
SwanLab
⚡️SwanLab - an open-source, modern-design AI training tracking and visualization tool. Supports Cloud / Self-hosted use. Integrated with PyTorch / Transformers / verl / LLaMA Factory / ms-swift / Ultralytics / MMEngine / Keras etc.
Stars: 3571
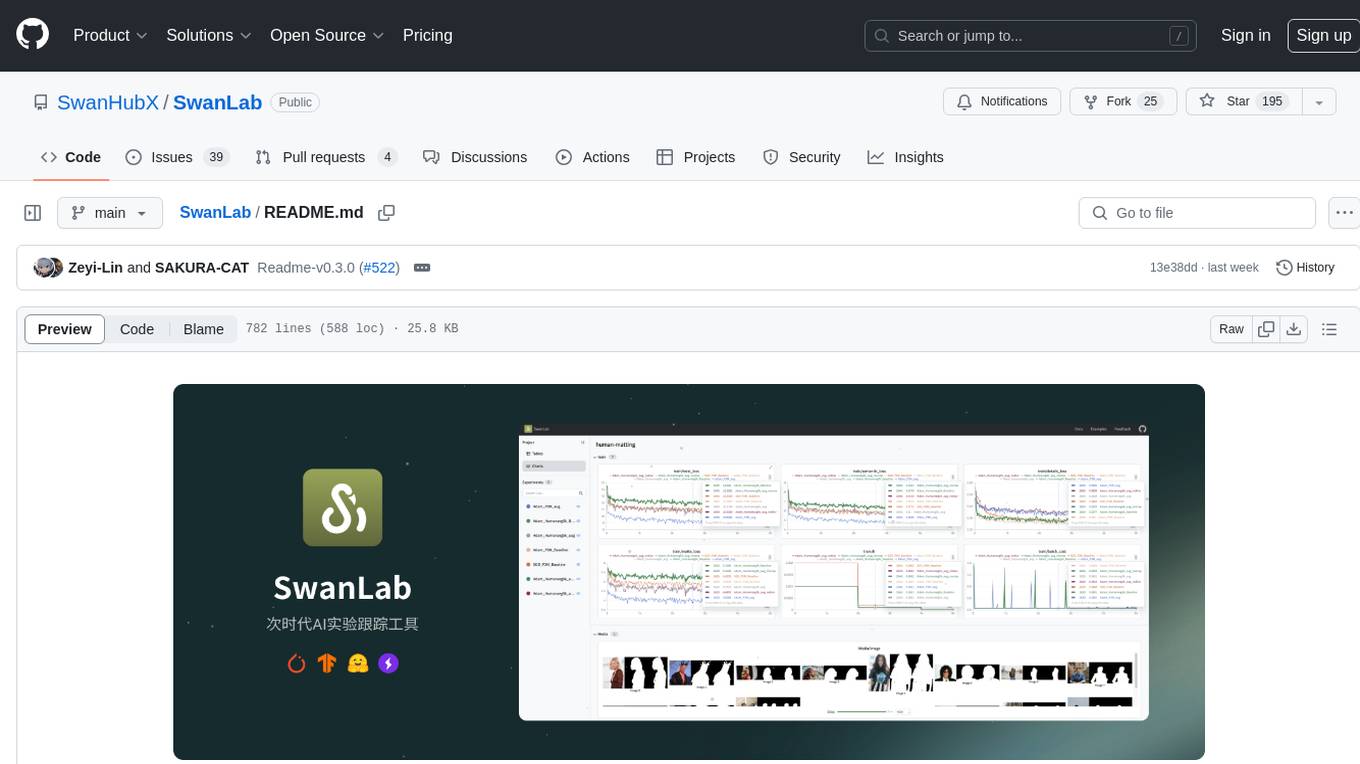
SwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and collaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times. It offers a friendly API and a beautiful interface, combining hyperparameter tracking, metric recording, online collaboration, experiment link sharing, real-time message notifications, and more. With SwanLab, researchers can document their training experiences, seamlessly communicate and collaborate with collaborators, and machine learning engineers can develop models for production faster.
