Remove internal component Joutai).
- Add version.json for better updates in the future.
- Reduce Gradio Bark maximum number of outputs to 1.
- Add unload model button to Tortoise, also unload the model before loading the next one/changing parameters, thus tortoise no longer uses 2x model memory during the settings change.
July 14:
- Regroup Gradio tabs into groups - Text to Speech, Audio Conversion, Music Generation, Outputs and Settings
- Clean up the header, add link for feedback
- Add seed control to Stable Audio
- Fix Stable Audio filename bug with newlines
- Disable "Simple Remixer" Gradio tab
- Fix bark voice clone & RVC once more
- Add "Installed Packages" tab for debugging
July 13:
- Major upgrade to Torch 2.3.1 and xformers 0.0.27
- All users, including Mac and CPU will now have the same PyTorch version.
- Upgrade CUDA to 11.8
- Force python to be 3.10.11
- Modify installer to allow upgrading Python and Torch without reinstalling (currently major version 2)
- Fix magnet default params for better quality
- Improve installer script checks to avoid bugs
- Update StyleTTS2
July 11:
- Improve Stable Audio generation filenames
- Add force reinstall to torch repair
- Make the installer auto-update before running
July 9:
- Fix new installer and installation instructions thanks to https://github.com/Xeraster !
July 8:
- Change the installation process to reduce package clashes and enable torch version flexibility.
July 6:
- Initial release of new mamba based installer.
- Save Stable Audio results to outputs-rvc/StableAudio folder.
- Add a disclaimer to Stable Audio model selection and show better error messages when files are missing.
July 1:
- Optimize Stable Audio memory usage after generation.
- Open React UI automatically only if gradio also opens automatically.
- Remove unnecessary conda git reinstall.
- Update to lastest Stable Audio which has mps support (requires newer torch versions).
Click to expand
June 22: * Add Stable Audio to Gradio.June 21:
- Add Vall-E-X demo to React UI.
- Open React UI automatically in browser, fix the link again.
- Add Split By Length to React/Tortoise.
- Fix UVR5 demo folders.
- Set fairseq version to 0.12.2 for Linux and Mac. (#323)
- Improve generation history for all React UI tabs.
May 17:
- Fix Tortoise presets in React UI.
May 9:
- Add MMS to React UI.
- Improve React UI and codebase.
May 4:
- Group Changelog by month
Click to expand
Apr 28: * Add Maha TTS to React UI. * Add GPU Info to React UI.Apr 6:
- Add Vall-E-X generation demo tab.
- Add MMS demo tab.
- Add Maha TTS demo tab.
- Add StyleTTS2 demo tab.
Apr 5:
- Fix RVC installation bug.
- Add basic UVR5 demo tab.
Apr 4:
- Upgrade RVC to include RVMPE and FCPE. Remove the direct file input for models and indexes due to file duplication. Improve React UI interface for RVC.
Click to expand
Mar 28:
- Add GPU Info tab
Mar 27:
- Add information about voice cloning to tab voice clone
Mar 26:
- Add Maha TTS demo notebook
Mar 22:
- Vall-E X demo via notebook (#292)
- Add React UI to Docker image
- Add install disclaimer
Mar 16:
- Upgrade vocos to 0.1.0
Mar 14:
- StyleTTS2 Demo Notebook
Mar 13:
- Add Experimental Pipeline (Bark / Tortoise / MusicGen / AudioGen / MAGNeT -> RVC / Demucs / Vocos) (#287)
- Fix RVC bug with model reloading on each generation. For short inputs that results in a visible speedup.
Mar 11:
- Add Play as Audio and Save to Voices to bark (#286)
- Change UX to show that files are deleted from favorites
- Fix images for bark voices not showing
- Fix audio playback in favorites
Mar 10:
- Add Batching to React UI Magnet (#283)
- Add audio to audio translation to SeamlessM4T (#284)
Mar 5:
- Add Batching to React UI MusicGen (#281), thanks to https://github.com/Aamir3d for requesting this and providing feedback
Mar 3:
- Add MMS demo as a notebook
- Add MultiBandDiffusion high VRAM disclaimer
Click to expand
Feb 21:
- Fix Docker container builds and bug with Docker-Audiocraft
Feb 8:
- Fix MultiBandDiffusion for MusicGen's stereo models, thank you https://github.com/mykeehu
- Fix Node.js installation steps on Google Colab, code by https://github.com/miaohf
Feb 6:
- Add FLAC file generation extension by https://github.com/JoaCHIP
Click to expand
Jan 21:
- Add CPU/M1 torch auto-repair script with each update. To disable, edit check_cuda.py and change FORCE_NO_REPAIR = True
Jan 16:
- Upgrade MusicGen, adding support for stereo and large melody models
- Add MAGNeT
Jan 15:
- Upgraded Gradio to 3.48.0
- Several visual bugs have appeared, if they are critical, please report them or downgrade gradio.
