
green-bit-llm
A toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's LLMs.
Stars: 78
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
README:
A toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit LLMs.
This Python package uses the Bitorch Engine for efficient operations on GreenBitAI's Low-bit Language Models (LLMs). It enables high-performance inference on both cloud-based and consumer-level GPUs, and supports full-parameter fine-tuning directly using quantized LLMs. Additionally, you can use our provided evaluation tools to validate the model's performance on mainstream benchmark datasets.
- [2024/10]
- Langchain integration, various refactoring and improvements.
- [2024/04]
- We have launched over 200 low-bit LLMs in GreenBitAI's Hugging Face Model Zoo. Our release includes highly precise 2.2/2.5/3-bit models across the LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, Gemma, and more.
- We released Bitorch Engine for low-bit quantized neural network operations. Our release support full parameter fine-tuning and parameter efficiency fine-tuning (PEFT), even under extremely constrained GPU resource conditions.
- We released gbx-lm python package which enables the efficient execution of GreenBitAI's low-bit models on Apple devices with MLX.
We have released over 200 highly precise 2.2/2.5/3/4-bit models across the modern LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, and more.
| Family | Bpw | Size | HF collection_id |
|---|---|---|---|
| Llama-3 | 4.0/3.0/2.5/2.2 |
8B/70B |
GreenBitAI Llama-3 |
| Llama-2 | 3.0/2.5/2.2 |
7B/13B/70B |
GreenBitAI Llama-2 |
| Qwen-1.5 | 4.0/3.0/2.5/2.2 |
0.5B/1.8B/4B/7B/14B/32B/110B |
GreenBitAI Qwen 1.5 |
| Phi-3 | 3.0/2.5/2.2 |
mini |
GreenBitAI Phi-3 |
| Mistral | 3.0/2.5/2.2 |
7B |
GreenBitAI Mistral |
| 01-Yi | 3.0/2.5/2.2 |
6B/34B |
GreenBitAI 01-Yi |
| Llama-3-instruct | 4.0/3.0/2.5/2.2 |
8B/70B |
GreenBitAI Llama-3 |
| Mistral-instruct | 3.0/2.5/2.2 |
7B |
GreenBitAI Mistral |
| Phi-3-instruct | 3.0/2.5/2.2 |
mini |
GreenBitAI Phi-3 |
| Qwen-1.5-Chat | 4.0/3.0/2.5/2.2 |
0.5B/1.8B/4B/7B/14B/32B/110B |
GreenBitAI Qwen 1.5 |
| 01-Yi-Chat | 3.0/2.5/2.2 |
6B/34B |
GreenBitAI 01-Yi |