README:
一个专业、现代化设计的AI训练分析平台
面向模型训练团队,与50+主流框架集成,与你的实验代码轻松结合
🔥SwanLab 在线版 · 📃 文档 · 报告问题 · 建议反馈 · 更新日志 · ![]() 基线社区
基线社区









👋 加入我们的微信群

-
2026.02.06: 🔥swanlab.Api已正式上线,提供更强大的、面向对象式的开放API接口,文档;ECharts.Table支持CSV下载;现在支持将图表一键置于分组首位了;
-
2026.01.28:⚡️LightningBoard V2上线,进一步提升仪表盘性能;
-
2026.01.16:⚡️LightningBoard(闪电看板)V1 现已上线,专为超大图表数量级场景打造;新增图表嵌入链接,现在可以把你的图表嵌入到在线文档当中(如Notion、飞书云文档等);
-
2026.01.02:🥳 新增对AMD ROCm与天数智芯Iluvatar GPU的硬件监控支持;SDK增加心跳包特性,实现更稳健的端云连接;
-
2025.12.15:🎉SwanLab Kubernetes版 现已发布!部署文档;NVIDIA NeMo RL 框架已集成SwanLab,文档;
-
2025.12.01:🕰 新增折线图详细信息展示,鼠标悬浮在折线图上时,单击Shift将开启详细模式,支持显示当前log点的时间;📊 图表分组支持MIN/MAX区域范围显示;
-
2025.11.17:📊全局图表配置增加X轴数据源选择、悬停模式功能,增加图表分析体验;增加
SWANLAB_WEBHOOK功能;文档 -
2025.11.06:🔪实验分组上线,支持对大批量实验进行分组管理;工作区页面升级,支持快捷在多个组织下切换;大幅优化了折线图的渲染性能;swanlab.init上线
group与job_type参数; -
2025.10.15:📊折线图配置支持X轴数据源选择;侧边栏支持显示表格视图中Pin的列,增强实验数据对齐能力;
完整更新日志
-
2025.09.22:📊全新UI上线;表格视图支持全局排序和筛选;数据层面统一表格视图与图表视图;
-
2025.09.12:🔢支持创建标量图,灵活显示实验指标的统计值;组织管理页面大升级,提供更强大的权限控制与项目管理能力;
-
2025.08.19:🤔更强大的图表渲染性能与低侵入式加载动画,让研究者更聚焦于实验分析本身;集成优秀的MLX-LM、SpecForge框架,提供更多场景的训练体验;
-
2025.08.06:👥训练轻协作上线,支持邀请项目协作者,分享项目链接与二维码;工作区支持列表视图,支持显示项目Tags;
-
2025.07.29:🚀侧边栏支持实验筛选、排序;📊表格视图上线列控制面板,能够方便地实现列的隐藏与显示;🔐多API Key管理上线,让你的数据更安全;swanlab sync提高了对日志文件完整性的兼容,适配训练崩溃等场景;新图表-PR曲线、ROC曲线、混淆矩阵上线,文档;
-
2025.07.17:📊更强大的折线图配置,支持灵活配置线型、颜色、粗细、网格、图例位置等;📹支持swanlab.Video数据类型,支持记录与可视化GIF格式文件;全局图表仪表盘支持配置Y轴与最大显示实验数;
-
2025.07.10:📚更强大的文本视图,支持Markdown渲染与方向键切换,可由
swanlab.echarts.table与swanlab.Text创建,Demo -
2025.07.06:🚄支持resume断点续训;新插件文件记录器;集成ray框架,文档;集成ROLL框架,感谢@PanAndy,文档
-
2025.06.27:📊支持小折线图局部放大;支持配置单个折线图平滑;大幅改进了图像图表放大后的交互效果;
-
2025.06.20:🤗集成accelerate框架,PR,文档,增强分布式训练中的实验记录体验;
-
2025.06.18:🐜集成AREAL框架,感谢@xichengpro,PR,文档;🖱支持鼠标Hover到侧边栏实验时,高亮相应曲线;支持跨组对比折线图;支持设置实验名裁剪规则;
-
2025.06.11:📊支持 swanlab.echarts.table 数据类型,支持纯文本图表展示;支持对分组进行拉伸交互,以增大同时显示的图表数量;表格视图增加 指标最大/最小值 选项;
-
2025.06.08:♻️支持在本地存储完整的实验日志文件,通过 swanlab sync 上传本地日志文件到云端/私有化部署端;硬件监控支持海光DCU;
-
2025.06.01:🏸支持图表自由拖拽;支持ECharts自定义图表,增加包括柱状图、饼状图、直方图在内的20+图表类型;硬件监控支持沐曦GPU;集成 PaddleNLP 框架;
