Best AI tools for< Fine-tune Models >
18 - AI tool Sites
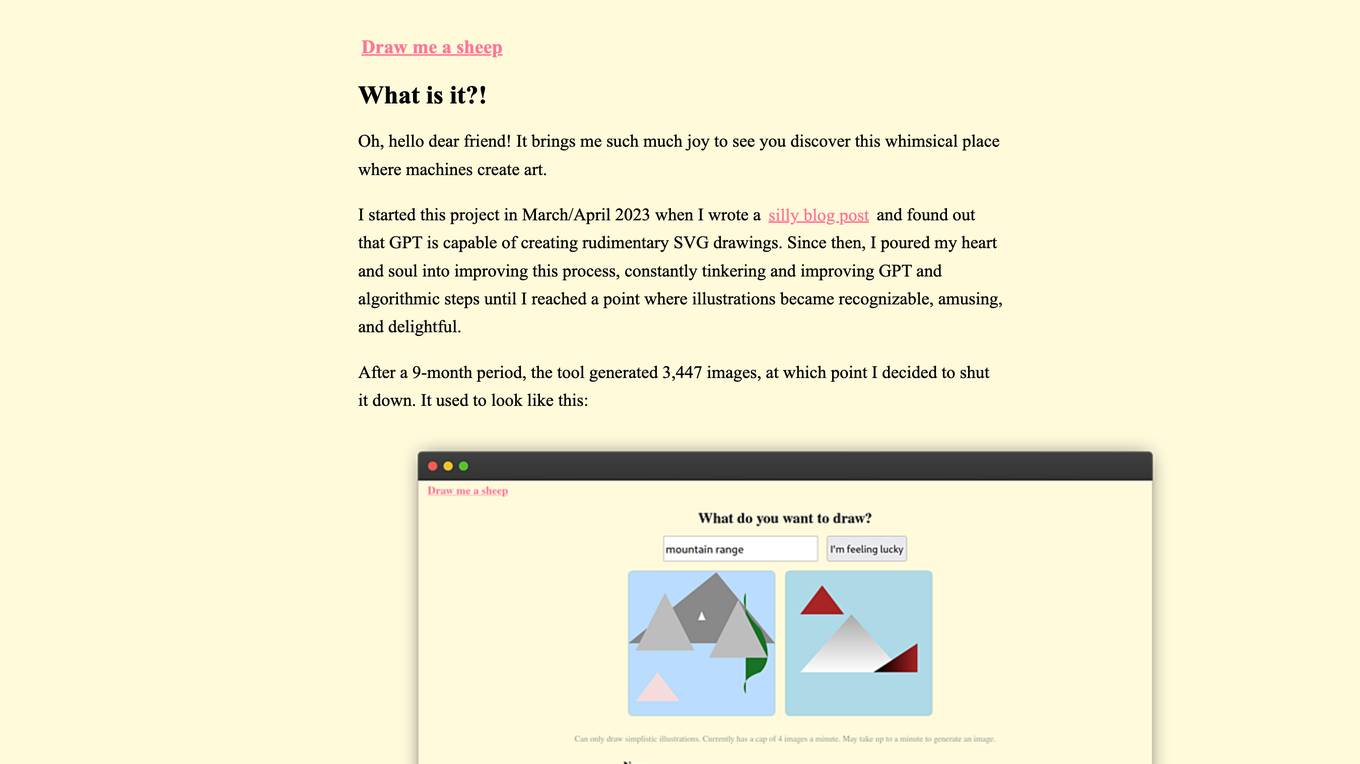
WhimsicalAI
The website is an AI tool that allows users to generate whimsical and delightful illustrations using GPT and algorithmic steps. The project started in March/April 2023 and evolved to create recognizable and amusing images. The tool generated 3,447 images over a 9-month period before being shut down. The collected data could be used for fine-tuning a model, although the project has not started yet.

