
promptfoo
Test your prompts, agents, and RAGs. AI Red teaming, pentesting, and vulnerability scanning for LLMs. Compare performance of GPT, Claude, Gemini, Llama, and more. Simple declarative configs with command line and CI/CD integration.
Stars: 10557

Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
README:




promptfoo is a developer-friendly local tool for testing LLM applications. Stop the trial-and-error approach - start shipping secure, reliable AI apps.
Website · Getting Started · Red Teaming · Documentation · Discord
# Install and initialize project
npx promptfoo@latest init
# Run your first evaluation
npx promptfoo evalSee Getting Started (evals) or Red Teaming (vulnerability scanning) for more.
- Test your prompts and models with automated evaluations
- Secure your LLM apps with red teaming and vulnerability scanning
- Compare models side-by-side (OpenAI, Anthropic, Azure, Bedrock, Ollama, and more)
- Automate checks in CI/CD
- Review pull requests for LLM-related security and compliance issues with code scanning
- Share results with your team
Here's what it looks like in action:
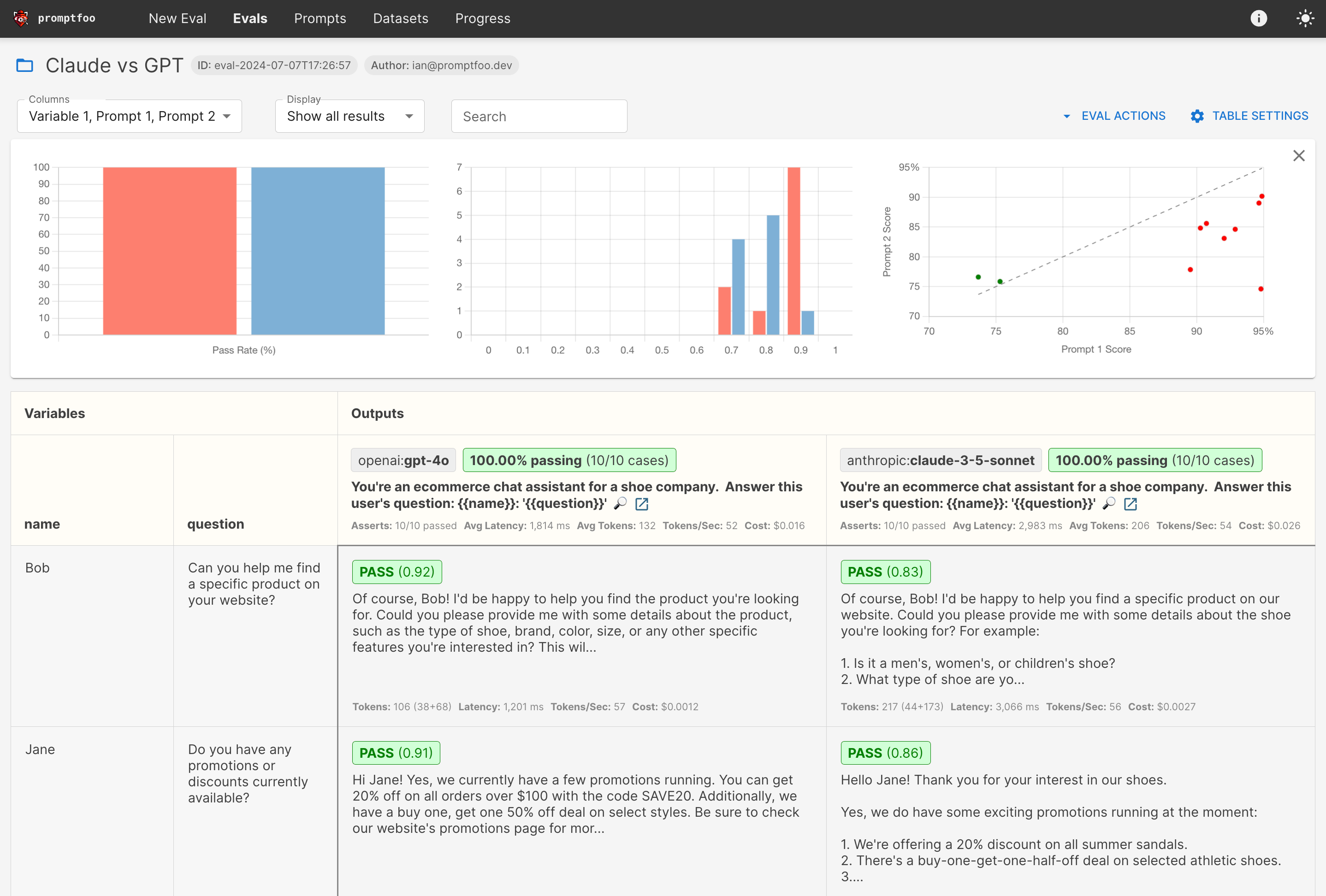
It works on the command line too:
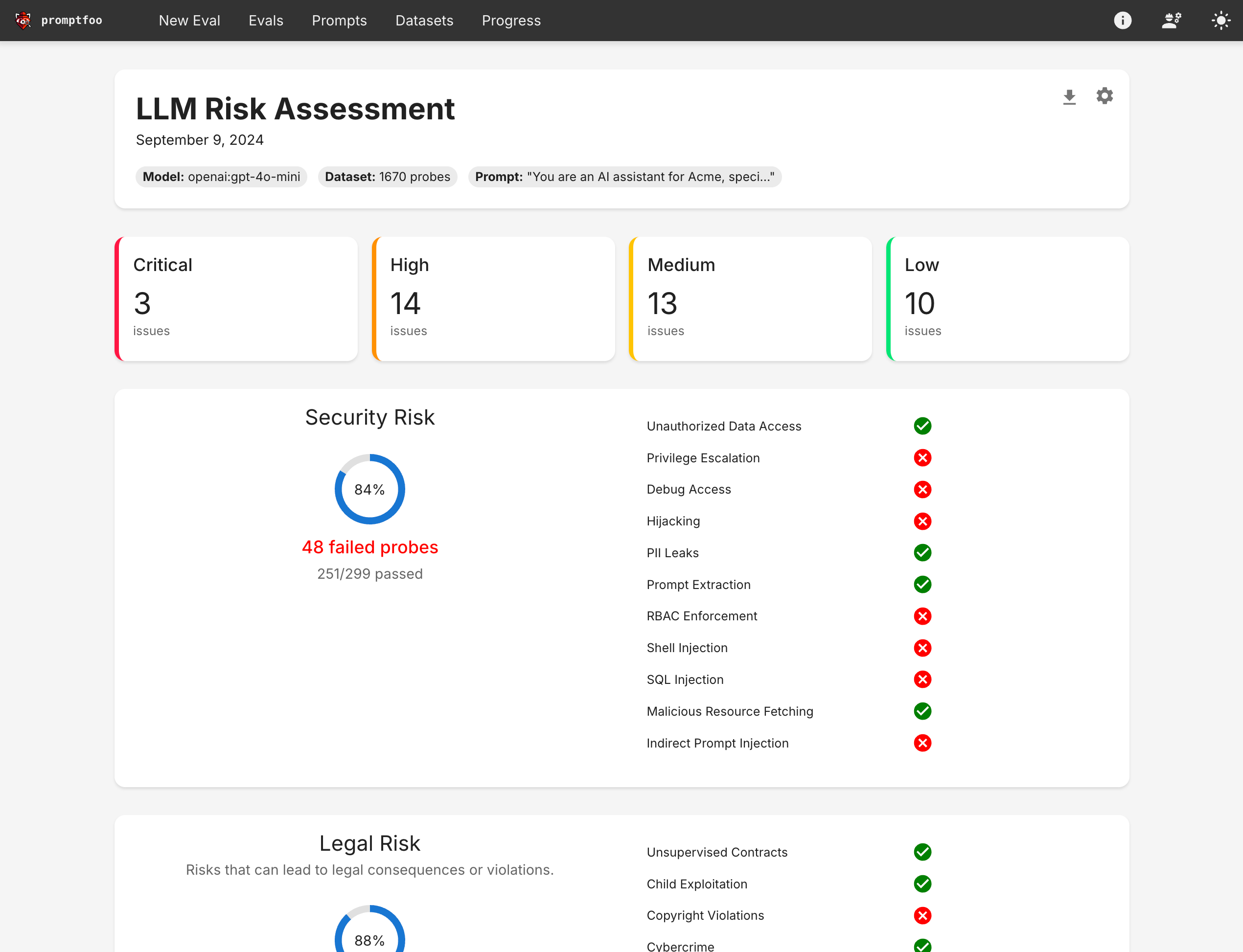
It also can generate security vulnerability reports:
- 🚀 Developer-first: Fast, with features like live reload and caching
- 🔒 Private: LLM evals run 100% locally - your prompts never leave your machine
- 🔧 Flexible: Works with any LLM API or programming language
- 💪 Battle-tested: Powers LLM apps serving 10M+ users in production
- 📊 Data-driven: Make decisions based on metrics, not gut feel
- 🤝 Open source: MIT licensed, with an active community
- 📚 Full Documentation
- 🔐 Red Teaming Guide
- 🎯 Getting Started
- 💻 CLI Usage
- 📦 Node.js Package
- 🤖 Supported Models
- 🔬 Code Scanning Guide
We welcome contributions! Check out our contributing guide to get started.
