
textcoder
Steganographic message encoder using LLMs
Stars: 51
Textcoder is a proof-of-concept tool for steganographically encoding secret messages into ordinary text using arithmetic coding based on a statistical model derived from an LLM. It encrypts the secret message to produce a pseudorandom bit stream, which is then decompressed to generate text that appears randomly sampled from the LLM while encoding the secret message in specific token choices.
README:
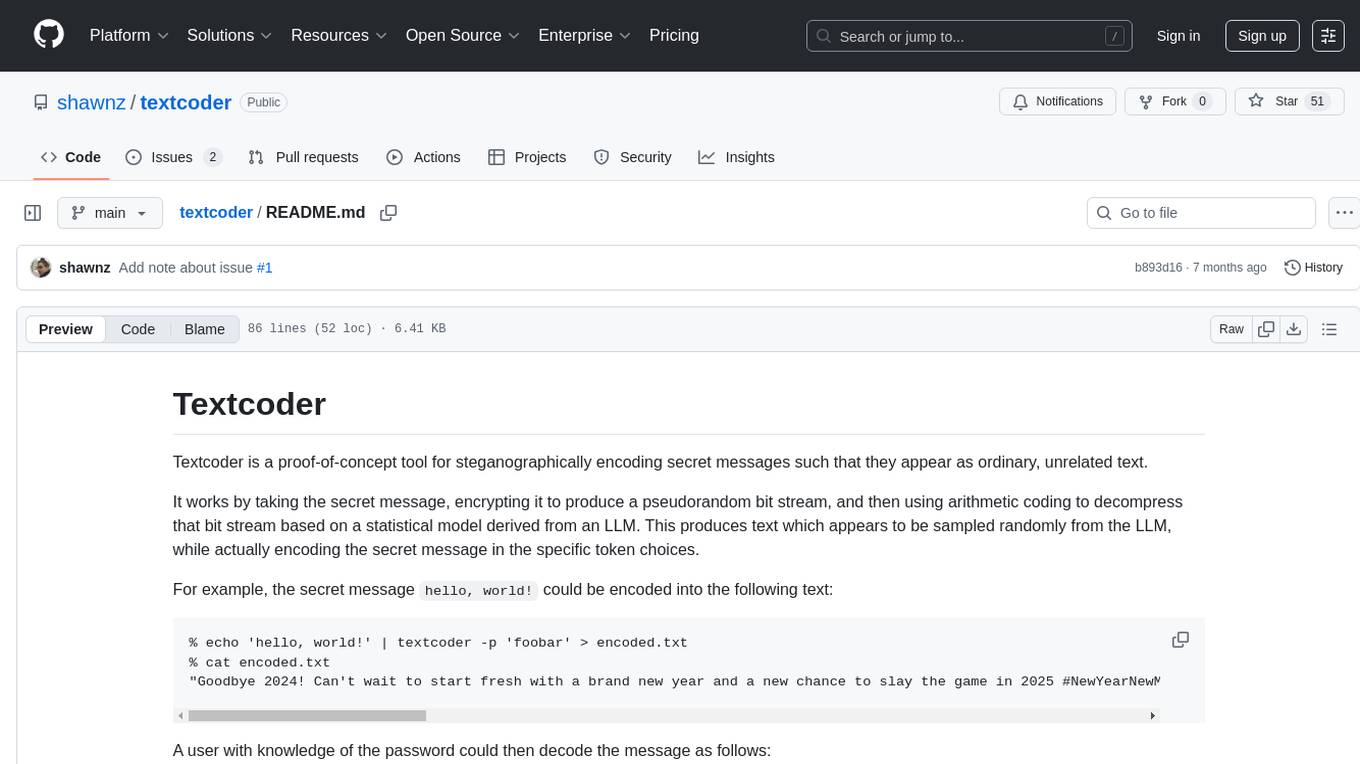
Textcoder is a proof-of-concept tool for steganographically encoding secret messages such that they appear as ordinary, unrelated text.
