
KnowAgent
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
Stars: 135
KnowAgent is a tool designed for Knowledge-Augmented Planning for LLM-Based Agents. It involves creating an action knowledge base, converting action knowledge into text for model understanding, and a knowledgeable self-learning phase to continually improve the model's planning abilities. The tool aims to enhance agents' potential for application in complex situations by leveraging external reservoirs of information and iterative processes.
README:


Our development is grounded on several key steps: Initially, we create an extensive action knowledge base, which amalgamates action planning knowledge pertinent to specific tasks. This database acts as an external reservoir of information, steering the model's action generation process. Subsequently, by converting action knowledge into text, we enable the model to deeply understand and utilize this knowledge in creating action trajectories. Finally, through a knowledgeable self-learning phase, we use trajectories developed from the model's iterative processes to continually improve its understanding and application of action knowledge. This process not only strengthens the agents' planning abilities but also enhances their potential for application in complex situations.
- 🌟Table of Contents
- 🔔News
- 🔧Installation
- 🗺️Planning Path Generation
- 📝Knowledgeable Self-Learning
- 🔖Citation
- ✨Acknowledgement
- [2024-03] We release a new paper: "KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents".
To get started with KnowAgent, follow these simple installation steps:
git clone https://github.com/zjunlp/KnowAgent.git
cd KnowAgent
pip install -r requirements.txtWe have placed the HotpotQA and ALFWorld datasets under Path_Generation/alfworld_run/data and Path_Generation/hotpotqa_run/data respectively. For further configuration, we recommend proceeding with the original setup of ALFWorld and FastChat.
The Planning Path Generation process is integral to KnowAgent. You can find the scripts for running the Planning Path Generation in Path_Generation directory, specifically run_alfworld.sh and run_hotpotqa.sh. These scripts can be executed using bash commands. To tailor the scripts to your needs, you may modify the mode parameter to switch between training (train) and testing (test)modes, and change the llm_name parameter to use a different LLM:
cd Path_Generation
# For training with HotpotQA
python run_hotpotqa.py --llm_name llama-2-13b --max_context_len 4000 --mode train --output_path ../Self-Learning/trajs/
# For testing with HotpotQA
python run_hotpotqa.py --llm_name llama-2-13b --max_context_len 4000 --mode test --output_path output/
# For training with ALFWorld
python alfworld_run/run_alfworld.py --llm_name llama-2-13b --mode train --output_path ../Self-Learning/trajs/
# For testing with ALFWorld
python alfworld_run/run_alfworld.py --llm_name llama-2-13b --mode test --output_path output/
Here we release the trajectories synthesized by Llama-{7,13,70}b-chat in Google Drive before Filtering.
After obtaining the planning paths and corresponding trajectories, the process of Knowledgeable Self-Learning begins. The generated trajectories are first converted to the Alpaca format using the scripts in the Self-Learning directory, such as traj_reformat.sh. For initial iterations, use:
cd Self-Learning
# For HotpotQA
python train/Hotpotqa_reformat.py --input_path trajs/KnowAgentHotpotQA_llama-2-13b.jsonl --output_path train/datas
# For ALFWorld
python train/ALFWorld_reformat.py --input_path trajs/KnowAgentALFWorld_llama-2-13b.jsonl --output_path train/datas
For subsequent iterations, before running traj_reformat.sh, it's necessary to perform Knowledge-Based Trajectory Filtering and Merging using traj_merge_and_filter.sh:
python trajs/traj_merge_and_filter.py \
--task HotpotQA \
--input_path1 trajs/datas/KnowAgentHotpotQA_llama-2-13b_D0.jsonl \
--input_path2 trajs/datas/KnowAgentHotpotQA_llama-2-13b_D1.jsonl \
--output_path trajs/datas
Next, commence Self-Learning by running train.sh and train_iter.sh, referring to the scripts in Self-Learning/train.sh and Self-Learning/train_iter.sh:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 deepspeed train/train_lora.py \
--model_name_or_path llama-2-13b-chat\
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--data_path datas/data_knowagent.json \
--output_dir models/Hotpotqa/M1 \
--num_train_epochs 5 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 10000 \
--save_total_limit 1 \
--learning_rate 1e-4 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fp16 True \
--model_max_length 4096 \
--gradient_checkpointing True \
--q_lora False \
--deepspeed /data/zyq/FastChat/playground/deepspeed_config_s3.json \
--resume_from_checkpoint False
@article{zhu2024knowagent,
title={KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents},
author={Zhu, Yuqi and Qiao, Shuofei and Ou, Yixin and Deng, Shumin and Zhang, Ningyu and Lyu, Shiwei and Shen, Yue and Liang, Lei and Gu, Jinjie and Chen, Huajun},
journal={arXiv preprint arXiv:2403.03101},
year={2024}
}-
We express our gratitude to the creators and contributors of the following projects, which have significantly influenced the development of KnowAgent:
- FastChat: Our training module code is adapted from FastChat. Visit FastChat,and Integration with open models through LangChain is facilitated via FastChat. Learn more about LangChain and FastChat Integration.
- BOLAA: The inference module code is implemented based on BOLAA. Visit BOLAA
- Additional baseline codes from ReAct, Reflexion, FireAct, and others have been utilized, showcasing a diverse range of approaches and methodologies.
Our heartfelt thanks go out to all contributors for their invaluable contributions to the field!