Join our Discord community for help and discussion.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for promptfoo
Similar Open Source Tools
promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing features like local data storage, multiple LLM provider support, image generation, enhanced prompting, keyboard shortcuts, and more. It offers a user-friendly interface with dark theme, team collaboration, cross-platform availability, web version access, iOS & Android apps, multilingual support, and ongoing feature enhancements. Developed for prompt and API debugging, it has gained popularity for daily chatting and professional role-playing with AI assistance.

orbit
ORBIT (Open Retrieval-Based Inference Toolkit) is a middleware platform that provides a unified API for AI inference. It acts as a central gateway, allowing you to connect various local and remote AI models with your private data sources like SQL databases, vector stores, and local files. ORBIT uses a flexible adapter architecture to connect your data to AI models, creating specialized 'agents' for specific tasks. It supports scenarios like Knowledge Base Q&A and Chat with Your SQL Database, enabling users to interact with AI models seamlessly. The tool offers a RESTful API for programmatic access and includes features like authentication, API key management, system prompts, health monitoring, and file management. ORBIT is designed to streamline AI inference tasks and facilitate interactions between users and AI models.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing a user-friendly interface for AI copilot assistance on Windows, Mac, and Linux. It offers features like local data storage, multiple LLM provider support, image generation with Dall-E-3, enhanced prompting, keyboard shortcuts, and more. Users can collaborate, access the tool on various platforms, and enjoy multilingual support. Chatbox is constantly evolving with new features to enhance the user experience.
strix
Strix is an open-source AI tool designed to help developers and security teams find and fix vulnerabilities in applications. It offers a full hacker toolkit, teams of autonomous AI agents for collaboration, real validation with proof-of-concepts, a developer-first CLI with actionable reports, and auto-fix & reporting features. Strix can be used for application security testing, rapid penetration testing, bug bounty automation, and CI/CD integration. It provides comprehensive vulnerability detection for various security issues and offers advanced multi-agent orchestration for security testing. The tool supports basic and advanced testing scenarios, headless mode for automated jobs, and CI/CD integration with GitHub Actions. Strix also offers configuration options for optimal performance and recommends specific AI models for best results. Full documentation is available at docs.strix.ai, and contributions to the project are welcome.

logto
Logto is a modern, open-source authentication infrastructure designed for SaaS and AI applications. It simplifies OIDC and OAuth 2.1 implementation, enabling secure, production-ready authentication with features like multi-tenancy, enterprise SSO, and RBAC. Logto offers pre-built sign-in flows, customizable UIs, and SDKs for various frameworks, supporting protocols like OIDC, OAuth 2.1, and SAML. It is suitable for teams scaling SaaS, AI, and agent-based platforms without authentication complexities.
bagofwords
Bag of words is an open-source AI platform that helps data teams deploy and manage chat-with-your-data agents in a controlled, reliable, and self-learning environment. It enables users to create charts, tables, and dashboards by chatting with their data, capture AI decisions and user feedback, automatically improve AI quality, integrate with various data sources and APIs, and ensure governance and integrations. The platform supports self-hosting in VPC via VMs, Docker/Compose, or Kubernetes, and offers additional integrations for AI Analyst in Slack, Excel, Google Sheets, and more. Users can start in minutes and scale to org-wide analytics.
LibreChat
LibreChat is an all-in-one AI conversation platform that integrates multiple AI models, including ChatGPT, into a user-friendly interface. It offers a wide range of features, including multimodal chat, multilingual UI, AI model selection, custom presets, conversation branching, message export, search, plugins, multi-user support, and extensive configuration options. LibreChat is open-source and community-driven, with a focus on providing a free and accessible alternative to ChatGPT Plus. It is designed to enhance productivity, creativity, and communication through advanced AI capabilities.
ComfyUI-Copilot
ComfyUI-Copilot is an intelligent assistant built on the Comfy-UI framework that simplifies and enhances the AI algorithm debugging and deployment process through natural language interactions. It offers intuitive node recommendations, workflow building aids, and model querying services to streamline development processes. With features like interactive Q&A bot, natural language node suggestions, smart workflow assistance, and model querying, ComfyUI-Copilot aims to lower the barriers to entry for beginners, boost development efficiency with AI-driven suggestions, and provide real-time assistance for developers.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
talkcody
TalkCody is a free, open-source AI coding agent designed for developers who value speed, cost, control, and privacy. It offers true freedom to use any AI model without vendor lock-in, maximum speed through unique four-level parallelism, and complete privacy as everything runs locally without leaving the user's machine. With professional-grade features like multimodal input support, MCP server compatibility, and a marketplace for agents and skills, TalkCody aims to enhance development productivity and flexibility.