In addition to our low-bit models, green-bit-llm is fully compatible with the AutoGPTQ series of 4-bit quantization and compression models.
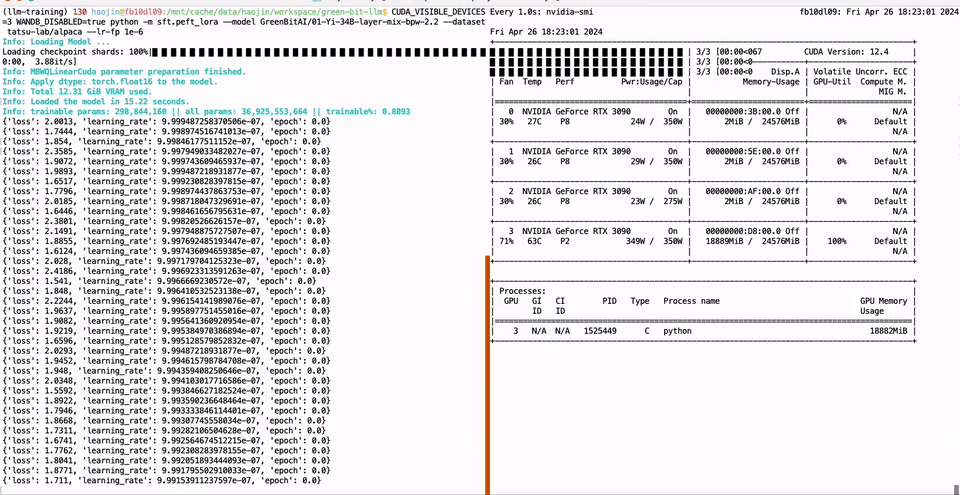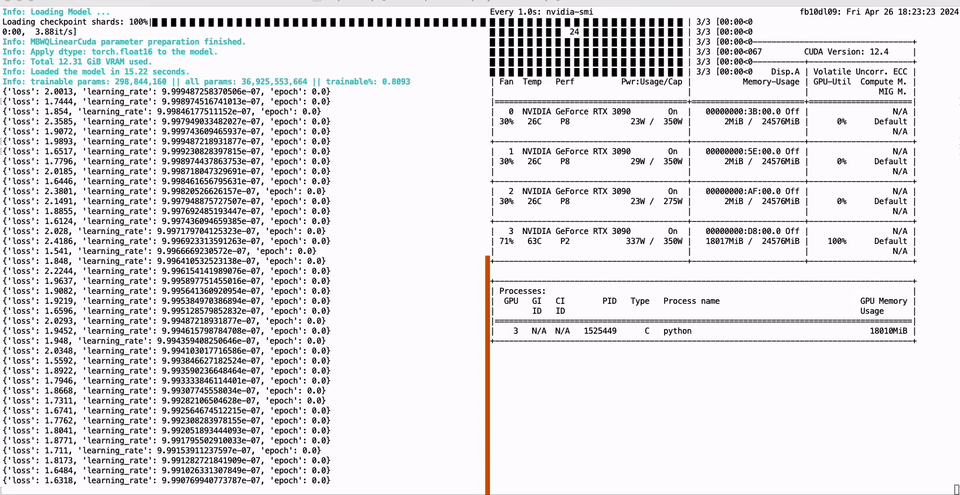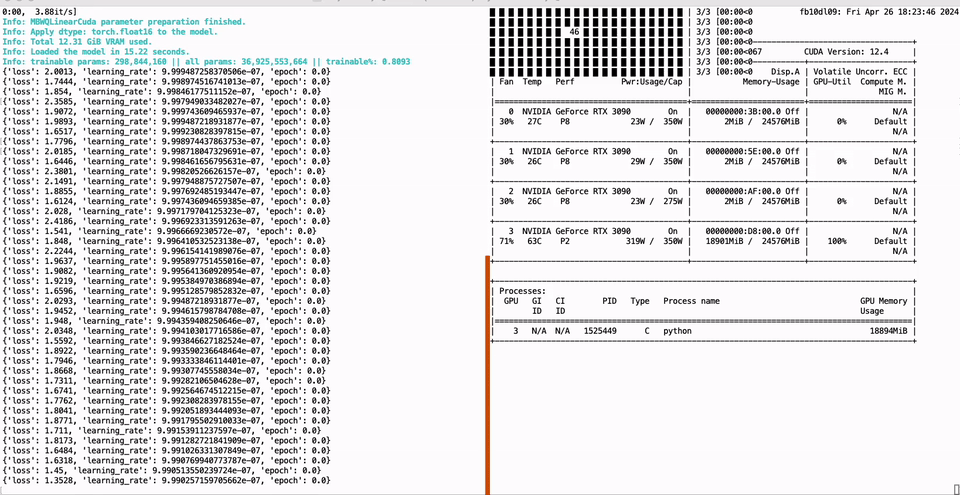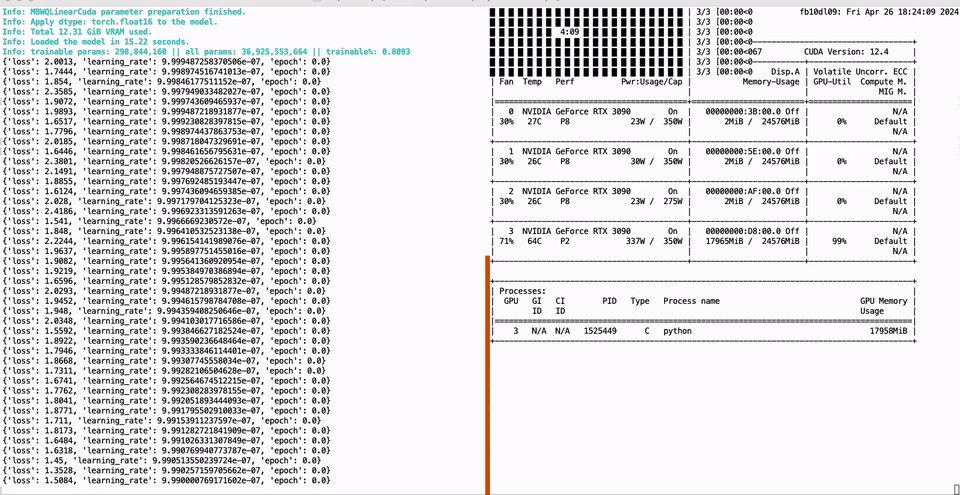
Full parameter fine-tuning of the LLaMA-3 8B model using a single GTX 3090 GPU with 24GB of graphics memory:
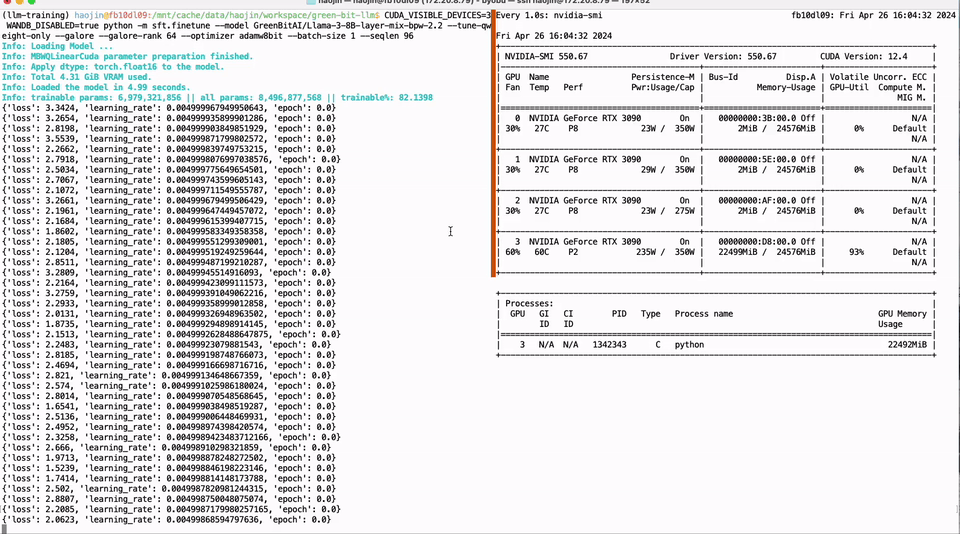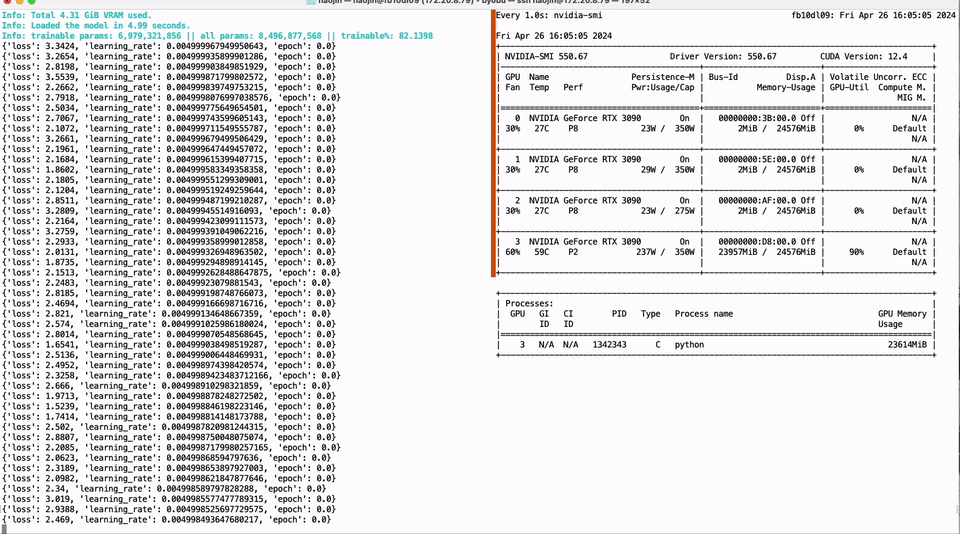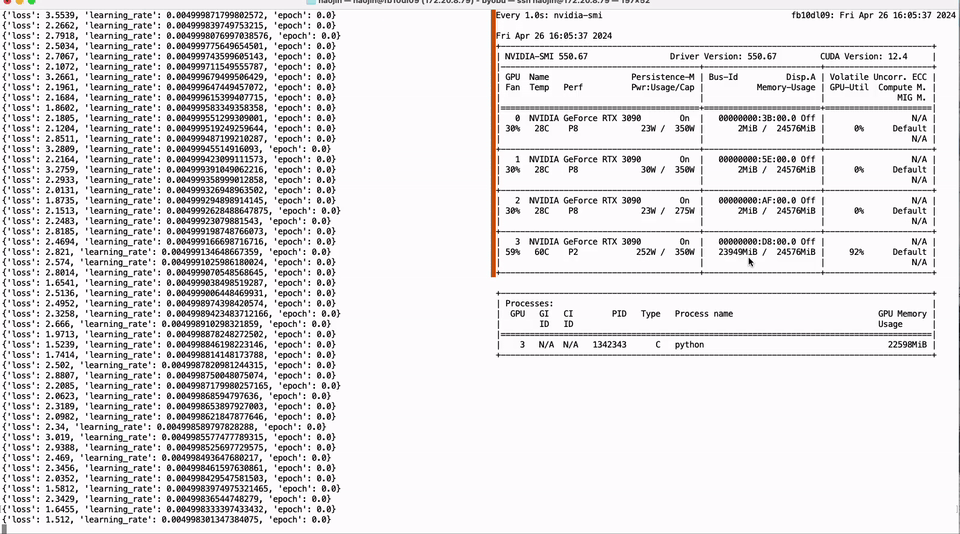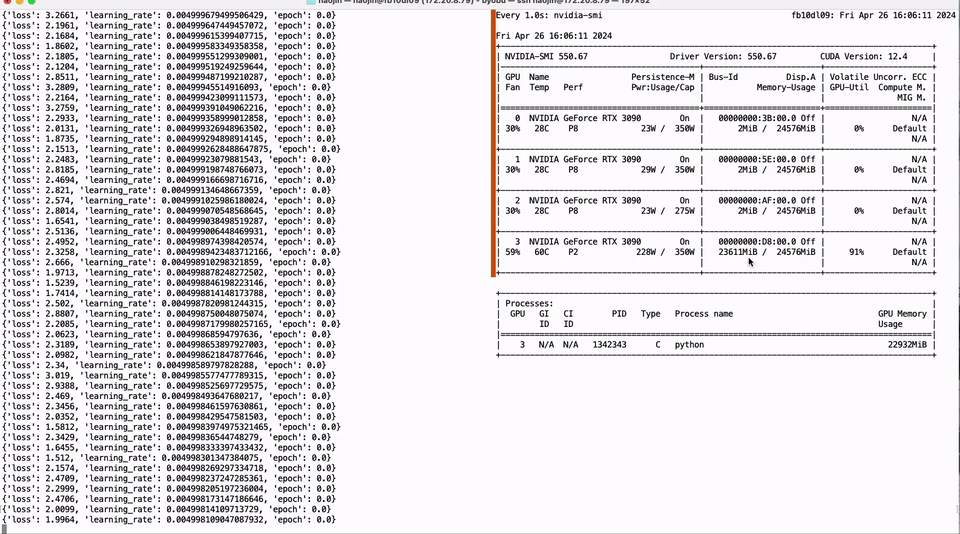
PEFT of the 01-Yi 34B model using a single GTX 3090 GPU with 24GB of graphics memory:
We support several ways to install this package. Except for the docker method, you should first install Bitorch Engine according to the official instructions.
