
ChatGPT-Telegram-Bot
TeleChat: 🤖️ an AI chat Telegram bot can Web Search Powered by GPT-5, DALL·E , Groq, Gemini 2.5 Pro/Flash and the official Claude4.1 API using Python on Zeabur, fly.io and Replit.
Stars: 1119
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.
README:
![]()

ChatGPT Telegram Bot is a powerful Telegram bot that supports OpenAI-compatible large language model APIs. It enables users to have efficient conversations and information searches on Telegram. For support of other models from providers such as Anthropic, Gemini, Vertex AI, Azure, AWS, XAI, Cohere, Groq, Cloudflare, OpenRouter, etc., please use my other project, uni-api, to integrate them. This helps reduce maintenance costs. Thank you for your understanding.
- Multiple AI Models: Supports APIs compatible with the OpenAI format. For other models from providers such as Anthropic, Gemini, Vertex AI, Azure, AWS, XAI, Cohere, Groq, Cloudflare, OpenRouter, etc., please integrate them using uni-api. Also supports one-api/new-api. Utilizes self-developed API to request backend SDK, does not rely on OpenAI SDK.
- Multimodal Question Answering: Supports question answering for voice, audio, images, and PDF/TXT/MD/python documents. Users can directly upload files in the chat box for use.
- Model Grouping System: Organize AI models into logical groups for easier selection. Models can be grouped by provider (GPT, Claude, etc.) or by capability. Models without an explicit group are automatically placed in an "OTHERS" group. This makes model selection more intuitive, especially when many models are available.
- Group Chat Topic Mode: Supports enabling topic mode in group chats, isolating APIs, dialogue history, plugin configurations, and preferences between topics.
- Rich plugin system: Supports web search (DuckDuckGo and Google), URL summarization, ArXiv paper summarization, and code interpreter.
- User-friendly interface: Allows flexible switching of models within the chat window and supports streaming output similar to a typewriter effect. Supports precise Markdown message rendering, utilizing another of my projects.
- Efficient Message Processing: Asynchronously processes messages, answers questions in a multi-threaded manner, supports isolated dialogues, and provides unique dialogues for different users.
- Long Text Message Handling: Automatically merges long text messages, breaking through Telegram's single message length limit. When the bot's response exceeds the Telegram limit, it will be split into multiple messages.
- Multi-user Dialogue Isolation: Supports dialogue isolation and configuration isolation, allowing selection between multi-user and single-user modes.
- Question Prediction: Automatically generates follow-up questions, anticipating what users might ask next.
- Multi-language Interface: Supports Simplified Chinese, Traditional Chinese, Russian and English interfaces.
- Whitelist, Blacklist, and Admin Settings: Supports setting up whitelists, blacklists, and administrators.
- Inline Mode: Allows users to @ the bot in any chat window to generate answers without needing to ask questions in the bot's chat window.
- Convenient Deployment: Supports one-click koyeb, Zeabur, Replit deployment with true zero cost and idiot-proof deployment process. It also supports kuma anti-sleep, as well as Docker and fly.io deployment.