ai-flow
AI Flow is an open-source, user-friendly UI application that empowers you to seamlessly connect multiple AI models together, specifically leveraging the capabilities of multiples AI APIs such as OpenAI, StabilityAI and Replicate. In a nutshell, AI Flow provides a visual platform for crafting and managing AI-driven workflows, thereby facilitating diverse and dynamic AI interactions.
meeting-minutes
An open-source AI assistant for taking meeting notes that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams to focus on discussions while automatically capturing and organizing meeting content without external servers or complex infrastructure. Features include modern UI, real-time audio capture, speaker diarization, local processing for privacy, and more. The tool also offers a Rust-based implementation for better performance and native integration, with features like live transcription, speaker diarization, and a rich text editor for notes. Future plans include database connection for saving meeting minutes, improving summarization quality, and adding download options for meeting transcriptions and summaries. The backend supports multiple LLM providers through a unified interface, with configurations for Anthropic, Groq, and Ollama models. System architecture includes core components like audio capture service, transcription engine, LLM orchestrator, data services, and API layer. Prerequisites for setup include Node.js, Python, FFmpeg, and Rust. Development guidelines emphasize project structure, testing, documentation, type hints, and ESLint configuration. Contributions are welcome under the MIT License.
onyx-foss
Onyx is an open-source AI platform that offers a feature-rich, self-hostable Chat UI with advanced features like custom agents, web search, RAG, connectors to 40+ knowledge sources, deep research, code interpreter, image generation, collaboration tools, and more. It works with various LLMs and self-hosted LLMs, providing users with a versatile and powerful tool for AI-related tasks.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.
For similar tasks
promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
llm-client
LLMClient is a JavaScript/TypeScript library that simplifies working with large language models (LLMs) by providing an easy-to-use interface for building and composing efficient prompts using prompt signatures. These signatures enable the automatic generation of typed prompts, allowing developers to leverage advanced capabilities like reasoning, function calling, RAG, ReAcT, and Chain of Thought. The library supports various LLMs and vector databases, making it a versatile tool for a wide range of applications.
SimplerLLM
SimplerLLM is an open-source Python library that simplifies interactions with Large Language Models (LLMs) for researchers and beginners. It provides a unified interface for different LLM providers, tools for enhancing language model capabilities, and easy development of AI-powered tools and apps. The library offers features like unified LLM interface, generic text loader, RapidAPI connector, SERP integration, prompt template builder, and more. Users can easily set up environment variables, create LLM instances, use tools like SERP, generic text loader, calling RapidAPI APIs, and prompt template builder. Additionally, the library includes chunking functions to split texts into manageable chunks based on different criteria. Future updates will bring more tools, interactions with local LLMs, prompt optimization, response evaluation, GPT Trainer, document chunker, advanced document loader, integration with more providers, Simple RAG with SimplerVectors, integration with vector databases, agent builder, and LLM server.
architext
Architext is a Python library designed for Large Language Model (LLM) applications, focusing on Context Engineering. It provides tools to construct and reorganize input context for LLMs dynamically. The library aims to elevate context construction from ad-hoc to systematic engineering, enabling precise manipulation of context content for AI Agents.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.
For similar jobs
promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
Sanmill
Sanmill is a free, powerful UCI-like N men's morris program with CUI, Flutter GUI and Qt GUI. Nine men's morris is a strategy board game for two players dating at least to the Roman Empire. The game is also known as nine-man morris , mill , mills , the mill game , merels , merrills , merelles , marelles , morelles , and ninepenny marl in English.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.
Efficient-LLMs-Survey
This repository provides a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from **model-centric** , **data-centric** , and **framework-centric** perspective, respectively. We hope our survey and this GitHub repository can serve as valuable resources to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
awesome-gpt-prompt-engineering
Awesome GPT Prompt Engineering is a curated list of resources, tools, and shiny things for GPT prompt engineering. It includes roadmaps, guides, techniques, prompt collections, papers, books, communities, prompt generators, Auto-GPT related tools, prompt injection information, ChatGPT plug-ins, prompt engineering job offers, and AI links directories. The repository aims to provide a comprehensive guide for prompt engineering enthusiasts, covering various aspects of working with GPT models and improving communication with AI tools.