Best AI tools for< Optimize Models >
10 - AI tool Sites
Sylph AI
Sylph AI is an AI tool designed to maximize the potential of LLM applications by providing an auto-optimization library and an AI teammate to assist users in navigating complex LLM workflows. The tool aims to streamline the process of model fine-tuning, hyperparameter optimization, and auto-data labeling for LLM projects, ultimately enhancing productivity and efficiency for users.
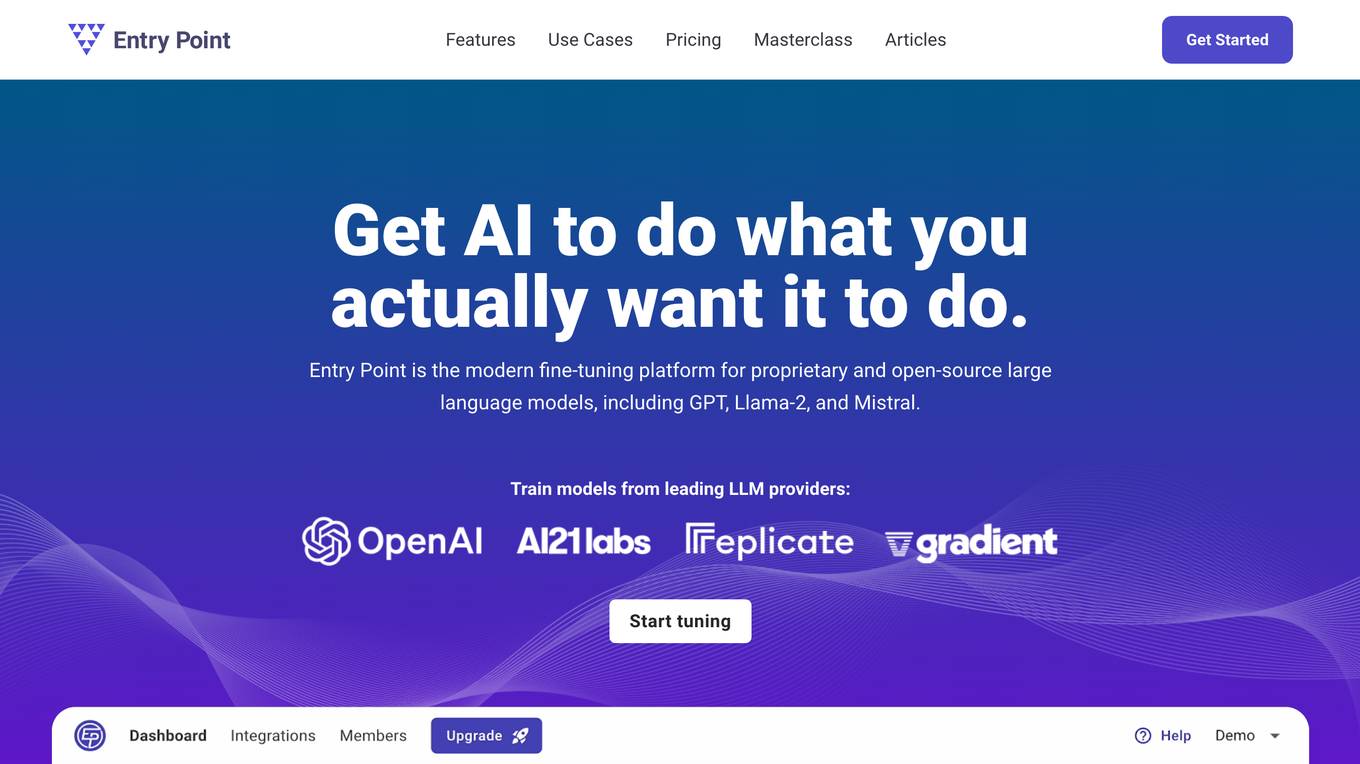
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Embedl
Embedl is an AI tool that specializes in developing advanced solutions for efficient AI deployment in embedded systems. With a focus on deep learning optimization, Embedl offers a cost-effective solution that reduces energy consumption and accelerates product development cycles. The platform caters to industries such as automotive, aerospace, and IoT, providing cutting-edge AI products that drive innovation and competitive advantage.
ONNX
ONNX is an open standard for machine learning interoperability, providing a common format to represent machine learning models. It defines a set of operators and a file format for AI developers to use models across various frameworks, tools, runtimes, and compilers. ONNX promotes interoperability, hardware access, and community engagement.

