
exllamav2
A fast inference library for running LLMs locally on modern consumer-class GPUs
Stars: 4046

ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.
README:
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs.
The official and recommended backend server for ExLlamaV2 is TabbyAPI, which provides an OpenAI-compatible API for local or remote inference, with extended features like HF model downloading, embedding model support and support for HF Jinja2 chat templates.
See the wiki for help getting started.
- ExLlamaV2 now supports paged attention via Flash Attention 2.5.7+
- New generator with dynamic batching, smart prompt caching, K/V cache deduplication and simplified API

The dynamic generator supports all inference, sampling and speculative decoding features of the previous two generators, consolidated into one API (with the exception of FP8 cache, though the Q4 cache mode is supported and performs better anyway, see here.)
The generator is explained in detail here.
- Single generation:
output = generator.generate(prompt = "Hello, my name is", max_new_tokens = 200)
- Batched generation:
outputs = generator.generate( prompt = [ "Hello, my name is", "Once upon a time,", "Large language models are", ], max_new_tokens = 200 )
- Streamed generation with
asyncio:job = ExLlamaV2DynamicJobAsync( generator, input_ids = tokenizer.encode("You can lead a horse to water"), banned_strings = ["make it drink"], gen_settings = ExLlamaV2Sampler.Settings.greedy(), max_new_tokens = 200 ) async for result in job: text = result.get("text", "") print(text, end = "")
See the full, updated examples here.
Some quick tests to compare performance with ExLlama V1. There may be more performance optimizations in the future, and speeds will vary across GPUs, with slow CPUs still being a potential bottleneck:
| Model | Mode | Size | grpsz | act | 3090Ti | 4090 |
|---|---|---|---|---|---|---|
| Llama | GPTQ | 7B | 128 | no | 181 t/s | 205 t/s |
| Llama | GPTQ | 13B | 128 | no | 110 t/s | 114 t/s |
| Llama | GPTQ | 33B | 128 | yes | 44 t/s | 48 t/s |
| OpenLlama | GPTQ | 3B | 128 | yes | 259 t/s | 296 t/s |
| CodeLlama | EXL2 4.0 bpw | 34B | - | - | 44 t/s | 50 t/s |
| Llama2 | EXL2 3.0 bpw | 7B | - | - | 217 t/s | 257 t/s |
| Llama2 | EXL2 4.0 bpw | 7B | - | - | 185 t/s | 211 t/s |
| Llama2 | EXL2 5.0 bpw | 7B | - | - | 164 t/s | 179 t/s |
| Llama2 | EXL2 2.5 bpw | 70B | - | - | 33 t/s | 38 t/s |
| TinyLlama | EXL2 3.0 bpw | 1.1B | - | - | 656 t/s | 770 t/s |
| TinyLlama | EXL2 4.0 bpw | 1.1B | - | - | 602 t/s | 700 t/s |
To install from the repo you'll need the CUDA Toolkit and either gcc on Linux or (Build Tools for) Visual Studio on Windows). Also make sure you have an appropriate version of PyTorch, then run:
git clone https://github.com/turboderp/exllamav2
cd exllamav2
pip install -r requirements.txt
pip install .
python test_inference.py -m <path_to_model> -p "Once upon a time,"
# Append the '--gpu_split auto' flag for multi-GPU inferenceA simple console chatbot is included. Run it with:
python examples/chat.py -m <path_to_model> -mode llama -gs autoThe -mode argument chooses the prompt format to use. raw will produce a simple chatlog-style chat that works with base
models and various other finetunes. Run with -modes for a list of all available prompt formats. You can also provide
a custom system prompt with -sp.
-
TabbyAPI is a FastAPI-based server that provides an OpenAI-style web API compatible with SillyTavern and other frontends.
-
ExUI is a simple, standalone single-user web UI that serves an ExLlamaV2 instance directly with chat and notebook modes.
-
text-generation-webui supports ExLlamaV2 through the exllamav2 and exllamav2_HF loaders.
-
lollms-webui supports ExLlamaV2 through the exllamav2 binding.
To install the current dev version, clone the repo and run the setup script:
git clone https://github.com/turboderp/exllamav2
cd exllamav2
pip install -r requirements.txt
pip install .By default this will also compile and install the Torch C++ extension (exllamav2_ext) that the library relies on.
You can skip this step by setting the EXLLAMA_NOCOMPILE environment variable:
EXLLAMA_NOCOMPILE= pip install .This will install the "JIT version" of the package, i.e. it will install the Python components without building the
C++ extension in the process. Instead, the extension will be built the first time the library is used, then cached in
~/.cache/torch_extensions for subsequent use.
Releases are available here, with prebuilt wheels that contain the extension binaries. Make sure to grab
the right version, matching your platform, Python version (cp) and CUDA version. Crucially, you must also match
the prebuilt wheel with your PyTorch version, since the Torch C++ extension ABI breaks with every new version of
PyTorch.
Either download an appropriate wheel or install directly from the appropriate URL:
pip install https://github.com/turboderp/exllamav2/releases/download/v0.0.12/exllamav2-0.0.12+cu121-cp311-cp311-linux_x86_64.whlThe py3-none-any.whl version is the JIT version which will build the extension on first launch. The .tar.gz file
can also be installed this way, and it will build the extension while installing.
A PyPI package is available as well. This is the same as the JIT version (see above). It can be installed with:
pip install exllamav2ExLlamaV2 supports the same 4-bit GPTQ models as V1, but also a new "EXL2" format. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6 and 8-bit quantization. The format allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight.
Moreover, it's possible to apply multiple quantization levels to each linear layer, producing something akin to sparse quantization wherein more important weights (columns) are quantized with more bits. The same remapping trick that lets ExLlama work efficiently with act-order models allows this mixing of formats to happen with little to no impact on performance.
Parameter selection is done automatically by quantizing each matrix multiple times, measuring the quantization error (with respect to the chosen calibration data) for each of a number of possible settings, per layer. Finally, a combination is chosen that minimizes the maximum quantization error over the entire model while meeting a target average bitrate.
In my tests, this scheme allows Llama2 70B to run on a single 24 GB GPU with a 2048-token context, producing coherent and mostly stable output with 2.55 bits per weight. 13B models run at 2.65 bits within 8 GB of VRAM, although currently none of them uses GQA which effectively limits the context size to 2048. In either case it's unlikely that the model will fit alongside a desktop environment. For now.


