
qlora-pipe
A pipeline parallel training script for LLMs.
Stars: 120
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.
README:
A pipeline parallel training script for LLMs.
Refer to the changelog at the bottom for details on updates.
This is a training script I made so that I can fine-tune LLMs using my workstation with four 4090s. It is developed first and foremost for myself, with my own use cases in mind. It is scrappy and hacked together. It will likely never be a stable, well-supported training script like Axolotl. I am open sourcing the code in case it is useful to others, and also as a proof-of-concept that this kind of thing is possible.
That being said, if something doesn't work right, or you would like it to support some feature, feel free to raise an issue and I'll try to look at it.
- Pipeline parallel training, for efficiently training large models that cannot fit on one GPU
- Supports QLoRA, LoRA, and full fine tuning
- Quantize weights using either bitsandbytes or HQQ
- Efficient model loading. Each process only loads the layers it needs, and quantizes and moves them to the GPU layer-by-layer. This means you can load a large model on a lot of GPUs even with limited system RAM.
- Load any dataset that Axolotl can, using the same YAML config file format
- Support for "raw text" training using either a structured list of documents in a JSON file, or a single txt file
- Support for resuming training from a checkpoint, including the dataloader state, to easily allow training in a piecemeal fashion
- Useful metrics logged to Tensorboard
- Ability to specify a separate, fixed evaluation dataset
- Train on multiple datasets simultaneously, with different sampling ratios per dataset
- Models currently supported: Llama, Mistral, Mixtral, Qwen, Cohere (Command R), Phi-3 (mini and medium), Gemma-2
Clone the repository:
git clone --recurse-submodules https://github.com/tdrussell/qlora-pipe
If you alread cloned it and forgot to do --recurse-submodules:
git submodule init
git submodule update
Install Miniconda: https://docs.conda.io/en/latest/miniconda.html
Create the environment
conda create -n qlora-pipe python=3.12
conda activate qlora-pipe
Install the dependencies:
pip install -r requirements.txt
Install nvcc:
conda install nvidia::cuda-nvcc
Start by reading through the config files in the examples directory. There are lots of comments explaining what the various fields do. Then, make a copy and edit it however you like. At minimum, change the paths at the top to point to your model and desired output directory. Launch the training script:
NCCL_P2P_DISABLE="1" NCCL_IB_DISABLE="1" deepspeed --num_gpus=1 train.py --deepspeed --config examples/config.toml
RTX 4000 series needs those 2 enviroment variables set. Other GPUs may not need them.
Deepspeed handles pipeline- and data-parallelism. Set the --num_gpus flag to however many GPUs to want to use. The config option pipeline_stages determines the level of model parallelism. Then, the data parallelism is automatically set so that all GPUs are used.
For example with 8 GPUs, and pipeline_stages=4, a single instance of the model is divided across 4 GPUs. Because there are 8 GPUs total, there are then 2 data-parallel instances.
The option gradient_accumulation_steps in the Deepspeed JSON config file determines the amount of pipelining when using pipeline parallelism (pipeline_stages>1). The higher the value, the more the GPUs can overlap computation. For example, with gradient_accumulation_steps=1, there is a single batch that gets passed between the GPUs forward, then in reverse for the backward pass. Only 1 GPU is active at a time, the others are idle. As gradient_accumulation_steps increases, you start pipelining multiple forward/backward batches. At the beginning and end of the step, some GPUs will always be idle. So as gradient_accumulation_steps approaches infinity, you approach 100% theoretical utilization. In practice, a value of 8 or so already gives good average utilization with 2 GPUs. With more GPUs, you may want to go higher.
There are 3 options for specifying each dataset. Set the dataset_type field to one of:
- axolotl
- Loads the dataset using the Axolotl codebase. Set
dataset_pathto a YAML file that contains the same dataset configuration you would use in Axolotl.
- Loads the dataset using the Axolotl codebase. Set
- doclist
- Set
dataset_pathto glob pattern matching one or more JSON or JSONL files. Each file should be a list of objects containing a 'text' key. For each file, all of the text is logically concatenated together, before being sliced into sequences.
- Set
- textfile
- Basically the same as doclist, except the
dataset_pathmatches one or more txt files. Each text file is sliced into sequences.
- Basically the same as doclist, except the
You can read dataset_utils.py for details on what each of these options is doing.
You can have multiple datasets. Just add additional [[datasets]] entries. When using multiple datasets, there are different ways to combine them.
-
dataset_combination_mode= 'concatenate' (the default)- Just concatenates the datasets.
-
dataset_combination_mode= 'interleave'- Uses the Huggingface Datasets library
interleave_datasets()function. - Use the
dataset_interleave_stopping_strategysetting to control when interleaving stops.- 'first_exhausted': stop when a dataset runs out of examples.
