
eureka-ml-insights
A framework for standardizing evaluations of large foundation models, beyond single-score reporting and rankings.
Stars: 106

The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.
README:
![]() Technical Report
Technical Report
![]() Blog Post
Blog Post
![]() Project Website
Project Website
- Eureka ML Insights Framework
- ✋ How to contribute:
- ✒️ Citation
- Responsible AI Considerations
The following table summarizes the benchmarks included in Eureka-Bench, their modalities, capabilities, and the corresponding experiment pipelines. The logs for each benchmark are available for download at the links provided in the table.
| Benchmark #prompts |
Modality | Capability | Logs | Pipeline Config |
|---|---|---|---|---|
| GeoMeter 1086 |
Image -> Text | Geometric Reasoning | GeoMeter.zip | geometer.py |
| MMMU 900 |
Image -> Text | Multimodal QA | MMMU.zip | mmmu.py |
| Image Understanding 10249 |
Image -> Text | Object Recognition Object Detection Visual Prompting Spatial Reasoning |
IMAGE_UNDERSTANDING.zip |
object_recognition.py object_detection.py visual_prompting.py spatial_reasoning.py |
| Vision Language 13500 |
Image -> Text | Spatial Understanding Navigation Counting |
VISION_LANGUAGE.zip |
spatial_map.py maze.py spatial_grid.py |
| IFEval 541 |
Text -> Text | Instruction Following | IFEval.zip | ifeval.py |
| FlenQA 12000 |
Text -> Text | Long Context Multi-hop QA | FlenQA.zip | flenQA.py |
| Kitab 34217 |
Text -> Text | Information Retrieval | Kitab.zip | kitab.py |
| Toxigen 10500 |
Text -> Text | Toxicity Detection Safe Language Generation |
ToxiGen.zip | toxigen.py |
Note: The benchmarks on Image Understanding will be available soon on HuggingFace. Please stay tuned.
For non-determinism evaluations using the above benchmarks, we provide pipelines in nondeterminism.py
To get started, clone this repository to your local machine and navigate to the project directory.
python3 -m venv .venv- Activate venv.
pip install -e .
- activate venv
- Update version inside setup.py if needed.
- Install wheel package via
pip install wheel python setup.py bdist_wheel- Fetch from dir dist/ the .whl
- This file can be installed via
pip install eureka_ml_insights.whl
- Make sure you have Conda installed on your system.
- Open a terminal and create a new Conda environment using the
environment.ymlfile:
conda env create --name myenv --file environment.yml - Activate your newly created environment:
conda activate myenv - [Optional] Install GPU packages if you have a GPU machine and want to self-host models:
conda env update --file environment_gpu.ymlInstallation tested for Unix/Linux, but it is currently not supported on Windows.
To reproduce the results of a pre-defined experiment pipeline, you can run the following command:
python main.py --exp_config exp_config_name --model_config model_config_name --exp_logdir your_log_dir
For example, to run the FlenQA_Experiment_Pipeline experiment pipeline defined in eureka_ml_insights/user_configs/flenqa.py using the OpenAI GPT4 1106 Preview model, you can run the following command:
python main.py --exp_config FlenQA_Experiment_Pipeline --model_config OAI_GPT4_1106_PREVIEW_CONFIG --exp_logdir gpt4_1106_preview
The results of the experiment will be saved in a directory under logs/FlenQA_Experiment_Pipeline/gpt4_1106_preview. For each experiment you run with these configurations, a new directory will be created using the date and time of the experiment run.
For other available experiment pipelines and model configurations, see the eureka_ml_insights/user_configs and eureka_ml_insights/configs directories, respectively. In model_configs.py you can configure the model classes to use your API keys, Key Vault urls, endpoints, and other model-specific configurations.
 Experiment pipelines define the sequence of components that are run to process data, run inference, and evaluate the model outputs. You can find examples of experiment pipeline configurations in the
Experiment pipelines define the sequence of components that are run to process data, run inference, and evaluate the model outputs. You can find examples of experiment pipeline configurations in the user_configs directory. To create a new experiment configuration, you need to define a class that inherits from ExperimentConfig and implements the configure_pipeline method. In the configure_pipeline method you define the Pipeline config (arrangement of Components) for your Experiment. Once your class is ready, add it to user_configs/__init__.py import list.
