Best AI tools for< Llm Evaluation >
Infographic
20 - AI tool Sites

Truesight
Goodeye Labs offers Truesight, an AI evaluation tool designed for domain experts to assess the performance of AI products without the need for extensive technical expertise. Truesight bridges the gap between domain knowledge and technical implementation, enabling users to evaluate AI-generated content against specific standards and factors. By empowering domain experts to provide judgment on AI performance, Truesight streamlines the evaluation process, reducing costs, meeting deadlines, and enhancing the reliability of AI products.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
Dr. Randal S. Olson
Dr. Randal S. Olson is an AI Researcher & Builder known for turning ambitious AI ideas into business wins by bridging the gap between technical promise and real-world impact. His work encompasses data science, AI engineering, and executive strategy. He has worked on various projects in AI, data science, and technology leadership, including the development of the Truesight Expert-grounded AI evaluation platform and the AutoML Tool TPOT. Dr. Olson's focus is on building privacy-first AI solutions that prioritize ethical AI development and user-centric design.

Confident AI
Confident AI is an AI evaluation and observability platform designed to help engineers, QA teams, and product leaders build reliable AI systems. It offers best-in-class evaluation metrics powered by DeepEval, real-time production alerts, and tools for tracing and monitoring AI performance. The platform aims to streamline dataset curation, metric alignment, and LLM testing automation, ultimately saving time, reducing costs, and ensuring continuous improvement of AI models.
Airtrain
Airtrain is a no-code compute platform for Large Language Models (LLMs). It provides a user-friendly interface for fine-tuning, evaluating, and deploying custom AI models. Airtrain also offers a marketplace of pre-trained models that can be used for a variety of tasks, such as text generation, translation, and question answering.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.
micro1
micro1 is an AI recruitment tool that leverages human data produced by subject matter experts to help companies identify and hire top talent efficiently. The platform offers end-to-end post-training solutions, high-quality data for model training, pre-vetted AI trainers, and enterprise-grade LLM evaluations. With a focus on tech startups, staffing agencies, and enterprises, micro1 aims to streamline the recruitment process and save costs for businesses.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
MindpoolAI
MindpoolAI is a tool that allows users to access multiple leading AI models with a single query. This means that users can get the answers they are looking for, spark ideas, and fuel their work, creativity, and curiosity. MindpoolAI is easy to use and does not require any technical expertise. Users simply need to enter their prompt and select the AI models they want to compare. MindpoolAI will then send the query to the selected models and present the results in an easy-to-understand format.
Agenta.ai
Agenta.ai is a platform designed to provide prompt management, evaluation, and observability for LLM (Large Language Model) applications. It aims to address the challenges faced by AI development teams in managing prompts, collaborating effectively, and ensuring reliable product outcomes. By centralizing prompts, evaluations, and traces, Agenta.ai helps teams streamline their workflows and follow best practices in LLMOps. The platform offers features such as unified playground for prompt comparison, automated evaluation processes, human evaluation integration, observability tools for debugging AI systems, and collaborative workflows for PMs, experts, and developers.
Weights & Biases
Weights & Biases is an AI tool that offers documentation, guides, tutorials, and support for using AI models in applications. The platform provides two main products: W&B Weave for integrating AI models into code and W&B Models for building custom AI models. Users can access features such as tracing, output evaluation, cost estimates, hyperparameter sweeps, model registry, and more. Weights & Biases aims to simplify the process of working with AI models and improving model reproducibility.
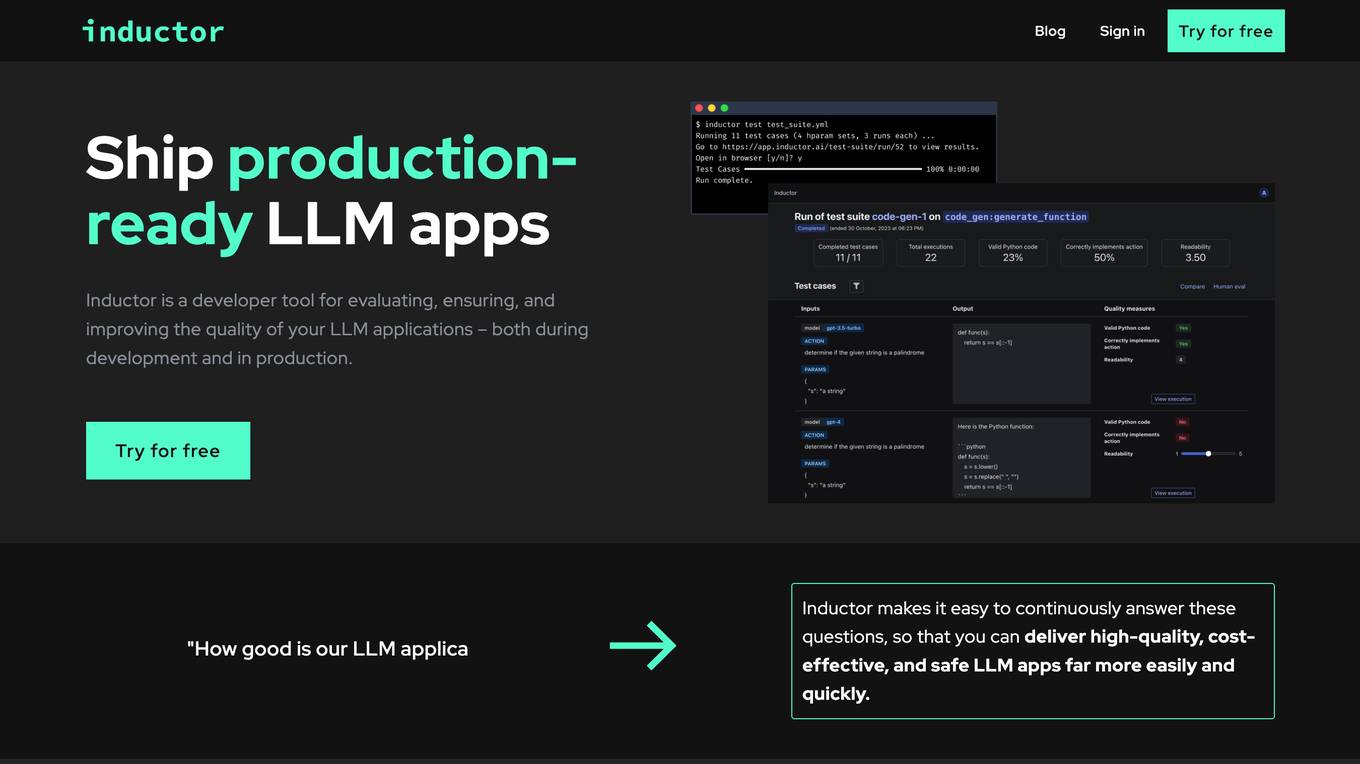
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
Vellum AI
Vellum AI is an AI platform that supports using Microsoft Azure hosted OpenAI models. It offers tools for prompt engineering, semantic search, prompt chaining, evaluations, and monitoring. Vellum enables users to build AI systems with features like workflow automation, document analysis, fine-tuning, Q&A over documents, intent classification, summarization, vector search, chatbots, blog generation, sentiment analysis, and more. The platform is backed by top VCs and founders of well-known companies, providing a complete solution for building LLM-powered applications.
1 - Open Source Tools

