
ModelGenerator
AIDO.ModelGenerator is a software stack powering the development of an AI-driven Digital Organism (AIDO) by enabling researchers to adapt pretrained models and generate finetuned models for downstream tasks.
Stars: 94
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.
README:

AIDO.ModelGenerator

AIDO.ModelGenerator is a software stack powering the development of an AI-driven Digital Organism by enabling researchers to adapt pretrained models and generate finetuned models for downstream tasks. To read more about AIDO.ModelGenerator's integral role in building the world's first AI-driven Digital Organism, see AIDO.
AIDO.ModelGenerator is open-sourced as an opinionated plug-and-play research framework for cross-disciplinary teams in ML & Bio. It is designed to enable rapid and reproducible prototyping with four kinds of experiments in mind:
- Applying pre-trained foundation models to new data
- Developing new finetuning and inference tasks for foundation models
- Benchmarking foundation models and creating leaderboards
- Testing new architectures for finetuning performance
while also scaling with hardware and integrating with larger data pipelines or research workflows.
AIDO.ModelGenerator is built on PyTorch, HuggingFace, and Lightning, and works seamlessly with these ecosystems.
See the AIDO.ModelGenerator documentation for installation, usage, tutorials, and API reference.
- Intuitive one-command CLIs for in silico experiments
- Pre-trained model zoo
- Broad data compatibility
- Pipeline-oriented workflows
- Reproducible-by-design experiments
- Architecture A/B testing
- Automatic hardware scaling
- Integration with PyTorch, Lightning, HuggingFace, and WandB
- Extensible and modular models, tasks, and data
- Strict typing and documentation
- Fail-fast interface design
- Continuous integration and testing
- A collaborative hub and focal point for multidisciplinary work on experiments, models, software, and data
- Community-driven development
- Permissive license for academic and non-commercial use
- Accurate and General DNA Representations Emerge from Genome Foundation Models at Scale
- A Large-Scale Foundation Model for RNA Function and Structure Prediction
- Mixture of Experts Enable Efficient and Effective Protein Understanding and Design
- Scaling Dense Representations for Single Cell with Transcriptome-Scale Context
- Balancing Locality and Reconstruction in Protein Structure Tokenizer
git clone https://github.com/genbio-ai/ModelGenerator.git
cd ModelGenerator
pip install -e .
Source installation is necessary to add new backbones, finetuning tasks, and data transformations, as well as use convenience configs and scripts. If you only need to run inference, reproduce published experiments, or finetune on new data, you can use
pip install modelgenerator
pip install git+https://github.com/genbio-ai/openfold.git@c4aa2fd0d920c06d3fd80b177284a22573528442
pip install git+https://github.com/NVIDIA/dllogger.git@0540a43971f4a8a16693a9de9de73c1072020769
mgen predict --model Embed --model.backbone aido_dna_dummy \
--data SequencesDataModule --data.path genbio-ai/100m-random-promoters \
--data.x_col sequence --data.id_col sequence --data.test_split_size 0.0001 \
--config configs/examples/save_predictions.yaml
mgen predict --model Inference --model.backbone aido_dna_dummy \
--data SequencesDataModule --data.path genbio-ai/100m-random-promoters \
--data.x_col sequence --data.id_col sequence --data.test_split_size 0.0001 \
--config configs/examples/save_predictions.yaml
mgen fit --model ConditionalDiffusion --model.backbone aido_dna_dummy \
--data ConditionalDiffusionDataModule --data.path "genbio-ai/100m-random-promoters"
mgen test --model ConditionalDiffusion --model.backbone aido_dna_dummy \
--data ConditionalDiffusionDataModule --data.path "genbio-ai/100m-random-promoters" \
--ckpt_path logs/lightning_logs/version_X/checkpoints/<your_model>.ckpt
mgen predict --model ConditionalDiffusion --model.backbone aido_dna_dummy \
--data ConditionalDiffusionDataModule --data.path "genbio-ai/100m-random-promoters" \
--ckpt_path logs/lightning_logs/version_X/checkpoints/<your_model>.ckpt \
--config configs/examples/save_predictions.yaml
This command
mgen fit --model ConditionalDiffusion --model.backbone aido_dna_dummy \
--data ConditionalDiffusionDataModule --data.path "genbio-ai/100m-random-promoters"
is equivalent to
mgen fit --config my_config.yaml with
# my_config.yaml
model:
class_path: ConditionalDiffusion
init_args:
backbone: aido_dna_dummy
data:
class_path: ConditionalDiffusionDataModule
init_args:
path: "genbio-ai/100m-random-promoters"
mgen fit --model SequenceRegression --data PromoterExpressionRegression \
--config configs/defaults.yaml \
--config configs/examples/lora_backbone.yaml \
--config configs/examples/wandb.yaml
We provide some useful examples in configs/examples.
Configs use the LAST value for each attribute.
Check the full configuration logged with each experiment in logs/lightning_logs/your-experiment/config.yaml, or if using wandb logs/config.yaml.
This also avoids saving the full model, only the LoRA weights are saved.
mgen fit --data PromoterExpressionRegression \
--model SequenceRegression --model.backbone.use_peft true \
--model.backbone.lora_r 16 \
--model.backbone.lora_alpha 32 \
--model.backbone.lora_dropout 0.1
First run pretraining objective on finetuning data
# https://arxiv.org/pdf/2310.02980
mgen fit --model MLM --model.backbone aido_dna_dummy \
--data MLMDataModule --data.path leannmlindsey/GUE \
--data.config_name prom_core_notata
Then finetune using the adapted model
mgen fit --model SequenceClassification --model.strict_loading false \
--data SequenceClassificationDataModule --data.path leannmlindsey/GUE \
--data.config_name prom_core_notata \
--ckpt_path logs/lightning_logs/version_X/checkpoints/<your_adapted_model>.ckpt
Make sure to turn off strict_loading to replace the adapter!
mgen fit --model SequenceClassification --data GUEClassification \
--model.use_legacy_adapter true
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ModelGenerator
Similar Open Source Tools
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.
ai2-kit
A toolkit for computational chemistry research, featuring tools to facilitate automated workflows. Includes tools for NMR prediction, dynamic catalysis research, proton transfer analysis, amorphous oxides structure analysis, reweighting, and more. Users can install 'ai2-kit' via pip and explore various domain-specific and general tools for processing system data and filtering structures by model deviation.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.
SiLLM
SiLLM is a toolkit that simplifies the process of training and running Large Language Models (LLMs) on Apple Silicon by leveraging the MLX framework. It provides features such as LLM loading, LoRA training, DPO training, a web app for a seamless chat experience, an API server with OpenAI compatible chat endpoints, and command-line interface (CLI) scripts for chat, server, LoRA fine-tuning, DPO fine-tuning, conversion, and quantization.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.

