
neural-compressor
SOTA low-bit LLM quantization (INT8/FP8/MXFP8/INT4/MXFP4/NVFP4) & sparsity; leading model compression techniques on PyTorch, TensorFlow, and ONNX Runtime
Stars: 2584
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.
README:
An open-source Python library supporting popular model compression techniques on all mainstream deep learning frameworks (TensorFlow, PyTorch, and ONNX Runtime)
Architecture | Workflow | LLMs Recipes | Results | Documentations
Intel® Neural Compressor aims to provide popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, and ONNX Runtime, as well as Intel extensions such as Intel Extension for TensorFlow and Intel Extension for PyTorch. In particular, the tool provides the key features, typical examples, and open collaborations as below:
-
Support a wide range of Intel hardware such as Intel Gaudi Al Accelerators, Intel Core Ultra Processors, Intel Xeon Scalable Processors, Intel Xeon CPU Max Series, Intel Data Center GPU Flex Series, and Intel Data Center GPU Max Series with extensive testing; support AMD CPU, ARM CPU, and NVidia GPU through ONNX Runtime with limited testing; support NVidia GPU for some WOQ algorithms like AutoRound and HQQ.
-
Validate popular LLMs such as LLama2, Falcon, GPT-J, Bloom, OPT, and more than 10,000 broad models such as Stable Diffusion, BERT-Large, and ResNet50 from popular model hubs such as Hugging Face, Torch Vision, and ONNX Model Zoo, with automatic accuracy-driven quantization strategies
-
Collaborate with cloud marketplaces such as Google Cloud Platform, Amazon Web Services, and Azure, software platforms such as Tencent TACO and Microsoft Olive, and open AI ecosystem such as Hugging Face, PyTorch, ONNX, ONNX Runtime, and Lightning AI
- [2025/12] NVFP4 quantization experimental support
- [2025/10] MXFP8 / MXFP4 quantization experimental support
- [2025/09] FP8 dynamic quantization, including Linear, FusedMoE on Intel Gaudi AI Accelerators
- [2025/05] FP8 static quantization of DeepSeek V3/R1 model on Intel Gaudi AI Accelerators
- [2025/03] VLM quantization in transformers-like API on Intel CPU/GPU
Choose the necessary framework dependencies to install based on your deploy environment.
- Install intel_extension_for_pytorch for CPU
- Install intel_extension_for_pytorch for Intel GPU
-
Use Docker Image with torch installed for HPU
Note: There is a version mapping between Intel Neural Compressor and Gaudi Software Stack, please refer to this table and make sure to use a matched combination. - Install torch for other platform
- Install TensorFlow
# Install 2.X API + Framework extension API + PyTorch dependency
pip install neural-compressor[pt]
# Install 2.X API + Framework extension API + TensorFlow dependency
pip install neural-compressor[tf]
Note: Further installation methods can be found under Installation Guide. check out our FAQ for more details.
After successfully installing these packages, try your first quantization program. Following example code demonstrates FP8 Quantization, it is supported by Intel Gaudi2 AI Accelerator.
To try on Intel Gaudi2, docker image with Gaudi Software Stack is recommended, please refer to following script for environment setup. More details can be found in Gaudi Guide.
Run a container with an interactive shell, more info
docker run -it --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --net=host --ipc=host vault.habana.ai/gaudi-docker/1.23.0/ubuntu24.04/habanalabs/pytorch-installer-2.9.0:latest
Note: Since Habana software >= 1.21.0,
PT_HPU_LAZY_MODE=0is the default setting. However, most low-precision functions (such asconvert_from_uint4) do not support this setting. Therefore, we recommend settingPT_HPU_LAZY_MODE=1to maintain compatibility.
Run the example,
from neural_compressor.torch.quantization import (
FP8Config,
prepare,
convert,
)
import torch
import torchvision.models as models
model = models.resnet18()
qconfig = FP8Config(fp8_config="E4M3")
model = prepare(model, qconfig)
# Customer defined calibration. Below is a dummy calibration
model(torch.randn(1, 3, 224, 224).to("hpu"))
model = convert(model)
output = model(torch.randn(1, 3, 224, 224).to("hpu")).to("cpu")
print(output.shape)
More FP8 quantization doc.