-
2025.05.25:日志支持记录标准错误流,PyTorch Lightning等框架的打印信息可以被更好地记录;硬件监控支持摩尔线程;新增运行命令记录安全防护功能,API Key将被自动隐藏;
-
2025.05.14:支持实验Tag;支持折线图Log Scale;支持分组拖拽;大幅度优化了大量指标上传的体验;增加
swanlab.OpenApi开放接口; -
2025.05.09:支持折线图创建;配置图表功能增加数据源选择功能,支持单张图表显示不同的指标;支持生成训练项目GitHub徽章;
-
2025.04.23:支持折线图编辑,支持自由配置图表的X、Y轴数据范围和标题样式;图表搜索支持正则表达式;支持昆仑芯XPU的硬件检测与监控;
-
2025.04.11:支持折线图局部区域选取;支持全局选择仪表盘折线图的step范围;支持一键隐藏全部图表;
-
2025.04.08:支持swanlab.Molecule数据类型,支持记录与可视化生物化学分子数据;支持保存表格视图中的排序、筛选、列顺序变化状态;
-
2025.04.07:我们与 EvalScope 完成了联合集成,现在你可以在EvalScope中使用SwanLab来评估大模型性能;
-
2025.03.30:支持swanlab.Settings方法,支持更精细化的实验行为控制;支持寒武纪MLU硬件监控;支持 Slack通知、Discord通知;
-
2025.03.21:🎉🤗HuggingFace Transformers已正式集成SwanLab(>=4.50.0版本),#36433;新增 Object3D图表 ,支持记录与可视化三维点云,文档;硬件监控支持了 GPU显存(MB)、磁盘利用率、网络上下行 的记录;
-
2025.03.12:🎉🎉SwanLab私有化部署版现已发布!!🔗部署文档;SwanLab 已支持插件扩展,如 邮件通知、飞书通知
-
2025.03.09:支持实验侧边栏拉宽;新增外显 Git代码 按钮;新增 sync_mlflow 功能,支持与mlflow框架同步实验跟踪;
-
2025.03.06:我们与 DiffSynth Studio 完成了联合集成,现在你可以在DiffSynth Studio中使用SwanLab来跟踪和可视化Diffusion模型文生图/视频实验,使用指引;
-
2025.03.04:新增 MLFlow转换 功能,支持将MLFlow实验转换为SwanLab实验,使用指引;
-
2025.03.01:新增 移动实验 功能,现在可以将实验移动到不同组织的不同项目下了;
-
2025.02.24:我们与 EasyR1 完成了联合集成,现在你可以在EasyR1中使用SwanLab来跟踪和可视化多模态大模型强化学习实验,使用指引
-
2025.02.18:我们与 Swift 完成了联合集成,现在你可以在Swift的CLI/WebUI中使用SwanLab来跟踪和可视化大模型微调实验,使用指引。
-
2025.02.16:新增 图表移动分组、创建分组 功能。
-
2025.02.09:我们与 veRL 完成了联合集成,现在你可以在veRL中使用SwanLab来跟踪和可视化大模型强化学习实验,使用指引。
-
2025.02.05:
swanlab.log支持嵌套字典 #812,适配Jax框架特性;支持name与notes参数; -
2025.01.22:新增
sync_tensorboardX与sync_tensorboard_torch功能,支持与此两种TensorBoard框架同步实验跟踪; -
2025.01.17:新增
sync_wandb功能,文档,支持与Weights & Biases实验跟踪同步;大幅改进了日志渲染性能 -
2025.01.11:云端版大幅优化了项目表格的性能,并支持拖拽、排序、筛选等交互
-
2025.01.01:新增折线图持久化平滑、折线图拖拽式改变大小,优化图表浏览体验
-
2024.12.22:我们与 LLaMA Factory 完成了联合集成,现在你可以在LLaMA Factory中使用SwanLab来跟踪和可视化大模型微调实验,使用指引。
-
2024.12.15:硬件监控(0.4.0) 功能上线,支持CPU、NPU(Ascend)、GPU(Nvidia)的系统级信息记录与监控。
-
2024.11.26:环境选项卡-硬件部分支持识别华为昇腾NPU与鲲鹏CPU;云厂商部分支持识别青云基石智算。