- Gradio: Suppress useless warnings
- Supress Triton warnings
- Gradio-Bark: Fix "Use last generation as history" behavior, empty selection no longer errors
- Improve extensions loader display
- Upgrade transformers to 4.36.1 from 4.31.0
- Add SeamlessM4T Demo
Jan 14:
- React UI: Fix missing directory errors
Jan 13:
- React UI: Fix missing npm build step from automatic install
Jan 12:
- React UI: Fix names for audio actions
- Gradio: Fix multiple API warnings
- Integration - React UI now is launched alongside Gradio, with a link to open it
Jan 11:
- React UI: Make the build work without any errors
Jan 9:
- React UI
- Fix 404 handler for Wavesurfer
- Group Bark tabs together
Jan 8:
- Release React UI
Click to expand
Oct 26:
- Improve model selection UX for Musicgen
Oct 24:
- Add initial React UI for Musicgen and Demucs (https://github.com/rsxdalv/tts-generation-webui/pull/202)
- Fix Bark long generation seed drifting (thanks to https://github.com/520Pig520)
Sep 21:
- Bark: Add continue as semantic history button
- Switch to github docker image storage, new docker image:
docker pull ghcr.io/rsxdalv/tts-generation-webui:main
- Fix server_port option in config https://github.com/rsxdalv/tts-generation-webui/issues/168 , thanks to https://github.com/Dartvauder
Sep 9:
- Fix xdg-open command line, thanks to https://github.com/JFronny
- Fix multi-line bark generations, thanks to https://github.com/slack-t and https://github.com/bkutasi
- Add unload model button to Bark as requested by https://github.com/Aamir3d
- Add Bark details to README_Bark.md as requested by https://github.com/Maki9009
- Add "optional" to burn in prompt, thanks to https://github.com/Maki9009
Sep 5:
- Add voice mixing to Bark
- Add v1 Burn in prompt to Bark (Burn in prompts are for directing the semantic model without spending time on generating the audio. The v1 works by generating the semantic tokens and then using it as a prompt for the semantic model.)
- Add generation length limiter to Bark
Aug 27:
- Fix MusicGen ignoring the melody https://github.com/rsxdalv/tts-generation-webui/issues/153
Aug 26:
- Add Send to RVC, Demucs, Vocos buttons to Bark and Vocos
Aug 24:
- Add date to RVC outputs to fix https://github.com/rsxdalv/tts-generation-webui/issues/147
- Fix safetensors missing wheel
- Add Send to demucs button to musicgen
Aug 21:
- Add torchvision install to colab for musicgen issue fix
- Remove rvc_tab file logging
Aug 20:
- Fix MBD by reinstalling hydra-core at the end of an update
Aug 18:
- CI: Add a GitHub Action to automatically publish docker image.
Aug 16:
- Add "name" to tortoise generation parameters
Aug 15:
- Pin torch to 2.0.0 in all requirements.txt files
- Bump audiocraft and bark versions
- Remove Tortoise transformers fix from colab
- Update Tortoise to 2.8.0
Aug 13:
- Potentially big fix for new user installs that had issues with GPU not being supported
Aug 11:
- Tortoise hotfix thanks to manmay-nakhashi
- Add Tortoise option to change tokenizer
Aug 8:
- Update AudioCraft, improving MultiBandDiffusion performance
- Fix Tortoise parameter 'cond_free' mismatch with 'ultra_fast' preset
Aug 7:
- add tortoise deepspeed fix to colab
Aug 6:
- Fix audiogen + mbd error, add tortoise fix for colab
Aug 4:
- Add MultiBandDiffusion option to MusicGen https://github.com/rsxdalv/tts-generation-webui/pull/109
- MusicGen/AudioGen save tokens on generation as .npz files.
Aug 3:
Aug 2:
- Fix Model locations not showing after restart
July 26:
- Voice gallery
- Voice cropping
- Fix voice rename bug, rename picture as well, add a hash textbox
- Easier downloading of voices (https://github.com/rsxdalv/tts-generation-webui/pull/98)
July 24:
- Change bark file format to include history hash: ...continued_generation... -> ...from_3ea0d063...
July 23:
- Docker Image thanks to https://github.com/jonfairbanks
- RVC UI naming improvements
July 21:
- Fix hubert not working with CPU only (https://github.com/rsxdalv/tts-generation-webui/pull/87)
- Add Google Colab demo (https://github.com/rsxdalv/tts-generation-webui/pull/88)
- New settings tab and model locations (for advanced users) (https://github.com/rsxdalv/tts-generation-webui/pull/90)
July 19:
- Add Tortoise Optimizations, Thank you https://github.com/manmay-nakhashi https://github.com/rsxdalv/tts-generation-webui/pull/79 (Implements https://github.com/rsxdalv/tts-generation-webui/issues/18)
July 16:
- Voice Photo Demo
- Add a directory to store RVC models/indexes in and a dropdown
- Workaround rvc not respecting is_half for CPU https://github.com/rsxdalv/tts-generation-webui/pull/74
- Tortoise model and voice selection improvements https://github.com/rsxdalv/tts-generation-webui/pull/73
July 10:
July 9:
- RVC Demo + Tortoise, v6 installer with update script and automatic attempts to install extra modules https://github.com/rsxdalv/tts-generation-webui/pull/66
July 5:
- Improved v5 installer - faster and more reliable https://github.com/rsxdalv/tts-generation-webui/pull/63
July 2:
- Upgrade bark settings https://github.com/rsxdalv/tts-generation-webui/pull/59
July 1:
Jun 29:
- Tortoise new params https://github.com/rsxdalv/tts-generation-webui/pull/54
Jun 27:
- Fix eager loading errors, refactor https://github.com/rsxdalv/tts-generation-webui/pull/50
Jun 20
- Tortoise: proper long form generation files https://github.com/rsxdalv/tts-generation-webui/pull/46
Jun 19
- Tortoise-upgrade https://github.com/rsxdalv/tts-generation-webui/pull/45
June 18:
- Update to newest audiocraft, add longer generations
Jun 14:
- add vocos wav tab https://github.com/rsxdalv/tts-generation-webui/pull/42
June 5:
- Fix "Save to Favorites" button on bark generation page, clean up console (v4.1.1)
- Add "Collections" tab for managing several different data sets and easier curration.
