
neptune-client
📘 The experiment tracker for foundation model training
Stars: 574
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.
README:

Neptune is the most scalable experiment tracker for teams that train foundation models.
Log millions of runs, view and compare them all in seconds. Effortlessly monitor and visualize months-long model training with multiple steps and branches.
Deploy Neptune on your infra from day one, track 100% of your metadata and get to the next big AI breakthrough faster.
Watch a 3min explainer video →
Play with a live example project in the Neptune app →
Step 1: Create a free account
Step 2: Install the Neptune client library
pip install neptuneStep 3: Add an experiment tracking snippet to your code
import neptune
run = neptune.init_run(project="workspace-name/project-name")
run["parameters"] = {"lr": 0.1, "dropout": 0.4}
run["test_accuracy"] = 0.84
Log and display
Add a snippet to any step of your ML pipeline once. Decide what and how you want to log. Run a million times.
-
Any framework: any code, fastai, PyTorch, Lightning, TensorFlow/Keras, scikit-learn, 🤗 Transformers, XGBoost, Optuna.
-
Any metadata type: metrics, parameters, dataset and model versions, images, interactive plots, videos, hardware (GPU, CPU, memory), code state.
-
From anywhere in your ML pipeline: multinode pipelines, distributed computing, log during or after execution, log offline, and sync when you are back online.

Organize experiments
Organize logs in a fully customizable nested structure. Display model metadata in user-defined dashboard templates.
-
Nested metadata structure: the flexible API lets you customize the metadata logging structure however you want. Organize nested parameter configs or the results on k-fold validation splits the way they should be.
-
Custom dashboards: combine different metadata types in one view. Define it for one run. Use anywhere. Look at GPU, memory consumption, and load times to debug training speed. See learning curves, image predictions, and confusion matrix to debug model quality.
-
Table views: create different views of the runs table and save them for later. You can have separate table views for debugging, comparing parameter sets, or best experiments.

Compare results
Visualize training live in the neptune.ai web app. See how different parameters and configs affect the results. Optimize models quicker.
-
Compare: learning curves, parameters, images, datasets.
-
Search, sort, and filter: experiments by any field you logged. Use our query language to filter runs based on parameter values, metrics, execution times, or anything else.
-
Visualize and display: runs table, interactive display, folder structure, dashboards.
-
Monitor live: hardware consumption metrics, GPU, CPU, memory.
-
Group by: dataset versions, parameters.

Version models
Version, review, and access production-ready models and metadata associated with them in a single place.
-
Version models: track model versions and external artifacts.
-
Review and change stages: look at the validation, test metrics and other model metadata.
-
Access and share models: all the tracked model metadata is accessible via the neptune.ai web app or through the API.
Share results
Have a single place where your team can see the results and access all models and experiments.
-
Send a link: share every chart, dashboard, table view, or anything else you see in the neptune.ai app by copying and sending persistent URLs.
-
Query API: access all model metadata via neptune.ai API. Whatever you logged, you can query in a similar way.
-
Manage users and projects: create different projects, add users to them, and grant different permissions levels.
-
Add your entire org: you can collaborate with a team on every plan, even the Free one. So, invite your entire organization, including product managers and subject matter experts, to increase the visibility from the very beginning.

neptune.ai integrates with 25+ frameworks: PyTorch, Lightning, TensorFlow/Keras, LightGBM, scikit-learn, XGBoost, Optuna, Kedro, 🤗 Transformers, fastai, Prophet, detectron2, Airflow, and more.
Example:
from pytorch_lightning import Trainer
from lightning.pytorch.loggers import NeptuneLogger
# Create NeptuneLogger instance
from neptune import ANONYMOUS_API_TOKEN
neptune_logger = NeptuneLogger(
api_key=ANONYMOUS_API_TOKEN,
project="common/pytorch-lightning-integration",
tags=["training", "resnet"], # optional
)
# Pass the logger to the Trainer
trainer = Trainer(max_epochs=10, logger=neptune_logger)
# Run the Trainer
trainer.fit(my_model, my_dataloader)

