
llvm-aie
Fork of LLVM to support AMD AIEngine processors
Stars: 164
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors. AI Engine processors are in-order, exposed-pipeline VLIW processors focused on application acceleration for AI, Machine Learning, and DSP applications. The repository adds LLVM support for specific features like non-power of 2 pointers, operand latencies, resource conflicts, negative operand latencies, slot assignment, relocations, code alignment restrictions, and register allocation. It includes support for Clang, LLD, binutils, Compiler-RT, and LLVM-LIBC.
README:
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors.
| Architecture | clang/LLVM target | High-Level Intrinsic API (AIE_API) |
|---|---|---|
| XDNA (Phoenix, Hawk Point) | --target=aie2-none-unknown-elf | Link |
| XDNA2 (Strix Point) | --target=aie2p-none-unknown-elf |
Generally speaking, AI Engine processors are in-order, exposed-pipeline VLIW processors. These processors are implemented as part of an array of processors focused on application acceleration targetting AI, Machine Learning, and DSP applications. They have been integrated in a number of commercial devices including the Versal AI Core Series and Ryzen-AI SOCs.
Each VLIW instruction bundle specifies the behavior of one or more functional units, which begin executing a new instruction at the same time. The processor pipeline does not include stall logic, and instructions will continue executing in order regardless of other instructions in the pipeline. As a result, the compiler is able to schedule machine instructions which access the same register in ways that potentially overlap. e.g.
1: lda r12, [p0] // writes r12 after cycle 8.
2: nop
3: nop
4: mul r12, r12, r12 // reads r12 initial value and writes r12 after cycle 6.
5: mov r14, r12 // reads r12 initial value
6: nop
7: add r13, r12, r6 // reads r12 from instruction 4.
8: nop
9: mul r14, r12, r7 // reads r12 from instruction 1.
Other key architectural characteristics include varying width instruction slots between different instruction encodings and relatively small address spaces (20-bit pointer registers). The presence of varying-width instruction slots implies some code alignment restrictions for instructions which are branch or return targets.
In order to support the unusual architecture features of AI Engine, this repository adds LLVM support for several specific features:
- support for non-power of 2 pointers;
- improved TableGen support for specifying operand latencies and resource conflicts of exposed pipeline instructions;
- scheduler support for negative operand latencies (i.e. an instruction writing to a register may be scheduled after a corresponding use);
- scheduler support for slot assignment for instructions that can be issued in multiple VLIW slots;
- support for selecting relocations for instructions with multiple encodings;
- support for architectures with code alignment restrictions;
- improved register allocation support for complex register hierarchies, specifically related to spills of sub-registers of large compound-registers;
Support for Clang, LLD, binutils (e.g. 'llvm-objdump'), Compiler-RT, and LLVM-LIBC is also included.
Note that this repository does not implement a generic compiler and may not completely support other technologies. If you require a generic compiler or need to compile code for use with different technologies, you will need to select a different compiler. The implementation maturity is generally similar to other 'Experimental' LLVM architectures. For critical designs, please use the production compiler.
Modifications (c) Copyright 2022-2024 Advanced Micro Devices, Inc. or its affiliates
![]()
Welcome to the LLVM project!
This repository contains the source code for LLVM, a toolkit for the construction of highly optimized compilers, optimizers, and run-time environments.
The LLVM project has multiple components. The core of the project is itself called "LLVM". This contains all of the tools, libraries, and header files needed to process intermediate representations and convert them into object files. Tools include an assembler, disassembler, bitcode analyzer, and bitcode optimizer.
C-like languages use the Clang frontend. This component compiles C, C++, Objective-C, and Objective-C++ code into LLVM bitcode -- and from there into object files, using LLVM.
Other components include: the libc++ C++ standard library, the LLD linker, and more.
Consult the Getting Started with LLVM page for information on building and running LLVM.
For information on how to contribute to the LLVM project, please take a look at the Contributing to LLVM guide.
Join the LLVM Discourse forums, Discord chat, LLVM Office Hours or Regular sync-ups.