It works by taking the secret message, encrypting it to produce a pseudorandom bit stream, and then using arithmetic coding to decompress that bit stream based on a statistical model derived from an LLM. This produces text which appears to be sampled randomly from the LLM, while actually encoding the secret message in the specific token choices.
For example, the secret message hello, world! could be encoded into the following text:
% echo 'hello, world!' | textcoder -p 'foobar' > encoded.txt
% cat encoded.txt
"Goodbye 2024! Can't wait to start fresh with a brand new year and a new chance to slay the game in 2025 #NewYearNewMe #ConfidenceIsKey" - @SlayMyGameLife7770 (280 character limit) I just ordered my fave coffee from Dunkin' yesterday but I almost spilled it on my shirt, oh no! #DunkinCoffeePlease #FashionBlunders Life is just trying to keep up with its favorite gamers rn. Wish I could say I'm coding instead of gaming, but when i have to put down my controller for a sec
A user with knowledge of the password could then decode the message as follows:
% cat encoded.txt | textcoder -d -p 'foobar'
hello, world!
Textcoder is packaged using Poetry. To run the project, Poetry must be installed. After installing Poetry, clone the repository and execute the poetry install command:
git clone https://github.com/shawnz/textcoder.git
cd textcoder
poetry installAdditionally, Textcoder makes use of the Llama 3.2 1B Instruct language model. The use of this model requires approval of the Llama 3.2 community license agreement. After approving the license, install the Hugging Face Hub command line interface and log in to your Hugging Face account:
huggingface-cli loginWARNING: The Llama 3.2 family of language models does not allow use of the model with the intent of representing the output as being human-generated. This might limit the situations in which you are allowed to use Textcoder. See this issue for details.
Finally, you can now run Textcoder using the textcoder command. To encode a message, run:
echo '<message>' | poetry run textcoder -p '<password>' > encoded.txtTo decode a message, run:
cat encoded.txt | poetry run textcoder -d -p '<password>'The Llama tokenizer used in this project sometimes permits multiple possible tokenizations for a given string. As a result, it is sometimes the case that the arithmetic coder produces a series of tokens which don't match the canonical tokenization for that string exactly. In these cases, decoding will fail and you may need to try to run the encoding process again.
To mitigate this, the encoder will try decoding the output before returning it. This validation step requires extra time and memory usage. To skip validation, use the -n (--no-validate) parameter.
The Llama model used in this project is not guaranteed to provide completely deterministic behaviour. Due to issues such as floating-point inaccuracy and differing algorithms on different hardware and software versions, it is possible that outputs can change between platforms, or even between successive runs on the same platform. When this happens, the output will not be able to be decoded.
Some steps are taken in this project to use deterministic algorithms when possible, but this doesn't guarantee that different platforms will produce the same outputs. For best results, make sure you are decoding messages on the same platform that they were encoded on.
To help mitigate the impact of hardware differences, consider disabling hardware acceleration using the -a (--no-acceleration) parameter. However, this will greatly decrease performance.
This project wouldn't have been possible without the work of Matt Timmermans and his Bijective Arithmetic Coding algorithm. The bijective arithmetic coding algorithm is necessary to be able to decompress arbitrary bit streams. Matt Timmermans' code was ported to Python with the assistance of Anthropic's Claude 3.5 Sonnet for inclusion in this project. See the original ported code here.
-
Fabrice Bellard's ts_sms and ts_zip projects
These projects essentially perform the opposite task as this one. In these projects, the arithmetic coder is actually used for compression, as it is designed to be used.
-
Neural Linguistic Steganography
This 2019 paper from Zachary Ziegler, Yuntian Deng, and Alexander Rush explores the same idea as what is proposed here. They also provide a web application and associated source code for their implementation. See also the Hacker News discussion of the app.