The following is a list of environment variables related to the bot's core settings:
| Variable Name | Description | Required? |
|---|---|---|
| BOT_TOKEN | Telegram bot token. Create a bot on BotFather to get the BOT_TOKEN. | Yes |
| API_KEY | OpenAI or third-party API key. | Yes |
| MODEL | Set the default QA model; the default is:gpt-5. This item can be freely switched using the bot's "info" command, and it doesn't need to be set in principle. |
No |
| WEB_HOOK | Whenever the telegram bot receives a user message, the message will be passed to WEB_HOOK, where the bot will listen to it and process the received messages in a timely manner. | No |
| BASE_URL | If you are using the OpenAI official API, you don't need to set this. If you using a third-party API, you need to fill in the third-party proxy website. The default is: https://api.openai.com/v1/chat/completions | No |
| NICK | The default is empty, and NICK is the name of the bot. The bot will only respond when the message starts with NICK that the user inputs, otherwise the bot will respond to any message. Especially in group chats, if there is no NICK, the bot will reply to all messages. | No |
| GOOGLE_API_KEY | If you need to use Google search, you need to set it. If you do not set this environment variable, the bot will default to provide duckduckgo search. | No |
| GOOGLE_CSE_ID | If you need to use Google search, you need to set it together with GOOGLE_API_KEY. | No |
| whitelist | Set which users can access the bot, and connect the user IDs authorized to use the bot with ','. The default value is None, which means that the bot is open to everyone. |
No |
| BLACK_LIST | Set which users are prohibited from accessing the bot, and connect the user IDs authorized to use the bot with ','. The default value is None
|
No |
| ADMIN_LIST | Set up an admin list. Only admins can use the /info command to configure the bot. |
No |
| GROUP_LIST | Set up a list of groups that can use the bot. Connect the group IDs with a comma (','). Even if group members are not on the whitelist, as long as the group ID is in the GROUP_LIST, all members of the group can use the bot. | No |
| CUSTOM_MODELS | Set a list of custom model names. Use commas (',') to connect model names. If you need to remove a default model, add a hyphen (-) before the default model name. To remove all default models, use -all. To create model groups, use semicolons (';') to separate groups and use colon (':') to define group name with its models, e.g., CUSTOM_MODELS=-all,command,grok-2;GPT:gpt-5,gpt-3.5-turbo;Claude:claude-3-opus,claude-3-sonnet;OTHERS. Models without specific groups will be automatically placed in the "OTHERS" group. |
No |
| CHAT_MODE | Introduce multi-user mode, different users' configurations are not shared. When CHAT_MODE is global, all users share the configuration. When CHAT_MODE is multiusers, user configurations are independent of each other. |
No |
| temperature | Specify the temperature of the LLM. The default value is 0.5. |
No |
| GET_MODELS | Specify whether to get supported models via API. Default is False. |
No |
| SYSTEMPROMPT | Specify system prompt, the system prompt is a string, for example: SYSTEMPROMPT=You are ChatGPT, a large language model trained by OpenAI. Respond conversationally. The default is None. The setting of the system prompt is only effective when CHAT_MODE is global. When CHAT_MODE is multiusers, the system prompt environment variable will not modify any user's system prompt regardless of its value, because users do not want their set system to be changed to a global system prompt. |
No |
| LANGUAGE | Specifies the default language displayed by the bot, including button display language and dialogue language. The default is English. Currently, it only supports setting to the following four languages: English, Simplified Chinese, Traditional Chinese, Russian. You can also use the /info command to set the display language after the bot is deployed. |
No |
| CONFIG_DIR | Specify storage user profile folder. CONFIG_DIR is the folder for storing user configurations. Each time the bot starts, it reads the configurations from the CONFIG_DIR folder, so users won't lose their previous settings every time they restart. you can achieve configuration persistence by mounting folders using the -v parameter when deploying locally with Docker. Default is user_configs. |
No |
| RESET_TIME | Specifies how many seconds the bot resets the chat history. Every RESET_TIME seconds, the bot will reset the chat history for all users except the admin list. The reset time for each user is different, calculated based on the last question time of each user to determine the next reset time. It is not all users resetting at the same time. The default value is 3600 seconds, and the minimum value is 60 seconds. |
No |
The following is a list of environment variables related to robot preferences. Preferences can also be set after the robot is started by using the /info command and clicking the Preferences button:
| Variable Name | Description | Required? |
|---|---|---|
| PASS_HISTORY | The default value is 9999. The bot will remember the conversation history and consider the context in the next reply. If set to 0, the bot will forget the conversation history and only consider the current conversation. The value of PASS_HISTORY must be greater than or equal to 0. It corresponds to the button named Chat history in the preferences. |
No |
| LONG_TEXT | If the length of the user's input message exceeds Telegram's limit and multiple messages are sent consecutively in a short period, the bot will treat these multiple messages as one. The default value is True. Corresponds to the button named Long text merge in the preferences. |
No |
| IMAGEQA | Enable image question answering, the default setting is that the model can answer image content, the default value is True. Corresponds to the button named Image Q&A in the preferences. |
No |
| LONG_TEXT_SPLIT | When the bot's reply exceeds Telegram's limit, it will be split into multiple messages. The default value is True. Corresponds to the button named Long text split in the preferences. |
No |
| FILE_UPLOAD_MESS | When a file or image upload is successful and the bot has finished processing, the bot will send a message indicating that the upload was successful. The default value is True. This corresponds to the button named File uploaded message in the preferences. |
No |
| FOLLOW_UP | Automatically generate multiple related questions for the user to choose from. The default value is False. Corresponds to the button named Question suggestions in the preferences. |
No |
| TITLE | Whether to display the model name at the beginning of the robot's reply. The default value is False. Corresponds to the button named Model title in the preferences. |
No |
| REPLY | Should the robot reply to the user's message in the "reply" format. The default value is False. Corresponds to the button named Reply message in the preferences. |
No |
The following is a list of environment variables related to the bot's plugin settings:
| Variable Name | Description | Required? |
|---|---|---|
| get_search_results | Whether to enable the search plugin. Default is False. |
No |
| get_url_content | Whether to enable the URL summarization plugin. Default is False. |
No |
| download_read_arxiv_pdf | Whether to enable the arXiv paper summarization plugin. Default is False. |
No |
| run_python_script | Whether to enable the code interpreter plugin. Default is False. |
No |
| generate_image | Whether to enable the image generation plugin. Default is False. |
No |
| get_time | Whether to enable the date plugin. Default is False. |
No |
There are two ways to deploy on Koyeb, one is to use the one-click deployment with the Docker image provided by Koyeb, and the other is to import this repository for deployment. Both methods are free. The first method is simple to deploy but cannot update automatically, while the second method is slightly more complex but can update automatically.