The LLVM project has adopted a code of conduct for participants to all modes of communication within the project.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llvm-aie
Similar Open Source Tools
llvm-aie
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors. AI Engine processors are in-order, exposed-pipeline VLIW processors focused on application acceleration for AI, Machine Learning, and DSP applications. The repository adds LLVM support for specific features like non-power of 2 pointers, operand latencies, resource conflicts, negative operand latencies, slot assignment, relocations, code alignment restrictions, and register allocation. It includes support for Clang, LLD, binutils, Compiler-RT, and LLVM-LIBC.
video-search-and-summarization
The NVIDIA AI Blueprint for Video Search and Summarization is a repository showcasing video search and summarization agent with NVIDIA NIM microservices. It enables industries to make better decisions faster by providing insightful, accurate, and interactive video analytics AI agents. These agents can perform tasks like video summarization and visual question-answering, unlocking new application possibilities. The repository includes software components like NIM microservices, ingestion pipeline, and CA-RAG module, offering a comprehensive solution for analyzing and summarizing large volumes of video data. The target audience includes video analysts, IT engineers, and GenAI developers who can benefit from the blueprint's 1-click deployment steps, easy-to-manage configurations, and customization options. The repository structure overview includes directories for deployment, source code, and training notebooks, along with documentation for detailed instructions. Hardware requirements vary based on deployment topology and dependencies like VLM and LLM, with different deployment methods such as Launchable Deployment, Docker Compose Deployment, and Helm Chart Deployment provided for various use cases.

unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.
airavata
Apache Airavata is a software framework for executing and managing computational jobs on distributed computing resources. It supports local clusters, supercomputers, national grids, academic and commercial clouds. Airavata utilizes service-oriented computing, distributed messaging, and workflow composition. It includes a server package with an API, client SDKs, and a general-purpose UI implementation called Apache Airavata Django Portal.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.
InfiniStore
InfiniStore is an open-source high-performance KV store designed to support LLM Inference clusters. It provides high-performance and low-latency KV cache transfer and reuse among inference nodes. In addition to inference clusters, it can be used as a standalone KV store for integration with LLM training or inference services. InfiniStore is currently integrated with vLLM via LMCache and is in progress for integration with SGLang and other inference engines.
eShopSupport
eShopSupport is a sample .NET application showcasing common use cases and development practices for building AI solutions in .NET, specifically Generative AI. It demonstrates a customer support application for an e-commerce website using a services-based architecture with .NET Aspire. The application includes support for text classification, sentiment analysis, text summarization, synthetic data generation, and chat bot interactions. It also showcases development practices such as developing solutions locally, evaluating AI responses, leveraging Python projects, and deploying applications to the Cloud.
dagger
Dagger is an open-source runtime for composable workflows, ideal for systems requiring repeatability, modularity, observability, and cross-platform support. It features a reproducible execution engine, a universal type system, a powerful data layer, native SDKs for multiple languages, an open ecosystem, an interactive command-line environment, batteries-included observability, and seamless integration with various platforms and frameworks. It also offers LLM augmentation for connecting to LLM endpoints. Dagger is suitable for AI agents and CI/CD workflows.
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).
