
byteir
A model compilation solution for various hardware
Stars: 418

The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.
README:
English | 中文
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution.
Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently.
The name, ByteIR, comes from a legacy purpose internally.
The ByteIR project is NOT an IR spec definition project.
Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo.
Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.
- Enjoy SOTA models: ByteIR maintains the popular frontends to handle lowering many SOTA models into Stablehlo, and also provides a model zoo (release soon) for research or benchmarking purposes.
- Just work: ByteIR adopts upstream MLIR dialects and Google Mhlo, and provides compatible passes, utilities, and infrastructure for all compiler builders using upstream MLIR. You can mix using ByteIR passes with upstream MLIR or Mhlo passes, or even your own passes to build your pipeline.
- Bring your own architecture: ByteIR provides rich generic graph-, loop-, tensor-level, optimizations in Mhlo and Linalg, which allow DL ASIC compilers to reuse, and focus only on the last mile for their backends.
ByteIR is still in its early phase. In this phase, we are aiming to provide well-defined, necessary building blocks and infrastructure support for model compilation in a wide-range of deep learning accelerators as well as general-purpose CPUs and GPUs. Therefore, highly-tuned kernels for specific architecture might not have been prioritized. For sure, any feedback for prioritizing specific architecture or corresponding contribution are welcome.
ByteIR Compiler is an MLIR-based compiler for CPU/GPU/ASIC.
ByteIR Runtime is a common, lightweight runtime, capable to serving both existing kernels and ByteIR compiler generated kernels.
ByteIR Frontends includes Tensorflow, PyTorch, and ONNX.
Each ByteIR component technically can perform independently. There are pre-defined communication interface between components.
ByteIR frontends and ByteIR compiler communicate through Stablehlo dialect, which version might be updated during development.
This also implies whatever frontend generating Stablehlo with a compatible version can work with ByteIR compiler, and also whatever compiler consuming Stablehlo with a compatible version can work with ByteIR frontends.
ByteIR compiler and ByteIR runtime communicates through ByRE format, which version might be updated during development. ByRE dialect is defined as a kind of ByRE format in ByteIR compiler, currently supporting emitting a textual form or bytecode with versioning for ByteIR compiler and runtime.
Other ByRE formats are under development.
ByteIR is the product of many great researchers and interns in ByteDance. Below is a list of our public talks:
- Linalg is All You Need to Optimize Attention -- C4ML'23
- ByteIR: Towards End-to-End AI Compilation -- China SoftCon'23
If you find ByteIR useful, please consider citing.
@misc{byteir2023,
title = {{ByteIR}},
author = {Cao, Honghua and Chang, Li-Wen and Chen, Chongsong and Jiang, Chengquan and Jiang, Ziheng and Liu, Liyang and Liu, Yuan and Liu, Yuanqiang and Shen, Chao and Wang, Haoran and Xiao, Jianzhe and Yao, Chengji and Yuan, Hangjian and Zhang, Fucheng and Zhang, Ru and Zhang, Xuanrun and Zhang, Zhekun and Zhang, Zhiwei and Zhu, Hongyu and Liu, Xin},
url = {https://github.com//bytedance/byteir},
year = {2023}
}
The ByteIR Project is under the Apache License v2.0
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for byteir
Similar Open Source Tools
byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.
aily-blockly
Aily Blockly is a blockly IDE under the Aily Project, providing AI-assisted programming capabilities for non-professional users. It aims to integrate numerous AI capabilities to help hardware developers develop more smoothly, ultimately achieving natural language programming. The software offers features like Engineering Project Management, Library Manager, Serial Debug Tool, AI Project Generation, AI Code Generation, AI Library Conversion, Development Board Configuration Generation, and Lightning Compilation Tool. It is currently in the alpha stage, suitable for prototype verification and educational teaching.

ModernBERT
ModernBERT is a repository focused on modernizing BERT through architecture changes and scaling. It introduces FlexBERT, a modular approach to encoder building blocks, and heavily relies on .yaml configuration files to build models. The codebase builds upon MosaicBERT and incorporates Flash Attention 2. The repository is used for pre-training and GLUE evaluations, with a focus on reproducibility and documentation. It provides a collaboration between Answer.AI, LightOn, and friends.

