
LongLoRA
Code and documents of LongLoRA and LongAlpaca (ICLR 2024 Oral)
Stars: 2573

LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.
README:

- News
- Highlights
- How to contribute
- Requirements
- Installation and quick guide
- LongAlpaca Data
- Models
- Training
- Evaluation
- Demo
- Streaming Inference
- Data Generation via Pdf2Text
- Examples
- Citation
- Acknowledgement
- License
- [x] [2024.1.17] LongLoRA has been accepted by ICLR 2024 as an Oral presentation.
- [x] [2023.11.19] We release a new version of LongAlpaca models, LongAlpaca-7B-16k, LongAlpaca-7B-16k, and LongAlpaca-7B-16k. These models are fine-tuned on a subset LongAlpaca-12k dataset with LongLoRA in SFT, LongAlpaca-16k-length. We evaluate the LongAlpaca-7B-16k model on LongBench and L-Eval benchmarks and results can be found here.
- [x] [2023.11.2] We have updated our LongAlpaca models from alpaca prompting to llama2 prompting, which is consistent to their pre-trained models. Please refer to the inference code with the llama2 prompting.
- [x] [2023.10.23] We support the combination of QLoRA and LongLoRA in the supervised fine-tuning, for further reduction of the GPU memory cost. We release the LoRA weights of a 7B model at LongAlpaca-7B-qlora-weights.
- [x] [2023.10.18] We support StreamingLLM inference on our LongAlpaca models. This increases the context-length of the multi-round dialogue in StreamingLLM.
- [x] [2023.10.8] We release the long instruction-following dataset, LongAlpaca-12k and the corresponding models, LongAlpaca-7B, LongAlpaca-13B, and LongAlpaca-70B.
- (The previous sft models, Llama-2-13b-chat-longlora-32k-sft and Llama-2-70b-chat-longlora-32k-sft, have been deprecated.)
- [x] [2023.10.3] We add support GPTNeoX models. Please refer to this PR for usage. Thanks for @naubull2 for this contribution.
- [x] [2023.9.22] We release all our fine-tuned models, including 70B-32k models, LLaMA2-LongLoRA-70B-32k, LLaMA2-LongLoRA-7B-100k. Welcome to check them out!
- [x] [2023.9.22] We release Paper and this GitHub repo, including training and evaluation code.
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models [Paper]
Yukang Chen,
Shengju Qian,
Haotian Tang,
Xin Lai,
Zhijian Liu,
Song Han,
Jiaya Jia
- In LongLoRA approach, The proposed shifted short attention is easy to implement, compatible with Flash-Attention, and is not required during inference.
- We released all our models, including models from 7B to 70B, context length from 8k to 100k, including LLaMA2-LongLoRA-7B-100k, LLaMA2-LongLoRA-13B-64k, and LLaMA2-LongLoRA-70B-32k.
- We built up a long-context instruction-following dataset, LongAlpaca-12k. We released the corresponding LongAlpaca-7B, LongAlpaca-13B and LongAlpaca-70B models. To our best knowledge, this is the first open-sourced long-context 70B model.
- Make sure to have git installed.
- Create your own fork of the project.
- Clone the repository on your local machine, using git clone and pasting the url of this project.
- Read both the
RequirementsandInstallation and Quick Guidesections below. - Commit and push your changes.
- Make a pull request when finished modifying the project.
To download and use the pre-trained weights you will need:
- Hugging Face (HF) account with valid email. Note, the email used for HF must alse be used for the license agreement.
- Accept the Meta license and acceptable use policy
To install and run the application:
- Fork this repo on github
- Clone the repository on your local machine, using git clone and pasting the url of this project.
- Run the following code:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
- Use either a Released model or Fine tune a model to fit your preferences.
- Test your model by chat.
- Deploy your own demo.
LongAlpaca-12k contains 9k long QA data that we collected and 3k short QA sampled from the original Alpaca data. This is to avoid the case that the model might degrade at short instruction following. The data we collect contains various types and amounts as the following figure.

| Data | Short QA | Long QA | Total | Download |
|---|---|---|---|---|
| LongAlpaca-12k | 3k | 9k | 12k | Link |
Following the original Alpaca format, our Long QA data uses the following prompts for fine-tuning:
-
instruction:str, describes the task the model should perform. For example, to answer a question after reading a book section or paper. We vary the contents and questions to make instructions diverse. -
output:str, the answer to the instruction.