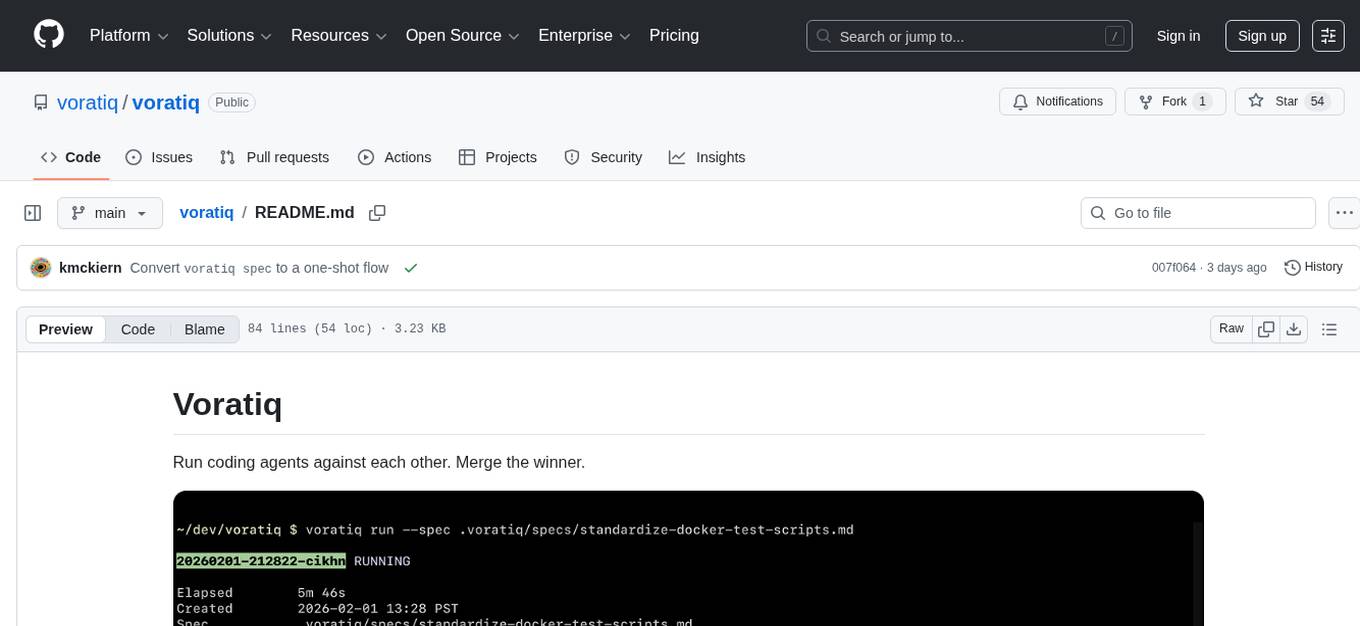
voratiq
Voratiq is a tool that allows users to run coding agents against each other and merge the winner. It enables users to select the best model for specific tasks, leading to higher quality code. Users can initialize a workspace, generate specs, run agent ensembles, review results, apply solutions, and clean up workspace. Voratiq positions users as architects and reviewers, shifting implementation onto an ensemble of agents. Each run is local, configurable, inspectable, and auditable, providing a detailed and structured approach to code quality improvement.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
NeMo-Agent-Toolkit
NVIDIA NeMo Agent toolkit is a flexible, lightweight, and unifying library that allows you to easily connect existing enterprise agents to data sources and tools across any framework. It is framework agnostic, promotes reusability, enables rapid development, provides profiling capabilities, offers observability features, includes an evaluation system, features a user interface for interaction, and supports the Model Context Protocol (MCP). With NeMo Agent toolkit, users can move quickly, experiment freely, and ensure reliability across all agent-driven projects.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
For similar tasks
llvm-aie
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors. AI Engine processors are in-order, exposed-pipeline VLIW processors focused on application acceleration for AI, Machine Learning, and DSP applications. The repository adds LLVM support for specific features like non-power of 2 pointers, operand latencies, resource conflicts, negative operand latencies, slot assignment, relocations, code alignment restrictions, and register allocation. It includes support for Clang, LLD, binutils, Compiler-RT, and LLVM-LIBC.
awesome-code-ai
A curated list of AI coding tools, including code completion, refactoring, and assistants. This list includes both open-source and commercial tools, as well as tools that are still in development. Some of the most popular AI coding tools include GitHub Copilot, CodiumAI, Codeium, Tabnine, and Replit Ghostwriter.
mlir-air
This repository contains tools and libraries for building AIR platforms, runtimes and compilers.
labs-ai-tools-vscode
AI Prompt Runner for VSCode is a research prototype project that provides a VSCode extension to run prompts. Users can install the extension, set a secret key, and run prompts to get results for any project. The tool is designed for developers and researchers to experiment with AI prompts within the VSCode environment.
aily-blockly
Aily Blockly is a blockly IDE under the Aily Project, providing AI-assisted programming capabilities for non-professional users. It aims to integrate numerous AI capabilities to help hardware developers develop more smoothly, ultimately achieving natural language programming. The software offers features like Engineering Project Management, Library Manager, Serial Debug Tool, AI Project Generation, AI Code Generation, AI Library Conversion, Development Board Configuration Generation, and Lightning Compilation Tool. It is currently in the alpha stage, suitable for prototype verification and educational teaching.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.