gradient-cli
Gradient CLI is a tool designed to facilitate the end-to-end MLOps process, allowing individuals and organizations to develop, train, and deploy Deep Learning models efficiently. It supports various ML/DL frameworks and provides features such as 1-click Jupyter Notebooks, scalable model training workflows, and model deployment as API endpoints. The tool can run on different infrastructures like AWS, GCP, on-premise, and Paperspace GPUs, offering automatic versioning, distributed training, hyperparameter search, and more.

crab
CRAB is a framework for building LLM agent benchmark environments in a Python-centric way. It is cross-platform and multi-environment, allowing the creation of agent environments supporting various deployment options. The framework offers easy-to-use configuration with the ability to add new actions and define environments seamlessly. CRAB also provides a novel benchmarking suite with tasks and evaluators defined in Python, along with a unique graph evaluator method for detailed metrics.
LLMFlex
LLMFlex is a python package designed for developing AI applications with local Large Language Models (LLMs). It provides classes to load LLM models, embedding models, and vector databases to create AI-powered solutions with prompt engineering and RAG techniques. The package supports multiple LLMs with different generation configurations, embedding toolkits, vector databases, chat memories, prompt templates, custom tools, and a chatbot frontend interface. Users can easily create LLMs, load embeddings toolkit, use tools, chat with models in a Streamlit web app, and serve an OpenAI API with a GGUF model. LLMFlex aims to offer a simple interface for developers to work with LLMs and build private AI solutions using local resources.