We did not use the input format in the Alpaca format for simplicity.
| Model | Size | Context | Train | Link |
|---|---|---|---|---|
| LongAlpaca-7B | 7B | 32768 | Full FT | Model |
| LongAlpaca-13B | 13B | 32768 | Full FT | Model |
| LongAlpaca-70B | 70B | 32768 | LoRA+ | Model (LoRA-weight) |
| Model | Size | Context | Train | Link |
|---|---|---|---|---|
| Llama-2-7b-longlora-8k-ft | 7B | 8192 | Full FT | Model |
| Llama-2-7b-longlora-16k-ft | 7B | 16384 | Full FT | Model |
| Llama-2-7b-longlora-32k-ft | 7B | 32768 | Full FT | Model |
| Llama-2-7b-longlora-100k-ft | 7B | 100000 | Full FT | Model |
| Llama-2-13b-longlora-8k-ft | 13B | 8192 | Full FT | Model |
| Llama-2-13b-longlora-16k-ft | 13B | 16384 | Full FT | Model |
| Llama-2-13b-longlora-32k-ft | 13B | 32768 | Full FT | Model |
| Model | Size | Context | Train | Link |
|---|---|---|---|---|
| Llama-2-7b-longlora-8k | 7B | 8192 | LoRA+ | LoRA-weight |
| Llama-2-7b-longlora-16k | 7B | 16384 | LoRA+ | LoRA-weight |
| Llama-2-7b-longlora-32k | 7B | 32768 | LoRA+ | LoRA-weight |
| Llama-2-13b-longlora-8k | 13B | 8192 | LoRA+ | LoRA-weight |
| Llama-2-13b-longlora-16k | 13B | 16384 | LoRA+ | LoRA-weight |
| Llama-2-13b-longlora-32k | 13B | 32768 | LoRA+ | LoRA-weight |
| Llama-2-13b-longlora-64k | 13B | 65536 | LoRA+ | LoRA-weight |
| Llama-2-70b-longlora-32k | 70B | 32768 | LoRA+ | LoRA-weight |
| Llama-2-70b-chat-longlora-32k | 70B | 32768 | LoRA+ | LoRA-weight |
We use LLaMA2 models as the pre-trained weights and fine-tune them to long context window sizes. Download based on your choices.
| Pre-trained weights |
|---|
| Llama-2-7b-hf |
| Llama-2-13b-hf |
| Llama-2-70b-hf |
| Llama-2-7b-chat-hf |
| Llama-2-13b-chat-hf |
| Llama-2-70b-chat-hf |
This project also supports GPTNeoX models as the base model architecture. Some candidate pre-trained weights may include GPT-NeoX-20B, Polyglot-ko-12.8B and other variants.
torchrun --nproc_per_node=8 fine-tune.py \
--model_name_or_path path_to/Llama-2-7b-hf \
--bf16 True \
--output_dir path_to_saving_checkpoints \
--cache_dir path_to_cache \
--model_max_length 8192 \
--use_flash_attn True \
--low_rank_training False \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--weight_decay 0.0 \
--warmup_steps 20 \
--lr_scheduler_type "constant_with_warmup" \
--logging_steps 1 \
--deepspeed "ds_configs/stage2.json" \
--tf32 True \
--max_steps 1000
- Please remember to change
path_to/Llama-2-7b-hf,path_to_saving_checkpoints,path_to_cacheto your own directory. - Note that you can change
model_max_lengthto other values. - You could change
ds_configs/stage2.jsontods_configs/stage3.jsonif you want. - Please set
use_flash_attnasFalseif you use V100 machines or do not install flash attention. - You can set
low_rank_trainingasFalseif you want to use fully fine-tuning. It will cost more GPU memory and slower, but the performance will be a bit better. - When training is finished, to get the full model weight:
cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Note that the path_to_saving_checkpoints might be the global_step directory, which depends on the deepspeed versions.
torchrun --nproc_per_node=8 supervised-fine-tune.py \
--model_name_or_path path_to_Llama2_chat_models \
--bf16 True \
--output_dir path_to_saving_checkpoints \
--model_max_length 16384 \
--use_flash_attn True \
--data_path LongAlpaca-16k-length.json \
--low_rank_training True \
--num_train_epochs 5 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 98 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--weight_decay 0.0 \
--warmup_steps 20 \
--lr_scheduler_type "constant_with_warmup" \
--logging_steps 1 \
--deepspeed "ds_configs/stage2.json" \
--tf32 True
- There is no need to make supervised fine-tuning upon the fine-tuned context extended models. It is all right to directly use base model as Llama2-chat models, as the amount of long instruction following data is enough for SFT.