Following example code demonstrates weight-only large language model loading on Intel Gaudi2 AI Accelerator.
from neural_compressor.torch.quantization import load
model_name = "TheBloke/Llama-2-7B-GPTQ"
model = load(
model_name_or_path=model_name,
format="huggingface",
device="hpu",
torch_dtype=torch.bfloat16,
)
Note: Intel Neural Compressor will convert the model format from auto-gptq to hpu format on the first load and save hpu_model.safetensors to the local cache directory for the next load. So it may take a while to load for the first time.
| Overview | |||||||
|---|---|---|---|---|---|---|---|
| Architecture | Workflow | APIs | LLMs Recipes | Examples | |||
| PyTorch Extension APIs | |||||||
| Overview | |||||||
| Dynamic Quantization | Static Quantization | Smooth Quantization | |||||
| Weight-Only Quantization | FP8 Quantization | Mixed Precision | |||||
| MX Quantization | NVFP4 Quantization | ||||||
| Tensorflow Extension APIs | |||||||
| Overview | Static Quantization | Smooth Quantization | |||||
| Transformers-like APIs | |||||||
| Overview | |||||||
| Other Modules | |||||||
| Auto Tune | |||||||
Note: From 3.0 release, we recommend to use 3.X API. Compression techniques during training such as QAT, Pruning, Distillation only available in 2.X API currently.
- arXiv: Faster Inference of LLMs using FP8 on the Intel Gaudi (Mar 2025)
- PyTorch landscape: PyTorch general optimizations (Mar 2025)
- Blog on SqueezeBits: [Intel Gaudi] #4. FP8 Quantization (Jan 2025)
- EMNLP'2024: Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs (Sep 2024)
- arXiv: Efficient Post-training Quantization with FP8 Formats (Sep 2023)
- arXiv: Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs (Sep 2023)
Note: View Full Publication List.
- GitHub Issues: mainly for bug reports, new feature requests, question asking, etc.
- Email: welcome to raise any interesting research ideas on model compression techniques by email for collaborations.
- Discord Channel: join the discord channel for more flexible technical discussion.
- WeChat group: scan the QA code to join the technical discussion.
{kind=link}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for neural-compressor
Similar Open Source Tools
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.

intel-extension-for-transformers
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples: * Seamless user experience of model compressions on Transformer-based models by extending [Hugging Face transformers](https://github.com/huggingface/transformers) APIs and leveraging [Intel® Neural Compressor](https://github.com/intel/neural-compressor) * Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper [Fast Distilbert on CPUs](https://arxiv.org/abs/2211.07715) and [QuaLA-MiniLM: a Quantized Length Adaptive MiniLM](https://arxiv.org/abs/2210.17114), and NeurIPS 2021's paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754)) * Optimized Transformer-based model packages such as [Stable Diffusion](examples/huggingface/pytorch/text-to-image/deployment/stable_diffusion), [GPT-J-6B](examples/huggingface/pytorch/text-generation/deployment), [GPT-NEOX](examples/huggingface/pytorch/language-modeling/quantization#2-validated-model-list), [BLOOM-176B](examples/huggingface/pytorch/language-modeling/inference#BLOOM-176B), [T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), [Flan-T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), and end-to-end workflows such as [SetFit-based text classification](docs/tutorials/pytorch/text-classification/SetFit_model_compression_AGNews.ipynb) and [document level sentiment analysis (DLSA)](workflows/dlsa) * [NeuralChat](intel_extension_for_transformers/neural_chat), a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of [plugins](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/docs/advanced_features.md) such as [Knowledge Retrieval](./intel_extension_for_transformers/neural_chat/pipeline/plugins/retrieval/README.md), [Speech Interaction](./intel_extension_for_transformers/neural_chat/pipeline/plugins/audio/README.md), [Query Caching](./intel_extension_for_transformers/neural_chat/pipeline/plugins/caching/README.md), and [Security Guardrail](./intel_extension_for_transformers/neural_chat/pipeline/plugins/security/README.md). This framework supports Intel Gaudi2/CPU/GPU. * [Inference](https://github.com/intel/neural-speed/tree/main) of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting [GPT-NEOX](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox), [LLAMA](https://github.com/intel/neural-speed/tree/main/neural_speed/models/llama), [MPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/mpt), [FALCON](https://github.com/intel/neural-speed/tree/main/neural_speed/models/falcon), [BLOOM-7B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/bloom), [OPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/opt), [ChatGLM2-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/chatglm), [GPT-J-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptj), and [Dolly-v2-3B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox). Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed [Sapphire Rapids](https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html).

llama.cpp
llama.cpp is a C++ implementation of LLaMA, a large language model from Meta. It provides a command-line interface for inference and can be used for a variety of tasks, including text generation, translation, and question answering. llama.cpp is highly optimized for performance and can be run on a variety of hardware, including CPUs, GPUs, and TPUs.