June 4:
- Update to v4.1 - improved hash function, code improvements
June 3:
- Update to v4 - new output structure, improved history view, codebase reorganization, improved metadata, output extensions support
May 21:
- Update to v3 - voice clone demo
May 17:
- Update to v2 - generate results as they appear, preview long prompt generations piece by piece, enable up to 9 outputs, UI tweaks
May 16:
- Add gradio settings tab, fix gradio errors in console, improve logging.
- Update History and Favorites with "use as voice" and "save voice" buttons
- Add voices tab
- Bark tab: Remove "or Use last generation as history"
- Improve code organization
May 13:
- Enable deterministic generation and enhance generated logs. Credits to https://github.com/suno-ai/bark/pull/175.
May 10:
- Enable the possibility of reusing history prompts from older generations. Save generations as npz files. Add a convenient method of reusing any of the last 3 generations for the next prompts. Add a button for saving and collecting history prompts under /voices. https://github.com/rsxdalv/tts-generation-webui/pull/10
May 4:
- Long form generation (credits to https://github.com/suno-ai/bark/blob/main/notebooks/long_form_generation.ipynb and https://github.com/suno-ai/bark/issues/161)
- Adapt to fixed env var bug
May 3:
- Improved Tortoise UI: Voice, Preset and CVVP settings as well as ability to generate 3 results (https://github.com/rsxdalv/tts-generation-webui/pull/6)
May 2:
- Added support for history recylcing to continue longer prompts manually
- Added support for v2 prompts
Before:
- Added support for Tortoise TTS
In case of issues, feel free to contact the developers.
- Download the new version and run the start_tts_webui.bat (Windows) or start_tts_webui.sh (MacOS, Linux)
- Once it is finished, close the server.
- Recommended: Copy the old generations to the new directory, such as favorites/ outputs/ outputs-rvc/ models/ collections/ config.json
- With caution: you can copy the whole new tts-generation-webui directory over the old one, but there might be some old files that are lost.
- Update the existing installation using the update_platform script
- After the update run the new start_tts_webui.bat (Windows) or start_tts_webui.sh (MacOS, Linux) inside of the tts-generation-webui directory
- Once the server starts, check if it works.
- With caution: if the new server works, within the one-click-installers directory, delete the old installer_files.
Not exactly, the dependencies clash, especially between conda and python (and dependencies are already in a critical state, moving them to conda is ways off). Therefore, while it might be possible to just replace the old installer with the new one and running the update, the problems are unpredictable and unfixable. Making an update to installer requires a lot of testing so it's not done lightly.
- Download the repository as a zip file and extract it.
- Run start_tts_webui.bat or start_tts_webui.sh to start the server. The server will be available at http://localhost:7860
- Output log will be available in the installer_scripts/output.log file.
-
These instructions might not reflect all of the latest fixes and adjustments, but could be useful as a reference for debugging or understanding what the installer does. Hopefully they can be a basis for supporting new platforms, such as AMD/Intel.
-
Install conda (https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html)
-
Set up an environment:
conda create -n venv python=3.10 -
Install git, node.js
conda install -y -c conda-forge git nodejs conda -
a) Either Continue with the installer script
- activate the environment:
conda activate venvand (venv) node installer_scripts\init_app.js- then run the server with
(venv) python server.py
- activate the environment:
-
b) Or install the requirements manually
- Set up pytorch with CUDA or CPU (https://pytorch.org/audio/stable/build.windows.html#install-pytorch):
-
(venv) conda install pytorch torchvision torchaudio cpuonly ffmpeg -c pytorchfor CPU/Mac -
(venv) conda install -y -k pytorch[version=2,build=py3.10_cuda11.7*] torchvision torchaudio pytorch-cuda=11.7 cuda-toolkit ninja ffmpeg -c pytorch -c nvidia/label/cuda-11.7.0 -c nvidiafor CUDA
-
- Clone the repo:
git clone https://github.com/rsxdalv/tts-generation-webui.git - Potentially (if errors occur in the next step) need to install build tools (without Visual Studio): https://visualstudio.microsoft.com/visual-cpp-build-tools/
- Install the requirements:
- activate the environment:
conda activate venvand - install all the requirements*.txt (this list might not be up to date, check https://github.com/rsxdalv/tts-generation-webui/blob/main/Dockerfile#L39-L40):
(venv) pip install -r requirements.txt(venv) pip install -r requirements_audiocraft.txt(venv) pip install -r requirements_bark_hubert_quantizer.txt(venv) pip install -r requirements_rvc.txt(venv) pip install hydra-core==1.3.2(venv) pip install -r requirements_styletts2.txt(venv) pip install -r requirements_vall_e.txt(venv) pip install -r requirements_maha_tts.txt(venv) pip install -r requirements_stable_audio.txt(venv) pip install soundfile==0.12.1
- due to pip-torch incompatibilities torch will be reinstalled to 2.0.0, thus it might be necessary to reinstall it again after the requirements if you have a CPU/Mac or installed a specific torch version other than 2.0.0:
-
(venv) conda install pytorch torchvision torchaudio cpuonly ffmpeg -c pytorchfor CPU/Mac -
(venv) conda install -y -k pytorch[version=2,build=py3.10_cuda11.7*] torchvision torchaudio pytorch-cuda=11.7 cuda-toolkit ninja ffmpeg -c pytorch -c nvidia/label/cuda-11.7.0 -c nvidiafor CUDA
-
- build the react app:
(venv) cd react-ui && npm install && npm run build
- activate the environment:
- run the server:
(venv) python server.py
- Set up pytorch with CUDA or CPU (https://pytorch.org/audio/stable/build.windows.html#install-pytorch):
- Install nodejs (if not already installed with conda)
- Install react dependencies:
npm install - Build react:
npm run build - Run react:
npm start - Also run the python server:
python server.pyor withstart_(platform)script
tts-generation-webui can also be ran inside of a Docker container. To get started, pull the image from GitHub Container Registry:
docker pull ghcr.io/rsxdalv/tts-generation-webui:main
Once the image has been pulled it can be started with Docker Compose:
docker compose up -d
The container will take some time to generate the first output while models are downloaded in the background. The status of this download can be verified by checking the container logs:
docker logs tts-generation-webui
If you wish to build your own docker container, you can use the included Dockerfile:
docker build -t tts-generation-webui .