- 'all_exhausted': stop when all datasets have run out of examples. This duplicates examples from smaller datasets.
- When using the 'interleave' mode, datasets can have a relative
sample_weight, which is a positive real number. This controls the relative proportion of the datasets when they are combined. -
IMPORTANT: When using the 'interleave' mode, the manner in which the datasets are proportionally combined (i.e. sampled from) is affected by the
batch_size_tokenssetting:- If
batch_size_tokensis unset, it means you are treating each example equally. Every batch has the same number of examples, even though they may be different lengths. So, when interleaving datasets, the rows are sampled according to the relative proportions given by thesample_weight. - If using
batch_size_tokens, it means you are treating each token equally. Every batch varies the number of examples (because they might have different lengths) so that the token count is approximately constant. So, when interleaving datasets, the sampling ratios are adjusted so that the number of tokens, not rows, drawn from different datasets matches thesample_weight. This is implemented by scaling the sampling probabilities by the average length of the dataset. You can read thecombine_datasets()function in dataset_utils.py if this is confusing. -
Which of these should I use? Probably set
batch_size_tokens. I think this is the better way to think about things, and it matches what sample packing would do. For example, in Axolotl, it is recommended to use sample packing, which packs multiple examples into a single sequence so that the sequence length is constant. This means, in the loss function, each token is being treated with equal weight, not each original row in the dataset. Usingbatch_size_tokensin this training script mimics that behavior, and thus when interleaving datasets, it samples from them so that the token ratios adhere to the sample_weight specified. -
Example: you have datasets A and B. B's average row length is twice that of A. A has a sample_weight of 2, B has a sample_weight of 1.
- Not setting batch_size_tokens: when interleaving, you get 2 rows of A for every row of B.
- Using batch_size_tokens: when interleaving, you get 4 rows of A for every row of B. This is because A's rows are on average half the length of B's rows, so you need twice as many as before so that the number of tokens in each matches the 2:1 ratio you specified with the sample_weight.
- If
- Uses the Huggingface Datasets library
Sample packing is not currently implemented. Instead, there is the option batch_size_tokens. If this field is set, the per-device batch size is ignored, and instead the batch size is adjusted dynamically to target a fixed number of tokens per batch, per device. This was easier to implement than sample packing, and does basically the same thing. It is also efficient: if I set batch_size_tokens to a modest 10000 and train a 7B model with the Alpaca dataset, all my 4090s hit their 350W power limit cap. Unless I'm missing something (definitely possible), it seems there is no need to support sample packing.
There are different places you can specify the floating point dtype. model_weight_dtype controls the precision of the underlying model weights (for any weights not quantized), and lora_weight_dtype is for the lora weights. If you are using quantization, both bnb and hqq have options for the compute dtype as well.
If you are using 16 bit dtypes, floating point roundoff error is a potential problem. For a good overview of the problem and solutions, see Revisiting Bfloat16 Training. TLDR: the main source of precision error when training with 16 bit weights is the weight update step: $(p = p + \Delta p * lr)$. When the update is very small compared to the parameter (which is often the case), there can be significant roundoff error, including the update being entirely dropped. Mixed precision training solves this by keeping a master copy of the weights in fp32, and running all optimizer steps in fp32. Kahan summation is another solution when training in full bf16, that keeps an extra bf16 buffer for each parameter to accumulate roundoff errors so that updates are never dropped.
- If unsure, set everything to bf16 and use the adamw_kahan optimizer type. Kahan summation is ESPECIALLY important for full fine tuning. Kahan summation requires an extra 2 bytes per trainable parameter compared to vanilla full bf16 training.
- For LoRAs, another option is setting
lora_weight_dtypeto fp32, which also makes all optimizer states fp32. - For LoRAs only, with constant learning rate no lower than 5e-5 or so, I have seen full bf16 training with no Kahan summation mostly match fp32 or bf16 + Kahan.
- (more experimental) You may try Deepspeed's bf16 mode, but I personally don't use this. I think this does something like mixed precision, where it wraps the optimizer to keep a master copy of the parameters in fp32, as well as doing gradient accumulation and all optimizer states in fp32. This will use much more memory than full bf16 + Kahan summation.
- Add DPO training. The examples directory has a DPO example.
- Add Gemma-2 support.
- Add adamw_kahan optimzer type and make it the default in the example.
The old config file format will break. Quantization is configured slightly differently now. Read examples/config_7b.toml. It's only a few lines to change.
- Change how quantization is configured. Quantization is now its own table in the TOML file.
- Add HQQ quantization.
- Add llama3 instruction formatting option when loading a ShareGPT formatted dataset using Axolotl.