Click the button below to automatically deploy using the pre-built Docker image with one click:

In the environment variables, fill in BOT_TOKEN, API, BASE_URL, and click the deploy button. WEB_HOOK environment variable can be left as is, and Koyeb will automatically assign a subdomain.
-
Fork this repository Click to fork this repository
-
When deploying, you need to choose the repository method, set
Run commandtopython3 bot.py, and setExposed portsto8080. -
Install pull to automatically sync this repository.
One-click deployment:

If you need follow-up function updates, the following deployment method is recommended:
- Fork this repository first, then register for Zeabur. Currently, Zeabur does not support free Docker container deployment. If you need to use Zeabur to deploy the bot for this project, you will need to upgrade to the Developer Plan. Fortunately, Zeabur has introduced their sponsorship program, which offers a one-month Developer Plan to all contributors of this project. If you have features you'd like to enhance, feel free to submit pull requests to this project.
- Import from your own Github repository.
- Set the required environment variables, and redeploy.
- If you need function updates in the follow-up, just synchronize this repository in your own repository and redeploy in Zeabur to get the latest functions.
After importing the Github repository, set the running command
pip install -r requirements.txt > /dev/null && python3 bot.pySelect Secrets in the Tools sidebar, add the environment variables required by the bot, where:
- WEB_HOOK: Replit will automatically assign a domain name to you, fill in
https://appname.username.repl.co - Remember to open "Always On"
Click the run button on the top of the screen to run the bot.
Official documentation: https://fly.io/docs/
Use Docker image to deploy fly.io application
flyctl launch --image yym68686/chatgpt:latestEnter the name of the application when prompted, and select No for initializing Postgresql or Redis.
Follow the prompts to deploy. A secondary domain name will be provided in the official control panel, which can be used to access the service.
Set environment variables
flyctl secrets set BOT_TOKEN=bottoken
flyctl secrets set API=
# optional
flyctl secrets set WEB_HOOK=https://flyio-app-name.fly.dev/
flyctl secrets set NICK=javisView all environment variables
flyctl secrets listRemove environment variables
flyctl secrets unset MY_SECRET DATABASE_URLssh to fly.io container
flyctl ssh issue --agent
# ssh connection
flyctl ssh establishCheck whether the webhook URL is correct
https://api.telegram.org/bot<token>/getWebhookInfoStart the container
docker run -p 80:8080 --name chatbot -dit \
-e BOT_TOKEN=your_telegram_bot_token \
-e API= \
-e BASE_URL= \
-v ./user_configs:/home/user_configs \
yym68686/chatgpt:latestOr if you want to use Docker Compose, here is a docker-compose.yml example:
version: "3.5"
services:
chatgptbot:
container_name: chatgptbot
image: yym68686/chatgpt:latest
environment:
- BOT_TOKEN=
- API=
- BASE_URL=
- CUSTOM_MODELS=-all;GPT:gpt-5,gpt-3.5-turbo;Claude:claude-3-opus,claude-3-sonnet
volumes:
- ./user_configs:/home/user_configs
ports:
- 80:8080Run Docker Compose container in the background
docker-compose pull
docker-compose up -d
# uni-api
docker-compose -f docker-compose-uni-api.yml up -dPackage the Docker image in the repository and upload it to Docker Hub
docker build --no-cache -t chatgpt:latest -f Dockerfile.build --platform linux/amd64 .