Please note that the docker-compose needs to be edited to use the image you just built.
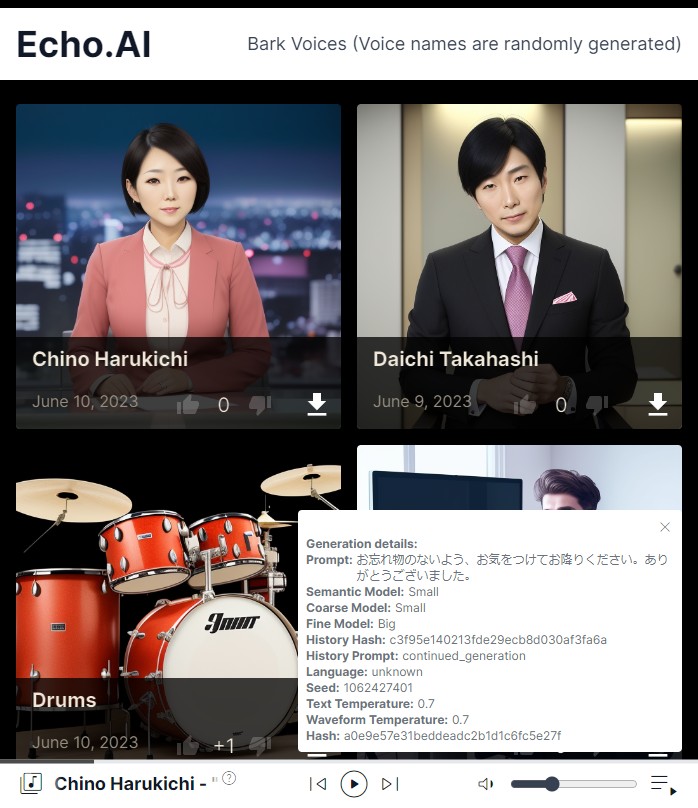
https://rsxdalv.github.io/bark-speaker-directory/
https://github.com/rsxdalv/tts-generation-webui/discussions/186#discussioncomment-7291274
 |
 |
 |
|---|
audio__bark__continued_generation__2024-05-04_16-07-49_long.webm
audio__bark__continued_generation__2024-05-04_16-09-21_long.webm
audio__bark__continued_generation__2024-05-04_16-10-55_long.webm
This project utilizes the following open source libraries:
-
suno-ai/bark - MIT License
- Description: Inference code for Bark model.
- Repository: suno/bark
-
tortoise-tts - Apache-2.0 License
- Description: A flexible text-to-speech synthesis library for various platforms.
- Repository: neonbjb/tortoise-tts
-
ffmpeg - LGPL License
- Description: A complete and cross-platform solution for video and audio processing.
- Repository: FFmpeg
- Use: Encoding Vorbis Ogg files
-
ffmpeg-python - Apache 2.0 License
- Description: Python bindings for FFmpeg library for handling multimedia files.
- Repository: kkroening/ffmpeg-python
-
audiocraft - MIT License
- Description: A library for audio generation and MusicGen.
- Repository: facebookresearch/audiocraft
-
vocos - MIT License
- Description: An improved decoder for encodec samples
- Repository: charactr-platform/vocos
-
RVC - MIT License
- Description: An easy-to-use Voice Conversion framework based on VITS.
- Repository: RVC-Project/Retrieval-based-Voice-Conversion-WebUI
This technology is intended for enablement and creativity, not for harm.
By engaging with this AI model, you acknowledge and agree to abide by these guidelines, employing the AI model in a responsible, ethical, and legal manner.
- Non-Malicious Intent: Do not use this AI model for malicious, harmful, or unlawful activities. It should only be used for lawful and ethical purposes that promote positive engagement, knowledge sharing, and constructive conversations.
- No Impersonation: Do not use this AI model to impersonate or misrepresent yourself as someone else, including individuals, organizations, or entities. It should not be used to deceive, defraud, or manipulate others.
- No Fraudulent Activities: This AI model must not be used for fraudulent purposes, such as financial scams, phishing attempts, or any form of deceitful practices aimed at acquiring sensitive information, monetary gain, or unauthorized access to systems.
- Legal Compliance: Ensure that your use of this AI model complies with applicable laws, regulations, and policies regarding AI usage, data protection, privacy, intellectual property, and any other relevant legal obligations in your jurisdiction.
- Acknowledgement: By engaging with this AI model, you acknowledge and agree to abide by these guidelines, using the AI model in a responsible, ethical, and legal manner.
The codebase is licensed under MIT. However, it's important to note that when installing the dependencies, you will also be subject to their respective licenses. Although most of these licenses are permissive, there may be some that are not. Therefore, it's essential to understand that the permissive license only applies to the codebase itself, not the entire project.
That being said, the goal is to maintain MIT compatibility throughout the project. If you come across a dependency that is not compatible with the MIT license, please feel free to open an issue and bring it to our attention.