- Our long instruction following data can be found in LongAlpaca-12k.json.
- Note that supervised-fine-tune.py can be replaced by supervised-fine-tune-qlora.py if you want to try 4-bit quantized fine-tuning for further GPU memory reduction. This follows QLoRA.
- If you meet issue for saving pytorch_model.bin after the qlora sft, please refer to this issue.
In low-rank training, we set embedding and normalization layers as trainable. Please use the following line to extract the trainable weights trainable_params.bin from pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Merge the LoRA weights of pytorch_model.bin and trainable parameters trainable_params.bin, save the resulting model into your desired path in the Hugging Face format:
python3 merge_lora_weights_and_save_hf_model.py \
--base_model path_to/Llama-2-7b-hf \
--peft_model path_to_saving_checkpoints \
--context_size 8192 \
--save_path path_to_saving_merged_model
For example,
python3 merge_lora_weights_and_save_hf_model.py \
--base_model /dataset/pretrained-models/Llama-2-7b-hf \
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k \
--context_size 8192 \
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
To evaluate a model that is trained in the low-rank setting, please set both base_model and peft_model. base_model is the pre-trained weight. peft_model is the path to the saved checkpoint, which should contain trainable_params.bin, adapter_model.bin and adapter_config.json. For example,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Or evaluate with multiple GPUs as follows.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
To evaluate a model that is fully fine-tuned, you only need to set base_model as the path to the saved checkpoint, which should contain pytorch_model.bin and config.json. peft_model should be ignored.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Or evaluate with multiple GPUs as follows.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
-
Note that
--seq_lenis to set the sequence length for evaluation.--context_sizeis to set the context length of the model during fine-tuning.--seq_lenshould not be larger than--context_size. -
We have already tokenized the validation and test splits of PG19 and proof-pile dataset into
pg19/validation.bin,pg19/test.bin, andproof-pile/test_sampled_data.bin, with the tokenizer of LLaMA.proof-pile/test_sampled_data.bincontains 128 documents that are randomly sampled from the total proof-pile test split. For each document, it has at least 32768 tokens. We also release the sampled ids in proof-pile/test_sampled_ids.bin. You can download them from the links below.
| Dataset | Split | Link |
|---|---|---|
| PG19 | validation | pg19/validation.bin |
| PG19 | test | pg19/test.bin |
| Proof-pile | test | proof-pile/test_sampled_data.bin |
We provide a manner to test the passkey retrieval accuracy. For example,
python3 passkey_retrivial.py \
--context_size 32768 \
--base_model path_to/Llama-2-7b-longlora-32k \
--max_tokens 32768 \
--interval 1000
- Note that the
context_sizeis the context length during fine-tuning. -
max_tokensis maximum length for the document in passkey retrieval evaluation. -
intervalis the interval during the document length increasing. It is a rough number because the document increases by sentences.
To chat with LongAlpaca models,
python3 inference.py \
--base_model path_to_model \
--question $question \
--context_size $context_length \
--max_gen_len $max_gen_len \
--flash_attn True \
--material $material_content
To ask a question related to a book:
python3 inference.py \
--base_model /data/models/LongAlpaca-13B \
--question "Why doesn't Professor Snape seem to like Harry?" \
--context_size 32768 \
--max_gen_len 512 \
--flash_attn True \
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
To ask a question related to a paper:
python3 inference.py \
--base_model /data/models/LongAlpaca-13B \
--question "What are the main contributions and novelties of this work?" \
--context_size 32768 \
--max_gen_len 512 \
--flash_attn True \
--material "materials/paper1.txt"
- Note that inference.py can be replaced by inference-qlora.py if you want to try 4-bit quantized fine-tuning for further GPU memory reduction. This follows QLoRA.