Replicate
Replicate is an AI tool that allows users to run and fine-tune models, deploy custom models at scale, and generate various types of content such as images, videos, music, and text with just one line of code. It provides access to a wide range of high-quality models contributed by the community, enabling users to explore, fine-tune, and deploy AI models efficiently. Replicate aims to make AI accessible and practical for real-world applications beyond academic research and demos.
fal.ai
fal.ai is a generative media platform designed for developers to build the next generation of creativity. It offers lightning-fast inference with no compromise on quality, providing access to high-quality generative media models optimized by the fal Inference Engine™. The platform allows developers to fine-tune their own models, leverage real-time infrastructure for new user experiences, and scale to thousands of GPUs as needed. With a focus on developer experience, fal.ai aims to be the fastest AI tool for running diffusion models.
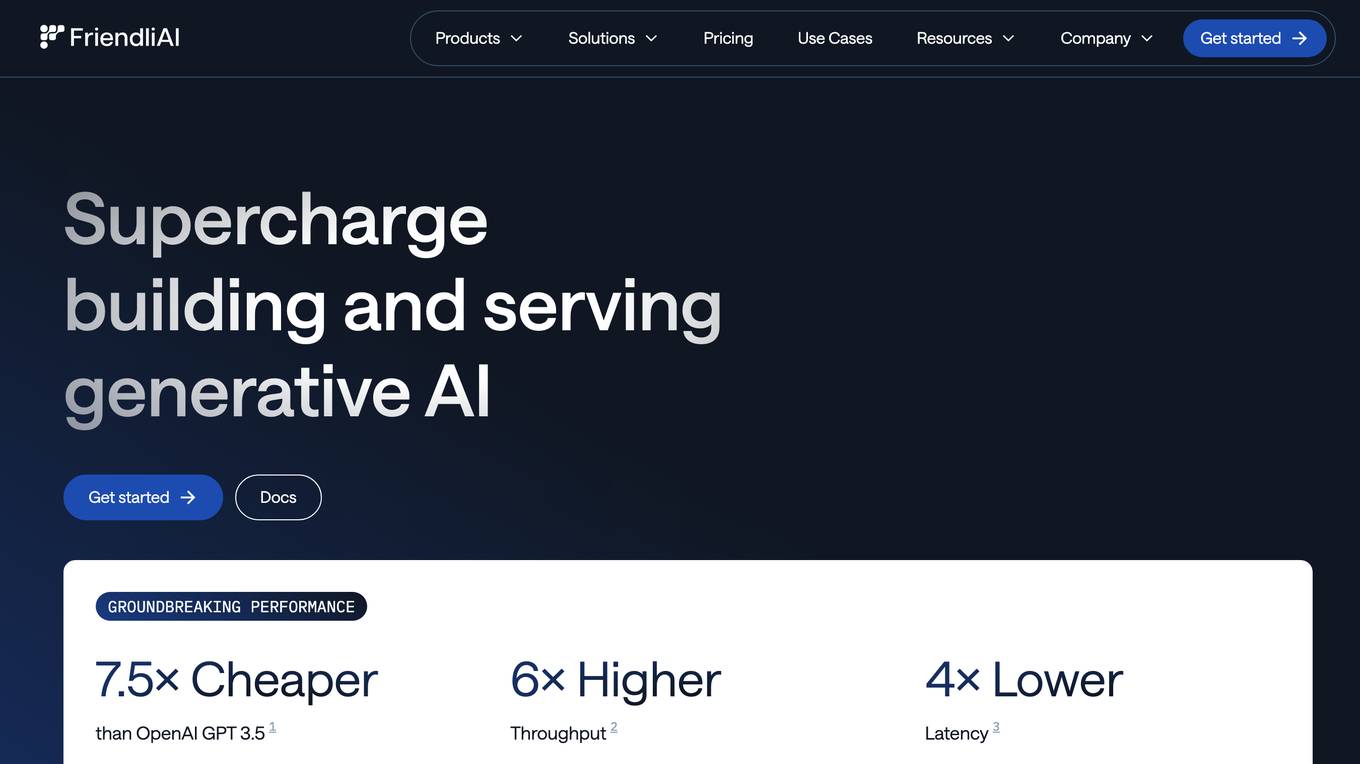
FriendliAI
FriendliAI is a generative AI infrastructure company that offers efficient, fast, and reliable generative AI inference solutions for production. Their cutting-edge technologies enable groundbreaking performance improvements, cost savings, and lower latency. FriendliAI provides a platform for building and serving compound AI systems, deploying custom models effortlessly, and monitoring and debugging model performance. The application guarantees consistent results regardless of the model used and offers seamless data integration for real-time knowledge enhancement. With a focus on security, scalability, and performance optimization, FriendliAI empowers businesses to scale with ease.
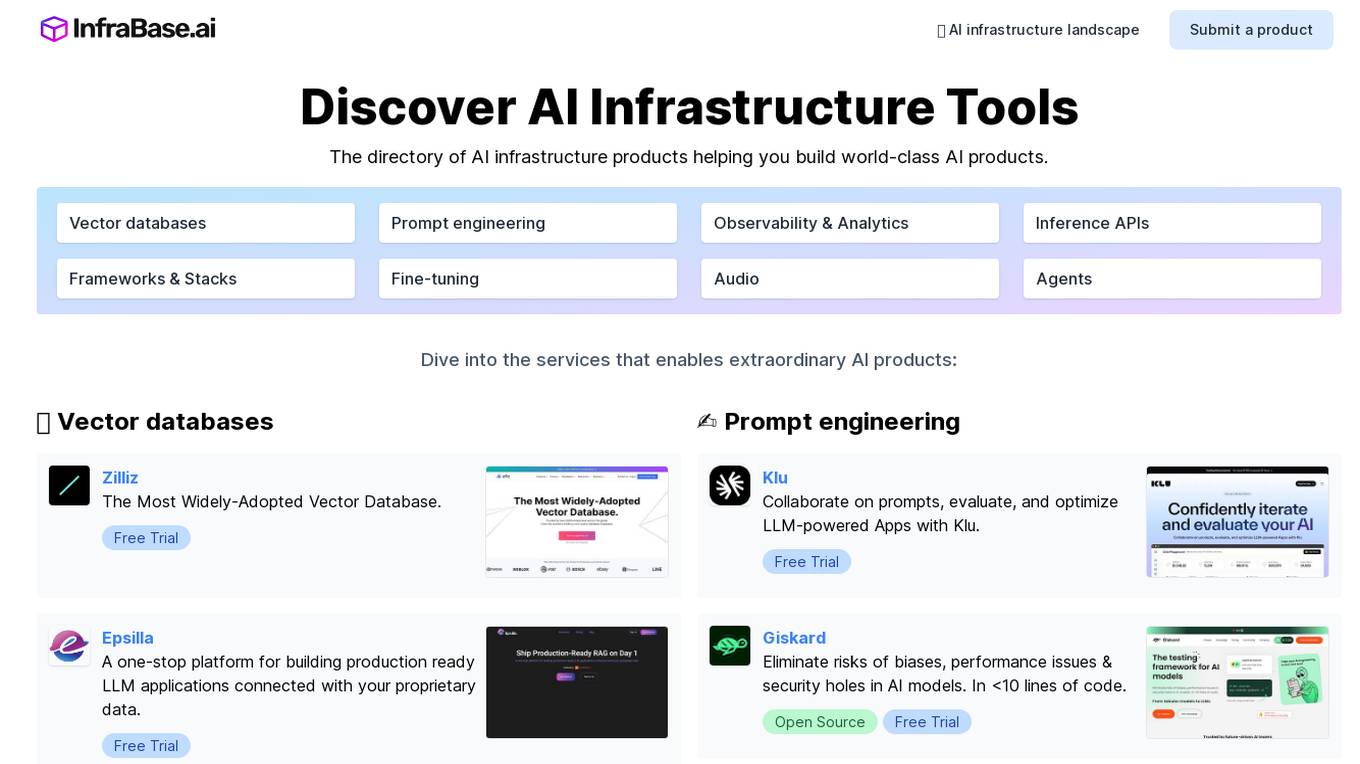
Infrabase.ai
Infrabase.ai is a directory of AI infrastructure products that helps users discover and explore a wide range of tools for building world-class AI products. The platform offers a comprehensive directory of products in categories such as Vector databases, Prompt engineering, Observability & Analytics, Inference APIs, Frameworks & Stacks, Fine-tuning, Audio, and Agents. Users can find tools for tasks like data storage, model development, performance monitoring, and more, making it a valuable resource for AI projects.

Helix AI
Helix AI is a private GenAI platform that enables users to build AI applications using open source models. The platform offers tools for RAG (Retrieval-Augmented Generation) and fine-tuning, allowing deployment on-premises or in a Virtual Private Cloud (VPC). Users can access curated models, utilize Helix API tools to connect internal and external APIs, embed Helix Assistants into websites/apps for chatbot functionality, write AI application logic in natural language, and benefit from the innovative RAG system for Q&A generation. Additionally, users can fine-tune models for domain-specific needs and deploy securely on Kubernetes or Docker in any cloud environment. Helix Cloud offers free and premium tiers with GPU priority, catering to individuals, students, educators, and companies of varying sizes.

Mixpeek
Mixpeek is a multimodal intelligence platform that helps users extract important data from videos, images, audio, and documents. It enables users to focus on insights rather than data preparation by identifying concepts, activities, and objects from various sources. Mixpeek offers features such as real-time synchronization, extraction and embedding, fine-tuning and scaling of models, and seamless integration with various data sources. The platform is designed to be easy to use, scalable, and secure, making it suitable for a wide range of applications.
ITSoli
ITSoli is an AI consulting firm that specializes in AI adoption, transformation, and data intelligence services. They offer custom AI models, data services, and strategic partnerships to help organizations innovate, automate, and accelerate their AI journey. With expertise in fine-tuning AI models and training custom agents, ITSoli aims to unlock the power of AI for businesses across various industries.