SwanLab 是一款AI训练分析与指标观测平台,面向模型训练团队,提供训练可视化、自动日志记录、超参数记录、实验对比、多人协同等功能,帮助团队快速发现训练问题,加速模型迭代。
在SwanLab上,研究者能基于直观的可视化图表发现训练问题,对比多个实验找到研究灵感,并通过在线网页的分享与基于组织的多人协同训练,打破团队沟通的壁垒,提高组织训练效率。
https://github.com/user-attachments/assets/7965fec4-c8b0-4956-803d-dbf177b44f54
以下是其核心特性列表:
1. 📊 实验指标与超参数跟踪: 极简的代码嵌入您的机器学习 pipeline,跟踪记录训练关键指标
-
☁️ 支持云端使用(类似Weights & Biases),随时随地查看训练进展。手机看实验的方法
-
📝 支持超参数记录、指标总结、表格分析
-
🌸 可视化训练过程: 通过UI界面对实验跟踪数据进行可视化,可以让训练师直观地看到实验每一步的结果,分析指标走势,判断哪些变化导致了模型效果的提升,从而整体性地提升模型迭代效率。
-
支持的元数据类型:标量指标、图像、音频、文本、视频、3D点云、生物化学分子、Echarts自定义图表...

- 支持的图表类型:折线图、媒体图(图像、音频、文本、视频)、3D点云、生物化学分子、柱状图、散点图、箱线图、热力图、饼状图、雷达图、自定义图表...

- LLM生成内容可视化组件:为大语言模型训练场景打造的文本内容可视化图表,支持Markdown渲染

-
后台自动记录:日志logging、硬件环境、Git 仓库、Python 环境、Python 库列表、项目运行目录
-
断点续训记录:支持在训练完成/中断后,补充新的指标数据到同个实验中
2. ⚡️ 全面的框架集成: PyTorch、🤗HuggingFace Transformers、PyTorch Lightning、🦙LLaMA Factory、MMDetection、Ultralytics、PaddleDetetion、LightGBM、XGBoost、Keras、Tensorboard、Weights&Biases、OpenAI、Swift、XTuner、Stable Baseline3、Hydra 在内的 30+ 框架

3. 💻 硬件监控: 支持实时记录与监控CPU、NPU(昇腾Ascend)、GPU(英伟达Nvidia)、AMD(AMD ROCm)、MLU(寒武纪Cambricon)、XLU(昆仑芯Kunlunxin)、DCU(海光DCU)、MetaX GPU(沐曦XPU)、Moore Threads GPU(摩尔线程)、Iluvatar GPU(天数智芯)、内存的系统级硬件指标
4. 📦 实验管理: 通过专为训练场景设计的集中式仪表板,通过整体视图速览全局,快速管理多个项目与实验
5. 🆚 比较结果: 通过在线表格与对比图表比较不同实验的超参数和结果,挖掘迭代灵感

6. 👥 在线协作: 您可以与团队进行协作式训练,支持将实验实时同步在一个项目下,您可以在线查看团队的训练记录,基于结果发表看法与建议
7. ✉️ 分享结果: 复制和发送持久的 URL 来共享每个实验,方便地发送给伙伴,或嵌入到在线笔记中
8. 💻 支持自托管: 支持离线环境使用,自托管的社区版同样可以查看仪表盘与管理实验,使用攻略
9. 🔌 插件拓展: 支持通过插件拓展SwanLab的使用场景,比如 飞书通知、Slack通知、CSV记录器等
[!IMPORTANT]
收藏项目,你将从 GitHub 上无延迟地接收所有发布通知~ ⭐️

来看看 SwanLab 的在线演示:
| ResNet50 猫狗分类 | Yolov8-COCO128 目标检测 |
|---|---|
 |
 |
| 跟踪一个简单的 ResNet50 模型在猫狗数据集上训练的图像分类任务。 | 使用 Yolov8 在 COCO128 数据集上进行目标检测任务,跟踪训练超参数和指标。 |
| Qwen2 指令微调 | LSTM Google 股票预测 |
|---|---|
 |
 |
| 跟踪 Qwen2 大语言模型的指令微调训练,完成简单的指令遵循。 | 使用简单的 LSTM 模型在 Google 股价数据集上训练,实现对未来股价的预测。 |
| ResNeXt101 音频分类 | Qwen2-VL COCO数据集微调 |
|---|---|
 |
 |
| 从ResNet到ResNeXt在音频分类任务上的渐进式实验过程 | 基于Qwen2-VL多模态大模型,在COCO2014数据集上进行Lora微调。 |