docker tag chatgpt:latest yym68686/chatgpt:latest
docker push yym68686/chatgpt:latestOne-Click Restart Docker Image
set -eu
docker pull yym68686/chatgpt:latest
docker rm -f chatbot
docker run -p 8080:8080 -dit --name chatbot \
-e BOT_TOKEN= \
-e API= \
-e BASE_URL= \
-e GOOGLE_API_KEY= \
-e GOOGLE_CSE_ID= \
-e claude_api_key= \
-v ./user_configs:/home/user_configs \
yym68686/chatgpt:latest
docker logs -f chatbotThis script is for restarting the Docker image with a single command. It first removes the existing Docker container named "chatbot" if it exists. Then, it runs a new Docker container with the name "chatbot", exposing port 8080 and setting various environment variables. The Docker image used is "yym68686/chatgpt:latest". Finally, it follows the logs of the "chatbot" container.
python >= 3.10
Run the robot directly from the source code without using docker, Clone the repository:
git clone --recurse-submodules --depth 1 -b main --quiet https://github.com/yym68686/ChatGPT-Telegram-Bot.gitInstall Dependencies:
pip install -r requirements.txtConfigure Environment Variables:
./configure_env.shRun:
python bot.pyThis project supports multiple plugins, including: DuckDuckGo and Google search, URL summary, ArXiv paper summary, DALLE-3 drawing, and code interpreter, etc. You can enable or disable these plugins by setting environment variables.
- How to develop a plugin?
All the code related to plugins is in the git submodule aient within this repository. aient is an independent repository that I developed to handle API requests, conversation history management, and other functions. When you clone this repository using the --recurse-submodules parameter with git clone, aient will be automatically downloaded to your local machine. All the plugin code in this repository is located at the relative path aient/src/aient/plugins. You can add your own plugin code in this directory. The plugin development process is as follows:
-
Create a new Python file in the
aient/src/aient/pluginsdirectory, for example,myplugin.py. Register the plugin by adding the@register_tool()decorator above your function. Importregister_toolviafrom .registry import register_tool. -
Add translations for the plugin name in various languages in the utils/i18n.py file.
After completing the above steps, your plugin is ready to use. 🎉
- What is the use of the WEB_HOOK environment variable? How should it be used?
WEB_HOOK is a webhook address. Specifically, when a Telegram bot receives a user message, it sends the message to the Telegram server, which then forwards the message to the server at the WEB_HOOK address set by the bot. Therefore, when a message is sent to the bot, the bot executes the processing program almost immediately. Receiving messages via WEB_HOOK results in faster response times than when WEB_HOOK is not set.
When deploying a bot using platforms like Zeabur, Replit, or Koyeb, these platforms provide you with a domain name that you need to fill in the WEB_HOOK, so the bot can receive user messages. Of course, not setting WEB_HOOK is also possible, but the bot's response time will be slightly longer, although the difference is not significant, so generally setting WEB_HOOK is not necessary.
When deploying a bot on a server, you need to use reverse proxy tools like nginx or caddy to forward messages sent by the Telegram server to your server, so the bot can receive user messages. Therefore, you need to set WEB_HOOK to your server's domain name and forward the traffic requesting WEB_HOOK to the server and corresponding port where the bot is located. For example, in caddy, you can configure it like this in the caddy configuration file /etc/caddy/Caddyfile:
your_webhook_domain.com {
reverse_proxy localhost:8082
}- Why can't I use Google search?
By default, DuckDuckGo search is provided. The official API for Google search needs to be applied for by the user. It can provide real-time information that GPT could not answer before, such as today's trending topics on Weibo, today's weather in a specific location, and the progress of a certain person or news event.
- Why can't I use the search function even though I added the Google search API?
There are two possibilities:
-
Only large language model (LLM) APIs that support tool usage can use the search function. Currently, this project only supports the search function for APIs of the OpenAI, Claude, and Gemini series models. APIs from other model providers are not supported for tool usage in this project at the moment. If you have a model provider you wish to adapt, you can contact the maintainer.