Flux LoRA Model Library
Flux LoRA Model Library is an AI tool that provides a platform for finding and using Flux LoRA models suitable for various projects. Users can browse a catalog of popular Flux LoRA models and learn about FLUX models and LoRA (Low-Rank Adaptation) technology. The platform offers resources for fine-tuning models and ensuring responsible use of generated images.
Cerebras
Cerebras is a leading AI tool and application provider that offers cutting-edge AI supercomputers, model services, and cloud solutions for various industries. The platform specializes in high-performance computing, large language models, and AI model training, catering to sectors such as health, energy, government, and financial services. Cerebras empowers developers and researchers with access to advanced AI models, open-source resources, and innovative hardware and software development kits.
HOPPR
HOPPR is a medical-grade platform that accelerates the development of tailored applications to enhance clinical care and optimize workflows. The platform streamlines AI development in medical imaging, prioritizes data security and privacy, and offers diverse datasets across modalities, anatomies, demographics, and geographies. HOPPR empowers faster prototyping, hypothesis testing, and scalable applications for research and medical imaging services, addressing the growing crisis in medical imaging by enabling partners to rapidly develop solutions that improve patient care, enhance operational efficiency, and increase clinician satisfaction.
MakePhotoFast
MakePhotoFast is an AI-powered image generation tool that allows users to create stunning photos with advanced AI models. Users can enter a prompt or select an image package to generate images quickly, fine-tune custom AI models, and download and share the enhanced photos. The tool offers powerful features such as AI-powered image generation, custom AI model fine-tuning, and style package selection. With simple one-time pricing and no subscriptions, MakePhotoFast provides a user-friendly experience for creating unique and professional-looking images.
Together AI
Together AI is an AI tool that offers a variety of generative AI services, including serverless models, fine-tuning capabilities, dedicated endpoints, and GPU clusters. Users can run or fine-tune leading open source models with only a few lines of code. The platform provides a range of functionalities for tasks such as chat, vision, text-to-speech, code/language reranking, and more. Together AI aims to simplify the process of utilizing AI models for various applications.
TractoAI
TractoAI is an advanced AI platform that offers deep learning solutions for various industries. It provides Batch Inference with no rate limits, DeepSeek offline inference, and helps in training open source AI models. TractoAI simplifies training infrastructure setup, accelerates workflows with GPUs, and automates deployment and scaling for tasks like ML training and big data processing. The platform supports fine-tuning models, sandboxed code execution, and building custom AI models with distributed training launcher. It is developer-friendly, scalable, and efficient, offering a solution library and expert guidance for AI projects.

Sapien.io
Sapien.io is a decentralized data foundry that offers data labeling services powered by a decentralized workforce and gamified platform. The platform provides high-quality training data for large language models through a human-in-the-loop labeling process, enabling fine-tuning of datasets to build performant AI models. Sapien combines AI and human intelligence to collect and annotate various data types for any model, offering customized data collection and labeling models across industries.

Mozilla.ai Lumigator Blueprints
Mozilla.ai Lumigator Blueprints is a developer-first hub for open-source AI workflows. It provides a platform for exploring and customizing AI blueprints, such as building timeline algorithms, fine-tuning models, and mapping features using computer vision. The site aims to empower users to create personalized AI solutions tailored to their specific needs and preferences.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.

Lambda Docs
Lambda Docs is an AI tool that provides cloud and hardware solutions for individuals, teams, and organizations. It offers services such as Managed Kubernetes, Preinstalled Kubernetes, Slurm, and access to GPU clusters. The platform also provides educational resources and tutorials for machine learning engineers and researchers to fine-tune models and deploy AI solutions.
129 - Open Source AI Tools

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.

awesome-llm
Awesome LLM is a curated list of resources related to Large Language Models (LLMs), including models, projects, datasets, benchmarks, materials, papers, posts, GitHub repositories, HuggingFace repositories, and reading materials. It provides detailed information on various LLMs, their parameter sizes, announcement dates, and contributors. The repository covers a wide range of LLM-related topics and serves as a valuable resource for researchers, developers, and enthusiasts interested in the field of natural language processing and artificial intelligence.
gigax
Gigax is a tool for creating and controlling Non-Player Characters (NPCs) powered by Large Language Models (LLMs). It allows users to define actions for NPCs such as speaking, jumping, and attacking, with quick GPU inference times. The tool provides access to open-weights models fine-tuned from Llama-3, Phi-3, Mistral, and more. Users can generate structured content with outlines, ensuring the output format is always respected. Gigax is continuously evolving with upcoming features like local server mode and API support for runtime quest generation and memory management. It offers various models on the Huggingface hub for instantiating NPCs and provides classes for handling locations, characters, items, and events.
ChuanhuChatGPT
Chuanhu Chat is a user-friendly web graphical interface that provides various additional features for ChatGPT and other language models. It supports GPT-4, file-based question answering, local deployment of language models, online search, agent assistant, and fine-tuning. The tool offers a range of functionalities including auto-solving questions, online searching with network support, knowledge base for quick reading, local deployment of language models, GPT 3.5 fine-tuning, and custom model integration. It also features system prompts for effective role-playing, basic conversation capabilities with options to regenerate or delete dialogues, conversation history management with auto-saving and search functionalities, and a visually appealing user experience with themes, dark mode, LaTeX rendering, and PWA application support.

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.
awesome-ml
Awesome ML is a curated list of resources and tools related to machine learning, covering a wide range of topics such as large language models, image models, video models, audio models, and marketing data science. It includes open LLM models, tools, GUIs, backends, voice assistants, code generation, libraries, fine tuning, data sets, research, image and video models, audio tasks like compression, speech recognition, and music generation, as well as resources for marketing data science. The repository aims to provide a comprehensive collection of resources for individuals interested in machine learning and its applications.

co-llm
Co-LLM (Collaborative Language Models) is a tool for learning to decode collaboratively with multiple language models. It provides a method for data processing, training, and inference using a collaborative approach. The tool involves steps such as formatting/tokenization, scoring logits, initializing Z vector, deferral training, and generating results using multiple models. Co-LLM supports training with different collaboration pairs and provides baseline training scripts for various models. In inference, it uses 'vllm' services to orchestrate models and generate results through API-like services. The tool is inspired by allenai/open-instruct and aims to improve decoding performance through collaborative learning.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.
awesome-gpt-prompt-engineering
Awesome GPT Prompt Engineering is a curated list of resources, tools, and shiny things for GPT prompt engineering. It includes roadmaps, guides, techniques, prompt collections, papers, books, communities, prompt generators, Auto-GPT related tools, prompt injection information, ChatGPT plug-ins, prompt engineering job offers, and AI links directories. The repository aims to provide a comprehensive guide for prompt engineering enthusiasts, covering various aspects of working with GPT models and improving communication with AI tools.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
LLM-Alchemy-Chamber
LLM Alchemy Chamber is a repository dedicated to exploring the world of Language Models (LLMs) through various experiments and projects. It contains scripts, notebooks, and experiments focused on tasks such as fine-tuning different LLM models, quantization for performance optimization, dataset generation for instruction/QA tasks, and more. The repository offers a collection of resources for beginners and enthusiasts interested in delving into the mystical realm of LLMs.
ai_summer
AI Summer is a repository focused on providing workshops and resources for developing foundational skills in generative AI models and transformer models. The repository offers practical applications for inferencing and training, with a specific emphasis on understanding and utilizing advanced AI chat models like BingGPT. Participants are encouraged to engage in interactive programming environments, decide on projects to work on, and actively participate in discussions and breakout rooms. The workshops cover topics such as generative AI models, retrieval-augmented generation, building AI solutions, and fine-tuning models. The goal is to equip individuals with the necessary skills to work with AI technologies effectively and securely, both locally and in the cloud.
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.
UnrealOpenAIPlugin
UnrealOpenAIPlugin is a comprehensive Unreal Engine wrapper for the OpenAI API, supporting various endpoints such as Models, Completions, Chat, Images, Vision, Embeddings, Speech, Audio, Files, Moderations, Fine-tuning, and Functions. It provides support for both C++ and Blueprints, allowing users to interact with OpenAI services seamlessly within Unreal Engine projects. The plugin also includes tutorials, updates, installation instructions, authentication steps, examples of usage, blueprint nodes overview, C++ examples, plugin structure details, documentation references, tests, packaging guidelines, and limitations. Users can leverage this plugin to integrate powerful AI capabilities into their Unreal Engine projects effortlessly.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.
Vodalus-Expert-LLM-Forge
Vodalus Expert LLM Forge is a tool designed for crafting datasets and efficiently fine-tuning models using free open-source tools. It includes components for data generation, LLM interaction, RAG engine integration, model training, fine-tuning, and quantization. The tool is suitable for users at all levels and is accompanied by comprehensive documentation. Users can generate synthetic data, interact with LLMs, train models, and optimize performance for local execution. The tool provides detailed guides and instructions for setup, usage, and customization.
vscode-ai-toolkit
AI Toolkit for Visual Studio Code simplifies generative AI app development by bringing together cutting-edge AI development tools and models from Azure AI Studio Catalog and other catalogs like Hugging Face. Users can browse the AI models catalog, download them locally, fine-tune, test, and deploy them to the cloud. The toolkit offers actions such as finding supported models, testing model inference, fine-tuning models locally or remotely, and deploying fine-tuned models to the cloud. It also provides optimized AI models for Windows and a Q&A section for common issues and resolutions.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
refact
This repository contains Refact WebUI for fine-tuning and self-hosting of code models, which can be used inside Refact plugins for code completion and chat. Users can fine-tune open-source code models, self-host them, download and upload Lloras, use models for code completion and chat inside Refact plugins, shard models, host multiple small models on one GPU, and connect GPT-models for chat using OpenAI and Anthropic keys. The repository provides a Docker container for running the self-hosted server and supports various models for completion, chat, and fine-tuning. Refact is free for individuals and small teams under the BSD-3-Clause license, with custom installation options available for GPU support. The community and support include contributing guidelines, GitHub issues for bugs, a community forum, Discord for chatting, and Twitter for product news and updates.