Bagel
Bagel is an AI & Cryptography Research Lab that focuses on making open source AI monetizable by leveraging novel cryptography techniques. Their innovative fine-tuning technology tracks the evolution of AI models, ensuring every contribution is rewarded. Bagel is built for autonomous AIs with large resource requirements and offers permissionless infrastructure for seamless information flow between machines and humans. The lab is dedicated to privacy-preserving machine learning through advanced cryptography schemes.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.

LM-Kit.NET
LM-Kit.NET is a comprehensive AI toolkit for .NET developers, offering a wide range of features such as AI agent integration, data processing, text analysis, translation, text generation, and model optimization. The toolkit enables developers to create intelligent and adaptable AI applications by providing tools for language models, sentiment analysis, emotion detection, and more. With a focus on performance optimization and security, LM-Kit.NET empowers developers to build cutting-edge AI solutions seamlessly into their C# and VB.NET applications.
30 - Open Source AI Tools

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀
effort
Effort is an example implementation of the bucketMul algorithm, which allows for real-time adjustment of the number of calculations performed during inference of an LLM model. At 50% effort, it performs as fast as regular matrix multiplications on Apple Silicon chips; at 25% effort, it is twice as fast while still retaining most of the quality. Additionally, users have the option to skip loading the least important weights.
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.