Read how various customers use Neptune to improve their workflow.
If you get stuck or simply want to talk to us about something, here are your options:
- Check our FAQ page.
- Take a look at our resource center.
- Chat! In the app, click the blue message icon in the bottom-right corner and send a message. A real person will talk to you ASAP (typically very ASAP).
- You can just shoot us an email at [email protected].
Created with ❤️ by the neptune.ai team
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for neptune-client
Similar Open Source Tools
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
eca
ECA (Editor Code Assistant) is a free and open-source editor-agnostic tool designed to link Language Model Machines (LLMs) with editors for AI pair programming. It provides a protocol for any editor to integrate, offering a seamless user experience. The tool allows for single configuration across different editors, features a chat interface for collaboration, supports multiple LLM models, and enhances code editing with context details. ECA aims to simplify the integration of LLMs with editors, focusing on improving the user experience and productivity in coding tasks.
inngest
Inngest is a platform that offers durable functions to replace queues, state management, and scheduling for developers. It allows writing reliable step functions faster without dealing with infrastructure. Developers can create durable functions using various language SDKs, run a local development server, deploy functions to their infrastructure, sync functions with the Inngest Platform, and securely trigger functions via HTTPS. Inngest Functions support retrying, scheduling, and coordinating operations through triggers, flow control, and steps, enabling developers to build reliable workflows with robust support for various operations.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.
llm-guard
LLM Guard is a comprehensive tool designed to fortify the security of Large Language Models (LLMs). It offers sanitization, detection of harmful language, prevention of data leakage, and resistance against prompt injection attacks, ensuring that your interactions with LLMs remain safe and secure.
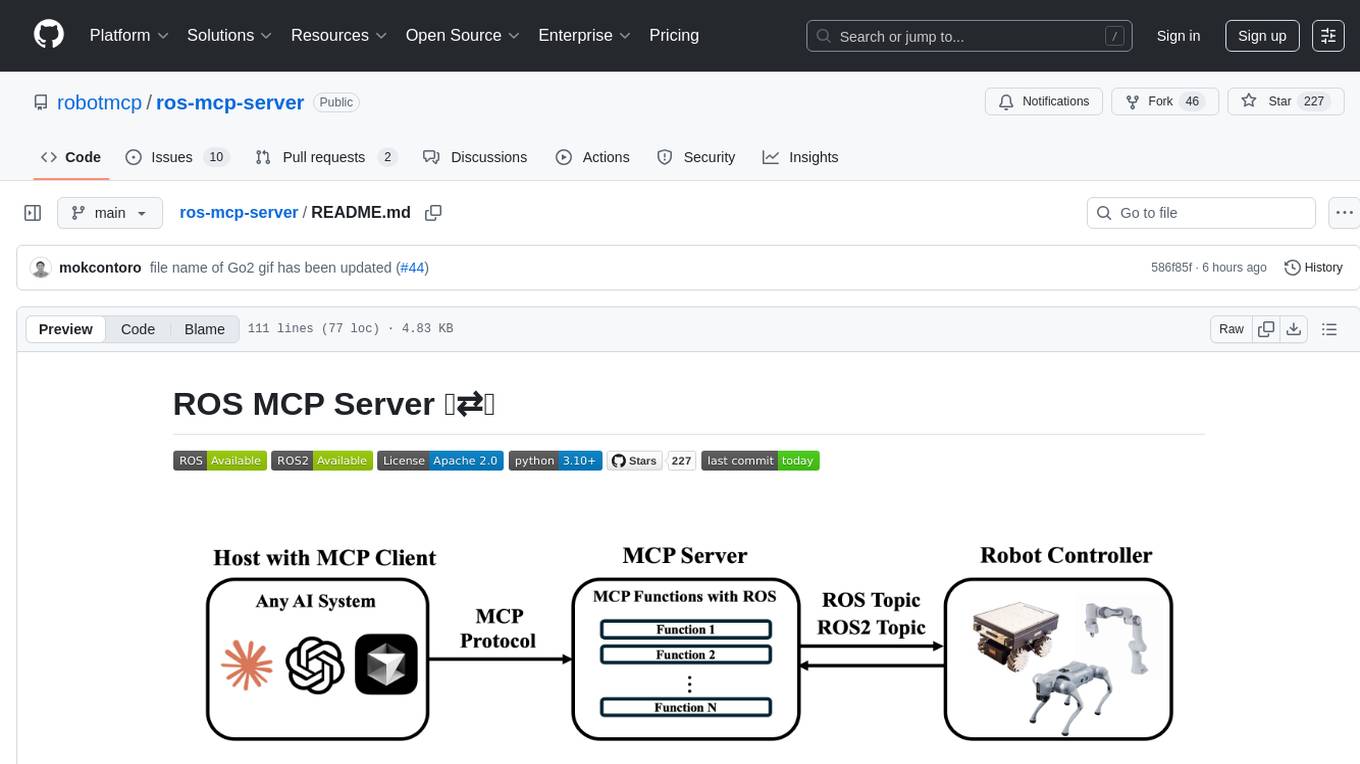
ros-mcp-server
The ros-mcp-server repository contains a ROS (Robot Operating System) package that provides a server for Multi-Contact Planning (MCP) in robotics. The server facilitates the planning of multiple contacts between a robot and its environment, enabling complex manipulation tasks. It includes functionalities for collision checking, motion planning, and contact stability analysis. This tool is designed to enhance the capabilities of robotic systems by enabling them to perform tasks that involve multiple points of contact with the environment. The repository includes documentation and examples to help users integrate the MCP server into their robotic applications.
agent-zero
Agent Zero is a personal and organic AI framework designed to be dynamic, organically growing, and learning as you use it. It is fully transparent, readable, comprehensible, customizable, and interactive. The framework uses the computer as a tool to accomplish tasks, with no single-purpose tools pre-programmed. It emphasizes multi-agent cooperation, complete customization, and extensibility. Communication is key in this framework, allowing users to give proper system prompts and instructions to achieve desired outcomes. Agent Zero is capable of dangerous actions and should be run in an isolated environment. The framework is prompt-based, highly customizable, and requires a specific environment to run effectively.
nexent
Nexent is a powerful tool for analyzing and visualizing network traffic data. It provides comprehensive insights into network behavior, helping users to identify patterns, anomalies, and potential security threats. With its user-friendly interface and advanced features, Nexent is suitable for network administrators, cybersecurity professionals, and anyone looking to gain a deeper understanding of their network infrastructure.