Your Pipeline can use any of the available Components which can be found under the core directory:
-
PromptProcessing: you can use this component to prepare your data for inference, apply transformation, or apply a Jinja prompt template. -
DataProcessing: you can use this component to to post-process the model outputs. -
Inference: you can use this component to run your model on any processed data, for example running inference on the model subject to evaluation, or another model that is involved in the evaluation pipeline as an evaluator or judge. -
EvalReporting: you can use this component to evaluate the model outputs using various metrics, aggregators and visualizers, and generate a report. -
DataJoin: you can use this component to join two sources of data, for example to join the model outputs with the ground truth data for evaluation.
Note that:
- You can inherit from one of the existing experiment config classes and override the necessary attributes to reduce the amount of code you need to write. You can find examples of this in spatial_reasoning.py.
- Your pipeline does not need to use all of the components. You can use only the components you need. And you can use the components multiple times in the pipeline.
- Make sure the input of each component matches the output of the previous component in the pipeline. The components are run sequentially in the order they are defined in the pipeline configuration.
- For standard scenarios you do not need to implement new components for your pipeline, but you do need to configure the existing components to use the correct utility classes (i.e. models, data readers, metrics, etc.) for your scenario.
Utility classes include Models, Metrics, DataLoaders, DataReaders, etc. The components in your pipeline need to use the correct utility classes for your scenario. For example, to evaluate an OpenAI model on a dataset that is available on HuggingFace, you need to use the HFDataReader data reader and the AzureOpenAIModel (or alternatively, DirectOpenAIModel) model class. In standard scenarios do not need to implement new components for your pipeline, but you do need to configure the existing components to work with the correct utility classes. If you need a functionality that is not provided by the existing utility classes, you can implement a new utility class and use it in your pipeline.
In general, to find out what utility classes and other attributes need to be configured for a component, you can look at the component's corresponding Config dataclass in configs/config.py. For example, if you are configuring the DataProcessing component, you can look at the DataProcessingConfig dataclass in configs/config.py.
Utility classes are also configurable. You can do so by providing the name of the class and the initialization arguments. For example see ModelConfig in configs/config.py that can be initialized with the model class name and the model initialization arguments. For example, you can see examples of configuring Model classes in configs/model_configs.py.
Our current components use the following utility classes: DataReader, DataLoader, Model, Metric, Aggregator. You can use the existing utility classes or implement new ones as needed to configure your components.
This component is used for general data processing tasks.
-
data_reader_config: Configuration for the DataReader that is used to load the data into a pandas dataframe, apply any necessary processing on it (optional), and return the processed data. We currently support local and Azure Blob Storage data sources.- Transformations: you can find the available transformations in
data_utils/transforms.py. If you need to implement new transform classes, add them to this file.
- Transformations: you can find the available transformations in
-
output_dir: This is the folder name where the processed data will be saved. This folder will automatically be created under the experiment log directory and the processed data will be saved in a file calledprocessed_data.jsonl. -
output_data_columns(OPTIONAL): This is the list of columns to save in transformed_data.jsonl. By default, all columns are saved.
This component inherits from the DataProcessing component and is used specifically for prompt processing tasks, such as applying a Jinja prompt template. If a prompt template is provided, the processed data will have a 'prompt' column that is expected by the inference component. Otherwise the input data is expected to already have a 'prompt' column. This component also reserves the "model_output" column for the model outputs so if it already exists in the input data, it will be removed.
In addition to the attributes of the DataProcessing component, the PromptProcessing component has the following attributes:
-
prompt_template_path(OPTIONAL): This template is used to format your data for model inference in case you need prompt templating or system prompts. Provide your jinja prompt template path to this component. See for exampleprompt_templates/basic.jinja. The prompt template processing step adds a 'prompt' column to the processed data, which is expected by the inference component. If you do not need prompt templating, make sure your data already does have a 'prompt' column. -
ignore_failure(OPTIONAL): Whether to ignore the failure of prompt processing on a row and move on to the next, or to raise an exception. Default is False.