-
If you are using the APIs of OpenAI, Claude, and Gemini series models but cannot use the search function, it may be because the search function is not enabled. You can check whether the search function is enabled by clicking on preferences through the
/infocommand. -
If you are using the API of OpenAI, Claude, and Gemini series models, please ensure you are using the official API. If you are using a third-party relay API, the provider may be offering you the API through web scraping. APIs provided through web scraping cannot use tools use, meaning that all plugins of this project cannot be used. If you confirm that you are using the official API and still cannot search successfully, please contact the developer.
- How do I switch models?
You can switch between GPT3.5/4/4o, and other models using the "/info" command in the chat window.
- Can it be deployed in a group?
Yes, it supports whitelist to prevent abuse and information leakage.
- Why can't the bot talk when I add it to the group?
If this is the first time you add the bot to a group chat, you need to set the group privacy to disable in botfather, then remove the bot from the group chat and re-add it to use it normally.
The second method is to set the bot as an administrator, so the bot can be used normally. However, if you want to add the bot to a group chat where you are not an administrator, the first method is more suitable.
Another possibility is that the GROUP_LIST set is not the current group chat ID. Please check if GROUP_LIST is set; GROUP_LIST is the group ID, not the group name. The group ID starts with a minus sign followed by a string of numbers.
- How do the settings of GROUP_LIST, ADMIN_LIST, and whitelist affect the behavior of the bot?
If whitelist is not set, everyone can use the bot. If whitelist is set, only users in the whitelist can use the bot. If GROUP_LIST is set, only groups in the GROUP_LIST can use the bot. If both whitelist and GROUP_LIST are set, everyone in the group can use the bot, but only users in the whitelist can privately chat with the bot. If ADMIN_LIST is set, only users in the ADMIN_LIST can use the /info command to change the bot's settings. If ADMIN_LIST is not set, everyone can use the /info command to change the bot's configuration. GROUP_LIST can also contain channels, channel IDs start with a minus sign followed by a string of numbers.
- How should I set the BASE_URL?
The BASE_URL supports all suffixes, including: https://api.openai.com/v1/chat/completions, https://api.openai.com/v1, and https://api.openai.com/. The bot will automatically allocate different endpoints based on different uses.
- Is it necessary to configure the web_hook environment variable?
The web_hook is not a mandatory environment variable. You only need to set the domain name (which must be consistent with WEB_HOOK) and other environment variables as required for your application's functionality.
- I deployed a robot with docker compose. If the documentation is placed on the server locally, which directory should it be mounted to in order to take effect? Do I need to set additional configurations and modify the code?
You can directly send the documentation to the robot through the chat box, and the robot will automatically parse the documentation. To use the documentation dialogue function, you need to enable the historical conversation feature. There is no need for additional processing of the documentation.
- I still can't get it to work... I want to use it in a group, I've set the ADMIN_LIST to myself, and the GROUP_LIST to that group, with the whitelist left empty. However, only I can use it in that group, other members in the group are prompted with no permission, what's going on?
Here's a troubleshooting guide: Please carefully check if the GROUP_LIST is correct. The ID of a Telegram group starts with a negative sign followed by a series of numbers. If it's not, please use this bot bot to reacquire the group ID.
- I've uploaded a document, but it's not responding based on the content of the document. What's going on?
To use the document question and answer feature, you must first enable the history record. You can turn on the history record through the /info command, or by setting the environment variable PASS_HISTORY to be greater than to 2 to enable the history record by default. Please note that enabling the history record will incur additional costs, so this project does not enable the history record by default. This means that the question and answer feature cannot be used under the default settings. Before using this feature, you need to manually enable the history record.
- After setting the
NICK, there's no response when I @ the bot, and it only replies when the message starts with the nick. How can I make it respond to both the nick and @botname?
In a group chat scenario, if the environment variable NICK is not set, the bot will receive all group messages and respond to all of them. Therefore, it is necessary to set NICK. After setting NICK, the bot will only respond to messages that start with NICK. So, if you want to @ the bot to get a response, you just need to set NICK to @botname. This way, when you @ the bot in the group, the bot will detect that the message starts with @botname, and it will respond to the message.
- How many messages will the history keep?