blades
Blades is a multimodal AI Agent framework in Go, supporting custom models, tools, memory, middleware, and more. It is well-suited for multi-turn conversations, chain reasoning, and structured output. The framework provides core components like Agent, Prompt, Chain, ModelProvider, Tool, Memory, and Middleware, enabling developers to build intelligent applications with flexible configuration and high extensibility. Blades leverages the characteristics of Go to achieve high decoupling and efficiency, making it easy to integrate different language model services and external tools. The project is in its early stages, inviting Go developers and AI enthusiasts to contribute and explore the possibilities of building AI applications in Go.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.
bpf-developer-tutorial
This is a development tutorial for eBPF based on CO-RE (Compile Once, Run Everywhere). It provides practical eBPF development practices from beginner to advanced, including basic concepts, code examples, and real-world applications. The tutorial focuses on eBPF examples in observability, networking, security, and more. It aims to help eBPF application developers quickly grasp eBPF development methods and techniques through examples in languages such as C, Go, and Rust. The tutorial is structured with independent eBPF tool examples in each directory, covering topics like kprobes, fentry, opensnoop, uprobe, sigsnoop, execsnoop, exitsnoop, runqlat, hardirqs, and more. The project is based on libbpf and frameworks like libbpf, Cilium, libbpf-rs, and eunomia-bpf for development.

onnx
Open Neural Network Exchange (ONNX) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types. Currently, we focus on the capabilities needed for inferencing (scoring). ONNX is widely supported and can be found in many frameworks, tools, and hardware, enabling interoperability between different frameworks and streamlining the path from research to production to increase the speed of innovation in the AI community. Join us to further evolve ONNX.
tau
Tau is a framework for building low maintenance & highly scalable cloud computing platforms that software developers will love. It aims to solve the high cost and time required to build, deploy, and scale software by providing a developer-friendly platform that offers autonomy and flexibility. Tau simplifies the process of building and maintaining a cloud computing platform, enabling developers to achieve 'Local Coding Equals Global Production' effortlessly. With features like auto-discovery, content-addressing, and support for WebAssembly, Tau empowers users to create serverless computing environments, host frontends, manage databases, and more. The platform also supports E2E testing and can be extended using a plugin system called orbit.
motleycrew
Motleycrew is an ultimate framework for building multi-agent AI systems, allowing users to mix and match AI agents and tools from popular frameworks, design advanced workflows, and leverage dynamic knowledge graphs with simplicity and elegance. It acts as a conductor orchestrating a symphony of AI agents and tools, providing building blocks for creating AI systems and enabling users to focus on high-level design while taking care of the rest. The framework offers integration with various tools, flexibility in providing agents with tools or other agents, advanced flow design capabilities, and built-in observability and caching features.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
AI4U
AI4U is a tool that provides a framework for modeling virtual reality and game environments. It offers an alternative approach to modeling Non-Player Characters (NPCs) in Godot Game Engine. AI4U defines an agent living in an environment and interacting with it through sensors and actuators. Sensors provide data to the agent's brain, while actuators send actions from the agent to the environment. The brain processes the sensor data and makes decisions (selects an action by time). AI4U can also be used in other situations, such as modeling environments for artificial intelligence experiments.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.
sudolang-llm-support
SudoLang is a programming language designed for collaboration with AI language models like ChatGPT, Bing Chat, Anthropic Claude, Google Gemini, Meta's Llama models, etc. It emphasizes natural language constraint-based programming, interfaces, semantic pattern matching, referential omnipotence, function composition, and Mermaid diagrams. SudoLang is easier to learn than traditional programming languages, improves reasoning performance, and offers a declarative, constraint-based, interface-oriented approach. It provides structured pseudocode for complex prompts, reducing prompting costs and response times.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.
paddler
Paddler is an open-source LLM load balancer and serving platform designed for digital products and users who prioritize privacy, reliability, cost control, and independence from closed-source model providers. It allows running inference, deploying, and scaling LLMs on personal infrastructure, offering a seamless developer experience. Key features include inference through llama.cpp engine, LLM-specific load balancing, dynamic model swapping, request buffering, and built-in web admin panel for management and monitoring. Paddler is suitable for product teams needing LLM inference, DevOps/LLMOps teams deploying LLMs at scale, organizations handling sensitive data, and product leaders aiming for predictable LLM costs and reliable model performance.
