Best AI tools for< Quantize Large Models >
0 - AI tool Sites
2 - Open Source AI Tools
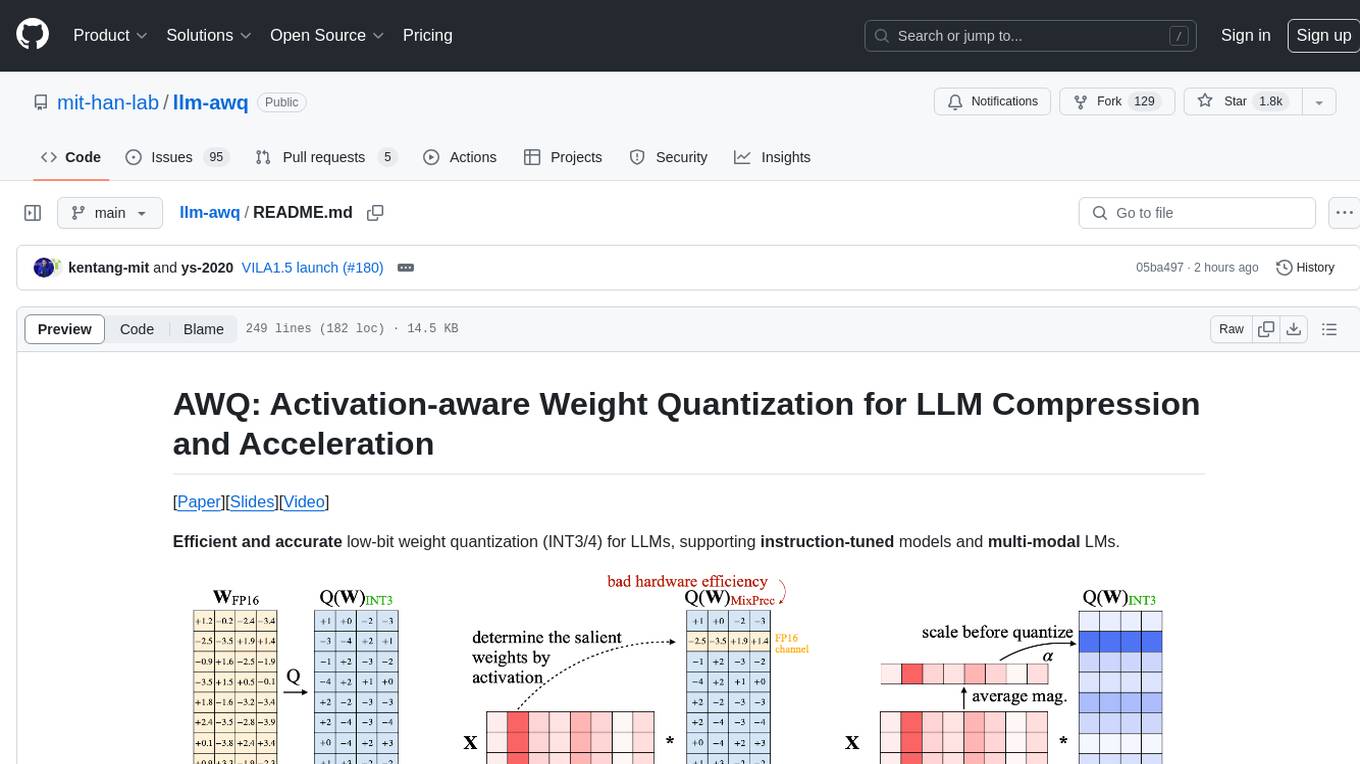
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
bitsandbytes
bitsandbytes enables accessible large language models via k-bit quantization for PyTorch. It provides features for reducing memory consumption for inference and training by using 8-bit optimizers, LLM.int8() for large language model inference, and QLoRA for large language model training. The library includes quantization primitives for 8-bit & 4-bit operations and 8-bit optimizers.