To deploy your own demo run
python3 demo.py \
--base_model path_to_model \
--context_size $context_size \
--max_gen_len $max_gen_len \
--flash_attn True
Example
python3 demo.py \
--base_model /data/models/LongAlpaca-13B \
--context_size 32768 \
--max_gen_len 512 \
--flash_attn True
- Note that
flash_attn=Truewill make the generation slow but save much GPU memory.
We support the inference of LongAlpaca models with StreamingLLM. This increases the context-length of the multi-round dialogue in StreamingLLM. Here is an example,
python run_streaming_llama_longalpaca.py \
----enable_streaming \
--test_filepath outputs_stream.json \
--use_flash_attn True \
--recent_size 32768
- Note that please use a smaller recent_size if you meet OOM issues, for example 8192.
-
test_filepathis the json file that contains prompts for inference. We provide an example file outputs_stream.json, which is a subset of LongAlpaca-12k. You can replace it to your own questions.
During our dataset collection, we convert paper and books from pdf to text. The conversion quality has a large influence on the final model quality. We think that this step is non-trivial. We release the tool for the pdf2txt conversion, in the folder pdf2txt. It is built upon pdf2image, easyocr, ditod and detectron2. Please refer to the README.md in pdf2txt for more details.








If you find this project useful in your research, please consider citing:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/dvlab-research/LongLoRA}},
}
- This work is built upon the LLaMA2 as the pre-trained models.
- This work can also be built upon the GPTNeoX-HF which is based upon EleutherAI/GPTNeoX as the pre-trained model architecture.
- This work is based on DeepSpeed, peft, and Flash-Attention2 for acceleration.
- Some evaluation code is modified upon Landmark Attention.
- We use LongChat for the retrieval evaluation.
- We follow StreamingLLM for streaming inference.
- We combine QLoRA with LongLoRA for supervised fine-tuning.
- LongLoRA is licensed under the Apache License 2.0. This means that it requires the preservation of copyright and license notices.
- Data and weights are under CC-BY-NC 4.0 License. They are licensed for research use only, and allowed only non-commercial. Models trained using the dataset should not be used outside of research purposes.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LongLoRA
Similar Open Source Tools
LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
Online-RLHF
This repository, Online RLHF, focuses on aligning large language models (LLMs) through online iterative Reinforcement Learning from Human Feedback (RLHF). It aims to bridge the gap in existing open-source RLHF projects by providing a detailed recipe for online iterative RLHF. The workflow presented here has shown to outperform offline counterparts in recent LLM literature, achieving comparable or better results than LLaMA3-8B-instruct using only open-source data. The repository includes model releases for SFT, Reward model, and RLHF model, along with installation instructions for both inference and training environments. Users can follow step-by-step guidance for supervised fine-tuning, reward modeling, data generation, data annotation, and training, ultimately enabling iterative training to run automatically.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.