For similar tasks
byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
For similar jobs
byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.
mlir-air
This repository contains tools and libraries for building AIR platforms, runtimes and compilers.
husky
Husky is a research-focused programming language designed for next-generation computing. It aims to provide a powerful and ergonomic development experience for various tasks, including system level programming, web/native frontend development, parser/compiler tasks, game development, formal verification, machine learning, and more. With a strong type system and support for human-in-the-loop programming, Husky enables users to tackle complex tasks such as explainable image classification, natural language processing, and reinforcement learning. The language prioritizes debugging, visualization, and human-computer interaction, offering agile compilation and evaluation, multiparadigm support, and a commitment to a good ecosystem.
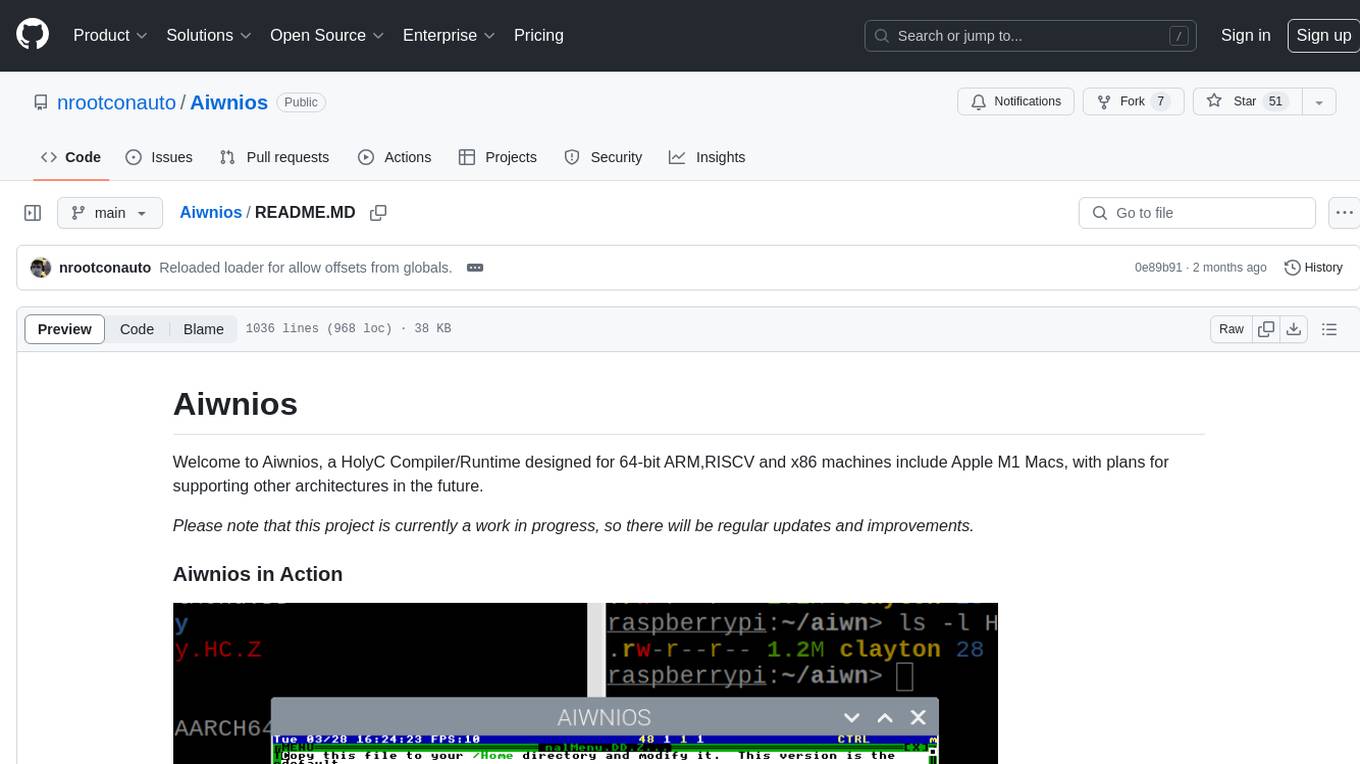
Aiwnios
Aiwnios is a HolyC Compiler/Runtime designed for 64-bit ARM, RISCV, and x86 machines, including Apple M1 Macs, with plans for supporting other architectures in the future. The project is currently a work in progress, with regular updates and improvements planned. Aiwnios includes a sockets API (currently tested on FreeBSD) and a HolyC assembler accessible through AARCH64. The heart of Aiwnios lies in `arm_backend.c`, where the compiler is located, and a powerful AARCH64 assembler in `arm64_asm.c`. The compiler uses reverse Polish notation and statements are reversed. The developer manual is intended for developers working on the C side, providing detailed explanations of the source code.