-
model_config: Configuration of the model class to use for inference. You can find the available models inmodels/. -
data_loader_config: Configuration of the data_loader class to use for inference. You can find the available data classes indata_utils/data.py. -
output_dir: This is the folder name where the model outputs will be saved. This folder will automatically be created under the experiment log directory and the model outputs will be saved in a file calledinference_result.jsonl.
-
data_reader_config: Configuration object for the DataReader that is used to load the data into a pandas dataframe. This is the same type of utility class used in the DataProcessing component. -
metric_config: a MetricConfig object to specify the metric class to use for evaluation. You can find the available metrics inmetrics/. If you need to implement new metric classes, add them to this directory. -
aggregator_configs/visualizer_configs: List of configs for aggregators/visualizers to apply to the metric results. These classes that take metric results and aggragate/analyze/vizualize them and save them. You can find the available aggregators and visualizers inmetrics/reports.py. -
output_dir: This is the folder name where the evaluation results will be saved.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repositories using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
To contribute to the framework:
- please create a new branch.
- Implement your pipeline configuration class under
user_configs, as well as any utility classes that your pipeline requires. - Please add end-to-end tests for your contributions in the
testsdirectory. - Please add unit tests for any new utility classes you implement in the
testsdirectory. - Please add documentation to your classes and methods in form of docstrings.
- Then use
make format-inplaceto format the files you have changed. This will only work on files that git is tracking, so make sure togit addany newly created files before running this command. - Use
make lintersto check any remaining style or format issues and fix them manually. - Use
make testto run the tests and make sure they all pass. - Finally, submit a pull request.
If you use this framework in your research, please cite the following paper:
@article{eureka2024,
title={Eureka: Evaluating and Understanding Large Foundation Models},
author={Balachandran, Vidhisha and Chen, Jingya and Joshi, Neel and Nushi, Besmira and Palangi, Hamid and Salinas, Eduardo and Vineet, Vibhav and Woffinden-Luey, James and Yousefi, Safoora},
journal={Microsoft Research. MSR-TR-2024-33},
year={2024}
}
A cross-cutting dimension for all capability evaluations is the evaluation of several aspects of model behavior important for the responsible fielding of AI systems. These consideration include the fairness, reliability, safety, privacy, and security of models. While evaluations through the Toxigen dataset (included in Eureka-Bench) capture notions of representational fairness for different demographic groups and, to some extent, the ability of the model to generate safe language despite non-safe input triggers in the prompt, other aspects or nuances of fairness and safety require further evaluation and additional clarity, which we hope to integrate in future versions and welcome contributions for. We are also interested in expanding Eureka-Bench with tasks where fairness and bias can be studied in more benign settings that simulate how risks may appear when humans use AI to assist them in everyday tasks (e.g. creative writing, information search etc.) and subtle language or visual biases encoded in training data might be reflected in the AI's assistance.
A general rising concern on responsible AI evaluations is that there is a quick turnaround between new benchmarks being released and then included in content safety filters or in post training datasets. Because of this, scores on benchmarks focused on responsible and safe deployment may appear to be unusually high for most capable models. While the quick reaction is a positive development, from an evaluation and understanding perspective, the high scores indicate that the benchmarks are not sensitive enough to capture differences in alignment and safety processes followed for different models. At the same time, it is also the case that fielding thresholds for responsible AI measurements can be inherently higher and as such these evaluations will require a different interpretation lens. For example, a 5 percent error rate in instruction following for content length should not be weighed in the same way as a 5 percent error rate in detecting toxic content, or even a 5 percent success rates in jailbreak attacks. Therefore, successful and timely evaluations to this end depend on collaborative efforts that integrate red teaming, quantified evaluations, and human studies in the context of real-world applications.