InternLM
InternLM is a powerful language model series with features such as 200K context window for long-context tasks, outstanding comprehensive performance in reasoning, math, code, chat experience, instruction following, and creative writing, code interpreter & data analysis capabilities, and stronger tool utilization capabilities. It offers models in sizes of 7B and 20B, suitable for research and complex scenarios. The models are recommended for various applications and exhibit better performance than previous generations. InternLM models may match or surpass other open-source models like ChatGPT. The tool has been evaluated on various datasets and has shown superior performance in multiple tasks. It requires Python >= 3.8, PyTorch >= 1.12.0, and Transformers >= 4.34 for usage. InternLM can be used for tasks like chat, agent applications, fine-tuning, deployment, and long-context inference.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
Online-RLHF
This repository, Online RLHF, focuses on aligning large language models (LLMs) through online iterative Reinforcement Learning from Human Feedback (RLHF). It aims to bridge the gap in existing open-source RLHF projects by providing a detailed recipe for online iterative RLHF. The workflow presented here has shown to outperform offline counterparts in recent LLM literature, achieving comparable or better results than LLaMA3-8B-instruct using only open-source data. The repository includes model releases for SFT, Reward model, and RLHF model, along with installation instructions for both inference and training environments. Users can follow step-by-step guidance for supervised fine-tuning, reward modeling, data generation, data annotation, and training, ultimately enabling iterative training to run automatically.
llm-cookbook
LLM Cookbook is a developer-oriented comprehensive guide focusing on LLM for Chinese developers. It covers various aspects from Prompt Engineering to RAG development and model fine-tuning, providing guidance on how to learn and get started with LLM projects in a way suitable for Chinese learners. The project translates and reproduces 11 courses from Professor Andrew Ng's large model series, categorizing them for beginners to systematically learn essential skills and concepts before exploring specific interests. It encourages developers to contribute by replicating unreproduced courses following the format and submitting PRs for review and merging. The project aims to help developers grasp a wide range of skills and concepts related to LLM development, offering both online reading and PDF versions for easy access and learning.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
generative_ai_with_langchain
Generative AI with LangChain is a code repository for building large language model (LLM) apps with Python, ChatGPT, and other LLMs. The repository provides code examples, instructions, and configurations for creating generative AI applications using the LangChain framework. It covers topics such as setting up the development environment, installing dependencies with Conda or Pip, using Docker for environment setup, and setting API keys securely. The repository also emphasizes stability, code updates, and user engagement through issue reporting and feedback. It aims to empower users to leverage generative AI technologies for tasks like building chatbots, question-answering systems, software development aids, and data analysis applications.
RAGMeUp
RAG Me Up is a generic framework that enables users to perform Retrieve and Generate (RAG) on their own dataset easily. It consists of a small server and UIs for communication. Best run on GPU with 16GB vRAM. Users can combine RAG with fine-tuning using LLaMa2Lang repository. The tool allows configuration for LLM, data, LLM parameters, prompt, and document splitting. Funding is sought to democratize AI and advance its applications.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