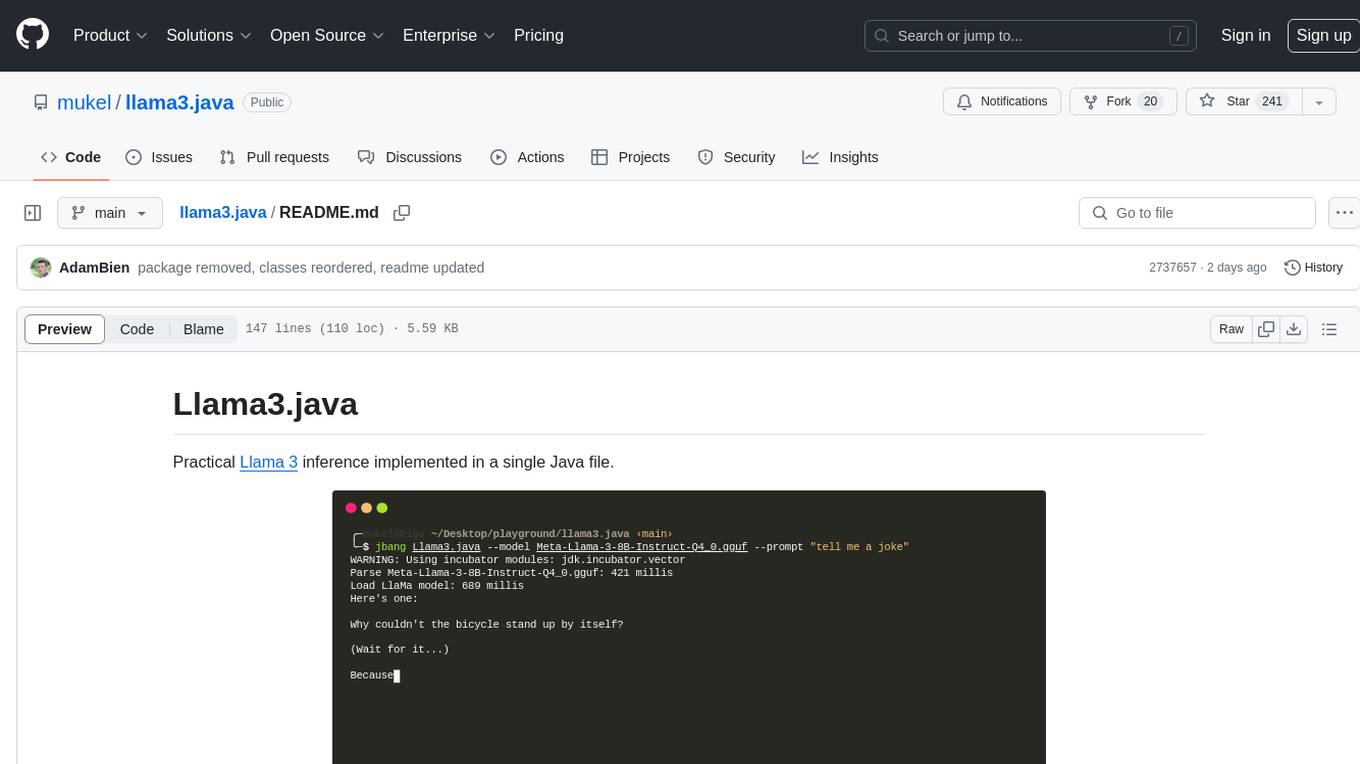
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
llvm-aie
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors. AI Engine processors are in-order, exposed-pipeline VLIW processors focused on application acceleration for AI, Machine Learning, and DSP applications. The repository adds LLVM support for specific features like non-power of 2 pointers, operand latencies, resource conflicts, negative operand latencies, slot assignment, relocations, code alignment restrictions, and register allocation. It includes support for Clang, LLD, binutils, Compiler-RT, and LLVM-LIBC.