| EasyR1 多模态LLM RL训练 | Qwen2.5-0.5B GRPO训练 |
|---|---|
 |
 |
| 使用EasyR1框架进行多模态LLM RL训练 | 基于Qwen2.5-0.5B模型在GSM8k数据集上进行GRPO训练 |
pip install swanlab源码安装
如果你想体验最新的特性,可以使用源码安装。
# 方式一
git clone https://github.com/SwanHubX/SwanLab.git
pip install -e .
# 方式二
pip install git+https://github.com/SwanHubX/SwanLab.gitswanlab login出现提示时,输入您的 API Key,按下回车,完成登陆。
import swanlab
# 初始化一个新的swanlab实验
swanlab.init(
project="my-first-ml",
config={'learning-rate': 0.003},
)
# 记录指标
for i in range(10):
swanlab.log({"loss": i, "acc": i})大功告成!前往SwanLab查看你的第一个 SwanLab 实验。
自托管社区版支持离线查看 SwanLab 仪表盘。

详细部署文档见:
使用SwanLab的优秀教程开源项目:
-
happy-llm:从零开始的大语言模型原理与实践教程
-
self-llm:《开源大模型食用指南》针对中国宝宝量身打造的基于Linux环境快速微调(全参数/Lora)、部署国内外开源大模型(LLM)/多模态大模型(MLLM)教程
-
Minimind:🚀🚀 「大模型」2小时完全从0训练26M的小参数GPT!
-
unlock-deepseek:DeepSeek 系列工作解读、扩展和复现
-
Qwen3-SmVL: 将SmolVLM2的视觉头与Qwen3-0.6B模型进行了拼接微调
-
OPPO/Agent_Foundation_Models: 通过多Agent蒸馏和Agent RL的端到端Agent基础模型。






使用SwanLab的优秀论文:
- MolAct: An Agentic RL Framework for Molecular Editing and Property Optimization
- CQLLM: A Framework for Generating CodeQL Security Vulnerability Detection Code Based on Large Language Model
- Animation Needs Attention: A Holistic Approach to Slides Animation Comprehension with Visual-Language Models
- Efficient Model Fine-Tuning with LoRA for Biomedical Named Entity Recognition
- SpectrumWorld: Artificial Intelligence Foundation for Spectroscopy
- CodeBoost: Boosting Code LLMs by Squeezing Knowledge from Code Snippets with RL
- A Joint Classification Method for Traditional Chinese Medicine Diseases and Syndromes Based on BertChinese-RCNNATTN
教程文章:
- MNIST手写体识别
- FashionMNIST服装分类
- Cifar10图像分类
- Resnet猫狗分类
- Yolo目标检测
- UNet医学影像分割
- 音频分类
- DQN强化学习-推车倒立摆
- LSTM Google股票预测
- BERT文本分类
- Stable Diffusion文生图微调
- LLM预训练
- GLM4指令微调
- Qwen下游任务训练
- NER命名实体识别
- Qwen3医学模型微调
- Qwen2-VL多模态大模型微调实战
- GRPO大模型强化学习
- Qwen3-SmVL-0.6B多模态模型训练
- LeRobot 具身智能入门
- GLM-4.5-Air-LoRA 及 SwanLab 可视化记录
- RAG怎么做?SwanLab文档助手方案开源了
🌟如果你有想收录的教程,欢迎提交PR!
