
llm-awq
[MLSys 2024 Best Paper Award] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Stars: 2636
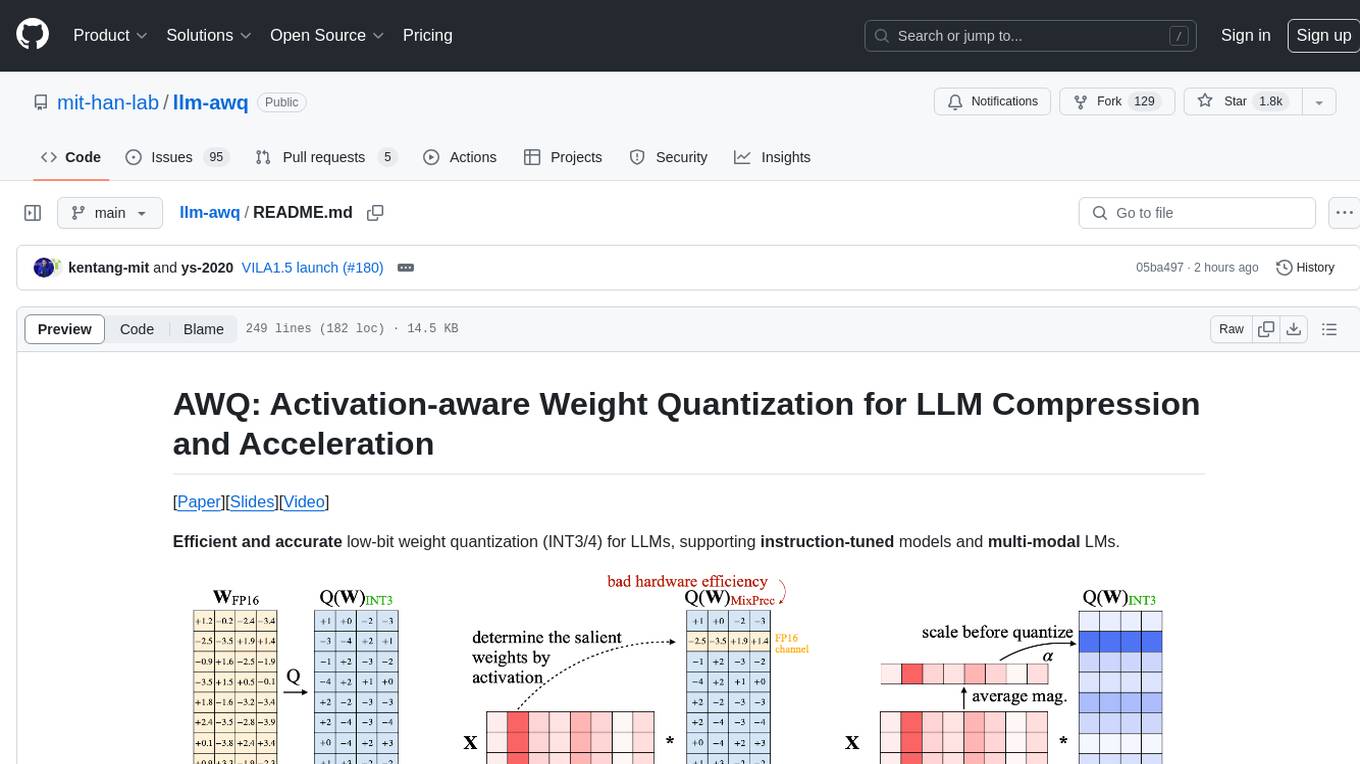
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
README:
Efficient and accurate low-bit weight quantization (INT3/4) for LLMs, supporting instruction-tuned models and multi-modal LMs.

The current release supports:
- AWQ search for accurate quantization.
- Pre-computed AWQ model zoo for LLMs (Llama-1/2/3, OPT, CodeLlama, StarCoder, Vicuna, VILA, LLaVA; load to generate quantized weights).
- Memory-efficient 4-bit Linear in PyTorch.
- Efficient CUDA kernel implementation for fast inference (support context and decoding stage).
- Examples on 4-bit inference of an instruction-tuned model (Vicuna) and multi-modal LM (VILA).
- Chunk prefilling for faster prefilling in multi-round Q&A setting.
- State-of-the-art prefilling speed of LLMs/VLMs on edge devices: TinyChat 2.0.
Thanks to AWQ, TinyChat can deliver more efficient responses with LLM/VLM chatbots through 4-bit inference.
- TinyChat with LLaMA-3-8b on RTX 4090 (2.7x faster than FP16):

- TinyChat with LLaMA-3-8b on Jetson Orin (2.9x faster than FP16):

TinyChat also supports inference with vision language models (e.g., VILA, LLaVA). In the following examples, W4A16 quantized models from VILA family are launched with TinyChat.
- TinyChat with NVILA-8B on RTX 4090 (single-image inputs):

- TinyChat with NVILA-8B on RTX 4090 (multi-image inputs):