helicone
Helicone is an open-source observability platform designed for Language Learning Models (LLMs). It logs requests to OpenAI in a user-friendly UI, offers caching, rate limits, and retries, tracks costs and latencies, provides a playground for iterating on prompts and chat conversations, supports collaboration, and will soon have APIs for feedback and evaluation. The platform is deployed on Cloudflare and consists of services like Web (NextJs), Worker (Cloudflare Workers), Jawn (Express), Supabase, and ClickHouse. Users can interact with Helicone locally by setting up the required services and environment variables. The platform encourages contributions and provides resources for learning, documentation, and integrations.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
L3AGI
L3AGI is an open-source tool that enables AI Assistants to collaborate together as effectively as human teams. It provides a robust set of functionalities that empower users to design, supervise, and execute both autonomous AI Assistants and Teams of Assistants. Key features include the ability to create and manage Teams of AI Assistants, design and oversee standalone AI Assistants, equip AI Assistants with the ability to retain and recall information, connect AI Assistants to an array of data sources for efficient information retrieval and processing, and employ curated sets of tools for specific tasks. L3AGI also offers a user-friendly interface, APIs for integration with other systems, and a vibrant community for support and collaboration.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
rwkv-qualcomm
This repository provides support for inference RWKV models on Qualcomm HTP (Hexagon Tensor Processor) using QNN SDK. It supports RWKV v5, v6, and experimentally v7 models, inference using Qualcomm CPU, GPU, or HTP as the backend, whole-model float16 inference, activation INT16 and weights INT8 quantized inference, and activation INT16 and weights INT4/INT8 mixed quantized inference. Users can convert model weights to QNN model library files, generate HTP context cache, and run inference on Qualcomm Snapdragon SM8650 with HTP v75. The project requires QNN SDK, AIMET toolkit, and specific hardware for verification.

SuperAGI
SuperAGI is an open-source framework designed to build, manage, and run autonomous AI agents. It enables developers to create production-ready and scalable agents, extend agent capabilities with toolkits, and interact with agents through a graphical user interface. The framework allows users to connect to multiple Vector DBs, optimize token usage, store agent memory, utilize custom fine-tuned models, and automate tasks with predefined steps. SuperAGI also provides a marketplace for toolkits that enable agents to interact with external systems and third-party plugins.
amd-shark-ai
The amdshark-ai repository contains the amdshark Modeling and Serving Libraries, which include sub-projects like shortfin for high performance inference, amdsharktank for model recipes and conversion tools, and amdsharktuner for tuning program performance. Developers can find API documentation, programming guides, and support matrix for various models within the repository.

VideoRefer
VideoRefer Suite is a tool designed to enhance the fine-grained spatial-temporal understanding capabilities of Video Large Language Models (Video LLMs). It consists of three primary components: Model (VideoRefer) for perceiving, reasoning, and retrieval for user-defined regions at any specified timestamps, Dataset (VideoRefer-700K) for high-quality object-level video instruction data, and Benchmark (VideoRefer-Bench) to evaluate object-level video understanding capabilities. The tool can understand any object within a video.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.
Ultimate-Data-Science-Toolkit---From-Python-Basics-to-GenerativeAI
Ultimate Data Science Toolkit is a comprehensive repository covering Python basics to Generative AI. It includes modules on Python programming, data analysis, statistics, machine learning, MLOps, case studies, and deep learning. The repository provides detailed tutorials on various topics such as Python data structures, control statements, functions, modules, object-oriented programming, exception handling, file handling, web API, databases, list comprehension, lambda functions, Pandas, Numpy, data visualization, statistical analysis, supervised and unsupervised machine learning algorithms, model serialization, ML pipeline orchestration, case studies, and deep learning concepts like neural networks and autoencoders.