ML-Bench
ML-Bench is a tool designed to evaluate large language models and agents for machine learning tasks on repository-level code. It provides functionalities for data preparation, environment setup, usage, API calling, open source model fine-tuning, and inference. Users can clone the repository, load datasets, run ML-LLM-Bench, prepare data, fine-tune models, and perform inference tasks. The tool aims to facilitate the evaluation of language models and agents in the context of machine learning tasks on code repositories.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.
LLM-Dojo
LLM-Dojo is an open-source platform for learning and practicing large models, providing a framework for building custom large model training processes, implementing various tricks and principles in the llm_tricks module, and mainstream model chat templates. The project includes an open-source large model training framework, detailed explanations and usage of the latest LLM tricks, and a collection of mainstream model chat templates. The term 'Dojo' symbolizes a place dedicated to learning and practice, borrowing its meaning from martial arts training.
cgft-llm
The cgft-llm repository is a collection of video tutorials and documentation for implementing large models. It provides guidance on topics such as fine-tuning llama3 with llama-factory, lightweight deployment and quantization using llama.cpp, speech generation with ChatTTS, introduction to Ollama for large model deployment, deployment tools for vllm and paged attention, and implementing RAG with llama-index. Users can find detailed code documentation and video tutorials for each project in the repository.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.
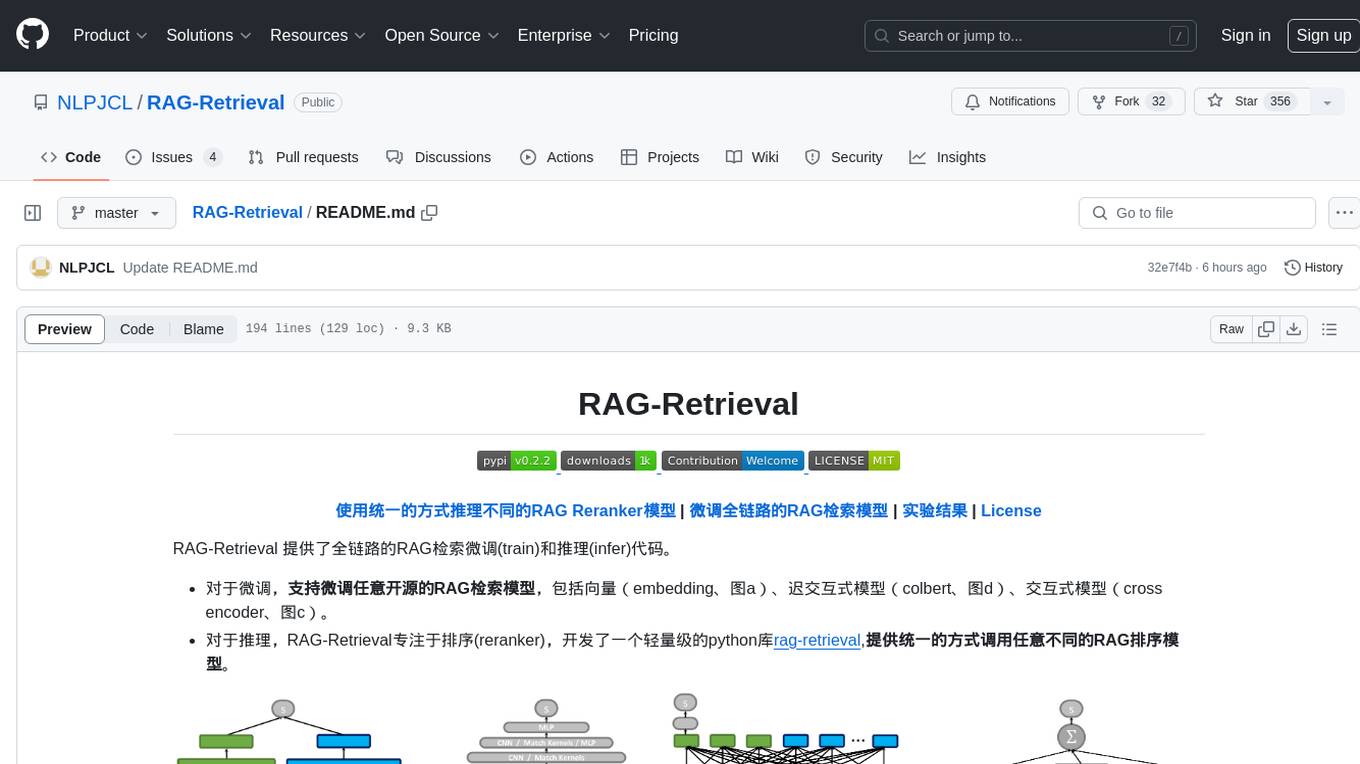
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
NeMo-Framework-Launcher
The NeMo Framework Launcher is a cloud-native tool designed for launching end-to-end NeMo Framework training jobs. It focuses on foundation model training for generative AI models, supporting large language model pretraining with techniques like model parallelism, tensor, pipeline, sequence, distributed optimizer, mixed precision training, and more. The tool scales to thousands of GPUs and can be used for training LLMs on trillions of tokens. It simplifies launching training jobs on cloud service providers or on-prem clusters, generating submission scripts, organizing job results, and supporting various model operations like fine-tuning, evaluation, export, and deployment.
oreilly_live_training_llm_apps
This repository provides resources and notebooks for building text-based applications using the ChatGPT API and Langchain. It includes guides on prompt engineering, fine-tuning ChatGPT, using LangChain, and creating applications like a quiz generator and notes summarizer. The repository aims to help users understand and implement various natural language processing tasks with pre-trained language models.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
shared_colab_notebooks
This repository serves as a collection of Google Colaboratory Notebooks for various tasks in Natural Language Processing (NLP), Natural Language Generation (NLG), Computer Vision, Generative Adversarial Networks (GANs), Streamlit applications, tutorials, UI/UX experiments, and other miscellaneous projects. It includes a wide range of pre-trained models, fine-tuning examples, and demos for tasks such as text generation, image processing, and more. The notebooks cover topics like self-attention, language model finetuning, emotion detection, image inpainting, and streamlit app creation. Users can explore different models, datasets, and techniques through these shared notebooks.
AI-Engineering.academy
AI Engineering Academy aims to provide a structured learning path for individuals looking to learn Applied AI effectively. The platform offers multiple roadmaps covering topics like Retrieval Augmented Generation, Fine-tuning, and Deployment. Each roadmap equips learners with the knowledge and skills needed to excel in applied GenAI. Additionally, the platform will feature Hands-on End-to-End AI projects in the future.
VinAI_Translate
VinAI_Translate is a Vietnamese-English Neural Machine Translation System offering state-of-the-art text-to-text translation models for Vietnamese-to-English and English-to-Vietnamese. The system includes pre-trained models with different configurations and parameters, allowing for further fine-tuning. Users can interact with the models through the VinAI Translate system website or the HuggingFace space 'VinAI Translate'. Evaluation scripts are available for assessing the translation quality. The tool can be used in the 'transformers' library for Vietnamese-to-English and English-to-Vietnamese translations, supporting both GPU-based batch translation and CPU-based sequence translation examples.
llm_recipes
This repository showcases the author's experiments with Large Language Models (LLMs) for text generation tasks. It includes dataset preparation, preprocessing, model fine-tuning using libraries such as Axolotl and HuggingFace, and model evaluation.
DistillKit
DistillKit is an open-source research effort by Arcee.AI focusing on model distillation methods for Large Language Models (LLMs). It provides tools for improving model performance and efficiency through logit-based and hidden states-based distillation methods. The tool supports supervised fine-tuning and aims to enhance the adoption of open-source LLM distillation techniques.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.
generative-ai-on-aws
Generative AI on AWS by O'Reilly Media provides a comprehensive guide on leveraging generative AI models on the AWS platform. The book covers various topics such as generative AI use cases, prompt engineering, large-language models, fine-tuning techniques, optimization, deployment, and more. Authors Chris Fregly, Antje Barth, and Shelbee Eigenbrode offer insights into cutting-edge AI technologies and practical applications in the field. The book is a valuable resource for data scientists, AI enthusiasts, and professionals looking to explore generative AI capabilities on AWS.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.
awesome-llms-fine-tuning
This repository is a curated collection of resources for fine-tuning Large Language Models (LLMs) like GPT, BERT, RoBERTa, and their variants. It includes tutorials, papers, tools, frameworks, and best practices to aid researchers, data scientists, and machine learning practitioners in adapting pre-trained models to specific tasks and domains. The resources cover a wide range of topics related to fine-tuning LLMs, providing valuable insights and guidelines to streamline the process and enhance model performance.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.
Auto-Data
Auto Data is a library designed for the automatic generation of realistic datasets, essential for the fine-tuning of Large Language Models (LLMs). This highly efficient and lightweight library enables the swift and effortless creation of comprehensive datasets across various topics, regardless of their size. It addresses challenges encountered during model fine-tuning due to data scarcity and imbalance, ensuring models are trained with sufficient examples.

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.
agent-contributions-library
The AI Agents Contributions Library is a repository dedicated to managing datasets on voice and cognitive core data for AI agents within the Virtual DAO ecosystem. It provides a structured framework for recording, reviewing, and rewarding contributions from contributors. The repository includes folders for character cards, contribution datasets, fine-tuning resources, text datasets, and voice datasets. Contributors can submit datasets following specific guidelines and formats, and the Virtual DAO team reviews and integrates approved datasets to enhance AI agents' capabilities.
felafax
Felafax is a framework designed to tune LLaMa3.1 on Google Cloud TPUs for cost efficiency and seamless scaling. It provides a Jupyter notebook for continued-training and fine-tuning open source LLMs using XLA runtime. The goal of Felafax is to simplify running AI workloads on non-NVIDIA hardware such as TPUs, AWS Trainium, AMD GPU, and Intel GPU. It supports various models like LLaMa-3.1 JAX Implementation, LLaMa-3/3.1 PyTorch XLA, and Gemma2 Models optimized for Cloud TPUs with full-precision training support.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.