BitMat
BitMat is a Python package designed to optimize matrix multiplication operations by utilizing custom kernels written in Triton. It leverages the principles outlined in the "1bit-LLM Era" paper, specifically utilizing packed int8 data to enhance computational efficiency and performance in deep learning and numerical computing tasks.
ort
Ort is an unofficial ONNX Runtime 1.17 wrapper for Rust based on the now inactive onnxruntime-rs. ONNX Runtime accelerates ML inference on both CPU and GPU.
Building-AI-Applications-with-ChatGPT-APIs
This repository is for the book 'Building AI Applications with ChatGPT APIs' published by Packt. It provides code examples and instructions for mastering ChatGPT, Whisper, and DALL-E APIs through building innovative AI projects. Readers will learn to develop AI applications using ChatGPT APIs, integrate them with frameworks like Flask and Django, create AI-generated art with DALL-E APIs, and optimize ChatGPT models through fine-tuning.
Fay
Fay is an open-source digital human framework that offers different versions for various purposes. The '带货完整版' is suitable for online and offline salespersons. The '助理完整版' serves as a human-machine interactive digital assistant that can also control devices upon command. The 'agent版' is designed to be an autonomous agent capable of making decisions and contacting its owner. The framework provides updates and improvements across its different versions, including features like emotion analysis integration, model optimizations, and compatibility enhancements. Users can access detailed documentation for each version through the provided links.
vscode-ai-toolkit
AI Toolkit for Visual Studio Code simplifies generative AI app development by bringing together cutting-edge AI development tools and models from Azure AI Studio Catalog and other catalogs like Hugging Face. Users can browse the AI models catalog, download them locally, fine-tune, test, and deploy them to the cloud. The toolkit offers actions such as finding supported models, testing model inference, fine-tuning models locally or remotely, and deploying fine-tuned models to the cloud. It also provides optimized AI models for Windows and a Q&A section for common issues and resolutions.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
LLM-Fine-Tuning
This GitHub repository contains examples of fine-tuning open source large language models. It showcases the process of fine-tuning and quantizing large language models using efficient techniques like Lora and QLora. The repository serves as a practical guide for individuals looking to optimize the performance of language models through fine-tuning.
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.
KuiperLLama
KuiperLLama is a custom large model inference framework that guides users in building a LLama-supported inference framework with Cuda acceleration from scratch. The framework includes modules for architecture design, LLama2 model support, model quantization, Cuda basics, operator implementation, and fun tasks like text generation and storytelling. It also covers learning other commercial inference frameworks for comprehensive understanding. The project provides detailed tutorials and resources for developing and optimizing large models for efficient inference.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.
LLM4Opt
LLM4Opt is a collection of references and papers focusing on applying Large Language Models (LLMs) for diverse optimization tasks. The repository includes research papers, tutorials, workshops, competitions, and related collections related to LLMs in optimization. It covers a wide range of topics such as algorithm search, code generation, machine learning, science, industry, and more. The goal is to provide a comprehensive resource for researchers and practitioners interested in leveraging LLMs for optimization tasks.
generative-ai-on-aws
Generative AI on AWS by O'Reilly Media provides a comprehensive guide on leveraging generative AI models on the AWS platform. The book covers various topics such as generative AI use cases, prompt engineering, large-language models, fine-tuning techniques, optimization, deployment, and more. Authors Chris Fregly, Antje Barth, and Shelbee Eigenbrode offer insights into cutting-edge AI technologies and practical applications in the field. The book is a valuable resource for data scientists, AI enthusiasts, and professionals looking to explore generative AI capabilities on AWS.
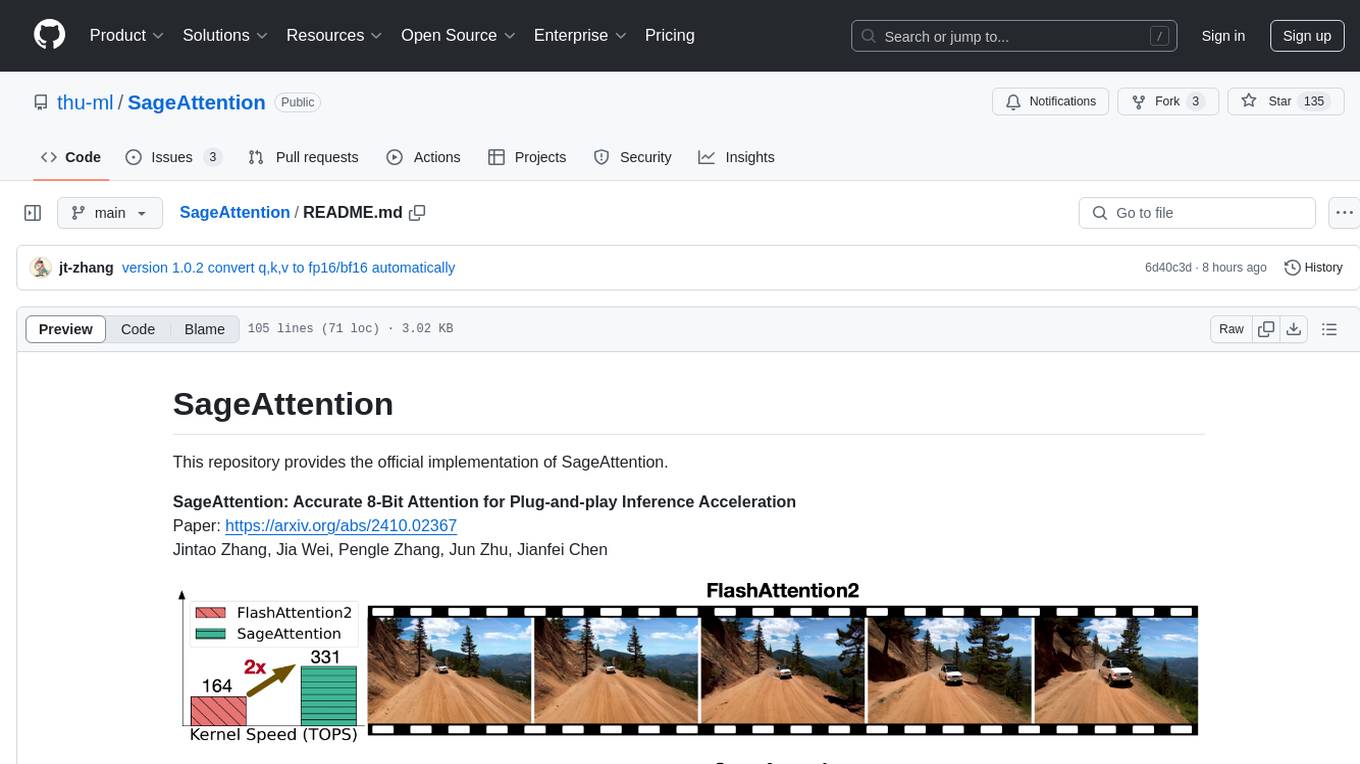
SageAttention
SageAttention is an official implementation of an accurate 8-bit attention mechanism for plug-and-play inference acceleration. It is optimized for RTX4090 and RTX3090 GPUs, providing performance improvements for specific GPU architectures. The tool offers a technique called 'smooth_k' to ensure accuracy in processing FP16/BF16 data. Users can easily replace 'scaled_dot_product_attention' with SageAttention for faster video processing.
efficient-transformers
Efficient Transformers Library provides reimplemented blocks of Large Language Models (LLMs) to make models functional and highly performant on Qualcomm Cloud AI 100. It includes graph transformations, handling for under-flows and overflows, patcher modules, exporter module, sample applications, and unit test templates. The library supports seamless inference on pre-trained LLMs with documentation for model optimization and deployment. Contributions and suggestions are welcome, with a focus on testing changes for model support and common utilities.
AmazonSageMakerCourse
Amazon SageMaker Course is a comprehensive guide for AWS Certified Machine Learning Specialty (MLS-C01) that covers training, optimizing, deploying, and integrating machine learning models in the AWS cloud. The course includes hands-on experience with AWS built-in algorithms, Bring Your Own models, and ready-to-use AI capabilities. It also provides a complete guide to AWS Certified Machine Learning – Specialty certification, along with a high-quality timed practice test. Participants will learn how to integrate trained models into their applications and receive prompt support through the course Q&A forum and private messaging.
ipex-llm
The `ipex-llm` repository is an LLM acceleration library designed for Intel GPU, NPU, and CPU. It provides seamless integration with various models and tools like llama.cpp, Ollama, HuggingFace transformers, LangChain, LlamaIndex, vLLM, Text-Generation-WebUI, DeepSpeed-AutoTP, FastChat, Axolotl, and more. The library offers optimizations for over 70 models, XPU acceleration, and support for low-bit (FP8/FP6/FP4/INT4) operations. Users can run different models on Intel GPUs, NPU, and CPUs with support for various features like finetuning, inference, serving, and benchmarking.

