
Fira
Fira: Can We Achieve Full-rank Training of LLMs Under Low-rank Constraint?
Stars: 61
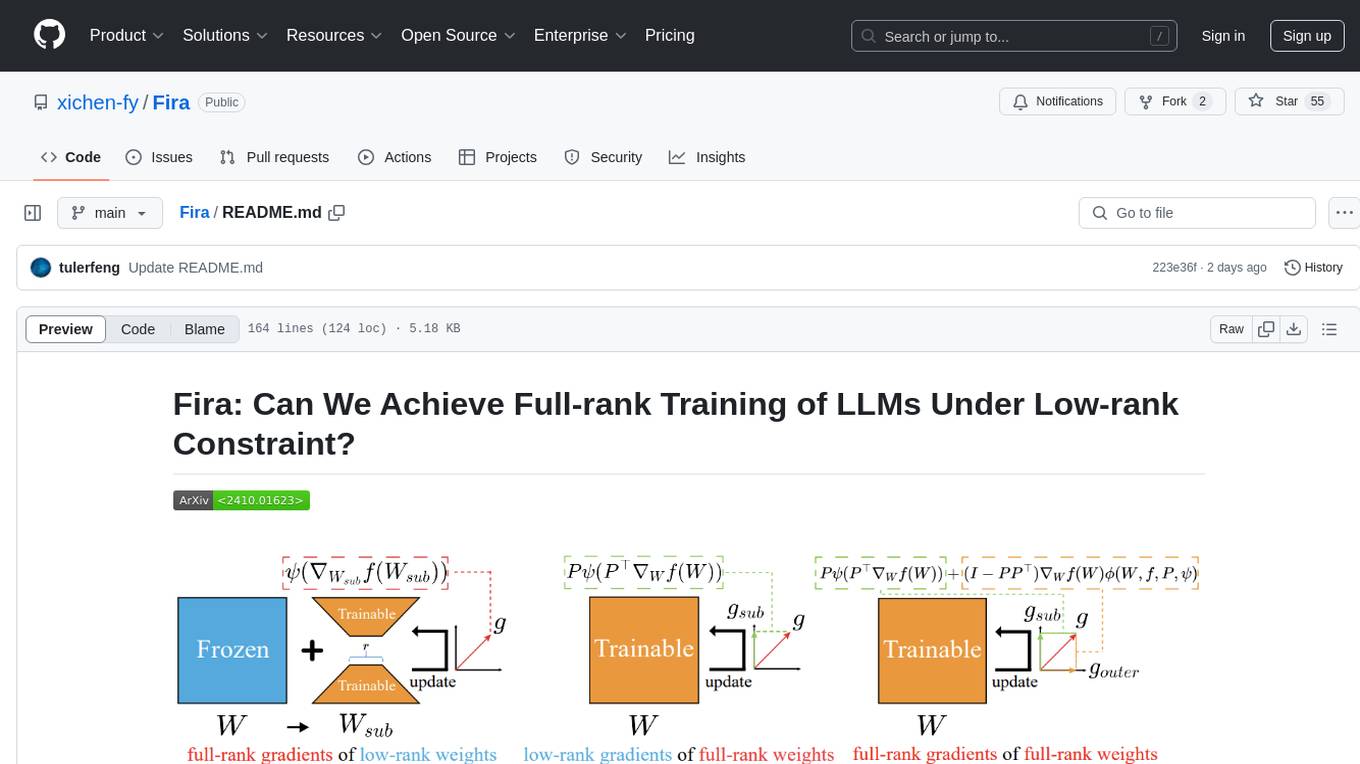
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.
README:

We introduce Fira, a plug-and-play memory-efficient training framework of LLMs.
Different from LoRA and Galore, we realize training with full-rank gradients of full-rank weights, constituting the first attempt to achieve full-rank training consistently under the low-rank constraint.
Our method is easy to implement, basically relying on just two lines of equations.
- [x] Release the pra-training code
- [x] Release the fine-tuning code
- [x] Package our Fira into a Python library for easy use
- [x] Release the code for quantitative analysis of scaling factor and provide further analysis on it
pip install firafrom fira import FiraAdamW, divide_params
param_groups = divide_params(model, target_modules_list = ["Linear"], rank=8)
optimizer = FiraAdamW(param_groups, lr=learning_rate)We also provide a quick-start tutorial for the Fira optimizer. You can find it in ./quick_start.
In Fira, Adam is used by default with weight_decay=0.
If you want to enable weight decay for AdamW, set as follows:
optimizer = FiraAdamW(param_groups, lr=learning_rate, weight_decay=0.01)Besides, you can modify the learning rate according to different tasks, with a recommended range of $10^{-5}$ to $10^{-2}$.
./pre_training_c4 includes the code for pre-training LLaMA models on the C4 dataset.
cd pre_training_c4
pip install -r requirements.txtOur experiment scripts are validated on Python 3.9 with PyTorch 2.2.2.
./pre_training_c4/torchrun_main.py script is used for pre-training LLaMA models on the C4 dataset.