Known non-permissive dependencies:
| Library | License | Notes |
|---|---|---|
| encodec | CC BY-NC 4.0 | Newer versions are MIT, but need to be installed manually |
| diffq | CC BY-NC 4.0 | Optional in the future, not necessary to run, can be uninstalled, should be updated with demucs |
| lameenc | GPL License | Future versions will make it LGPL, but need to be installed manually |
| unidecode | GPL License | Not mission critical, can be replaced with another library, issue: https://github.com/neonbjb/tortoise-tts/issues/494 |
Model weights have different licenses, please pay attention to the license of the model you are using.
Most notably:
- Bark: MIT
- Tortoise: Unknown (Apache-2.0 according to repo, but no license file in HuggingFace)
- MusicGen: CC BY-NC 4.0
- AudioGen: CC BY-NC 4.0
Audiocraft is currently only compatible with Linux and Windows. MacOS support still has not arrived, although it might be possible to install manually.
Due to the python package manager (pip) limitations, torch can get reinstalled several times. This is a wide ranging issue of pip and torch.
These messages:
---- requires ----, but you have ---- which is incompatible.
Are completely normal. It's both a limitation of pip and because this Web UI combines a lot of different AI projects together. Since the projects are not always compatible with each other, they will complain about the other projects being installed. This is normal and expected. And in the end, despite the warnings/errors the projects will work together. It's not clear if this situation will ever be resolvable, but that is the hope.
You can configure the interface through the "Settings" tab or, for advanced users, via the config.json file in the root directory (not recommended). Below is a detailed explanation of each setting:
| Argument | Default Value | Description |
|---|---|---|
text_use_gpu |
true |
Determines whether the GPU should be used for text processing. |
text_use_small |
true |
Determines whether a "small" or reduced version of the text model should be used. |
coarse_use_gpu |
true |
Determines whether the GPU should be used for "coarse" processing. |
coarse_use_small |
true |
Determines whether a "small" or reduced version of the "coarse" model should be used. |
fine_use_gpu |
true |
Determines whether the GPU should be used for "fine" processing. |
fine_use_small |
true |
Determines whether a "small" or reduced version of the "fine" model should be used. |
codec_use_gpu |
true |
Determines whether the GPU should be used for codec processing. |
load_models_on_startup |
false |
Determines whether the models should be loaded during application startup. |
| Argument | Default Value | Description |
|---|---|---|
inline |
false |
Display inline in an iframe. |
inbrowser |
true |
Automatically launch in a new tab. |
share |
false |
Create a publicly shareable link. |
debug |
false |
Block the main thread from running. |
enable_queue |
true |
Serve inference requests through a queue. |
max_threads |
40 |
Maximum number of total threads. |
auth |
null |
Username and password required to access interface, format: username:password. |
auth_message |
null |
HTML message provided on login page. |
prevent_thread_lock |
false |
Block the main thread while the server is running. |
show_error |
false |
Display errors in an alert modal. |
server_name |
0.0.0.0 |
Make app accessible on local network. |
server_port |
null |
Start Gradio app on this port. |
show_tips |
false |
Show tips about new Gradio features. |
height |
500 |
Height in pixels of the iframe element. |
width |
100% |
Width in pixels of the iframe element. |
favicon_path |
null |
Path to a file (.png, .gif, or .ico) to use as the favicon. |
ssl_keyfile |
null |
Path to a file to use as the private key file for a local server running on HTTPS. |
ssl_certfile |
null |
Path to a file to use as the signed certificate for HTTPS. |
ssl_keyfile_password |
null |
Password to use with the SSL certificate for HTTPS. |
ssl_verify |
true |
Skip certificate validation. |
quiet |
true |
Suppress most print statements. |
show_api |
true |
Show the API docs in the footer of the app. |
file_directories |
null |
List of directories that Gradio is allowed to serve files from. |
_frontend |
true |
Frontend. |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tts-generation-webui
Similar Open Source Tools
tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image, video, audio, and 3D processing, along with features like smart memory management, model loading, embeddings/textual inversion, and offline usage. Users can experiment with different models, create complex workflows, and optimize their processes efficiently.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.
AirConnect-Synology
AirConnect-Synology is a minimal Synology package that allows users to use AirPlay to stream to UPnP/Sonos & Chromecast devices that do not natively support AirPlay. It is compatible with DSM 7.0 and DSM 7.1, and provides detailed information on installation, configuration, supported devices, troubleshooting, and more. The package automates the installation and usage of AirConnect on Synology devices, ensuring compatibility with various architectures and firmware versions. Users can customize the configuration using the airconnect.conf file and adjust settings for specific speakers like Sonos, Bose SoundTouch, and Pioneer/Phorus/Play-Fi.