- TinyChat with video reasoning:
https://github.com/user-attachments/assets/b68a7a0d-5175-4030-985b-5ae0ae94f874
Prompt: What might be the next step according to the video?
Answer: The next step in the video could be to place the shaped dough onto a baking sheet and let it rise before baking.
Online demo: https://vila.mit.edu
Check out TinyChat, which offers a turn-key solution for on-device inference of LLMs and VLMs on resource-constrained edge platforms. With TinyChat, it is now possible to efficiently run large models on small and low-power devices even without Internet connection!
- [2024/10] 🔥⚡ Explore advancements in TinyChat 2.0, the latest version with significant advancements in prefilling speed of Edge LLMs and VLMs, 1.5-1.7x faster than the previous version of TinyChat. Please refer to the README and blog for more details.
- [2024/05] 🏆 AWQ receives the Best Paper Award at MLSys 2024. 🎉
- [2024/05] 🔥 The VILA-1.5 model family which features video understanding is now supported in AWQ and TinyChat. Check out out online demo powered by TinyChat here. Example is here.
- [2024/05] 🔥 AMD adopts AWQ to improve LLM serving efficiency.
- [2024/04] 🔥 We released AWQ and TinyChat support for The Llama-3 model family! Check out our example here.
- [2024/02] 🔥 AWQ has been accepted to MLSys 2024!
- [2024/02] 🔥 We supported VILA Vision Languague Models in AWQ & TinyChat! Check our latest demos with multi-image inputs!
- [2024/02] 🔥 We released new version of quantized GEMM/GEMV kernels in TinyChat, leading to 38 tokens/second inference speed on NVIDIA Jetson Orin!
- [2024/01] 🔥 AWQ has been integrated by Google Vertex AI!
- [2023/11] 🔥 AWQ has been integrated by Amazon Sagemaker Containers!
- [2023/11] 🔥 We added AWQ support and pre-computed search results for CodeLlama, StarCoder, StableCode models. Checkout our model zoo here!
- [2023/11] 🔥 AWQ is now integrated natively in Hugging Face transformers through
from_pretrained. You can either load quantized models from the Hub or your own HF quantized models. - [2023/10] AWQ is integrated into NVIDIA TensorRT-LLM
- [2023/09] AWQ is integrated into Intel Neural Compressor, FastChat, vLLM, HuggingFace TGI, and LMDeploy.
- [2023/09] ⚡ Check out our latest TinyChat, which is ~2x faster than the first release on Orin!
- [2023/09] ⚡ Check out AutoAWQ, a third-party implementation to make AWQ easier to expand to new models, improve inference speed, and integrate into Huggingface.
- [2023/07] 🔥 We released TinyChat, an efficient and lightweight chatbot interface based on AWQ. TinyChat enables efficient LLM inference on both cloud and edge GPUs. Llama-2-chat models are supported! Check out our implementation here.
- [2023/07] 🔥 We added AWQ support and pre-computed search results for Llama-2 models (7B & 13B). Checkout our model zoo here!
- [2023/07] We extended the support for more LLM models including MPT, Falcon, and BLOOM.
- VILA online demo: Visual Language Models efficiently supported by AWQ & TinyChat.
- LLM on the Edge: AWQ and TinyChat support edge GPUs such as NVIDIA Jetson Orin.
- VLMs on Laptop: Follow the instructions to deploy VLMs on NVIDIA Laptops with TinyChat.
- Gradio Server: Try to build your own VLM online demo with AWQ and TinyChat!
- QServe: 🔥 [New] Efficient and accurate serving system for large-scale LLM inference.
- Clone this repository and navigate to AWQ folder
git clone https://github.com/mit-han-lab/llm-awq
cd llm-awq
- Install Package
conda create -n awq python=3.10 -y
conda activate awq
pip install --upgrade pip # enable PEP 660 support
pip install -e .
-
For edge devices like Orin, before running the commands above, please:
- Modify pyproject.toml by commenting out this line.
- Manually install precompiled PyTorch binaries (>=2.0.0) from NVIDIA. You also need to install torchvision from this website when running NVILA.
- Set the appropriate Python version for conda environment (e.g.,
conda create -n awq python=3.8 -yfor JetPack 5).
- Install efficient W4A16 (4-bit weight, 16-bit activation) CUDA kernel and optimized FP16 kernels (e.g. layernorm, positional encodings).
cd awq/kernels
python setup.py install
- In order to run AWQ and TinyChat with NVILA model family, please install VILA:
git clone https://github.com/NVlabs/VILA.git
cd VILA
pip install -e .We provide pre-computed AWQ search results for multiple model families, including LLaMA, OPT, Vicuna, and LLaVA. To get the pre-computed AWQ search results, run:
# git lfs install # install git lfs if not already
git clone https://huggingface.co/datasets/mit-han-lab/awq-model-zoo awq_cacheThe detailed support list:
| Models | Sizes | INT4-g128 | INT3-g128 |
|---|---|---|---|
| VILA-1.5 | 3B/8B/13B/40B | ✅ | ✅ |
| Llama3 | 8B/70B | ✅ | ✅ |
| VILA | 7B/13B | ✅ | |
| Llama2 | 7B/13B/70B | ✅ | ✅ |
| LLaMA | 7B/13B/30B/65B | ✅ | ✅ |
| OPT | 125m/1.3B/2.7B/6.7B/13B/30B | ✅ | ✅ |
| CodeLlama | 7B/13B/34B | ✅ | ✅ |
| StarCoder | 15.5B | ✅ | ✅ |
| Vicuna-v1.1 | 7B/13B | ✅ | |
| LLaVA-v0 | 13B | ✅ |
Note: We only list models that we have prepare the AWQ searching results in the table above. AWQ also supports models such as LLaVA-v1.5 7B, and you may need to run the AWQ search on your own to quantize these models.
AWQ can be easily applied to various LMs thanks to its good generalization, including instruction-tuned models and multi-modal LMs. It provides an easy-to-use tool to reduce the serving cost of LLMs.
Here we provide two examples of AWQ application: Vicuna-7B (chatbot) and LLaVA-13B (visual reasoning) under ./examples directory. AWQ can easily reduce the GPU memory of model serving and speed up token generation. It provides accurate quantization, providing reasoning outputs. You should be able to observe memory savings when running the models with 4-bit weights.
Note that we perform AWQ using only textual calibration data, depsite we are running on multi-modal input. Please refer to ./examples for details.