Finally, Eureka and the set of associated benchmarks are only the initial snapshot of an effort that aims at reliably measuring progress in AI. Our team is excited about further collaborations with the open-source community and research, with the goal of sharing and extending current measurements for new capabilities and models. Our current roadmap involves enriching Eureka with more measurements around planning, reasoning, fairness, reliability and safety, and advanced multimodal capabilities for video and audio.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for eureka-ml-insights
Similar Open Source Tools
eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

airbroke
Airbroke is an open-source error catcher tool designed for modern web applications. It provides a PostgreSQL-based backend with an Airbrake-compatible HTTP collector endpoint and a React-based frontend for error management. The tool focuses on simplicity, maintaining a small database footprint even under heavy data ingestion. Users can ask AI about issues, replay HTTP exceptions, and save/manage bookmarks for important occurrences. Airbroke supports multiple OAuth providers for secure user authentication and offers occurrence charts for better insights into error occurrences. The tool can be deployed in various ways, including building from source, using Docker images, deploying on Vercel, Render.com, Kubernetes with Helm, or Docker Compose. It requires Node.js, PostgreSQL, and specific system resources for deployment.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.
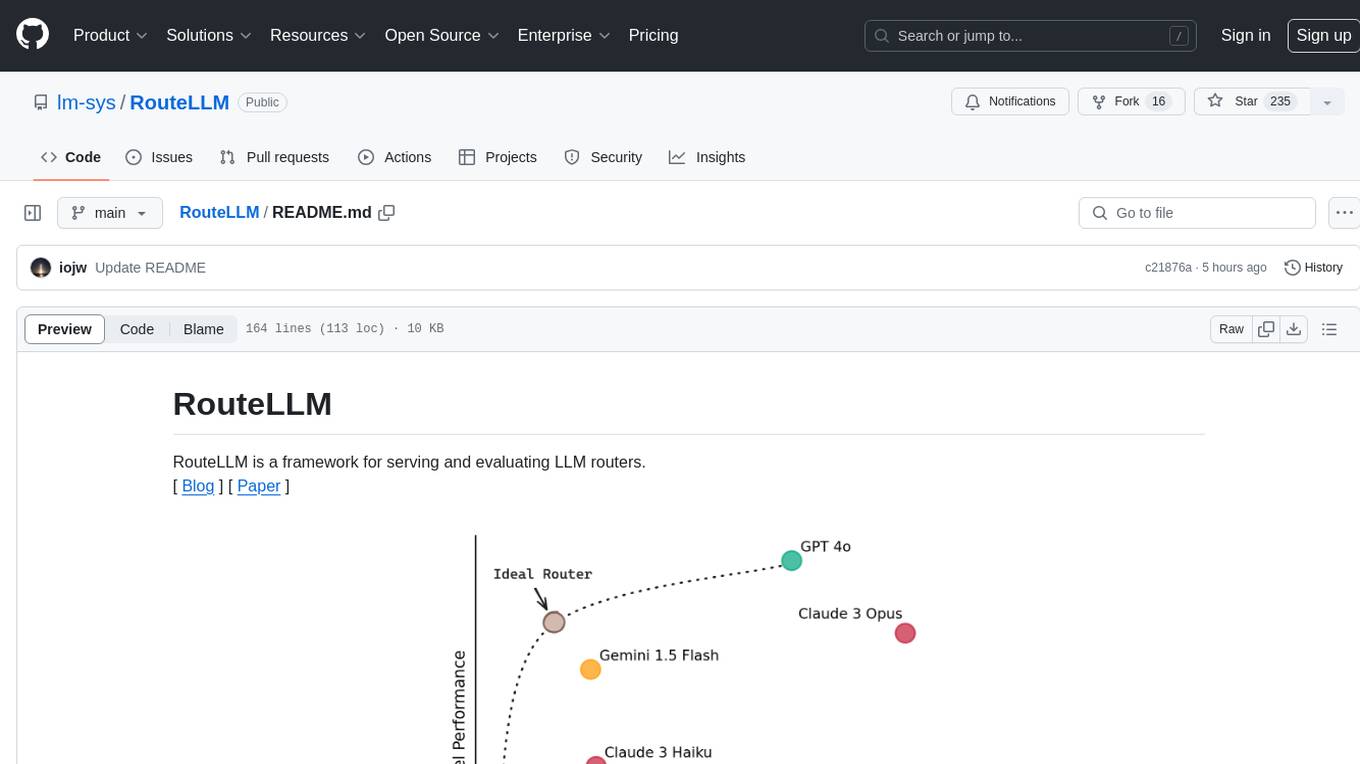
RouteLLM
RouteLLM is a framework for serving and evaluating LLM routers. It allows users to launch an OpenAI-compatible API that routes requests to the best model based on cost thresholds. Trained routers are provided to reduce costs while maintaining performance. Users can easily extend the framework, compare router performance, and calibrate cost thresholds. RouteLLM supports multiple routing strategies and benchmarks, offering a lightweight server and evaluation framework. It enables users to evaluate routers on benchmarks, calibrate thresholds, and modify model pairs. Contributions for adding new routers and benchmarks are welcome.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.