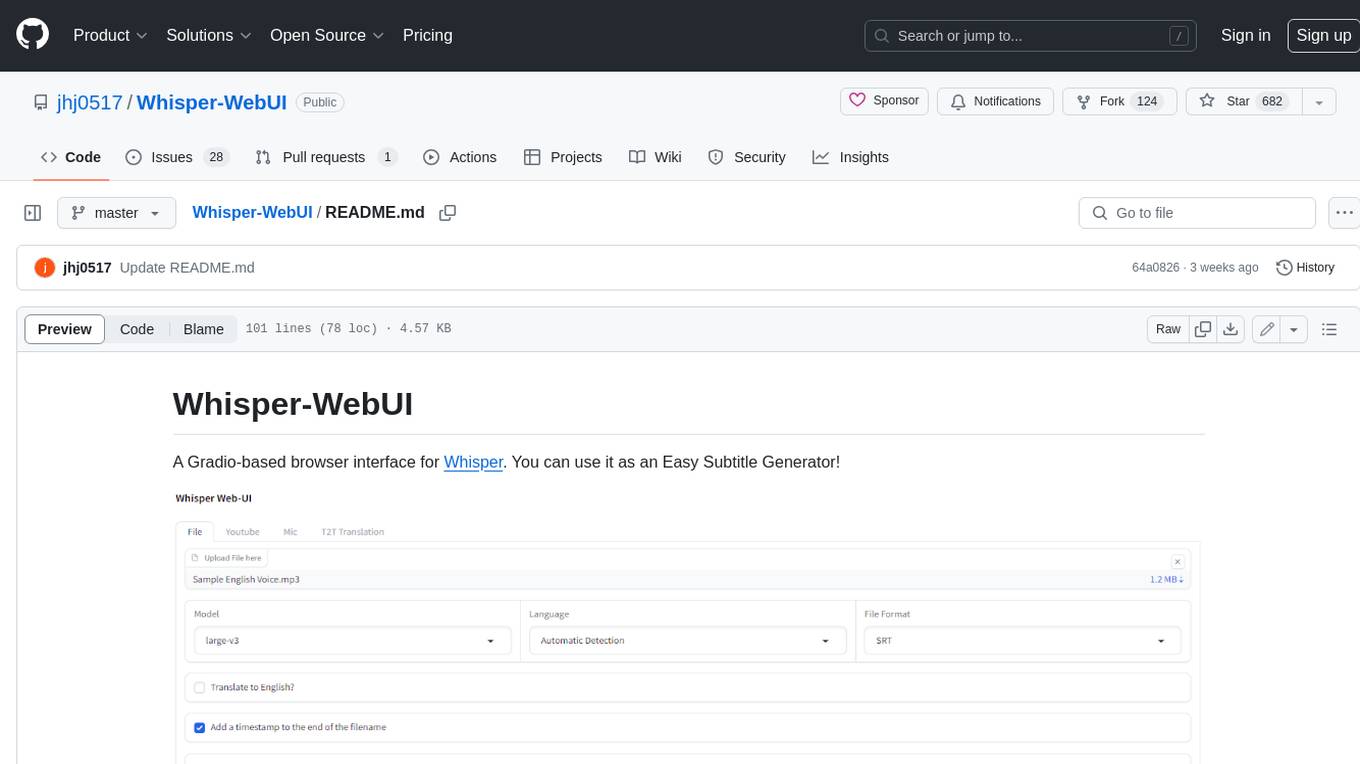
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
sd-webui-agent-scheduler
AgentScheduler is an Automatic/Vladmandic Stable Diffusion Web UI extension designed to enhance image generation workflows. It allows users to enqueue prompts, settings, and controlnets, manage queued tasks, prioritize, pause, resume, and delete tasks, view generation results, and more. The extension offers hidden features like queuing checkpoints, editing queued tasks, and custom checkpoint selection. Users can access the functionality through HTTP APIs and API callbacks. Troubleshooting steps are provided for common errors. The extension is compatible with latest versions of A1111 and Vladmandic. It is licensed under Apache License 2.0.
mobile-use
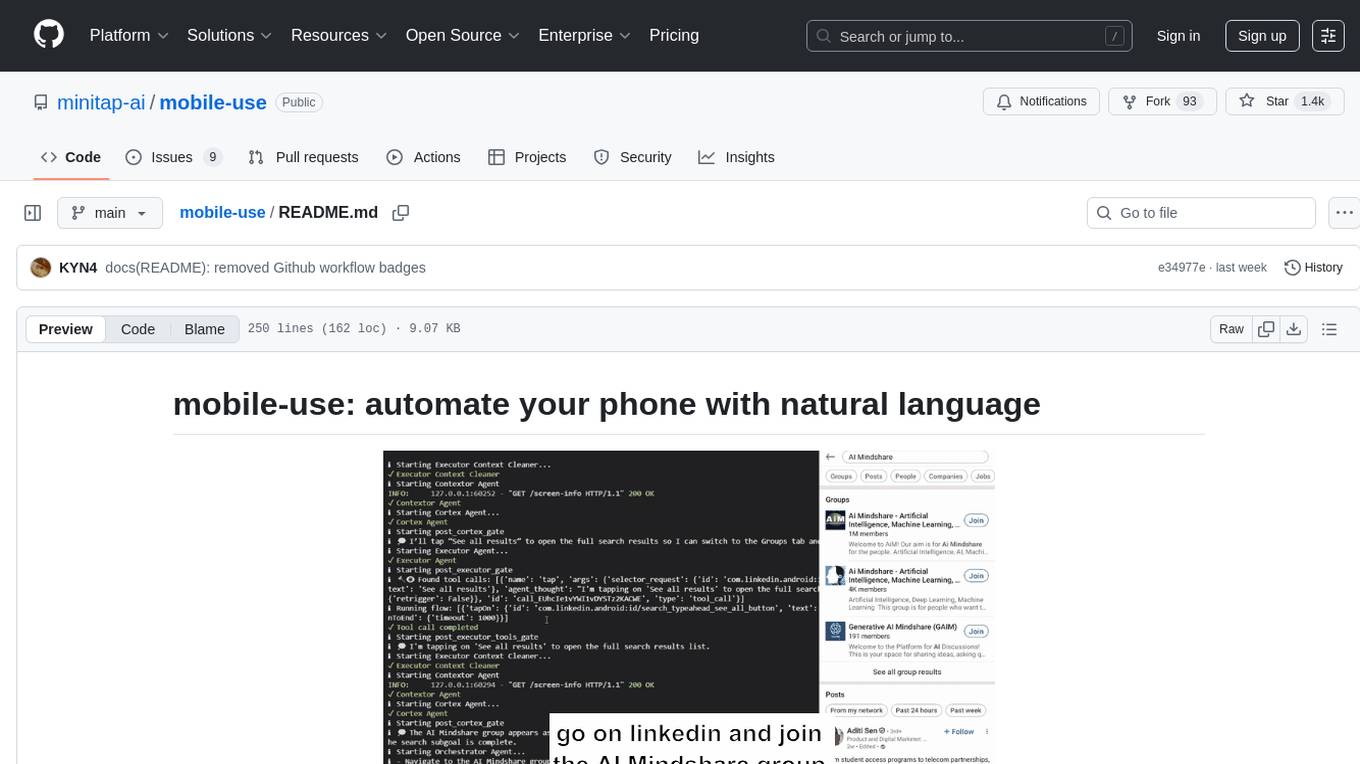
Mobile-use is an open-source AI agent that controls Android or IOS devices using natural language. It understands commands to perform tasks like sending messages and navigating apps. Features include natural language control, UI-aware automation, data scraping, and extensibility. Users can automate their mobile experience by setting up environment variables, customizing LLM configurations, and launching the tool via Docker or manually for development. The tool supports physical Android phones, Android simulators, and iOS simulators. Contributions are welcome, and the project is licensed under MIT.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

QodeAssist
QodeAssist is an AI-powered coding assistant plugin for Qt Creator, offering intelligent code completion and suggestions for C++ and QML. It leverages large language models like Ollama to enhance coding productivity with context-aware AI assistance directly in the Qt development environment. The plugin supports multiple LLM providers, extensive model-specific templates, and easy configuration for enhanced coding experience.