SwanLab会对AI训练过程中所使用的硬件信息和资源使用情况进行记录,下面是支持情况表格:
| 硬件 | 信息记录 | 资源监控 | 脚本 |
|---|---|---|---|
| 英伟达GPU | ✅ | ✅ | nvidia.py |
| AMD ROCm | ✅ | ✅ | amd.py |
| 昇腾NPU | ✅ | ✅ | ascend.py |
| 苹果SOC | ✅ | ✅ | apple.py |
| 寒武纪MLU | ✅ | ✅ | cambricon.py |
| 昆仑芯XPU | ✅ | ✅ | kunlunxin.py |
| 摩尔线程GPU | ✅ | ✅ | moorethreads.py |
| 沐曦GPU | ✅ | ✅ | metax.py |
| 天数智芯GPU | ✅ | ✅ | iluvatar.py |
| 海光DCU | ✅ | ✅ | hygon.py |
| CPU | ✅ | ✅ | cpu.py |
| 内存 | ✅ | ✅ | memory.py |
| 硬盘 | ✅ | ✅ | disk.py |
| 网络 | ✅ | ✅ | network.py |
如果你希望记录其他硬件,欢迎提交Issue与PR!
将你最喜欢的框架与 SwanLab 结合使用!
下面是我们已集成的框架列表,欢迎提交 Issue 来反馈你想要集成的框架。
基础框架
LLM训练框架
- HuggingFace Transformers
- LLaMA Factory
- MS-Swift
- Unsloth
- MLX-LM
- Torchtune
- PaddleNLP
- Sentence Transformers
- XTuner
- OpenMind
LLM强化学习框架
机器人框架
文生图/视频训练框架
深度学习框架
计算机视觉
机器学习框架
评估框架
传统强化学习框架
其他框架:
- Tensorboard
- Weights&Biases
- MLFlow
- HuggingFace Accelerate
- Ray
- Hydra
- Omegaconf
- OpenAI
- ZhipuAI
- SpecForge
欢迎通过插件来拓展SwanLab的功能,增强你的实验管理体验!
开放接口:
-
☁️ 支持在线使用: 通过 SwanLab 可以方便地将训练实验在云端在线同步与保存,便于远程查看训练进展、管理历史项目、分享实验链接、发送实时消息通知、多端看实验等。而 Tensorboard 是一个离线的实验跟踪工具。
-
👥 多人协作: 在进行多人、跨团队的机器学习协作时,通过 SwanLab 可以轻松管理多人的训练项目、分享实验链接、跨空间交流讨论。而 Tensorboard 主要为个人设计,难以进行多人协作和分享实验。
-
💻 持久、集中的仪表板: 无论你在何处训练模型,无论是在本地计算机上、在实验室集群还是在公有云的 GPU 实例中,你的结果都会记录到同一个集中式仪表板中。而使用 TensorBoard 需要花费时间从不同的机器复制和管理 TFEvent 文件。
-
💪 更强大的表格: 通过 SwanLab 表格可以查看、搜索、过滤来自不同实验的结果,可以轻松查看数千个模型版本并找到适合不同任务的最佳性能模型。 TensorBoard 不适用于大型项目。
-
Weights and Biases 是一个必须联网使用的闭源 MLOps 平台
-
SwanLab 不仅支持联网使用,也支持开源、免费、自托管的版本
- self-hosted:私有化部署脚本仓库
- SwanLab-Docs:官方文档仓库
-
SwanLab-Dashboard:离线看板仓库,存放了由
swanlab watch打开的轻量离线看板的web代码
- GitHub Issues:使用 SwanLab 时遇到的错误和问题
- 电子邮件支持:反馈关于使用 SwanLab 的问题
- 微信交流群:交流使用 SwanLab 的问题、分享最新的 AI 技术
如果你喜欢在工作中使用 SwanLab,请将 SwanLab 徽章添加到你的 README 中:
、
[](your experiment url)
[](your experiment url)
更多设计素材:assets
如果您发现 SwanLab 对您的研究之旅有帮助,请考虑以下列格式引用:
@software{Zeyilin_SwanLab_2023,
author = {Zeyi Lin, Shaohong Chen, Kang Li, Qiushan Jiang, Zirui Cai, Kaifang Ji and {The SwanLab team}},
doi = {10.5281/zenodo.11100550},
license = {Apache-2.0},
title = {{SwanLab}},
url = {https://github.com/swanhubx/swanlab},
year = {2023}
}考虑为 SwanLab 做出贡献吗?首先,请花点时间阅读 贡献指南。
同时,我们非常欢迎通过社交媒体、活动和会议的分享来支持 SwanLab,衷心感谢!
Contributors

本仓库遵循 Apache 2.0 License 开源协议
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SwanLab
Similar Open Source Tools
SwanLab
SwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and collaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times. It offers a friendly API and a beautiful interface, combining hyperparameter tracking, metric recording, online collaboration, experiment link sharing, real-time message notifications, and more. With SwanLab, researchers can document their training experiences, seamlessly communicate and collaborate with collaborators, and machine learning engineers can develop models for production faster.
99AI
99AI is a commercializable AI web application based on NineAI 2.4.2 (no authorization, no backdoors, no piracy, integrated front-end and back-end integration packages, supports Docker rapid deployment). The uncompiled source code is temporarily closed. Compared with the stable version, the development version is faster.
