
Kiln
The easiest tool for fine-tuning LLM models, synthetic data generation, and collaborating on datasets.
Stars: 4207

Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.
README:
Kiln is a free and intuitive app for building AI systems and products
Guides: Evals • Fine Tuning • Synthetic Data • RAG • Quick Start • All Docs
![]()

- 🚀 Intuitive Desktop Apps: One-click apps for Windows, MacOS, and Linux.
- 📊 Evals: Evaluate the quality of your models/tasks using state of the art evaluators.
- 🎛️ Fine Tuning: Zero-code fine-tuning for Llama, GPT-4o, and more. Automatic serverless deployment of models.
- 🤖 Synthetic Data Generation: Generate eval datasets or fine-tuning data with our interactive visual tooling.
- 🔍 Docs & Search (RAG): Add knowledge to your AI systems with Retrieval-Augmented Generation (RAG).
- 🛠 Tools & MCP: Connect powerful tools to your Kiln tasks
- 🧠 Reasoning Models: Train or distill your own custom reasoning models.
- 📝 Prompt Generation: Automatically generate prompts including chain-of-thought, few-shot, and multi-shot, and more.
- 🌐 Comprehensive Model Support: Skip the guesswork — we've tested over 100 models' capabilities. Use any model via Ollama, OpenAI, OpenRouter, Fireworks, Groq, AWS, any OpenAI compatible API, and more.
- 🤝 Team Collaboration: Git-based version control for your AI datasets. Intuitive UI makes it easy to collaborate with QA, PM, and subject matter experts on data samples, evals, prompts, ratings and issues.
- 🗃️ Structured Data: Build AI tasks that speak JSON.
- 🧑💻 Open-Source Library and API: Our Python library and OpenAPI REST API are MIT open source.
- 🔒 Privacy-First: Kiln runs locally on your computer. We can't access your data. Bring your own API keys or use Ollama.
- 📚 Awesome Docs: easy-to-follow video guides, approachable for beginners, and depth for advanced users.
- 💰 Free: Our apps are free and our library is open-source.
Watch a 2 minute overview of Kiln or our end to end project demo (20 minutes).

For privacy, Kiln doesn't track the identity of who uses it. People from these companies have joined our communities on Github & Discord.
Available on MacOS, Windows and Linux.
Kiln is quite intuitive, so we suggest launching the desktop app and diving in. However if you have any questions or want to learn more, our docs are here to help.
- Fine Tuning LLM Models
- Guide: Train a Reasoning Model
- LLM Evaluators
- End to End Project Demo
- Tools 101: Intro to Tools & MCP
- Quick Start
- How to use any AI model or provider in Kiln
- Documents & Search Tools (RAG)
- Tools & MCP
- Reasoning & Chain of Thought
- Synthetic Data Generation
- Collaborating with Kiln
- Rating and Labeling Data
- Prompt Styles
- Structured Data / JSON
- Organizing Kiln Datasets (Tags and Filters)
- Our Data Model
- Repairing Responses
- Keyboard Shortcuts
- Privacy Overview: Private by Design
For developers, see our Kiln Python Library Docs. These include how to load datasets into Kiln, or using Kiln datasets in your own code-base/notebooks.
| CI |
|
| Tests |