Then choose how you want to install it:
pip install green-bit-llmClone the repository and install the required dependencies (for Python >= 3.9):
git clone https://github.com/GreenBitAI/green-bit-llm.git
pip install -r requirements.txtAfterward, install Flash Attention (flash-attn) according to their official instructions.
Alternatively, you can also use the prepared conda environment configuration:
conda env create -f environment.yml
conda activate gbai_cuda_lmAfterward, install Flash Attention (flash-attn) according to their official instructions.
Alternatively you can activate an existing conda environment and install the requirements with pip (as shown in the previous section).
To use docker, you can also use the provided Dockerfile which extends the bitorch-engine docker image.
Build the bitorch-engine image first, then run the following commands:
cd docker
cp -f ../requirements.txt .
docker build -t gbai/green-bit-llm .
docker run -it --rm --gpus all gbai/green-bit-llmCheck the docker readme for options and more details.
Please see the description of the Inference package for details.
Please see the description of the Evaluation package for details.
Please see the description of the sft package for details.
- Python 3.x
- Bitorch Engine
- See
requirements.txtorenvironment.ymlfor a complete list of dependencies
Run the simple generation script as follows:
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.sim_gen --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --max-tokens 100 --use-flash-attention-2 --ignore-chat-templateCUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.evaluation.evaluate --model GreenBitAI/Qwen-1.5-4B-layer-mix-bpw-3.0 --trust-remote-code --eval-ppl --ppl-tasks wikitext2,c4_new,ptbRun the script as follows to fine-tune the quantized weights of the model on the target dataset. The '--tune-qweight-only' parameter determines whether to fine-tune only the quantized weights or all weights, including non-quantized ones.
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --optimizer DiodeMix --tune-qweight-only
# AutoGPTQ model Q-SFT
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --tune-qweight-only --batch-size 1CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --lr-fp 1e-6
# AutoGPTQ model with Lora
CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --lr-fp 1e-6We release our codes under the Apache 2.0 License. Additionally, three packages are also partly based on third-party open-source codes. For detailed information, please refer to the description pages of the sub-projects.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for green-bit-llm
Similar Open Source Tools
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.
manim-generator
The 'manim-generator' repository focuses on automatic video generation using an agentic LLM flow combined with the manim python library. It experiments with automated Manim video creation by delegating code drafting and validation to specific roles, reducing render failures, and improving visual consistency through iterative feedback and vision inputs. The project also includes 'Manim Bench' for comparing AI models on full Manim video generation.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.
Online-RLHF
This repository, Online RLHF, focuses on aligning large language models (LLMs) through online iterative Reinforcement Learning from Human Feedback (RLHF). It aims to bridge the gap in existing open-source RLHF projects by providing a detailed recipe for online iterative RLHF. The workflow presented here has shown to outperform offline counterparts in recent LLM literature, achieving comparable or better results than LLaMA3-8B-instruct using only open-source data. The repository includes model releases for SFT, Reward model, and RLHF model, along with installation instructions for both inference and training environments. Users can follow step-by-step guidance for supervised fine-tuning, reward modeling, data generation, data annotation, and training, ultimately enabling iterative training to run automatically.
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.
TinyLLM
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.