Awesome-Chinese-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, ,'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in less than 3 words,Verb + noun form,in daily spoken language,in lowercase letters).Answer in english languagesname:Awesome-Chinese-LLM readme:# Awesome Chinese LLM   An Awesome Collection for LLM in Chinese 收集和梳理中文LLM相关    自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮自然语言处理领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个! 如果本项目能给您带来一点点帮助,麻烦点个⭐️吧~ 同时也欢迎大家贡献本项目未收录的开源模型、应用、数据集等。提供新的仓库信息请发起PR,并按照本项目的格式提供仓库链接、star数,简介等相关信息,感谢~
LLMs-from-scratch-CN
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.
torch-rechub
Torch-RecHub is a lightweight, efficient, and user-friendly PyTorch recommendation system framework. It provides easy-to-use solutions for industrial-level recommendation systems, with features such as generative recommendation models, modular design for adding new models and datasets, PyTorch-based implementation for GPU acceleration, a rich library of 30+ classic and cutting-edge recommendation algorithms, standardized data loading, training, and evaluation processes, easy configuration through files or command-line parameters, reproducibility of experimental results, ONNX model export for production deployment, cross-engine data processing with PySpark support, and experiment visualization and tracking with integrated tools like WandB, SwanLab, and TensorBoardX.
KubeDoor
KubeDoor is a microservice resource management platform developed using Python and Vue, based on K8S admission control mechanism. It supports unified remote storage, monitoring, alerting, notification, and display for multiple K8S clusters. The platform focuses on resource analysis and control during daily peak hours of microservices, ensuring consistency between resource request rate and actual usage rate.
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.

omnia
Omnia is a deployment tool designed to turn servers with RPM-based Linux images into functioning Slurm/Kubernetes clusters. It provides an Ansible playbook-based deployment for Slurm and Kubernetes on servers running an RPM-based Linux OS. The tool simplifies the process of setting up and managing clusters, making it easier for users to deploy and maintain their infrastructure.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
kirara-ai
Kirara AI is a chatbot that supports mainstream large language models and chat platforms. It provides features such as image sending, keyword-triggered replies, multi-account support, personality settings, and support for various chat platforms like QQ, Telegram, Discord, and WeChat. The tool also supports HTTP server for Web API, popular large models like OpenAI and DeepSeek, plugin mechanism, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, custom workflows, web management interface, and built-in Frpc intranet penetration.