|
| Package |
 
|
| Meta |
|
| Apps |

|
| Connect |
|
Our open-source python library allows you to integrate Kiln datasets into your own workflows, build fine tunes, use Kiln in Notebooks, build custom tools, and much more! Read the docs for examples.
pip install kiln-aiThere are new models and techniques emerging all the time. Kiln makes it easy to try a variety of approaches and compare them in a few clicks without writing code. These can result in higher quality and improved performance.
We currently support:
- Various prompting techniques: basic, few-shot, multi-shot, repair & feedback
- Chain of thought / thinking, with optional custom “thinking” instructions
- Many models: GPT, Llama, Claude, Gemini, Mistral, Gemma, Phi
- Fine Tuning: create custom models using your Kiln dataset
- Evaluations using LLM-as-Judge and G-Eval
- Distilling models
In the future, we plan to add more powerful no-code options like RAG. For experienced data-scientists, you can create these techniques today using Kiln datasets and our Python library.
When building AI products, there’s usually a subject matter expert who knows the problem you are trying to solve, and a different technical team assigned to build the model. Kiln bridges that gap as a collaboration tool.
Subject matter experts can use our intuitive desktop apps to generate structured datasets and ratings, without coding or using technical tools. No command line or GPU required.
Data-scientists can consume the dataset created by subject matter experts, using the UI, or deep dive with our python library.
QA and PM can easily identify issues sooner and help generate the dataset content needed to fix the issue at the model layer.
The dataset file format is designed to be used with Git for powerful collaboration and attribution. Many people can contribute in parallel; collisions are avoided using UUIDs, and attribution is captured inside the dataset files. You can even share a dataset on a shared drive, letting completely non-technical team members contribute data and evals without knowing Git.
Products don’t naturally have “datasets”, but Kiln helps you create one. Every time you use Kiln, we capture the inputs, outputs, human ratings, feedback, and repairs needed to build high quality models for use in your product. The more you use it, the more data you have.
Our synthetic data generation tool can build datasets for evals and fine-tuning in minutes.
Your model quality improves automatically as the dataset grows, by giving the models more examples of quality content (and mistakes). If your product goals shift or new bugs are found (as is almost always the case), you can easily iterate the dataset to address issues.
See CONTRIBUTING.md for information on how to setup a development environment and contribute to Kiln.
@software{kiln_ai,
title = {Kiln: Rapid AI Prototyping and Dataset Collaboration Tool},
author = {{Chesterfield Laboratories Inc.}},
year = {2025},
url = {https://github.com/Kiln-AI/Kiln},
version = {latest}
}- Python Library: MIT License
- Python REST Server/API: MIT License
- Desktop App: free to download and use under our EULA, and source-available. License
- The Kiln names and logos are trademarks of Chesterfield Laboratories Inc.
Copyright 2024 - Chesterfield Laboratories Inc.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Kiln
Similar Open Source Tools
Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
pipeshub-ai
Pipeshub-ai is a versatile tool for automating data pipelines in AI projects. It provides a user-friendly interface to design, deploy, and monitor complex data workflows, enabling seamless integration of various AI models and data sources. With Pipeshub-ai, users can easily create end-to-end pipelines for tasks such as data preprocessing, model training, and inference, streamlining the AI development process and improving productivity. The tool supports integration with popular AI frameworks and cloud services, making it suitable for both beginners and experienced AI practitioners.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.

MONAI
MONAI is a PyTorch-based, open-source framework for deep learning in healthcare imaging. It provides a comprehensive set of tools for medical image analysis, including data preprocessing, model training, and evaluation. MONAI is designed to be flexible and easy to use, making it a valuable resource for researchers and developers in the field of medical imaging.
giselle
Giselle is an open source AI tool designed for agentic workflows, facilitating seamless collaboration between humans and AI. It offers cloud hosting with free agent time, self-hosting options, and a Vibe Cording Guide for using AI coding assistants. Giselle is suitable for developers and non-engineers alike, empowering users to leverage AI capabilities without extensive coding knowledge. The tool is actively developed, with a roadmap in progress, and welcomes contributions from the community under the Apache License Version 2.0.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
aiida-core
AiiDA (www.aiida.net) is a workflow manager for computational science with a strong focus on provenance, performance and extensibility. **Features** * **Workflows:** Write complex, auto-documenting workflows in python, linked to arbitrary executables on local and remote computers. The event-based workflow engine supports tens of thousands of processes per hour with full checkpointing. * **Data provenance:** Automatically track inputs, outputs & metadata of all calculations in a provenance graph for full reproducibility. Perform fast queries on graphs containing millions of nodes. * **HPC interface:** Move your calculations to a different computer by changing one line of code. AiiDA is compatible with schedulers like SLURM, PBS Pro, torque, SGE or LSF out of the box. * **Plugin interface:** Extend AiiDA with plugins for new simulation codes (input generation & parsing), data types, schedulers, transport modes and more. * **Open Science:** Export subsets of your provenance graph and share them with peers or make them available online for everyone on the Materials Cloud. * **Open source:** AiiDA is released under the MIT open source license

flow-like
Flow-Like is an enterprise-grade workflow operating system built upon Rust for uncompromising performance, efficiency, and code safety. It offers a modular frontend for apps, a rich set of events, a node catalog, a powerful no-code workflow IDE, and tools to manage teams, templates, and projects within organizations. With typed workflows, users can create complex, large-scale workflows with clear data origins, transformations, and contracts. Flow-Like is designed to automate any process through seamless integration of LLM, ML-based, and deterministic decision-making instances.
tuff
Tuff is a local-first, AI-native, and infinitely extensible desktop command center designed to enhance workflow efficiency. It offers a seamless integration of core utilities, AI-powered search, contextual intelligence, and extensibility through custom plugins. With a beautiful UI design, rich functionality, simple operations, and a focus on security and reliability, Tuff provides users with a cross-platform desktop software that is easy to use and offers a good user experience.
xpert
Xpert is a powerful tool for data analysis and visualization. It provides a user-friendly interface to explore and manipulate datasets, perform statistical analysis, and create insightful visualizations. With Xpert, users can easily import data from various sources, clean and preprocess data, analyze trends and patterns, and generate interactive charts and graphs. Whether you are a data scientist, analyst, researcher, or student, Xpert simplifies the process of data analysis and visualization, making it accessible to users with varying levels of expertise.