Fira
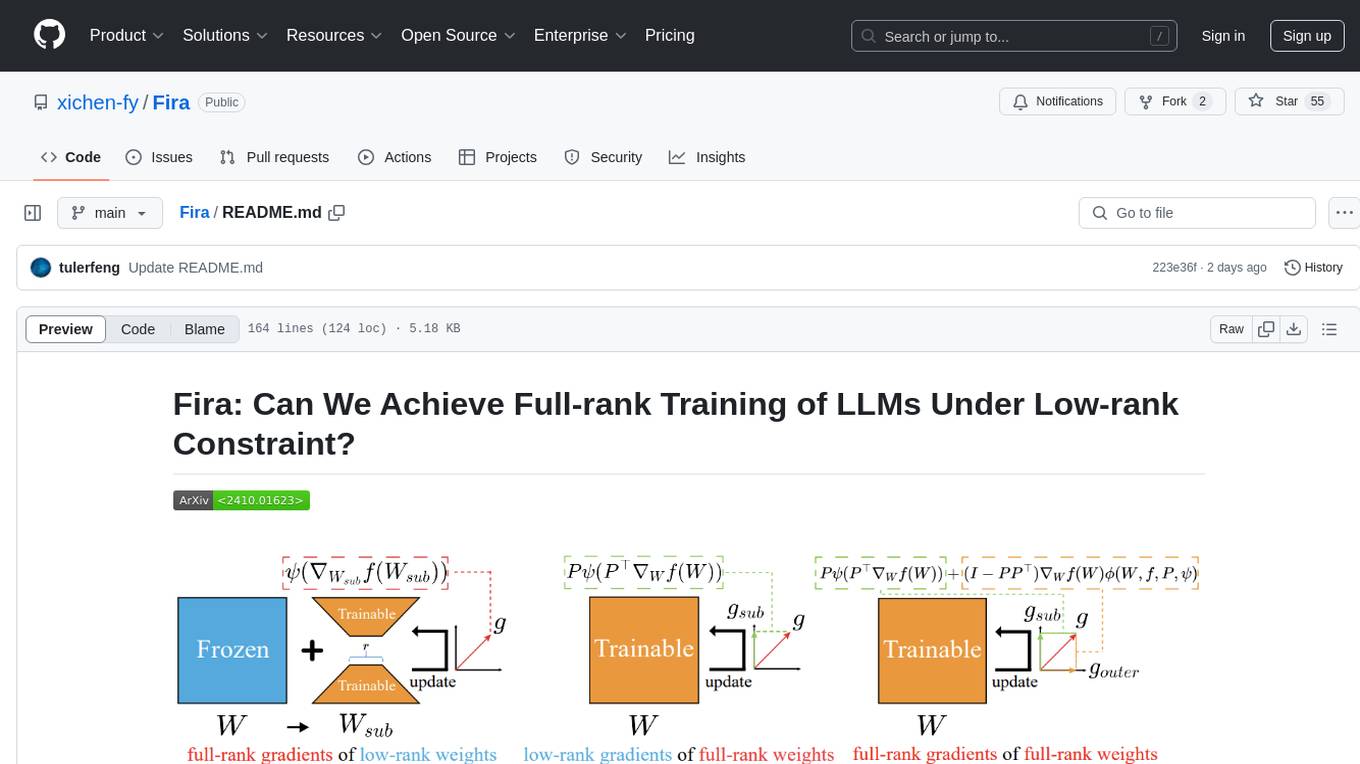
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.
TheoremExplainAgent
TheoremExplainAgent is an AI system that generates long-form Manim videos to visually explain theorems, proving its deep understanding while uncovering reasoning flaws that text alone often hides. The codebase for the paper 'TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding' is available in this repository. It provides a tool for creating multimodal explanations for theorem understanding using AI technology.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.

mistral-inference
Mistral Inference repository contains minimal code to run 7B, 8x7B, and 8x22B models. It provides model download links, installation instructions, and usage guidelines for running models via CLI or Python. The repository also includes information on guardrailing, model platforms, deployment, and references. Users can interact with models through commands like mistral-demo, mistral-chat, and mistral-common. Mistral AI models support function calling and chat interactions for tasks like testing models, chatting with models, and using Codestral as a coding assistant. The repository offers detailed documentation and links to blogs for further information.
For similar tasks
LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

ml-engineering
This repository provides a comprehensive collection of methodologies, tools, and step-by-step instructions for successful training of large language models (LLMs) and multi-modal models. It is a technical resource suitable for LLM/VLM training engineers and operators, containing numerous scripts and copy-n-paste commands to facilitate quick problem-solving. The repository is an ongoing compilation of the author's experiences training BLOOM-176B and IDEFICS-80B models, and currently focuses on the development and training of Retrieval Augmented Generation (RAG) models at Contextual.AI. The content is organized into six parts: Insights, Hardware, Orchestration, Training, Development, and Miscellaneous. It includes key comparison tables for high-end accelerators and networks, as well as shortcuts to frequently needed tools and guides. The repository is open to contributions and discussions, and is licensed under Attribution-ShareAlike 4.0 International.
distributed-llama
Distributed Llama is a tool that allows you to run large language models (LLMs) on weak devices or make powerful devices even more powerful by distributing the workload and dividing the RAM usage. It uses TCP sockets to synchronize the state of the neural network, and you can easily configure your AI cluster by using a home router. Distributed Llama supports models such as Llama 2 (7B, 13B, 70B) chat and non-chat versions, Llama 3, and Grok-1 (314B).

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.