Hands-On-Large-Language-Models
Hands-On Large Language Models is a repository containing code examples from the book 'The Illustrated LLM Book' by Jay Alammar and Maarten Grootendorst. The repository provides practical tools and concepts for using Large Language Models with over 250 custom-made figures. It covers topics such as language model introduction, tokens and embeddings, transformer LLMs, text classification, text clustering, prompt engineering, text generation techniques, semantic search, multimodal LLMs, text embedding models, fine-tuning representation models, and fine-tuning generation models. The examples are designed to be run on Google Colab with T4 GPU support, but can be adapted to other cloud platforms as well.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
awesome-flux-ai
Awesome Flux AI is a curated list of resources, tools, libraries, and applications related to Flux AI technology. It serves as a comprehensive collection for developers, researchers, and enthusiasts interested in Flux AI. The platform offers open-source text-to-image AI models developed by Black Forest Labs, aiming to advance generative deep learning models for media, creativity, efficiency, and diversity.
flux-fine-tuner
This is a Cog training model that creates LoRA-based fine-tunes for the FLUX.1 family of image generation models. It includes features such as automatic image captioning during training, image generation using LoRA, uploading fine-tuned weights to Hugging Face, automated test suite for continuous deployment, and Weights and biases integration. The tool is designed for users to fine-tune Flux models on Replicate for image generation tasks.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.
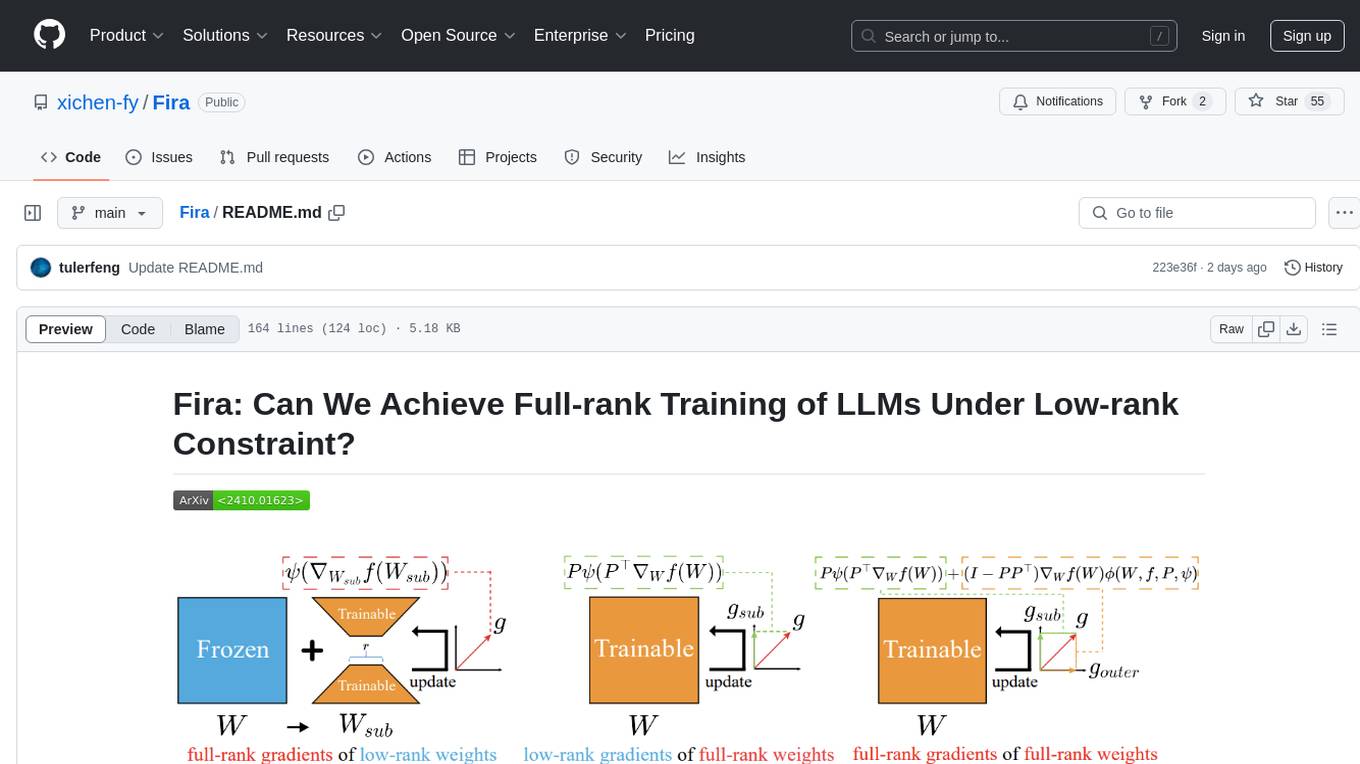
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.

AutoPatent
AutoPatent is a multi-agent framework designed for automatic patent generation. It challenges large language models to generate full-length patents based on initial drafts. The framework leverages planner, writer, and examiner agents along with PGTree and RRAG to craft lengthy, intricate, and high-quality patent documents. It introduces a new metric, IRR (Inverse Repetition Rate), to measure sentence repetition within patents. The tool aims to streamline the patent generation process by automating the creation of detailed and specialized patent documents.
LLMForEverybody
LLMForEverybody is a comprehensive repository covering various aspects of large language models (LLMs) including pre-training, architecture, optimizers, activation functions, attention mechanisms, tokenization, parallel strategies, training frameworks, deployment, fine-tuning, quantization, GPU parallelism, prompt engineering, agent design, RAG architecture, enterprise deployment challenges, evaluation metrics, and current hot topics in the field. It provides detailed explanations, tutorials, and insights into the workings and applications of LLMs, making it a valuable resource for researchers, developers, and enthusiasts interested in understanding and working with large language models.
LLMInterviewQuestions
LLMInterviewQuestions is a repository containing over 100+ interview questions for Large Language Models (LLM) used by top companies like Google, NVIDIA, Meta, Microsoft, and Fortune 500 companies. The questions cover various topics related to LLMs, including prompt engineering, retrieval augmented generation, chunking, embedding models, internal working of vector databases, advanced search algorithms, language models internal working, supervised fine-tuning of LLM, preference alignment, evaluation of LLM system, hallucination control techniques, deployment of LLM, agent-based system, prompt hacking, and miscellaneous topics. The questions are organized into 15 categories to facilitate learning and preparation.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

ai-enablement-stack
The AI Enablement Stack is a curated collection of venture-backed companies, tools, and technologies that enable developers to build, deploy, and manage AI applications. It provides a structured view of the AI development ecosystem across five key layers: Agent Consumer Layer, Observability and Governance Layer, Engineering Layer, Intelligence Layer, and Infrastructure Layer. Each layer focuses on specific aspects of AI development, from end-user interaction to model training and deployment. The stack aims to help developers find the right tools for building AI applications faster and more efficiently, assist engineering leaders in making informed decisions about AI infrastructure and tooling, and help organizations understand the AI development landscape to plan technology adoption.
awesome-generative-ai-data-scientist
A curated list of 50+ resources to help you become a Generative AI Data Scientist. This repository includes resources on building GenAI applications with Large Language Models (LLMs), and deploying LLMs and GenAI with Cloud-based solutions.
LLMLanding
LLMLanding is a repository focused on practical implementation of large models, covering topics from theory to practice. It provides a structured learning path for training large models, including specific tasks like training 1B-scale models, exploring SFT, and working on specialized tasks such as code generation, NLP tasks, and domain-specific fine-tuning. The repository emphasizes a dual learning approach: quickly applying existing tools for immediate output benefits and delving into foundational concepts for long-term understanding. It offers detailed resources and pathways for in-depth learning based on individual preferences and goals, combining theory with practical application to avoid overwhelm and ensure sustained learning progress.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.