axolotl
Axolotl is a lightweight and efficient tool for managing and analyzing large datasets. It provides a user-friendly interface for data manipulation, visualization, and statistical analysis. With Axolotl, users can easily import, clean, and explore data to gain valuable insights and make informed decisions. The tool supports various data formats and offers a wide range of functions for data processing and modeling. Whether you are a data scientist, researcher, or business analyst, Axolotl can help streamline your data workflows and enhance your data analysis capabilities.
For similar tasks
Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
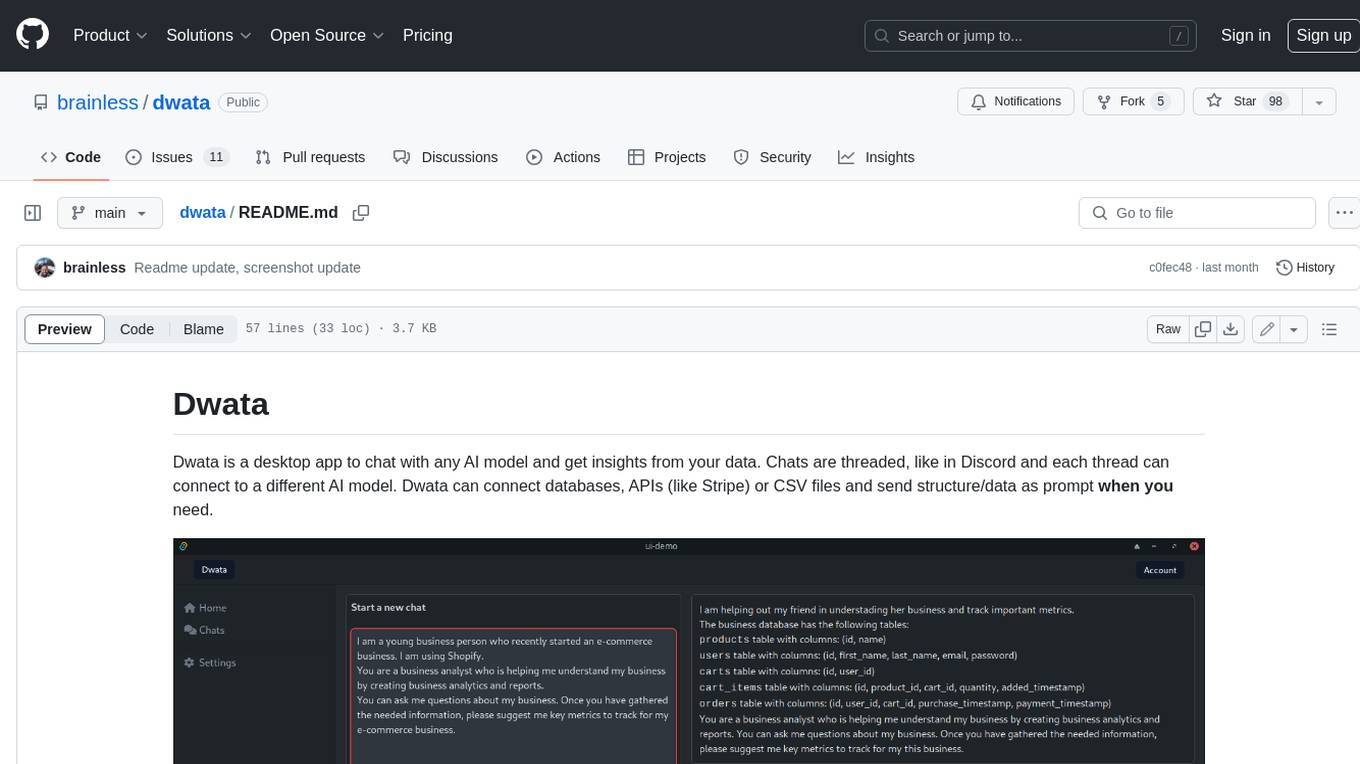
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.