All other models use the official context length settings, for example, the gpt-3.5-turbo-16k context is 16k, the gpt-5 context is 128k, and the Claude3/3.5 context is 200k. This limitation is implemented to save user costs, as most scenarios do not require a high context.
- How to delete the default model name from the model list?
You can use the CUSTOM_MODELS environment variable to complete it. For example, if you want to add gpt-5 and remove the gpt-3.5 model from the model list, please set CUSTOM_MODELS to gpt-5,-gpt-3.5. If you want to delete all default models at once, you can set CUSTOM_MODELS to -all,gpt-5.
- How do I organize models into groups?
You can use the CUSTOM_MODELS environment variable with a special syntax:
- Use semicolons (
;) to separate groups - Use a colon (
:) to define a group name and its models - List models within a group separated by commas (
,)
For example:
CUSTOM_MODELS=-all;GPT:gpt-5,gpt-4,gpt-3.5-turbo;Claude:claude-3-opus,claude-3-sonnet,claude-3-haiku;Gemini:gemini-1.5-pro,gemini-1.0-pro;command,grok-2
This creates three groups: "GPT", "Claude", and "Gemini", each containing their respective models. The models "command" and "grok-2" have no explicit group, so they'll automatically be placed in the "OTHERS" group.
To include an empty "OTHERS" group even if there are no ungrouped models, add "OTHERS" at the end:
CUSTOM_MODELS=-all;GPT:gpt-5;Claude:claude-3-opus;OTHERS
- How does conversation isolation specifically work?
Conversations are always isolated based on different windows, not different users. This means that within the same group chat window, the same topic, and the same private chat window, it is considered the same conversation. CHAT_MODE only affects whether configurations are isolated. In multi-user mode, each user's plugin configurations, preferences, etc., are independent and do not affect each other. In single-user mode, all users share the same plugin configurations and preferences. However, conversation history is always isolated. Conversation isolation is to protect user privacy, ensuring that users' conversation history, plugin configurations, preferences, etc., are not visible to other users.
- Why hasn't the Docker image been updated for a long time?
The Docker image only stores the runtime environment of the program. Currently, the runtime environment of the program is stable, and the environment dependencies have hardly changed, so the Docker image has not been updated. Each time the Docker image is redeployed, it will pull the latest code, so there is no need to worry about the Docker image update issue.
- Why does the container report an error "http connect error or telegram.error.TimedOut: Timed out" after starting?
This issue is likely caused by the server deploying Docker being unable to connect to the Telegram server or the instability of the Telegram server.
- In most cases, restarting the service, checking the server network environment, or waiting for the Telegram service to recover will suffice.
- Additionally, you might try communicating with the Telegram server via web hook, which might solve the problem.
- How to make docker retry infinitely instead of stop at beginning?
The --restart unless-stopped parameter in Docker sets the container's restart policy. Specifically:
-
unless-stopped: This policy means that the container will automatically restart if it stops, except when it is manually stopped. In other words, if the container stops due to an error or system reboot, it will automatically restart. However, if you manually stop the container (e.g., using the docker stop command), it will not restart on its own. This parameter is particularly useful for services that need to run continuously, as it ensures that the service will automatically recover from unexpected interruptions without requiring manual intervention.
-
Example: Suppose you have a Docker container running a web server, and you want it to restart automatically if it crashes or if the system reboots, but not if you manually stop it. You can use the following command:
docker run -d --name my-web-server -p 80:80 --restart unless-stopped my-web-server-imageIn this example, the web server container named my-web-server will restart automatically unless you manually stop it.
- Switching models, do I need to re-enter the prompt?
Yes, because switching models will reset the history, so you need to re-enter the prompt.
- What is the appropriate value for PASS_HISTORY?
The number of PASS_HISTORY is strictly equal to the number of messages in the conversation history. The recommended value is 2, because the system prompt occupies one message count. If set to 0, PASS_HISTORY will automatically reset to 2 to ensure the conversation proceeds normally. When PASS_HISTORY is less than or equal to 2, the bot's behavior can be regarded as only remembering the current conversation, i.e., one question and one answer, and it will not remember the content of the previous Q&A next time. There is no limit to the maximum value of PASS_HISTORY, but please note that the more messages in the conversation history, the higher the cost of each conversation will be. When PASS_HISTORY is not set, the default value is 9999, indicating that the number of messages in the conversation history is 9999.