We provide several sample script to run AWQ (please refer to ./scripts). We use Llama3-8B as an example.
- Perform AWQ search and save search results (we already did it for you):
python -m awq.entry --model_path /PATH/TO/LLAMA3/llama3-8b \
--w_bit 4 --q_group_size 128 \
--run_awq --dump_awq awq_cache/llama3-8b-w4-g128.pt- Evaluate the AWQ quantized model on WikiText-2 (simulated pseudo quantization)
python -m awq.entry --model_path /PATH/TO/LLAMA3/llama3-8b \
--tasks wikitext \
--w_bit 4 --q_group_size 128 \
--load_awq awq_cache/llama3-8b-w4-g128.pt \
--q_backend fake- Generate real quantized weights (INT4)
mkdir quant_cache
python -m awq.entry --model_path /PATH/TO/LLAMA3/llama3-8b \
--w_bit 4 --q_group_size 128 \
--load_awq awq_cache/llama3-8b-w4-g128.pt \
--q_backend real --dump_quant quant_cache/llama3-8b-w4-g128-awq.pt- Load and evaluate the real quantized model (now you can see smaller gpu memory usage)
python -m awq.entry --model_path /PATH/TO/LLAMA3/llama3-8b \
--tasks wikitext \
--w_bit 4 --q_group_size 128 \
--load_quant quant_cache/llama3-8b-w4-g128-awq.ptAWQ also seamlessly supports large multi-modal models (LMMs). Please refer to TinyChat for more details.
If you find AWQ useful or relevant to your research, please kindly cite our paper:
@inproceedings{lin2023awq,
title={AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration},
author={Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song},
booktitle={MLSys},
year={2024}
}
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
GPTQ: Accurate Post-training Compression for Generative Pretrained Transformers
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-awq
Similar Open Source Tools
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.

Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.
LLM-Hub
LLM Hub is an open-source Android app optimized for mobile usage, supporting multiple model formats for on-device LLM chat and image generation. It offers six AI tools including chat, writing aid, image generator, translator, transcriber, and scam detector. Privacy-first with on-device processing and zero data collection. Advanced capabilities include GPU/NPU acceleration, text-to-speech, RAG with global memory, and custom model import. Developed using Kotlin + Jetpack Compose, LLM Runtime, and various model runtimes.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
Pai-Megatron-Patch
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.

flow-like
Flow-Like is an enterprise-grade workflow operating system built upon Rust for uncompromising performance, efficiency, and code safety. It offers a modular frontend for apps, a rich set of events, a node catalog, a powerful no-code workflow IDE, and tools to manage teams, templates, and projects within organizations. With typed workflows, users can create complex, large-scale workflows with clear data origins, transformations, and contracts. Flow-Like is designed to automate any process through seamless integration of LLM, ML-based, and deterministic decision-making instances.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
For similar tasks
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.
ai-edge-quantizer
AI Edge Quantizer is a tool designed for advanced developers to quantize converted LiteRT models. It aims to optimize performance on resource-demanding models by providing quantization recipes for edge device deployment. The tool supports dynamic quantization, weight-only quantization, and static quantization methods, allowing users to customize the quantization process for different hardware deployments. Users can specify quantization recipes to apply to source models, resulting in quantized LiteRT models ready for deployment. The tool also includes advanced features such as selective quantization and mixed precision schemes for fine-tuning quantization recipes.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
For similar jobs
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.