Deep-Live-Cam
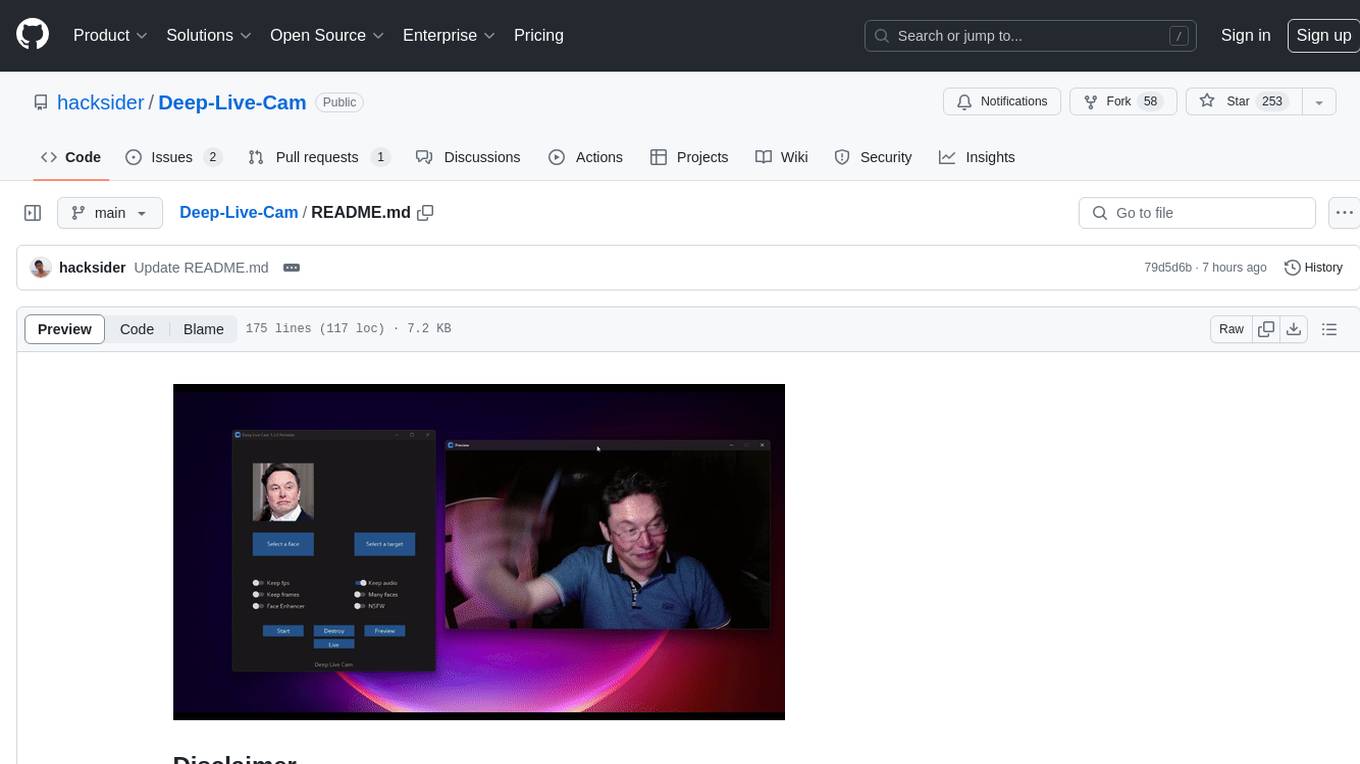
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.