BTGenBot
BTGenBot is a tool that generates behavior trees for robots using lightweight large language models (LLMs) with a maximum of 7 billion parameters. It fine-tunes on a specific dataset, compares multiple LLMs, and evaluates generated behavior trees using various methods. The tool demonstrates the potential of LLMs with a limited number of parameters in creating effective and efficient robot behaviors.
ai-tutor-rag-system
The AI Tutor RAG System repository contains Jupyter notebooks supporting the RAG course, focusing on enhancing AI models with retrieval-based methods. It covers foundational and advanced concepts in retrieval-augmented generation, including data retrieval techniques, model integration with retrieval systems, and practical applications of RAG in real-world scenarios.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.
LLMs-Zero-to-Hero
LLMs-Zero-to-Hero is a repository dedicated to training large language models (LLMs) from scratch, covering topics such as dense models, MOE models, pre-training, supervised fine-tuning, direct preference optimization, reinforcement learning from human feedback, and deploying large models. The repository provides detailed learning notes for different chapters, code implementations, and resources for training and deploying LLMs. It aims to guide users from being beginners to proficient in building and deploying large language models.
llama-cookbook
The Llama Cookbook is the official guide for building with Llama Models, providing resources for inference, fine-tuning, and end-to-end use-cases of Llama Text and Vision models. The repository includes popular community approaches, use-cases, and recipes for working with Llama models. It covers topics such as multimodal inference, inferencing using Llama Guard, and specific tasks like Email Agent and Text to SQL. The structure includes sections for 3P Integrations, End to End Use Cases, Getting Started guides, and the source code for the original llama-recipes library.
RAGMeUp
RAG Me Up is a generic framework that enables users to perform Retrieve, Answer, Generate (RAG) on their own dataset easily. It consists of a small server and UIs for communication. The tool can run on CPU but is optimized for GPUs with at least 16GB of vRAM. Users can combine RAG with fine-tuning using the LLaMa2Lang repository. The tool provides a configurable RAG pipeline without the need for coding, utilizing indexing and inference steps to accurately answer user queries.

together-cookbook
The Together Cookbook is a collection of code and guides designed to help developers build with open source models using Together AI. The recipes provide examples on how to chain multiple LLM calls, create agents that route tasks to specialized models, run multiple LLMs in parallel, break down tasks into parallel subtasks, build agents that iteratively improve responses, perform LoRA fine-tuning and inference, fine-tune LLMs for repetition, improve summarization capabilities, fine-tune LLMs on multi-step conversations, implement retrieval-augmented generation, conduct multimodal search and conditional image generation, visualize vector embeddings, improve search results with rerankers, implement vector search with embedding models, extract structured text from images, summarize and evaluate outputs with LLMs, generate podcasts from PDF content, and get LLMs to generate knowledge graphs.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
CodeGen
CodeGen is an official release of models for Program Synthesis by Salesforce AI Research. It includes CodeGen1 and CodeGen2 models with varying parameters. The latest version, CodeGen2.5, outperforms previous models. The tool is designed for code generation tasks using large language models trained on programming and natural languages. Users can access the models through the Hugging Face Hub and utilize them for program synthesis and infill sampling. The accompanying Jaxformer library provides support for data pre-processing, training, and fine-tuning of the CodeGen models.
Kolo
Kolo is a lightweight tool for fast and efficient data generation, fine-tuning, and testing of Large Language Models (LLMs) on your local machine. It simplifies the fine-tuning and data generation process, runs locally without the need for cloud-based services, and supports popular LLM toolkits. Kolo is built using tools like Unsloth, Torchtune, Llama.cpp, Ollama, Docker, and Open WebUI. It requires Windows 10 OS or higher, Nvidia GPU with CUDA 12.1 capability, and 8GB+ VRAM, and 16GB+ system RAM. Users can join the Discord group for issues or feedback. The tool provides easy setup, training data generation, and integration with major LLM frameworks.
rlhf_thinking_model
This repository is a collection of research notes and resources focusing on training large language models (LLMs) and Reinforcement Learning from Human Feedback (RLHF). It includes methodologies, techniques, and state-of-the-art approaches for optimizing preferences and model alignment in LLM training. The purpose is to serve as a reference for researchers and engineers interested in reinforcement learning, large language models, model alignment, and alternative RL-based methods.
KG-LLM-MDQA
This repository contains code and demo for Knowledge Graph Prompting for Multi-Document Question Answering. It includes modules for data collection, training DPR and MDR models, fine-tuning T5 and LLaMA, and reproducing KGP-LLM algorithm. The workflow involves document collection, knowledge graph construction, fine-tuning models, and reproducing main table results. The repository provides instructions for environment setup, folder architecture, and running different modules.

second-brain-ai-assistant-course
This open-source course teaches how to build an advanced RAG and LLM system using LLMOps and ML systems best practices. It helps you create an AI assistant that leverages your personal knowledge base to answer questions, summarize documents, and provide insights. The course covers topics such as LLM system architecture, pipeline orchestration, large-scale web crawling, model fine-tuning, and advanced RAG features. It is suitable for ML/AI engineers and data/software engineers & data scientists looking to level up to production AI systems. The course is free, with minimal costs for tools like OpenAI's API and Hugging Face's Dedicated Endpoints. Participants will build two separate Python applications for offline ML pipelines and online inference pipeline.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.
Awesome-LLM-Resources-List
Awesome LLM Resources is a curated collection of resources for Large Language Models (LLMs) covering various aspects such as serverless hosting, accessing off-the-shelf models via API, local inference, LLM serving frameworks, open-source LLM web chat UIs, renting GPUs for fine-tuning, fine-tuning with no-code UI, fine-tuning frameworks, OS agentic/AI workflow, AI agents, co-pilots, voice API, open-source TTS models, OS RAG frameworks, research papers on chain-of-thought prompting, CoT implementations, CoT fine-tuned models & datasets, and more.
eairp
Next generation artificial intelligent ERP system. On the basis of ERP business, we have expanded GPT-3.5. Individually or company can fine-tune your model through our system. You can provide fully automated business form submission operations through your simple description, and you can chat, interact, and consult information with GPT. You can deploy through Docker to quickly start and use. Completely free project. Enginsh / 简体中文.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.
Ling
Ling is a MoE LLM provided and open-sourced by InclusionAI. It includes two different sizes, Ling-Lite with 16.8 billion parameters and Ling-Plus with 290 billion parameters. These models show impressive performance and scalability for various tasks, from natural language processing to complex problem-solving. The open-source nature of Ling encourages collaboration and innovation within the AI community, leading to rapid advancements and improvements. Users can download the models from Hugging Face and ModelScope for different use cases. Ling also supports offline batched inference and online API services for deployment. Additionally, users can fine-tune Ling models using Llama-Factory for tasks like SFT and DPO.
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.
Awesome-LLMOps
Awesome-LLMOps is a curated list of the best LLMOps tools, providing a comprehensive collection of frameworks and tools for building, deploying, and managing large language models (LLMs) and AI agents. The repository includes a wide range of tools for tasks such as building multimodal AI agents, fine-tuning models, orchestrating applications, evaluating models, and serving models for inference. It covers various aspects of the machine learning operations (MLOps) lifecycle, from training to deployment and observability. The tools listed in this repository cater to the needs of developers, data scientists, and machine learning engineers working with large language models and AI applications.
osm-ai-helper
OSM-AI-helper is a Blueprint by Mozilla.ai designed to assist users in mapping features in OpenStreetMap using object detection and image segmentation models. It provides tools for identifying and mapping various features, such as swimming pools, in OpenStreetMap. Users can also create custom datasets and fine-tune models for different use cases. The project is licensed under the AGPL-3.0 License and welcomes contributions from the community.
PhiCookBook
Phi Cookbook is a repository containing hands-on examples with Microsoft's Phi models, which are a series of open source AI models developed by Microsoft. Phi is currently the most powerful and cost-effective small language model with benchmarks in various scenarios like multi-language, reasoning, text/chat generation, coding, images, audio, and more. Users can deploy Phi to the cloud or edge devices to build generative AI applications with limited computing power.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.