Their project has some key differences from this one. It is able to achieve better efficiency with natural language inputs by compressing the inputs first before decompressing them under a different LLM context. Textcoder does not compress the inputs first. However, Textcoder supports authentication and encryption of the inputs, which their system does not.
-
Perfectly Secure Steganography Using Minimum Entropy Coupling
This 2023 paper from Christian Schroeder de Witt, Samuel Sokota, J. Zico Kolter, Jakob Foerster, and Martin Strohmeier describes some possible improvements upon this technique. The paper was discussed on Hacker News here. See also the Quanta article covering this paper and the associated Hacker News discussion of that article.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for textcoder
Similar Open Source Tools
textcoder
Textcoder is a proof-of-concept tool for steganographically encoding secret messages into ordinary text using arithmetic coding based on a statistical model derived from an LLM. It encrypts the secret message to produce a pseudorandom bit stream, which is then decompressed to generate text that appears randomly sampled from the LLM while encoding the secret message in specific token choices.
qlora-pipe
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.
sorcery
Sorcery is a SillyTavern extension that allows AI characters to interact with the real world by executing user-defined scripts at specific events in the chat. It is easy to use and does not require a specially trained function calling model. Sorcery can be used to control smart home appliances, interact with virtual characters, and perform various tasks in the chat environment. It works by injecting instructions into the system prompt and intercepting markers to run associated scripts, providing a seamless user experience.
llms-txt
The llms-txt repository proposes a standardization on using an `/llms.txt` file to provide information to help large language models (LLMs) use a website at inference time. The `llms.txt` file is a markdown file that offers brief background information, guidance, and links to more detailed information in markdown files. It aims to provide concise and structured information for LLMs to access easily, helping users interact with websites via AI helpers. The repository also includes tools like a CLI and Python module for parsing `llms.txt` files and generating LLM context from them, along with a sample JavaScript implementation. The proposal suggests adding clean markdown versions of web pages alongside the original HTML pages to facilitate LLM readability and access to essential information.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.
llmap
LLMap is a CLI code search tool designed to automatically find context in large codebases by evaluating the relevance of each source file using DeepSeek-V3 and DeepSeek-R1. It optimizes analysis by performing multi-stage analysis and caching results for faster searches. Currently supports Java and Python files, with potential for extension to other languages. Install with 'pip install llmap-ai' and use with a DeepSeek API key to search for specific context in code.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.
llm_steer