We will offer long-term maintenance to fix bugs and solve issues. So if you have any problems, please put issues to us.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for KnowAgent
Similar Open Source Tools
KnowAgent
KnowAgent is a tool designed for Knowledge-Augmented Planning for LLM-Based Agents. It involves creating an action knowledge base, converting action knowledge into text for model understanding, and a knowledgeable self-learning phase to continually improve the model's planning abilities. The tool aims to enhance agents' potential for application in complex situations by leveraging external reservoirs of information and iterative processes.
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.
humanoid-gym
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.
metta
Metta AI is an open-source research project focusing on the emergence of cooperation and alignment in multi-agent AI systems. It explores the impact of social dynamics like kinship and mate selection on learning and cooperative behaviors of AI agents. The project introduces a reward-sharing mechanism mimicking familial bonds and mate selection to observe the evolution of complex social behaviors among AI agents. Metta aims to contribute to the discussion on safe and beneficial AGI by creating an environment where AI agents can develop general intelligence through continuous learning and adaptation.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
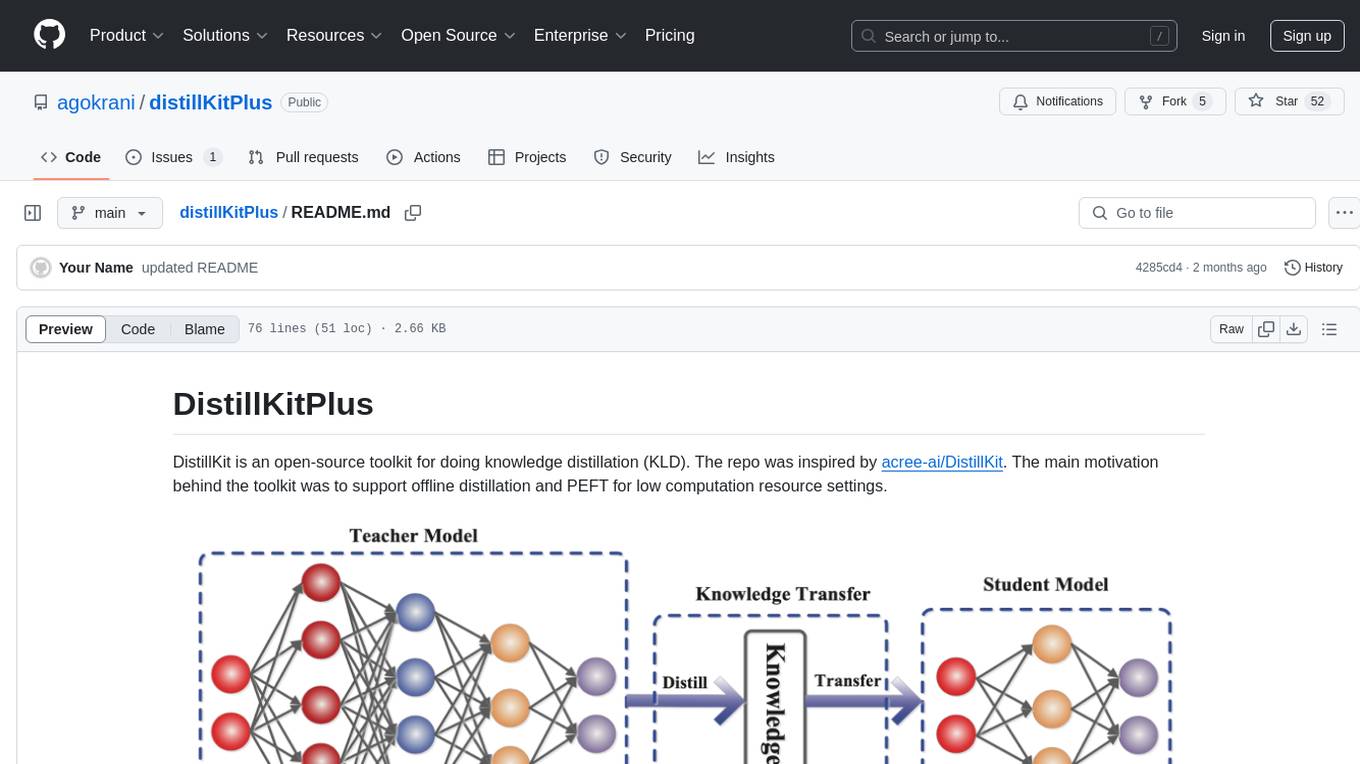
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
distilabel
Distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency. It helps you synthesize data and provide AI feedback to improve the quality of your AI models. With Distilabel, you can: * **Synthesize data:** Generate synthetic data to train your AI models. This can help you to overcome the challenges of data scarcity and bias. * **Provide AI feedback:** Get feedback from AI models on your data. This can help you to identify errors and improve the quality of your data. * **Improve your AI output quality:** By using Distilabel to synthesize data and provide AI feedback, you can improve the quality of your AI models and get better results.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.
habitat-lab
Habitat-Lab is a modular high-level library for end-to-end development in embodied AI. It is designed to train agents to perform a wide variety of embodied AI tasks in indoor environments, as well as develop agents that can interact with humans in performing these tasks.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
For similar tasks
KnowAgent
KnowAgent is a tool designed for Knowledge-Augmented Planning for LLM-Based Agents. It involves creating an action knowledge base, converting action knowledge into text for model understanding, and a knowledgeable self-learning phase to continually improve the model's planning abilities. The tool aims to enhance agents' potential for application in complex situations by leveraging external reservoirs of information and iterative processes.
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.