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
20 - OpenAI Gpts




Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.

CISO GPT
Specialized LLM in computer security, acting as a CISO with 20 years of experience, providing precise, data-driven technical responses to enhance organizational security.
NEO - Ultimate AI
I imitate GPT-5 LLM, with advanced reasoning, personalization, and higher emotional intelligence
DataLearnerAI-GPT
Using OpenLLMLeaderboard data to answer your questions about LLM. For Currently!

Prompt Peerless - Complete Prompt Optimization
Premier AI Prompt Engineer for Advanced LLM Optimization, Enhancing AI-to-AI Interaction and Comprehension. Create -> Optimize -> Revise iteratively
EmotionPrompt(LLM→人間ver.)
EmotionPrompt手法に基づいて作成していますが、本来の理論とは反対に人間に対してLLMがPromptを投げます。本来の手法の詳細:https://ai-data-base.com/archives/58158
HackMeIfYouCan
Hack Me if you can - I can only talk to you about computer security, software security and LLM security @JacquesGariepy
SSLLMs Advisor
Helps you build logic security into your GPTs custom instructions. Documentation: https://github.com/infotrix/SSLLMs---Semantic-Secuirty-for-LLM-GPTs
Prompt For Me
🪄Prompt一键强化,快速、精准对齐需求,与AI对话更高效。 🧙♂️解锁LLM潜力,让ChatGPT、Claude更懂你,工作快人一步。 🧸你的AI对话伙伴,定制专属需求,轻松开启高品质对话体验