LLM Steer is a Python module designed to steer Large Language Models (LLMs) towards specific topics or subjects by adding steer vectors to different layers of the model. It enhances the model's capabilities, such as providing correct responses to logical puzzles. The tool should be used in conjunction with the transformers library. Users can add steering vectors to specific layers of the model with coefficients and text, retrieve applied steering vectors, and reset all steering vectors to the initial model. Advanced usage involves changing default parameters, but it may lead to the model outputting gibberish in most cases. The tool is meant for experimentation and can be used to enhance role-play characteristics in LLMs.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
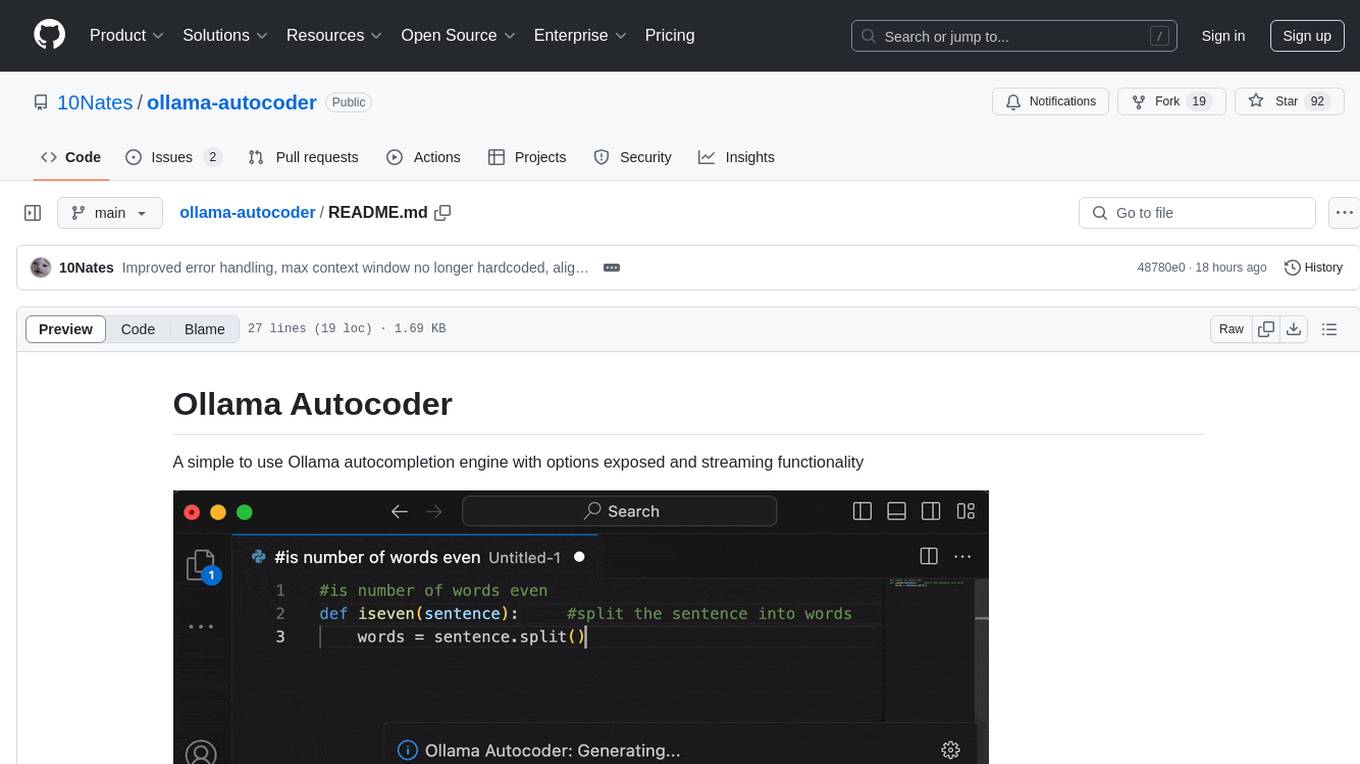
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
agent-os
The Agent OS is an experimental framework and runtime to build sophisticated, long running, and self-coding AI agents. We believe that the most important super-power of AI agents is to write and execute their own code to interact with the world. But for that to work, they need to run in a suitable environment—a place designed to be inhabited by agents. The Agent OS is designed from the ground up to function as a long-term computing substrate for these kinds of self-evolving agents.

deep-seek
DeepSeek is a new experimental architecture for a large language model (LLM) powered internet-scale retrieval engine. Unlike current research agents designed as answer engines, DeepSeek aims to process a vast amount of sources to collect a comprehensive list of entities and enrich them with additional relevant data. The end result is a table with retrieved entities and enriched columns, providing a comprehensive overview of the topic. DeepSeek utilizes both standard keyword search and neural search to find relevant content, and employs an LLM to extract specific entities and their associated contents. It also includes a smaller answer agent to enrich the retrieved data, ensuring thoroughness. DeepSeek has the potential to revolutionize research and information gathering by providing a comprehensive and structured way to access information from the vastness of the internet.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
clippinator
Clippinator is a code assistant tool that helps users develop code autonomously by planning, writing, debugging, and testing projects. It consists of agents based on GPT-4 that work together to assist the user in coding tasks. The main agent, Taskmaster, delegates tasks to specialized subagents like Architect, Writer, Frontender, Editor, QA, and Devops. The tool provides project architecture, tools for file and terminal operations, browser automation with Selenium, linting capabilities, CI integration, and memory management. Users can interact with the tool to provide feedback and guide the coding process, making it a powerful tool when combined with human intervention.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
For similar tasks
textcoder
Textcoder is a proof-of-concept tool for steganographically encoding secret messages into ordinary text using arithmetic coding based on a statistical model derived from an LLM. It encrypts the secret message to produce a pseudorandom bit stream, which is then decompressed to generate text that appears randomly sampled from the LLM while encoding the secret message in specific token choices.