- Can Bot tokens have multiple tokens?
No, in the future it will support multiple Bot Tokens.
- How to use robot commands?
-
/info: The robot/infocommand can view the robot's configuration information, including the current model in use, API URL, API key, etc. It can also change the robot's display language, preferences, and plugin settings. -
/start: The robot/startcommand can view the robot's usage instructions, usage methods, and function introduction. You can set the API key using the/startcommand. If you have an official OpenAI API key, please use the following command:/start your_api_key. If you are using a third-party API key, please use the following command:/start https://your_api_url your_api_key. -
/reset: The robot/resetcommand can clear the robot's conversation messages and force the robot to stop generating replies. If you want to reset the system prompt, please use the following command:/reset your_system_prompt. However, the/resetcommand will never restore the robot's display language, preferences, plugin settings, model in use, API URL, API key, system prompt, etc. -
/model: The robot/modelcommand allows you to quickly switch between AI models without going through the/infomenu. Simply use/model model_nameto switch to a specific model. For example:/model gpt-5to switch to GPT-5 or/model claude-3-opusto switch to Claude 3 Opus. This command provides a faster way to change models during conversations.
- What to do if Koyeb deployment fails?
Koyeb's free service can be a bit unstable, so deployment failures are pretty common. You might want to try redeploying, and if that doesn't work, consider switching to another platform. 😊
- Why does the default model name reappear after I use CUSTOM_MODELS to delete it, and then check again with the /info command?
If you deployed using docker-compose.yml, do not add quotes around the value of CUSTOM_MODELS. Incorrect usage: CUSTOM_MODELS="gpt-5,-gpt-3.5", otherwise it will cause environment variable parsing errors, resulting in the default model name reappearing. The incorrect way will be parsed as deleting the gpt-3.5" model, which will cause the default model name gpt-3.5 not to be deleted. The correct way to write it is: CUSTOM_MODELS=gpt-5,-gpt-3.5.
The same applies to model groups. Incorrect: CUSTOM_MODELS="GPT:gpt-5;Claude:claude-3-opus". Correct: CUSTOM_MODELS=GPT:gpt-5;Claude:claude-3-opus. If your group names or model names contain special characters, be careful with escaping.
https://core.telegram.org/bots/api
https://github.com/acheong08/ChatGPT
https://github.com/franalgaba/chatgpt-telegram-bot-serverless
The markdown rendering of the message used is another project of mine.
duckduckgo AI: https://github.com/mrgick/duck_chat
We are grateful for the support from the following sponsors:
-
@fasizhuanqian: 300 USDT
-
@ZETA: $380
-
@yuerbujin: ¥1200
-
@RR5AM: ¥300
-
@IKUNONHK: 30 USDT
-
@miya0v0: 30 USDT
-
@Zeabur: $25
-
@Bill_ZKE: 20 USDT
-
@wagon_look: ¥50
If you would like to support our project, you can sponsor us through the following methods:
-
USDT-TRC20, USDT-TRC20 Wallet Address:
TLFbqSv5pDu5he43mVmK1dNx7yBMFeN7d8
Thank you for your support!
This project is licensed under GPLv3, which means you are free to copy, distribute, and modify the software, as long as all modifications and derivative works are also released under the same license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChatGPT-Telegram-Bot
Similar Open Source Tools
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.