amazon-sagemaker-llm-fine-tuning-remote-decorator
This repository provides interactive fine-tuning of Foundation Models with Amazon SageMaker Training using the @remote decorator. It showcases the use of SageMaker AI capabilities for Small/Large Language Models fine-tuning by employing different distribution techniques like FSDP and DDP. Users can run the repository from Amazon SageMaker Studio or a local IDE. The notebooks cover various supervised and self-supervised fine-tuning scenarios for different models, along with instructions for updating configurations based on the AWS region and Python version compatibility.
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
AI-fundermentals
AI Fundamentals is a comprehensive AI infrastructure learning resource collection, covering a complete technical stack from hardware basics to advanced applications. It includes GPU architecture and programming, CUDA development, large language models, AI system design, performance optimization, enterprise deployment, and more. The repository aims to provide a systematic learning path and practical guidance for AI engineers, architects, GPU programming developers, large model application developers, and technical researchers.
mini-swe-agent
The mini-swe-agent is a lightweight AI agent designed to solve GitHub issues and more. It is a minimal tool with just 100 lines of Python code, suitable for researchers, developers, and engineers looking for a simple, powerful, and deployable solution. The agent is built to be convenient, deployable in various environments, and tested for performance. It focuses on providing a hackable tool that is simple, convenient, and flexible, without unnecessary bloat or complexity. Users can run the agent with any model using bash, making it ideal for benchmarking, fine-tuning, and reinforcement learning tasks.

DeepFabric
Deepfabric is an SDK and CLI tool that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data. The key innovation lies in Deepfabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.
llm_model_hub
Model Hub V2 is a one-stop platform for model fine-tuning, deployment, and debugging without code, providing users with a visual interface to quickly validate the effects of fine-tuning various open-source models, facilitating rapid experimentation and decision-making, and lowering the threshold for users to fine-tune large models. For detailed instructions, please refer to the Feishu documentation.
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.

openai
An open-source client package that allows developers to easily integrate the power of OpenAI's state-of-the-art AI models into their Dart/Flutter applications. The library provides simple and intuitive methods for making requests to OpenAI's various APIs, including the GPT-3 language model, DALL-E image generation, and more. It is designed to be lightweight and easy to use, enabling developers to focus on building their applications without worrying about the complexities of dealing with HTTP requests. Note that this is an unofficial library as OpenAI does not have an official Dart library.
tunix
Tunix is a JAX-based library designed for post-training Large Language Models. It provides efficient support for supervised fine-tuning, reinforcement learning, and knowledge distillation. Tunix leverages JAX for accelerated computation and integrates seamlessly with the Flax NNX modeling framework. The library is modular, efficient, and designed for distributed training on accelerators like TPUs. Currently in early development, Tunix aims to expand its capabilities, usability, and performance.
lm-engine
LM Engine is a research-grade, production-ready library for training large language models at scale. It provides support for multiple accelerators including NVIDIA GPUs, Google TPUs, and AWS Trainiums. Key features include multi-accelerator support, advanced distributed training, flexible model architectures, HuggingFace integration, training modes like pretraining and finetuning, custom kernels for high performance, experiment tracking, and efficient checkpointing.
aikit
AIKit is a comprehensive platform for hosting, deploying, building, and fine-tuning large language models (LLMs). It offers inference using LocalAI, extensible fine-tuning interface, and OCI packaging for distributing models. AIKit supports various models, multi-modal model and image generation, Kubernetes deployment, and supply chain security. It can run on AMD64 and ARM64 CPUs, NVIDIA GPUs, and Apple Silicon (experimental). Users can quickly get started with AIKit without a GPU and access pre-made models. The platform is OpenAI API compatible and provides easy-to-use configuration for inference and fine-tuning.
base-llm
Base LLM is a comprehensive learning tutorial from traditional Natural Language Processing (NLP) to Large Language Models (LLM), covering core technologies such as word embeddings, RNN, Transformer architecture, BERT, GPT, and Llama series models. The project aims to help developers build a solid technical foundation by providing a clear path from theory to practical engineering. It covers NLP theory, Transformer architecture, pre-trained language models, advanced model implementation, and deployment processes.
llmxcpg
LLMxCPG is a framework for vulnerability detection using Code Property Graphs (CPG) and Large Language Models (LLM). It involves a two-phase process: Slice Construction where an LLM generates queries for a CPG to extract a code slice, and Vulnerability Detection where another LLM classifies the code slice as vulnerable or safe. The repository includes implementations of baseline models, information on datasets, scripts for running models, prompt templates, query generation examples, and configurations for fine-tuning models.
19 - OpenAI Gpts


HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch
Joke Smith | Joke Edits for Standup Comedy
A witty editor to fine-tune stand-up comedy jokes.
BrandChic Strategic
I'm Chic Strategic, your ally in carving out a distinct brand position and fine-tuning your voice. Let's make your brand's presence robust and its message clear in a bustling market.
AI绘画|画图|画画|超级绘图|牛逼dalle|painting
👉AI绘画,无视版权,精准创作提示词。👈1.可描述画面2.可给出midjourney的绘画提示词3.为每幅画作指定专属 ID,便于精调4.可以画绘制皮克斯拟人可爱动物。1. Can describe the picture . 2. Can give the prompt words for midjourney's painting . 3. Assign a unique ID to each painting to facilitate fine-tuning
Fine dining cuisine Chef (with images)
A Michelin-starred chef offering French-style plating and recipes.

Boundary Coach
Boundary Coach is now fine-tuned and ready for use! It's an advanced guide for assertive boundary setting, offering nuanced advice, practical tips, and interactive exercises. It will provide tailored guidance, avoiding medical or legal advice and suggesting professional help when needed.
Secret Somm
Enter the world of Secret Somm, where intrigue and fine wine meet. Whether you're a rookie or a connoisseur, your personal wine agent awaits—ready to unveil the secrets of the perfect pour. Your mission, should you choose to accept it, will lead to unparalleled wine discoveries.

The Magic Money Tree
Tell us your favourite animal and let us create some fine banknotes for you !
Prompt QA
Designed for excellence in Quality Assurance, fine-tuning custom GPT configurations through continuous refinement.
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)
Music Production Teacher
It acts as an instructor guiding you through music production skills, such as fine-tuning parameters in mixing, mastering, and compression. Additionally, it functions as an aide, offering advice for your music production hurdles with just a screenshot of your production or parameter settings.
Copywriter GPT
Your innovative partner for viral ad copywriting! Dive into viral marketing strategies fine-tuned to your needs!