For similar jobs
CipherChat
CipherChat is a novel framework designed to examine the generalizability of safety alignment to non-natural languages, specifically ciphers. The framework utilizes human-unreadable ciphers to potentially bypass safety alignments in natural language models. It involves teaching a language model to comprehend ciphers, converting input into a cipher format, and employing a rule-based decrypter to convert model output back to natural language.
textcoder
Textcoder is a proof-of-concept tool for steganographically encoding secret messages into ordinary text using arithmetic coding based on a statistical model derived from an LLM. It encrypts the secret message to produce a pseudorandom bit stream, which is then decompressed to generate text that appears randomly sampled from the LLM while encoding the secret message in specific token choices.
last_layer
last_layer is a security library designed to protect LLM applications from prompt injection attacks, jailbreaks, and exploits. It acts as a robust filtering layer to scrutinize prompts before they are processed by LLMs, ensuring that only safe and appropriate content is allowed through. The tool offers ultra-fast scanning with low latency, privacy-focused operation without tracking or network calls, compatibility with serverless platforms, advanced threat detection mechanisms, and regular updates to adapt to evolving security challenges. It significantly reduces the risk of prompt-based attacks and exploits but cannot guarantee complete protection against all possible threats.
aircrack-ng
Aircrack-ng is a comprehensive suite of tools designed to evaluate the security of WiFi networks. It covers various aspects of WiFi security, including monitoring, attacking (replay attacks, deauthentication, fake access points), testing WiFi cards and driver capabilities, and cracking WEP and WPA PSK. The tools are command line-based, allowing for extensive scripting and have been utilized by many GUIs. Aircrack-ng primarily works on Linux but also supports Windows, macOS, FreeBSD, OpenBSD, NetBSD, Solaris, and eComStation 2.
reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.
AutoAudit
AutoAudit is an open-source large language model specifically designed for the field of network security. It aims to provide powerful natural language processing capabilities for security auditing and network defense, including analyzing malicious code, detecting network attacks, and predicting security vulnerabilities. By coupling AutoAudit with ClamAV, a security scanning platform has been created for practical security audit applications. The tool is intended to assist security professionals with accurate and fast analysis and predictions to combat evolving network threats.
aif
Arno's Iptables Firewall (AIF) is a single- & multi-homed firewall script with DSL/ADSL support. It is a free software distributed under the GNU GPL License. The script provides a comprehensive set of configuration files and plugins for setting up and managing firewall rules, including support for NAT, load balancing, and multirouting. It offers detailed instructions for installation and configuration, emphasizing security best practices and caution when modifying settings. The script is designed to protect against hostile attacks by blocking all incoming traffic by default and allowing users to configure specific rules for open ports and network interfaces.

watchtower
AIShield Watchtower is a tool designed to fortify the security of AI/ML models and Jupyter notebooks by automating model and notebook discoveries, conducting vulnerability scans, and categorizing risks into 'low,' 'medium,' 'high,' and 'critical' levels. It supports scanning of public GitHub repositories, Hugging Face repositories, AWS S3 buckets, and local systems. The tool generates comprehensive reports, offers a user-friendly interface, and aligns with industry standards like OWASP, MITRE, and CWE. It aims to address the security blind spots surrounding Jupyter notebooks and AI models, providing organizations with a tailored approach to enhancing their security efforts.