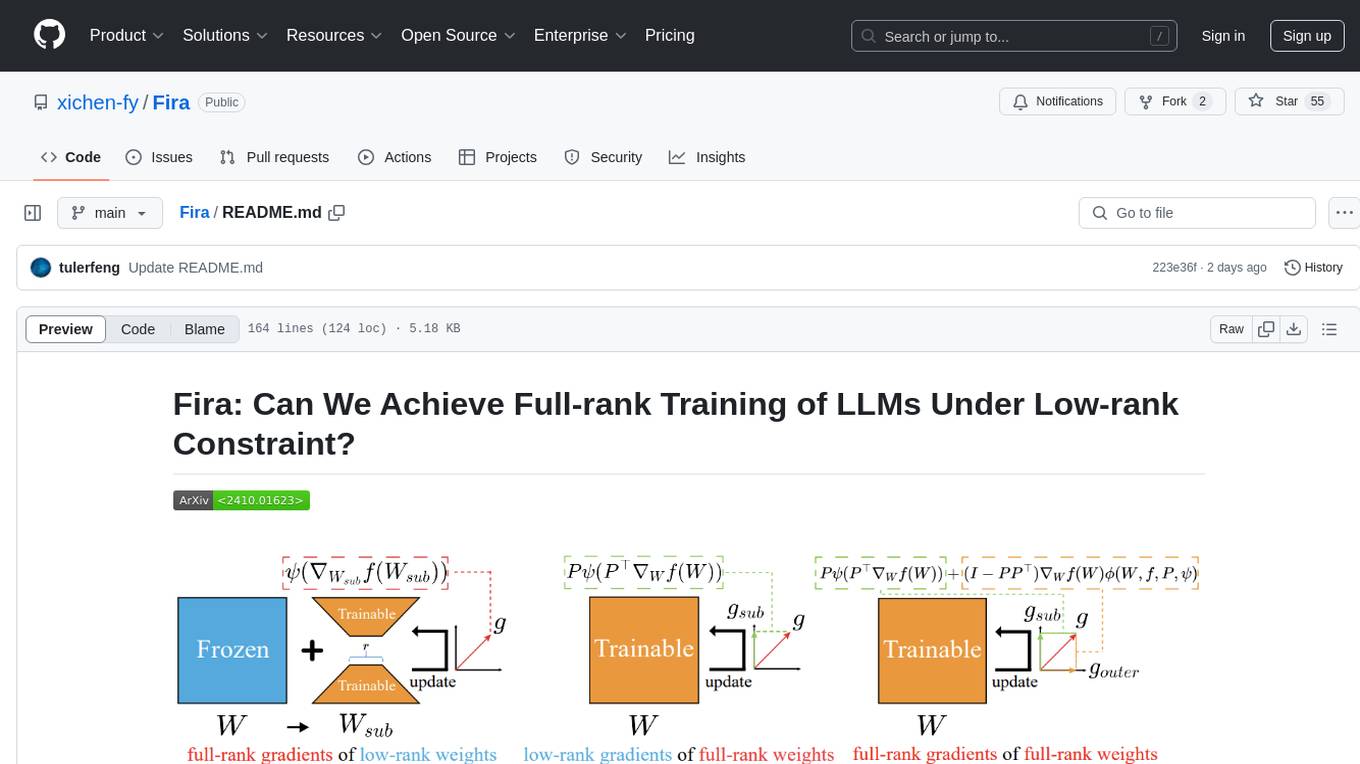
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.
MockingBird
MockingBird is a toolbox designed for Mandarin speech synthesis using PyTorch. It supports multiple datasets such as aidatatang_200zh, magicdata, aishell3, and data_aishell. The toolbox can run on Windows, Linux, and M1 MacOS, providing easy and effective speech synthesis with pretrained encoder/vocoder models. It is webserver ready for remote calling. Users can train their own models or use existing ones for the encoder, synthesizer, and vocoder. The toolbox offers a demo video and detailed setup instructions for installation and model training.
iloom-cli
iloom is a tool designed to streamline AI-assisted development by focusing on maintaining alignment between human developers and AI agents. It treats context as a first-class concern, persisting AI reasoning in issue comments rather than temporary chats. The tool allows users to collaborate with AI agents in an isolated environment, switch between complex features without losing context, document AI decisions publicly, and capture key insights and lessons learned from AI sessions. iloom is not just a tool for managing git worktrees, but a control plane for maintaining alignment between users and their AI assistants.
For similar tasks

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.