./pre_training_c4/scripts directory stores the benchmark scripts across different LLaMA model sizes (60M, 130M, 350M, 1B, 7B).
For instance, to pre-train a 60M model on C4 dataset, execute the following command:
# LLaMA-60M, Fira-Adam, 1 A100, 1 Node
torchrun --standalone --nproc_per_node 1 torchrun_main.py \
--model_config llama_configs/llama_60m.json \
--lr 0.01 \
--alpha 0.25 \
--rank 128 \
--update_proj_gap 200 \
--batch_size 256 \
--total_batch_size 512 \
--num_training_steps 10000 \
--warmup_steps 1000 \
--weight_decay 0 \
--dtype bfloat16 \
--eval_every 1000 \
--optimizer fira_adamw This script directly accesses huggingface to load the C4 dataset, so please ensure a stable internet connection.
Alternatively, you can refer to the tutorials in ./download_use_c4 for using a local dataset.
./fine_tuning includes the code for fine-tuning LLaMA-7B with Fira.
cd fine_tuning
pip install -r requirements.txtDownload commonsense 170k finetuning dataset from LLM-Adapters. Then, place it as ./fine_tuning/commonsense_170k.json.
Download full dataset directory from LLM-Adapters. Then, place it as ./fine_tuning/dataset.
./finetune.py is used for finetuning LLaMA-7B on the commonsense reasoning tasks.
./commonsense_evaluate.py is used for evaluating the finetuned LLaMA-7B model on 8 sub-tasks of the commonsense reasoning tasks.
For instance, to finetuning LLaMA-7B with Fira on the commonsense reasoning tasks by a single GPU, execute the following command:
# LLaMA-7B, Fira-Adam, 1 4090
CUDA_VISIBLE_DEVICES=0 python finetune.py \
--base_model 'yahma/llama-7b-hf' \
--data_path 'commonsense_170k.json' \
--output_dir './result/fira' \
--batch_size 16 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 256 \
--val_set_size 120 \
--adapter_name lora \
--lora_r 32 \
--lora_alpha 64 \
--use_gradient_checkpointing \
--target_modules '["q_proj", "k_proj", "v_proj", "up_proj", "down_proj"]' \
--save_step 15000 \
--eval_step 1000 \
--optimizer_name fira_adamw For instance, evaluate the finetuned LLaMA-7B model on the BoolQ sub-task:
# LLaMA-7B, Fira-Adam, 1 4090
CUDA_VISIBLE_DEVICES=0 python commonsense_evaluate.py \
--model LLaMA-7B \
--adapter LoRA \
--dataset boolq \
--batch_size 1 \
--base_model 'yahma/llama-7b-hf' \
--lora_weights './result/fira' | tee -a './result/fira/boolq.txt'To further substantiate our findings of the scaling factor, we conduct more quantitative analysis of scaling factor similarities between low-rank and full-rank LLMs training. Specifically, we assess scaling factor similarities at both matrix and column level for pre-training LLaMA models ranging from 60M to 1B, averaged over 10,000 steps.
| Size | Matrix Level | Column Level | ||||||
|---|---|---|---|---|---|---|---|---|
| Spearman | Kendall | Spearman | Kendall | |||||
| Coefficient | P-value | Coefficient | P-value | Coefficient | P-value | Coefficient | P-value | |
| 60M | 0.9972 | 2e-62 | 0.9662 | 7e-26 | 0.9372 | 0.0 | 0.7942 | 0.0 |
| 130M | 0.9925 | 2e-76 | 0.9409 | 9e-37 | 0.8698 | 0.0 | 0.6830 | 0.0 |
| 350M | 0.9770 | 3e-113 | 0.8848 | 5e-65 | 0.9091 | 0.0 | 0.7400 | 0.0 |
| 1B | 0.9469 | 1e-83 | 0.8249 | 1e-56 | 0.8331 | 0.0 | 0.6513 | 0.0 |
Spearman and Kendall correlation coefficients range from -1 to +1, +1 signifies a perfect positive correlation, and -1 signifies a perfect negative correlation. Generally, a p-value below 0.05 suggests that a significant correlation exists. As shown in the above table, both Spearman and Kendall correlation coefficients indicate a strong positive relationship at the matrix and column levels across all sizes of the LLaMA models, with all p-values below 0.05.
Therefore, it is likely that the observed behavior is an inherent feature of LLM training, manifesting across a broad range of scenarios. This insight provides a robust experimental basis for our proposed norm-based scaling in Fira and helps explain its effectiveness. Code for this analysis is provided in ./similarity.
This implementation is based on code from several repositories.
@article{chen2024firaachievefullranktraining,
title={Fira: Can We Achieve Full-rank Training of LLMs Under Low-rank Constraint?},
author={Xi Chen and Kaituo Feng and Changsheng Li and Xunhao Lai and Xiangyu Yue and Ye Yuan and Guoren Wang},
journal={arXiv},
year={2024},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Fira
Similar Open Source Tools
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.
For similar tasks

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.