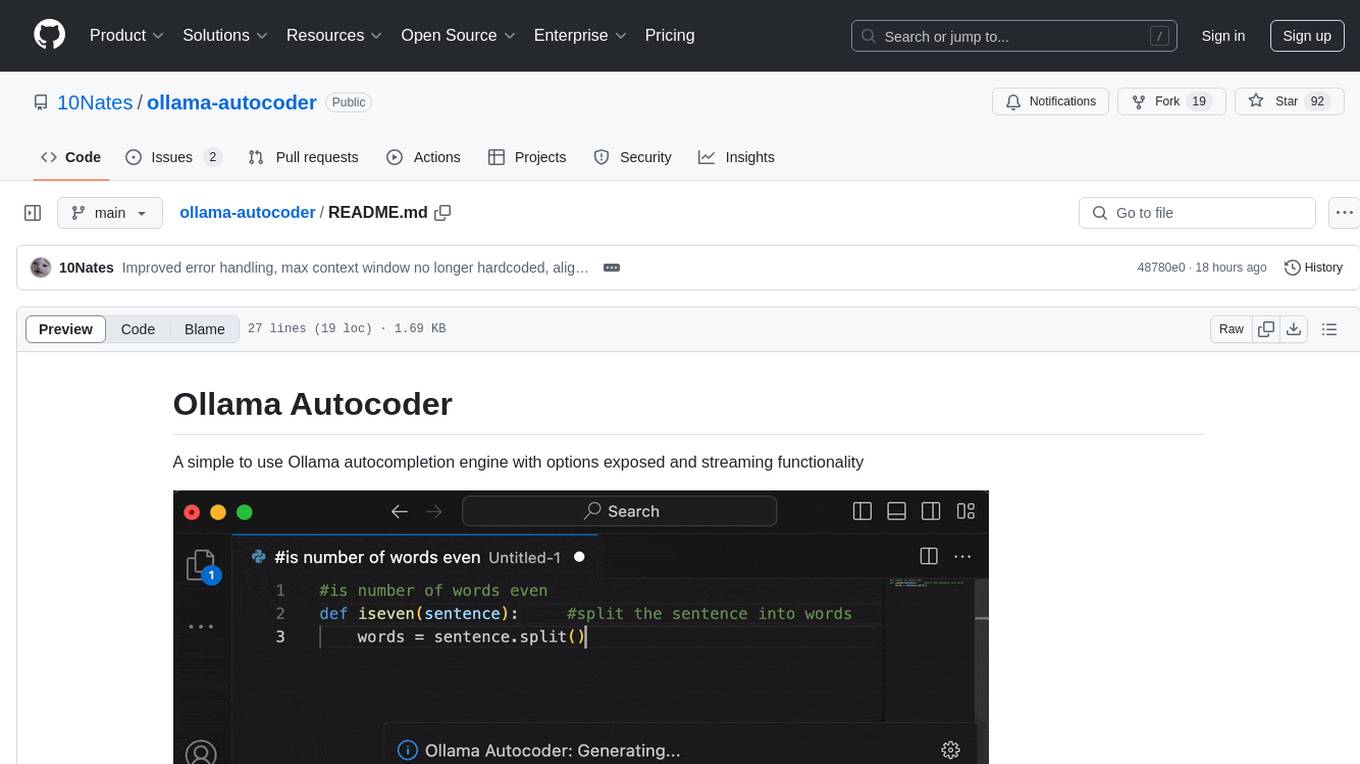
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
cookbook
This repository contains community-driven practical examples of building AI applications and solving various tasks with AI using open-source tools and models. Everyone is welcome to contribute, and we value everybody's contribution! There are several ways you can contribute to the Open-Source AI Cookbook: Submit an idea for a desired example/guide via GitHub Issues. Contribute a new notebook with a practical example. Improve existing examples by fixing issues/typos. Before contributing, check currently open issues and pull requests to avoid working on something that someone else is already working on.
boxcars
Boxcars is a Ruby gem that enables users to create new systems with AI composability, incorporating concepts such as LLMs, Search, SQL, Rails Active Record, Vector Search, and more. It allows users to work with Boxcars, Trains, Prompts, Engines, and VectorStores to solve problems and generate text results. The gem is designed to be user-friendly for beginners and can be extended with custom concepts. Boxcars is actively seeking ways to enhance security measures to prevent malicious actions. Users can use Boxcars for tasks like running calculations, performing searches, generating Ruby code for math operations, and interacting with APIs like OpenAI, Anthropic, and Google SERP.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.
cluster-toolkit
Cluster Toolkit is an open-source software by Google Cloud for deploying AI/ML and HPC environments on Google Cloud. It allows easy deployment following best practices, with high customization and extensibility. The toolkit includes tutorials, examples, and documentation for various modules designed for AI/ML and HPC use cases.

HackBot
HackBot is an AI-powered cybersecurity chatbot designed to provide accurate answers to cybersecurity-related queries, conduct code analysis, and scan analysis. It utilizes the Meta-LLama2 AI model through the 'LlamaCpp' library to respond coherently. The chatbot offers features like local AI/Runpod deployment support, cybersecurity chat assistance, interactive interface, clear output presentation, static code analysis, and vulnerability analysis. Users can interact with HackBot through a command-line interface and utilize it for various cybersecurity tasks.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.