GPTModels.nvim
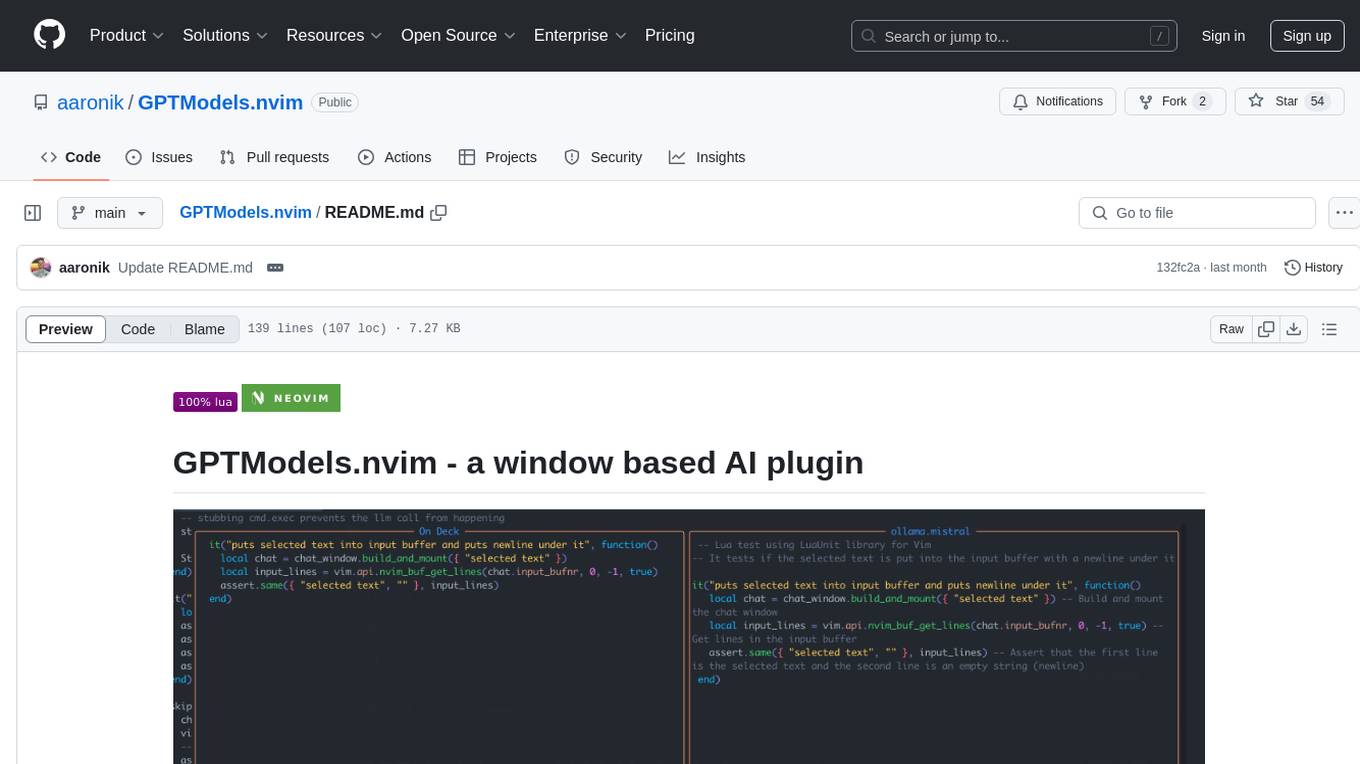
GPTModels.nvim is a window-based AI plugin for Neovim that enhances workflow with AI LLMs. It provides two popup windows for chat and code editing, focusing on stability and user experience. The plugin supports OpenAI and Ollama, includes LSP diagnostics, file inclusion, background processing, request cancellation, selection inclusion, and filetype inclusion. Developed with stability in mind, the plugin offers a seamless user experience with various features to streamline AI integration in Neovim.
For similar tasks

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.
tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
qwen-tts
Qwen-TTS is a versatile text-to-speech service offering multi-voice support for both Chinese and English, including dialects like Beijing, Shanghai, and Sichuan. It provides real-time synthesis, batch processing, smart segmentation, progress tracking, audio playback, and outputs in WAV format. The application features a modern design, intuitive operation, history tracking, and real-time feedback. It also offers technical features like asynchronous processing, error handling, file management, and API documentation.
Generative-AI-for-beginners-dotnet
Generative AI for Beginners .NET is a hands-on course designed for .NET developers to learn how to build Generative AI applications. The repository focuses on real-world applications and live coding, providing fully functional code samples and integration with tools like GitHub Codespaces and GitHub Models. Lessons cover topics such as generative models, text generation, multimodal capabilities, and responsible use of Generative AI in .NET apps. The course aims to simplify the journey of implementing Generative AI into .NET projects, offering practical guidance and references for deeper theoretical understanding.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
orcish-ai-nextjs-framework
The Orcish AI Next.js Framework is a powerful tool that leverages OpenAI API to seamlessly integrate AI functionalities into Next.js applications. It allows users to generate text, images, and text-to-speech based on specified input. The framework provides an easy-to-use interface for utilizing AI capabilities in application development.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
GLaDOS
GLaDOS Personality Core is a project dedicated to building a real-life version of GLaDOS, an aware, interactive, and embodied AI system. The project aims to train GLaDOS voice generator, create a 'Personality Core,' develop medium- and long-term memory, provide vision capabilities, design 3D-printable parts, and build an animatronics system. The software architecture focuses on low-latency voice interactions and minimal dependencies. The hardware system includes servo- and stepper-motors, 3D printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions involve setting up a local LLM server, installing drivers, and running GLaDOS on different operating systems.
For similar jobs
tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
start-machine-learning
Start Machine Learning in 2024 is a comprehensive guide for beginners to advance in machine learning and artificial intelligence without any prior background. The guide covers various resources such as free online courses, articles, books, and practical tips to become an expert in the field. It emphasizes self-paced learning and provides recommendations for learning paths, including videos, podcasts, and online communities. The guide also includes information on building language models and applications, practicing through Kaggle competitions, and staying updated with the latest news and developments in AI. The goal is to empower individuals with the knowledge and resources to excel in machine learning and AI.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
trustworthyAI
Trustworthy AI is a repository from Huawei Noah's Ark Lab containing works related to trustworthy AI. It includes a causal structure learning toolchain, information on causality-related competitions, real-world datasets, and research works on causality such as CausalVAE, GAE, and causal discovery with reinforcement learning.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.