ai-server
AI Server is a self-hosted private gateway that orchestrates AI requests through a single integration, allowing control over AI providers like LLM, Diffusion, and image transformation. It dynamically delegates requests across various providers, including LLM APIs, Media APIs, and Comfy UI with FFmpeg Agents. The tool also offers built-in UIs for tasks like chat, text-to-image, image-to-text, image upscaling, speech-to-text, and text-to-speech. Additionally, it provides admin UIs for managing AI and media providers, API key access, and monitoring background jobs and AI requests.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
For similar tasks
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
ai-edge-quantizer
AI Edge Quantizer is a tool designed for advanced developers to quantize converted LiteRT models. It aims to optimize performance on resource-demanding models by providing quantization recipes for edge device deployment. The tool supports dynamic quantization, weight-only quantization, and static quantization methods, allowing users to customize the quantization process for different hardware deployments. Users can specify quantization recipes to apply to source models, resulting in quantized LiteRT models ready for deployment. The tool also includes advanced features such as selective quantization and mixed precision schemes for fine-tuning quantization recipes.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
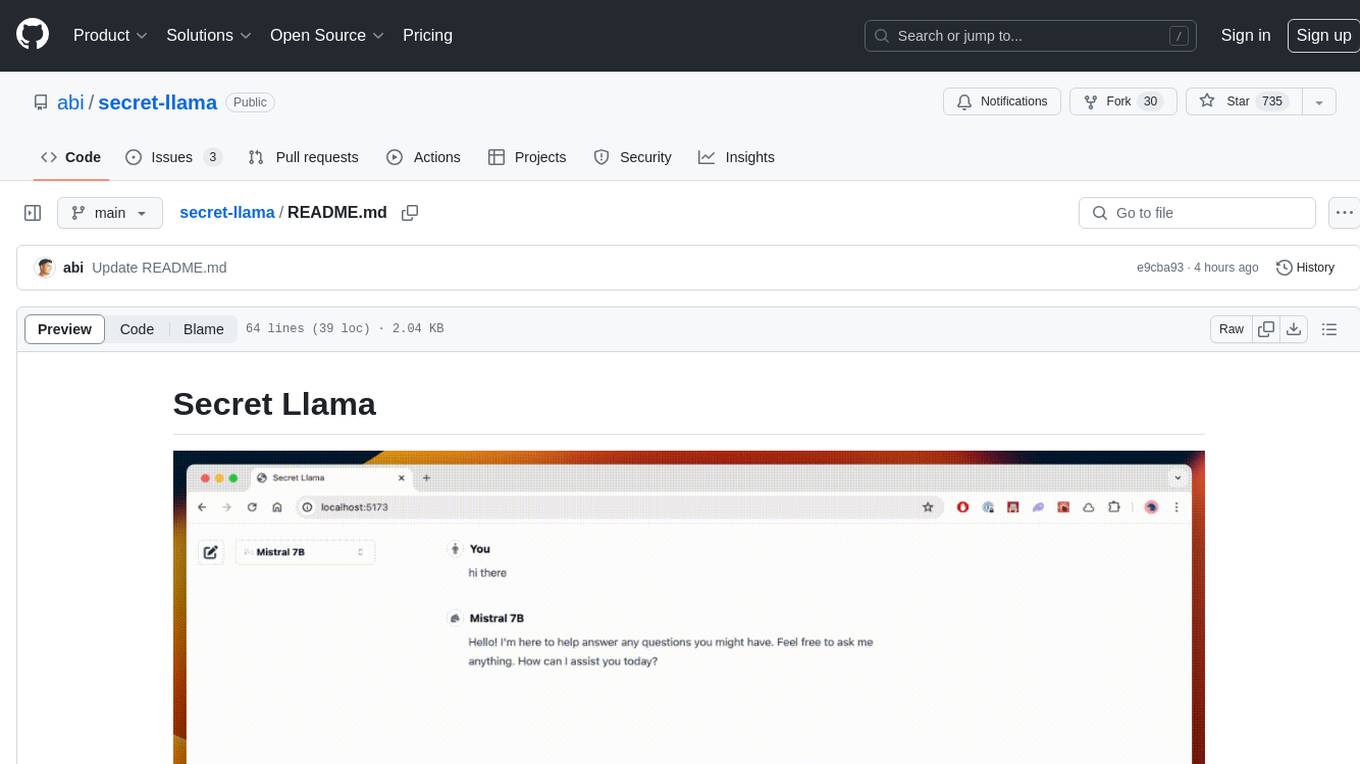
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.

baal
Baal is an active learning library that supports both industrial applications and research use cases. It provides a framework for Bayesian active learning methods such as Monte-Carlo Dropout, MCDropConnect, Deep ensembles, and Semi-supervised learning. Baal helps in labeling the most uncertain items in the dataset pool to improve model performance and reduce annotation effort. The library is actively maintained by a dedicated team and has been used in various research papers for production and experimentation.
LLM-Fine-Tuning
This GitHub repository contains examples of fine-tuning open source large language models. It showcases the process of fine-tuning and quantizing large language models using efficient techniques like Lora and QLora. The repository serves as a practical guide for individuals looking to optimize the performance of language models through fine-tuning.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.