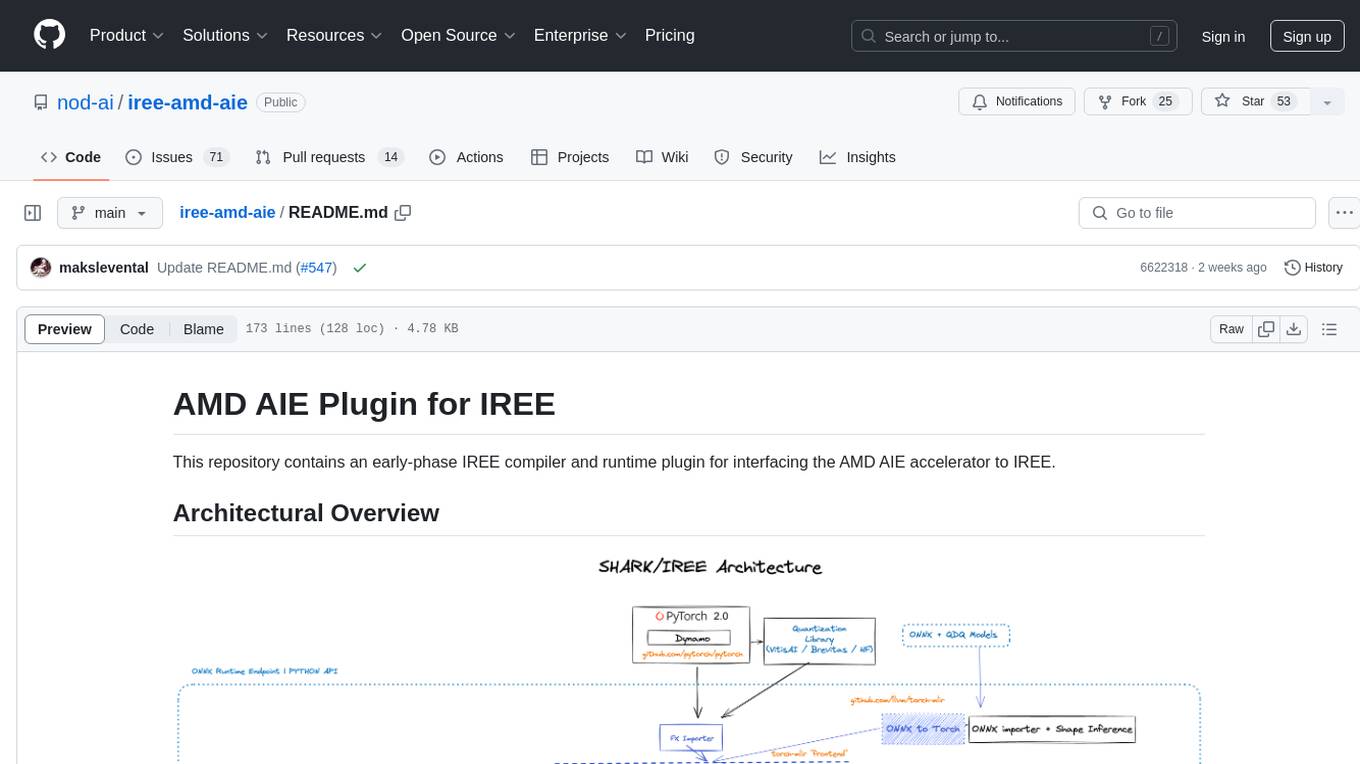
iree-amd-aie
This repository contains an early-phase IREE compiler and runtime plugin for interfacing the AMD AIE accelerator to IREE. It provides architectural overview, developer setup instructions, building guidelines, and runtime driver setup details. The repository focuses on enabling the integration of the AMD AIE accelerator with IREE, offering developers the tools and resources needed to build and run applications leveraging this technology.
AILZ80ASM
AILZ80ASM is a Z80 assembler that runs in a .NET 8 environment written in C#. It can be used to assemble Z80 assembly code and generate output files in various formats. The tool supports various command-line options for customization and provides features like macros, conditional assembly, and error checking. AILZ80ASM offers good performance metrics with fast assembly times and efficient output file sizes. It also includes support for handling different file encodings and provides a range of built-in functions for working with labels, expressions, and data types.