FloTorch
FloTorch is an innovative product designed to simplify and optimize the decision-making process for leveraging Large Language Models (LLMs) in Retrieval Augmented Generation (RAG) systems. It focuses on providing a well-architected framework, maximizing efficiency, eliminating complexity, accelerating selection, and fostering innovation. The tool offers a streamlined, user-friendly approach to help users achieve efficiency, accuracy, and cost-effectiveness in the fast-paced digital landscape of AI.
ai-edge-quantizer
AI Edge Quantizer is a tool designed for advanced developers to quantize converted LiteRT models. It aims to optimize performance on resource-demanding models by providing quantization recipes for edge device deployment. The tool supports dynamic quantization, weight-only quantization, and static quantization methods, allowing users to customize the quantization process for different hardware deployments. Users can specify quantization recipes to apply to source models, resulting in quantized LiteRT models ready for deployment. The tool also includes advanced features such as selective quantization and mixed precision schemes for fine-tuning quantization recipes.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.
transformer-tricks
A collection of tricks to simplify and speed up transformer models by removing parts from neural networks. Includes Flash normalization, slim attention, matrix-shrink, precomputing the first layer, and removing weights from skipless transformers. Follows recent trends in neural network optimization.
AI-Practices
AI-Practices is a systematic platform for learning and practicing artificial intelligence, covering a wide range of topics from foundational machine learning to advanced deep learning, reinforcement learning, generative models, large language models, multimodal learning, deployment optimization, distributed training, and agent reasoning. The platform provides a structured learning path, combining theoretical knowledge with practical implementation, following industrial code standards and including Kaggle competition solutions. It covers core algorithms in machine learning, deep learning, reinforcement learning, generative models, and large models. The platform supports popular deep learning frameworks like PyTorch, TensorFlow, and Keras, along with essential data science tools like NumPy, Pandas, and Scikit-Learn.
Model-Optimizer
NVIDIA Model Optimizer is a library that offers state-of-the-art model optimization techniques like quantization, distillation, pruning, speculative decoding, and sparsity to accelerate models. It supports inputs of Hugging Face, PyTorch, or ONNX models, provides Python APIs for easy composition of optimization techniques, and exports optimized quantized checkpoints. Integrated with NVIDIA Megatron-Bridge, Megatron-LM, and Hugging Face Accelerate for training required inference optimization techniques. The generated quantized checkpoint is ready for deployment in downstream inference frameworks like SGLang, TensorRT-LLM, TensorRT, or vLLM.
amd-shark-ai
The amdshark-ai repository contains the amdshark Modeling and Serving Libraries, which include sub-projects like shortfin for high performance inference, amdsharktank for model recipes and conversion tools, and amdsharktuner for tuning program performance. Developers can find API documentation, programming guides, and support matrix for various models within the repository.
20 - OpenAI Gpts





Apple CoreML Complete Code Expert
A detailed expert trained on all 3,018 pages of Apple CoreML, offering complete coding solutions. Saving time? https://www.buymeacoffee.com/parkerrex ☕️❤️
LFG GPT
Talk to Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning (LFG)
Back Propagation
I'm Back Propagation, here to help you understand and apply back propagation techniques to your AI models.
Code Solver
ML/DL expert focused on mathematical modeling, Kaggle competitions, and advanced ML models.


Modelos de Negocios GPT
Guía paso a paso para la creación y mejora de modelos de negocio usando la metodología Business Model Canvas.