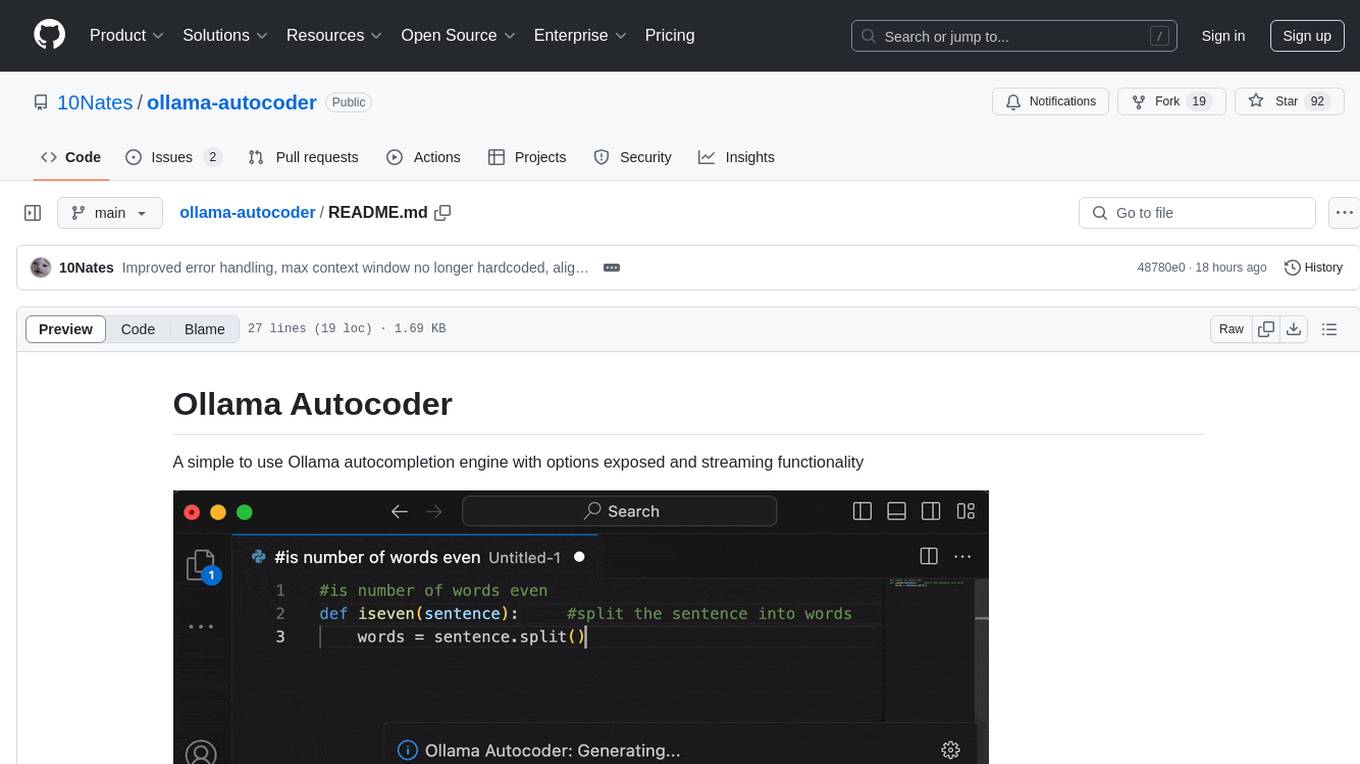
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.
langchain-google
LangChain Google is a repository containing three packages with Google integrations: langchain-google-genai for Google Generative AI models, langchain-google-vertexai for Google Cloud Generative AI on Vertex AI, and langchain-google-community for other Google product integrations. The repository is organized as a monorepo with a structure including libs for different packages, and files like pyproject.toml and Makefile for building, linting, and testing. It provides guidelines for contributing, local development dependencies installation, formatting, linting, working with optional dependencies, and testing with unit and integration tests. The focus is on maintaining unit test coverage and avoiding excessive integration tests, with annotations for GCP infrastructure-dependent tests.