kestra
Kestra is an open-source event-driven orchestration platform that simplifies building scheduled and event-driven workflows. It offers Infrastructure as Code best practices for data, process, and microservice orchestration, allowing users to create reliable workflows using YAML configuration. Key features include everything as code with Git integration, event-driven and scheduled workflows, rich plugin ecosystem for data extraction and script running, intuitive UI with syntax highlighting, scalability for millions of workflows, version control friendly, and various features for structure and resilience. Kestra ensures declarative orchestration logic management even when workflows are modified via UI, API calls, or other methods.
trigger.dev
Trigger.dev is an open source platform and SDK for creating long-running background jobs. It provides features like JavaScript and TypeScript SDK, no timeouts, retries, queues, schedules, observability, React hooks, Realtime API, custom alerts, elastic scaling, and works with existing tech stack. Users can create tasks in their codebase, deploy tasks using the SDK, manage tasks in different environments, and have full visibility of job runs. The platform offers a trace view of every task run for detailed monitoring. Getting started is easy with account creation, project setup, and onboarding instructions. Self-hosting and development guides are available for users interested in contributing or hosting Trigger.dev.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.
rocketnotes
Rocketnotes is a web-based Markdown note taking app with LLM-powered text completion, chat and semantic search. It utilizes a 100% serverless RAG pipeline build with langchain, sentence-transformers, faiss and OpenAI or Anthropic API.
gemini-android
Gemini Android is a repository showcasing Google's Generative AI on Android using Stream Chat SDK for Compose. It demonstrates the Gemini API for Android, implements UI elements with Jetpack Compose, utilizes Android architecture components like Hilt and AppStartup, performs background tasks with Kotlin Coroutines, and integrates chat systems with Stream Chat Compose SDK for real-time event handling. The project also provides technical content, instructions on building the project, tech stack details, architecture overview, modularization strategies, and a contribution guideline. It follows Google's official architecture guidance and offers a real-world example of app architecture implementation.
voltagent
VoltAgent is an open-source TypeScript framework designed for building and orchestrating AI agents. It simplifies the development of AI agent applications by providing modular building blocks, standardized patterns, and abstractions. Whether you're creating chatbots, virtual assistants, automated workflows, or complex multi-agent systems, VoltAgent handles the underlying complexity, allowing developers to focus on defining their agents' capabilities and logic. The framework offers ready-made building blocks, such as the Core Engine, Multi-Agent Systems, Workflow Engine, Extensible Packages, Tooling & Integrations, Data Retrieval & RAG, Memory management, LLM Compatibility, and a Developer Ecosystem. VoltAgent empowers developers to build sophisticated AI applications faster and more reliably, avoiding repetitive setup and the limitations of simpler tools.
For similar tasks
SwanLab
SwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and collaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times. It offers a friendly API and a beautiful interface, combining hyperparameter tracking, metric recording, online collaboration, experiment link sharing, real-time message notifications, and more. With SwanLab, researchers can document their training experiences, seamlessly communicate and collaborate with collaborators, and machine learning engineers can develop models for production faster.
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

aisuite
Aisuite is a simple, unified interface to multiple Generative AI providers. It allows developers to easily interact with various Language Model (LLM) providers like OpenAI, Anthropic, Azure, Google, AWS, and more through a standardized interface. The library focuses on chat completions and provides a thin wrapper around python client libraries, enabling creators to test responses from different LLM providers without changing their code. Aisuite maximizes stability by using HTTP endpoints or SDKs for making calls to the providers. Users can install the base package or specific provider packages, set up API keys, and utilize the library to generate chat completion responses from different models.
AI-Shortcuts
AI Shortcuts is a browser extension designed to enhance the efficiency of using AI websites. It allows users to quickly send messages, open frequently used AI sites, compare generation results from multiple sites, and access AI content without the need for registration or membership. Users can configure their most frequently used AI sites and easily query selected text on webpages. The extension also features a tab mode for comparing results across multiple AI sites.
simple-llm-eval
Simpleval is a Python package for evaluating Large Language Models (LLMs) using the 'LLM as a Judge' technique. It supports various LLM providers such as OpenAI, Google, AWS, Anthropic, Azure, and more. The package includes reports for analyzing and summarizing evaluation results.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.
Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.