PromptHub
PromptHub is a versatile tool for generating prompts and ideas to spark creativity and overcome writer's block. It provides a wide range of customizable prompts and exercises to inspire writers, artists, educators, and anyone looking to enhance their creative thinking. With PromptHub, users can access a diverse collection of prompts across various categories such as writing, drawing, brainstorming, and more. The tool offers a user-friendly interface and allows users to save and share their favorite prompts for future reference. Whether you're a professional writer seeking inspiration or a student looking to boost your creativity, PromptHub is the perfect companion to ignite your imagination and enhance your creative process.
easyaiot
EasyAIoT is an AI cloud platform designed to support camera integration, annotation, training, inference, data collection, analysis, alerts, recording, storage, and deployment. It aims to provide a zero-threshold AI experience for everyone, with a focus on cameras below a hundred levels. The platform consists of five core projects: WEB module for frontend management, DEVICE module for device management, VIDEO module for video processing, AI module for AI analysis, and TASK module for high-performance task execution. EasyAIoT combines Java, Python, and C++ to create a versatile and user-friendly AIoT platform.
Unity-Skills
UnitySkills is an AI-driven Unity editor automation engine based on REST API. It allows AI to directly control Unity scenes through Skills. The tool offers extreme efficiency with Result Truncation and SKILL.md slimming, a versatile tool library with 282 Skills supporting Batch operations, ensuring transactional safety with automatic rollback, multiple instance support for controlling multiple Unity projects simultaneously, deep integration with Antigravity Slash Commands for interactive experience, compatibility with popular AI terminals like Claude Code, Antigravity, Gemini CLI, and support for Cinemachine 2.x/3.x dual versions with advanced camera control features like MixingCamera, ClearShot, TargetGroup, and Spline.
tradecat
TradeCat is a comprehensive data analysis and trading platform designed for cryptocurrency, stock, and macroeconomic data. It offers a wide range of features including multi-market data collection, technical indicator modules, AI analysis, signal detection engine, Telegram bot integration, and more. The platform utilizes technologies like Python, TimescaleDB, TA-Lib, Pandas, NumPy, and various APIs to provide users with valuable insights and tools for trading decisions. With a modular architecture and detailed documentation, TradeCat aims to empower users in making informed trading decisions across different markets.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.
For similar tasks
SwanLab
SwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and collaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times. It offers a friendly API and a beautiful interface, combining hyperparameter tracking, metric recording, online collaboration, experiment link sharing, real-time message notifications, and more. With SwanLab, researchers can document their training experiences, seamlessly communicate and collaborate with collaborators, and machine learning engineers can develop models for production faster.
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

aisuite
Aisuite is a simple, unified interface to multiple Generative AI providers. It allows developers to easily interact with various Language Model (LLM) providers like OpenAI, Anthropic, Azure, Google, AWS, and more through a standardized interface. The library focuses on chat completions and provides a thin wrapper around python client libraries, enabling creators to test responses from different LLM providers without changing their code. Aisuite maximizes stability by using HTTP endpoints or SDKs for making calls to the providers. Users can install the base package or specific provider packages, set up API keys, and utilize the library to generate chat completion responses from different models.
AI-Shortcuts
AI Shortcuts is a browser extension designed to enhance the efficiency of using AI websites. It allows users to quickly send messages, open frequently used AI sites, compare generation results from multiple sites, and access AI content without the need for registration or membership. Users can configure their most frequently used AI sites and easily query selected text on webpages. The extension also features a tab mode for comparing results across multiple AI sites.
simple-llm-eval
Simpleval is a Python package for evaluating Large Language Models (LLMs) using the 'LLM as a Judge' technique. It supports various LLM providers such as OpenAI, Google, AWS, Anthropic, Azure, and more. The package includes reports for analyzing and summarizing evaluation results.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.