cluster-toolkit
Cluster Toolkit is an open-source software by Google Cloud for deploying AI/ML and HPC environments on Google Cloud. It allows easy deployment following best practices, with high customization and extensibility. The toolkit includes tutorials, examples, and documentation for various modules designed for AI/ML and HPC use cases.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.
trinityX
TrinityX is an open-source HPC, AI, and cloud platform designed to provide all services required in a modern system, with full customization options. It includes default services like Luna node provisioner, OpenLDAP, SLURM or OpenPBS, Prometheus, Grafana, OpenOndemand, and more. TrinityX also sets up NFS-shared directories, OpenHPC applications, environment modules, HA, and more. Users can install TrinityX on Enterprise Linux, configure network interfaces, set up passwordless authentication, and customize the installation using Ansible playbooks. The platform supports HA, OpenHPC integration, and provides detailed documentation for users to contribute to the project.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.
cookbook
This repository contains community-driven practical examples of building AI applications and solving various tasks with AI using open-source tools and models. Everyone is welcome to contribute, and we value everybody's contribution! There are several ways you can contribute to the Open-Source AI Cookbook: Submit an idea for a desired example/guide via GitHub Issues. Contribute a new notebook with a practical example. Improve existing examples by fixing issues/typos. Before contributing, check currently open issues and pull requests to avoid working on something that someone else is already working on.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
For similar tasks
intro-llm-rag
This repository serves as a comprehensive guide for technical teams interested in developing conversational AI solutions using Retrieval-Augmented Generation (RAG) techniques. It covers theoretical knowledge and practical code implementations, making it suitable for individuals with a basic technical background. The content includes information on large language models (LLMs), transformers, prompt engineering, embeddings, vector stores, and various other key concepts related to conversational AI. The repository also provides hands-on examples for two different use cases, along with implementation details and performance analysis.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.
llm-colosseum
llm-colosseum is a tool designed to evaluate Language Model Models (LLMs) in real-time by making them fight each other in Street Fighter III. The tool assesses LLMs based on speed, strategic thinking, adaptability, out-of-the-box thinking, and resilience. It provides a benchmark for LLMs to understand their environment and take context-based actions. Users can analyze the performance of different LLMs through ELO rankings and win rate matrices. The tool allows users to run experiments, test different LLM models, and customize prompts for LLM interactions. It offers installation instructions, test mode options, logging configurations, and the ability to run the tool with local models. Users can also contribute their own LLM models for evaluation and ranking.
eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.
Pixelle-MCP
Pixelle-MCP is a multi-channel publishing tool designed to streamline the process of publishing content across various social media platforms. It allows users to create, schedule, and publish posts simultaneously on platforms such as Facebook, Twitter, and Instagram. With a user-friendly interface and advanced scheduling features, Pixelle-MCP helps users save time and effort in managing their social media presence. The tool also provides analytics and insights to track the performance of posts and optimize content strategy. Whether you are a social media manager, content creator, or digital marketer, Pixelle-MCP is a valuable tool to enhance your online presence and engage with your audience effectively.
trae-agent
Trae-agent is a Python library for building and training reinforcement learning agents. It provides a simple and flexible framework for implementing various reinforcement learning algorithms and experimenting with different environments. With Trae-agent, users can easily create custom agents, define reward functions, and train them on a variety of tasks. The library also includes utilities for visualizing agent performance and analyzing training results, making it a valuable tool for both beginners and experienced researchers in the field of reinforcement learning.
dataset-viewer
Dataset Viewer is a modern, high-performance tool built with Tauri, React, and TypeScript, designed to handle massive datasets from multiple sources with efficient streaming for large files (100GB+) and lightning-fast search capabilities. It supports instant large file opening, real-time search, direct archive preview, multi-protocol and multi-format support, and features a modern interface with dark/light themes and responsive design. The tool is perfect for data scientists, log analysis, archive management, remote access, and performance-critical tasks.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.