- Automatically add BOS token for Llama 3.
- Add option for Unsloth activation checkpointing, which saves VRAM for a very small hit to performance.
- Optimizer is now specified in the config.toml file.
- Can use AdamW8Bit optimizer.
- MLP offloading works again. For MoE, can offload a specified number of experts.
- Can have separate dtype for saved files.
- Cohere model support (command-r)
Make sure to update requirements! Axolotl does some dynamic importing, so things will break in a very hard to diagnose way if you don't have a new dependency that was added.
- Removed the need for manually specifying cache directories for datasets. All dataset processing uses the Huggingface Datasets library and takes advantage of the automatic caching that it provides.
- Added the ability to specify multiple datasets, with different ways to combine them. This breaks the old config format for datasets. Refer to the example config for what it should look like now.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for qlora-pipe
Similar Open Source Tools
qlora-pipe
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
textcoder
Textcoder is a proof-of-concept tool for steganographically encoding secret messages into ordinary text using arithmetic coding based on a statistical model derived from an LLM. It encrypts the secret message to produce a pseudorandom bit stream, which is then decompressed to generate text that appears randomly sampled from the LLM while encoding the secret message in specific token choices.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.
wtffmpeg
wtffmpeg is a command-line tool that uses a Large Language Model (LLM) to translate plain-English descriptions of video or audio tasks into actual, executable ffmpeg commands. It aims to streamline the process of generating ffmpeg commands by allowing users to describe what they want to do in natural language, review the generated command, optionally edit it, and then decide whether to run it. The tool provides an interactive REPL interface where users can input their commands, retain conversational context, and history, and control the level of interactivity. wtffmpeg is designed to assist users in efficiently working with ffmpeg commands, reducing the need to search for solutions, read lengthy explanations, and manually adjust commands.
llmap
LLMap is a CLI code search tool designed to automatically find context in large codebases by evaluating the relevance of each source file using DeepSeek-V3 and DeepSeek-R1. It optimizes analysis by performing multi-stage analysis and caching results for faster searches. Currently supports Java and Python files, with potential for extension to other languages. Install with 'pip install llmap-ai' and use with a DeepSeek API key to search for specific context in code.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
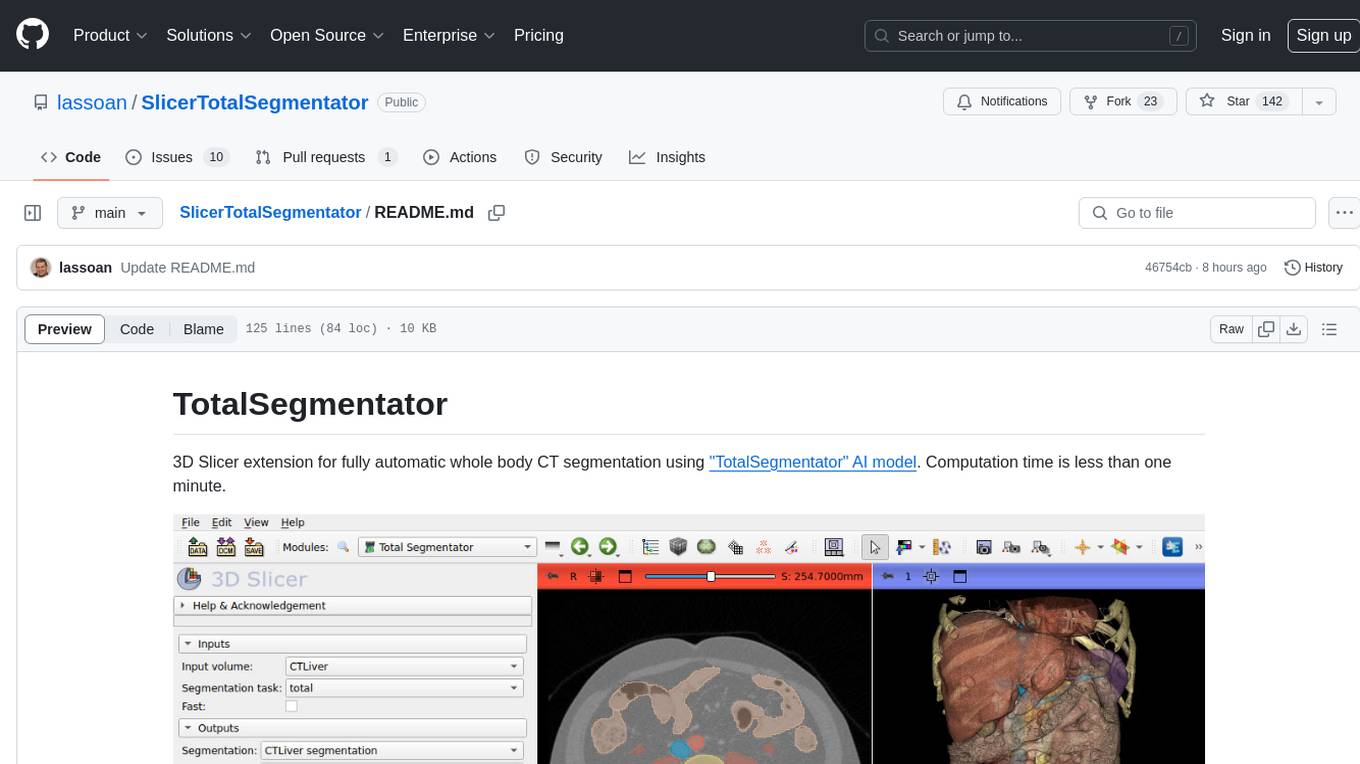
SlicerTotalSegmentator
TotalSegmentator is a 3D Slicer extension designed for fully automatic whole body CT segmentation using the 'TotalSegmentator' AI model. The computation time is less than one minute, making it efficient for research purposes. Users can set up GPU acceleration for faster segmentation. The tool provides a user-friendly interface for loading CT images, creating segmentations, and displaying results in 3D. Troubleshooting steps are available for common issues such as failed computation, GPU errors, and inaccurate segmentations. Contributions to the extension are welcome, following 3D Slicer contribution guidelines.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.
For similar tasks
qlora-pipe
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.
Wandb.jl
