
transformer-tricks
A collection of tricks and tools to speed up transformer models
Stars: 179
A collection of tricks to simplify and speed up transformer models by removing parts from neural networks. Includes Flash normalization, slim attention, matrix-shrink, precomputing the first layer, and removing weights from skipless transformers. Follows recent trends in neural network optimization.
README:
A collection of tricks to simplify and speed up transformer models:
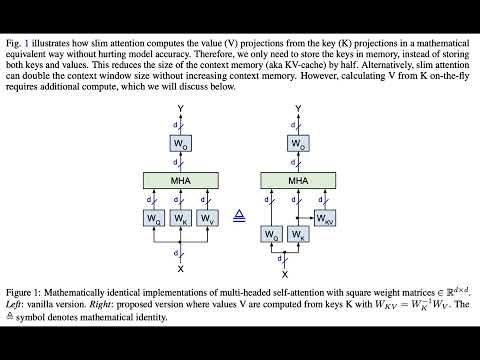
- Slim attention: [paper], [video], [podcast], [notebook], [code-readme], 🤗 [article], [reddit]
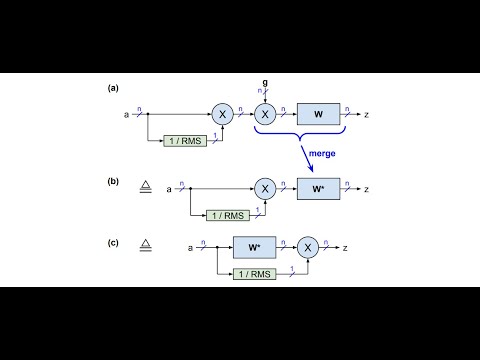
- Flash normalization: [paper], [video], [podcast], [notebook], [code-readme]
- Matrix-shrink [work in progress]: [paper]
- Precomputing the first layer: [paper], [podcast]
- Removing weights from skipless transformers: [paper], [podcast], [notebook]
Many of these tricks follow a recent trend of removing parts from neural networks such as RMSNorm’s removal of mean centering from LayerNorm, PaLM's removal of bias-parameters, decoder-only transformer's removal of the encoder stack, and of course transformer’s revolutionary removal of recurrent layers.
For example, our FlashNorm removes the weights from RMSNorm and merges them with the next linear layer. And slim attention removes the entire V-cache from the context memory for MHA transformers.
Install the transformer tricks package:
pip install transformer-tricksAlternatively, to run from latest repo:
git clone https://github.com/OpenMachine-ai/transformer-tricks.git
python3 -m venv .venv
source .venv/bin/activate
pip3 install --quiet -r requirements.txtFollow the links below for documentation of the python code in this directory:
The papers are accompanied by the following Jupyter notebooks:
- Slim attention:
- Flash normalization:
- Removing weights from skipless transformers:
Please subscribe to our newsletter on substack to get the latest news about this project. We will never send you more than one email per month.
We pay cash for high-impact contributions. Please check out CONTRIBUTING for how to get involved.
The Transformer Tricks project is currently sponsored by OpenMachine. We'd love to hear from you if you'd like to join us in supporting this project.
Please give us a ⭐ if you like this repo, and check out TinyFive
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for transformer-tricks
Similar Open Source Tools
transformer-tricks
A collection of tricks to simplify and speed up transformer models by removing parts from neural networks. Includes Flash normalization, slim attention, matrix-shrink, precomputing the first layer, and removing weights from skipless transformers. Follows recent trends in neural network optimization.
read-frog
Read-frog is a powerful text analysis tool designed to help users extract valuable insights from text data. It offers a wide range of features including sentiment analysis, keyword extraction, entity recognition, and text summarization. With its user-friendly interface and robust algorithms, Read-frog is suitable for both beginners and advanced users looking to analyze text data for various purposes such as market research, social media monitoring, and content optimization. Whether you are a data scientist, marketer, researcher, or student, Read-frog can streamline your text analysis workflow and provide actionable insights to drive decision-making and enhance productivity.
Flare
Flare is an open-source AI-powered decentralized social network client for Android/iOS/macOS, consolidating multiple social networks into one platform. It allows cross-posting content, ensures privacy, and plans to implement features like mixed timeline, AI-powered functions, and support for various platforms. The project is in active development and aims to provide a seamless social networking experience for users.
core
OpenSumi is a framework designed to help users quickly build AI Native IDE products. It provides a set of tools and templates for creating Cloud IDEs, Desktop IDEs based on Electron, CodeBlitz web IDE Framework, Lite Web IDE on the Browser, and Mini-App liked IDE. The framework also offers documentation for users to refer to and a detailed guide on contributing to the project. OpenSumi encourages contributions from the community and provides a platform for users to report bugs, contribute code, or improve documentation. The project is licensed under the MIT license and contains third-party code under other open source licenses.
anything
Anything is an open automation tool built in Rust that aims to rebuild Zapier, enabling local AI to perform a wide range of tasks beyond chat functionalities. The tool focuses on extensibility without sacrificing understandability, allowing users to create custom extensions in Rust or other interpreted languages like Python or Typescript. It features an embedded SQLite DB, a WYSIWYG editor, event system, cron trigger, HTTP and CLI extensions, with plans for additional extensions like Deno, Python, and Local AI. The tool is designed to be user-friendly, with a file-first state approach, portable triggers, actions, and flows, and a human-centric file and folder naming convention. It does not require Docker, making it easy to run on low-powered devices for 24/7 self-hosting. The event processing is focused on simplicity and visibility, with extensibility through custom extensions and a marketplace for templates, actions, and triggers.
MLE-agent
MLE-Agent is an intelligent companion designed for machine learning engineers and researchers. It features autonomous baseline creation, integration with Arxiv and Papers with Code, smart debugging, file system organization, comprehensive tools integration, and an interactive CLI chat interface for seamless AI engineering and research workflows.


lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.
esp-ai
ESP-AI provides a complete AI conversation solution for your development board, including IAT+LLM+TTS integration solutions for ESP32 series development boards. It can be injected into projects without affecting existing ones. By providing keys from platforms like iFlytek, Jiling, and local services, you can run the services without worrying about interactions between services or between development boards and services. The project's server-side code is based on Node.js, and the hardware code is based on Arduino IDE.
amplication
Amplication is a robust, open-source development platform designed to revolutionize the creation of scalable and secure .NET and Node.js applications. It automates backend applications development, ensuring consistency, predictability, and adherence to the highest standards with code that's built to scale. The user-friendly interface fosters seamless integration of APIs, data models, databases, authentication, and authorization. Built on a flexible, plugin-based architecture, Amplication allows effortless customization of the code and offers a diverse range of integrations. With a strong focus on collaboration, Amplication streamlines team-oriented development, making it an ideal choice for groups of all sizes, from startups to large enterprises. It enables users to concentrate on business logic while handling the heavy lifting of development. Experience the fastest way to develop .NET and Node.js applications with Amplication.

LakeSoul
LakeSoul is a cloud-native Lakehouse framework that supports scalable metadata management, ACID transactions, efficient and flexible upsert operation, schema evolution, and unified streaming & batch processing. It supports multiple computing engines like Spark, Flink, Presto, and PyTorch, and computing modes such as batch, stream, MPP, and AI. LakeSoul scales metadata management and achieves ACID control by using PostgreSQL. It provides features like automatic compaction, table lifecycle maintenance, redundant data cleaning, and permission isolation for metadata.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.
BabelDuck
BabelDuck is a highly customizable AI oral conversation practice application for language learners at all levels, with a focus on being more beginner-friendly. It aims to minimize the threshold and mental burden of oral expression practice. The tool supports various AI conversation features such as managing multiple dialogues, customizing system prompts, and providing suggestions for grammar, translation, or expression refinement without interrupting the current conversation. Users can seek further discussion through sub-dialogues when in doubt about AI suggestions, seamlessly returning to the original conversation afterward. BabelDuck also offers voice input and output, integrates browser-built text-to-speech, and Azure TTS, and supports different dialogue preferences, data stored locally for user privacy, multilingual interface, and built-in tutorials.
Anima
Anima is the first open-source 33B Chinese large language model based on QLoRA, supporting DPO alignment training and open-sourcing a 100k context window model. The latest update includes AirLLM, a library that enables inference of 70B LLM from a single GPU with just 4GB memory. The tool optimizes memory usage for inference, allowing large language models to run on a single 4GB GPU without the need for quantization or other compression techniques. Anima aims to democratize AI by making advanced models accessible to everyone and contributing to the historical process of AI democratization.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.
LMCache
LMCache is a serving engine extension designed to reduce time to first token (TTFT) and increase throughput, particularly in long-context scenarios. It stores key-value caches of reusable texts across different locations like GPU, CPU DRAM, and Local Disk, allowing the reuse of any text in any serving engine instance. By combining LMCache with vLLM, significant delay savings and GPU cycle reduction are achieved in various large language model (LLM) use cases, such as multi-round question answering and retrieval-augmented generation (RAG). LMCache provides integration with the latest vLLM version, offering both online serving and offline inference capabilities. It supports sharing key-value caches across multiple vLLM instances and aims to provide stable support for non-prefix key-value caches along with user and developer documentation.
For similar tasks

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀
effort
Effort is an example implementation of the bucketMul algorithm, which allows for real-time adjustment of the number of calculations performed during inference of an LLM model. At 50% effort, it performs as fast as regular matrix multiplications on Apple Silicon chips; at 25% effort, it is twice as fast while still retaining most of the quality. Additionally, users have the option to skip loading the least important weights.
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.

BitMat
BitMat is a Python package designed to optimize matrix multiplication operations by utilizing custom kernels written in Triton. It leverages the principles outlined in the "1bit-LLM Era" paper, specifically utilizing packed int8 data to enhance computational efficiency and performance in deep learning and numerical computing tasks.
ort
Ort is an unofficial ONNX Runtime 1.17 wrapper for Rust based on the now inactive onnxruntime-rs. ONNX Runtime accelerates ML inference on both CPU and GPU.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.