gpustack
GPUStack is an open-source GPU cluster manager designed for running large language models (LLMs). It supports a wide variety of hardware, scales with GPU inventory, offers lightweight Python package with minimal dependencies, provides OpenAI-compatible APIs, simplifies user and API key management, enables GPU metrics monitoring, and facilitates token usage and rate metrics tracking. The tool is suitable for managing GPU clusters efficiently and effectively.
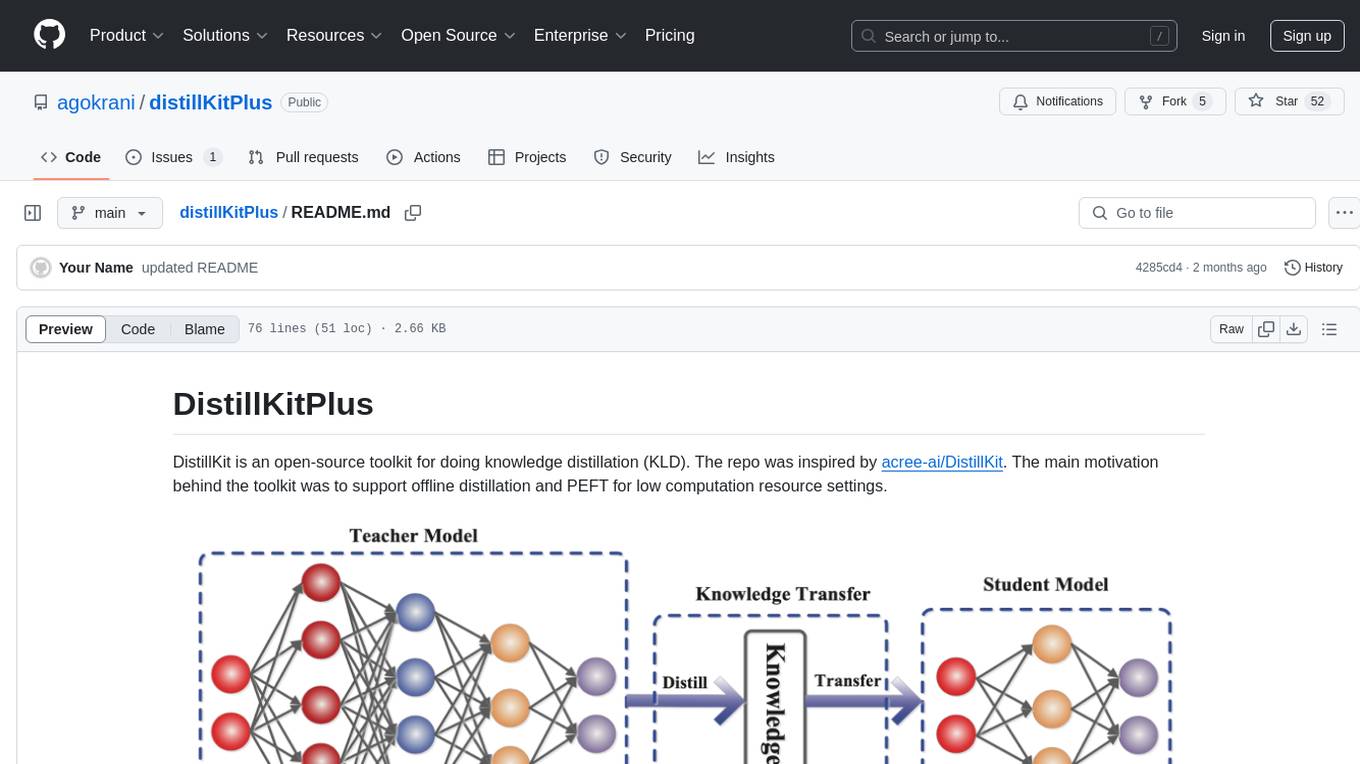
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
For similar tasks
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.
For similar jobs
OpenCRISPR
OpenCRISPR is a set of free and open gene editing systems designed by Profluent Bio. The OpenCRISPR-1 protein maintains the prototypical architecture of a Type II Cas9 nuclease but is hundreds of mutations away from SpCas9 or any other known natural CRISPR-associated protein. You can view OpenCRISPR-1 as a drop-in replacement for many protocols that need a cas9-like protein with an NGG PAM and you can even use it with canonical SpCas9 gRNAs. OpenCRISPR-1 can be fused in a deactivated or nickase format for next generation gene editing techniques like base, prime, or epigenome editing.
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.
BioAgents
BioAgents AgentKit is an advanced AI agent framework tailored for biological and scientific research. It offers powerful conversational AI capabilities with specialized knowledge in biology, life sciences, and scientific research methodologies. The framework includes state-of-the-art analysis agents, configurable research agents, and a variety of specialized agents for tasks such as file parsing, research planning, literature search, data analysis, hypothesis generation, research reflection, and user-facing responses. BioAgents also provides support for LLM libraries, multiple search backends for literature agents, and two backends for data analysis. The project structure includes backend source code, services for chat, job queue system, real-time notifications, and JWT authentication, as well as a frontend UI built with Preact.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.