Unofficial Julia Bindings for wandb.ai. Wandb is a platform for tracking and visualizing machine learning experiments. It provides a simple and consistent way to log metrics, parameters, and other data from your experiments, and to visualize them in a variety of ways. Wandb.jl provides a convenient way to use Wandb from Julia.

wandb
Weights & Biases (W&B) is a platform that helps users build better machine learning models faster by tracking and visualizing all components of the machine learning pipeline, from datasets to production models. It offers tools for tracking, debugging, evaluating, and monitoring machine learning applications. W&B provides integrations with popular frameworks like PyTorch, TensorFlow/Keras, Hugging Face Transformers, PyTorch Lightning, XGBoost, and Sci-Kit Learn. Users can easily log metrics, visualize performance, and compare experiments using W&B. The platform also supports hosting options in the cloud or on private infrastructure, making it versatile for various deployment needs.
fsdp_qlora
The fsdp_qlora repository provides a script for training Large Language Models (LLMs) with Quantized LoRA and Fully Sharded Data Parallelism (FSDP). It integrates FSDP+QLoRA into the Axolotl platform and offers installation instructions for dependencies like llama-recipes, fastcore, and PyTorch. Users can finetune Llama-2 70B on Dual 24GB GPUs using the provided command. The script supports various training options including full params fine-tuning, LoRA fine-tuning, custom LoRA fine-tuning, quantized LoRA fine-tuning, and more. It also discusses low memory loading, mixed precision training, and comparisons to existing trainers. The repository addresses limitations and provides examples for training with different configurations, including BnB QLoRA and HQQ QLoRA. Additionally, it offers SLURM training support and instructions for adding support for a new model.
Anima
Anima is the first open-source 33B Chinese large language model based on QLoRA, supporting DPO alignment training and open-sourcing a 100k context window model. The latest update includes AirLLM, a library that enables inference of 70B LLM from a single GPU with just 4GB memory. The tool optimizes memory usage for inference, allowing large language models to run on a single 4GB GPU without the need for quantization or other compression techniques. Anima aims to democratize AI by making advanced models accessible to everyone and contributing to the historical process of AI democratization.
LLM-Dojo
LLM-Dojo is an open-source platform for learning and practicing large models, providing a framework for building custom large model training processes, implementing various tricks and principles in the llm_tricks module, and mainstream model chat templates. The project includes an open-source large model training framework, detailed explanations and usage of the latest LLM tricks, and a collection of mainstream model chat templates. The term 'Dojo' symbolizes a place dedicated to learning and practice, borrowing its meaning from martial arts training.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.
LLMLanding
LLMLanding is a repository focused on practical implementation of large models, covering topics from theory to practice. It provides a structured learning path for training large models, including specific tasks like training 1B-scale models, exploring SFT, and working on specialized tasks such as code generation, NLP tasks, and domain-specific fine-tuning. The repository emphasizes a dual learning approach: quickly applying existing tools for immediate output benefits and delving into foundational concepts for long-term understanding. It offers detailed resources and pathways for in-depth learning based on individual preferences and goals, combining theory with practical application to avoid overwhelm and ensure sustained learning progress.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.