A script is provided to quantize models. Converting large models can be somewhat slow, so be warned. The conversion script and its options are explained in detail here
A number of evaluaion scripts are provided. See here for details.
A test community is provided at https://discord.gg/NSFwVuCjRq Quanting service free of charge is provided at #bot test. The computation is generiously provided by the Bloke powered by Lambda labs.
-
I've uploaded a few EXL2-quantized models to Hugging Face to play around with, here.
-
LoneStriker provides a large number of EXL2 models on Hugging Face.
-
bartowski has some more EXL2 models on HF.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for exllamav2
Similar Open Source Tools
exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.
all-rag-techniques
This repository provides a hands-on approach to Retrieval-Augmented Generation (RAG) techniques, simplifying advanced concepts into understandable implementations using Python libraries like openai, numpy, and matplotlib. It offers a collection of Jupyter Notebooks with concise explanations, step-by-step implementations, code examples, evaluations, and visualizations for various RAG techniques. The goal is to make RAG more accessible and demystify its workings for educational purposes.
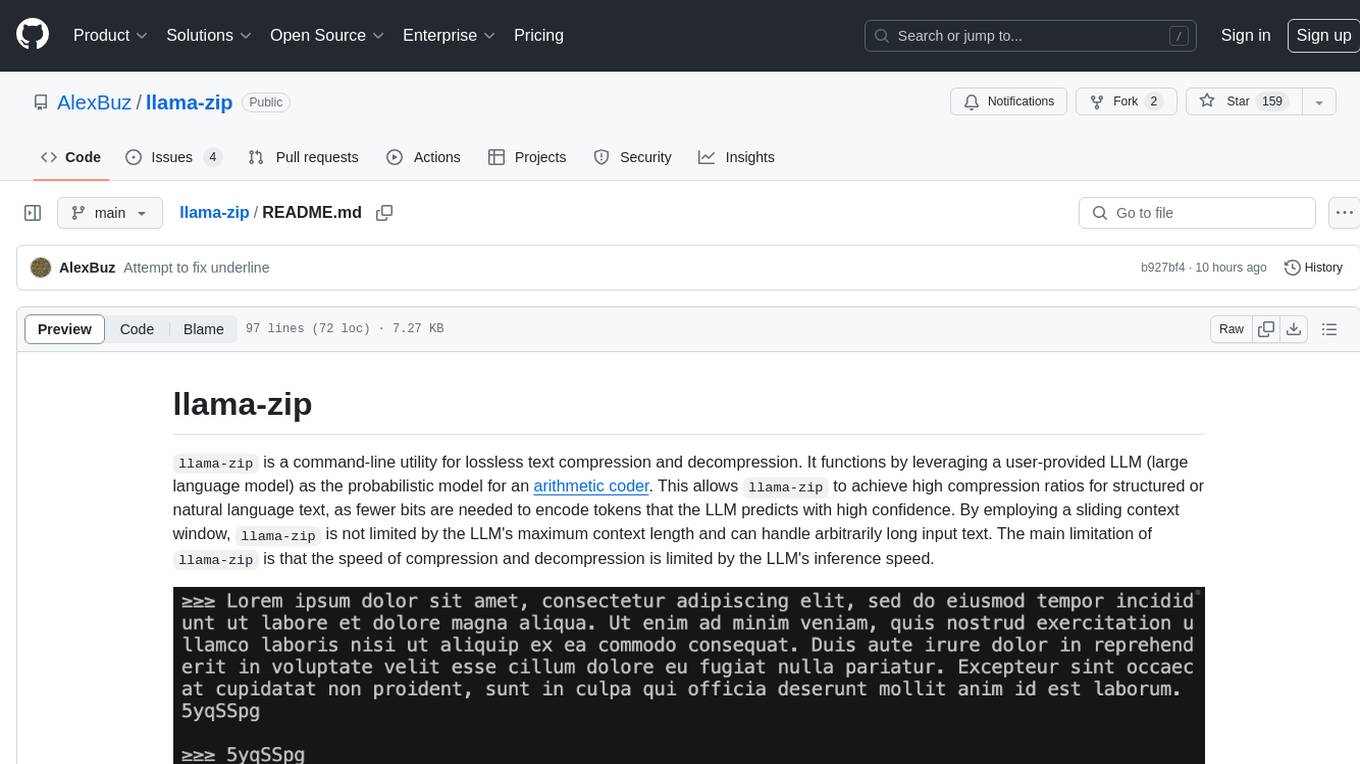
llama-zip
llama-zip is a command-line utility for lossless text compression and decompression. It leverages a user-provided large language model (LLM) as the probabilistic model for an arithmetic coder, achieving high compression ratios for structured or natural language text. The tool is not limited by the LLM's maximum context length and can handle arbitrarily long input text. However, the speed of compression and decompression is limited by the LLM's inference speed.
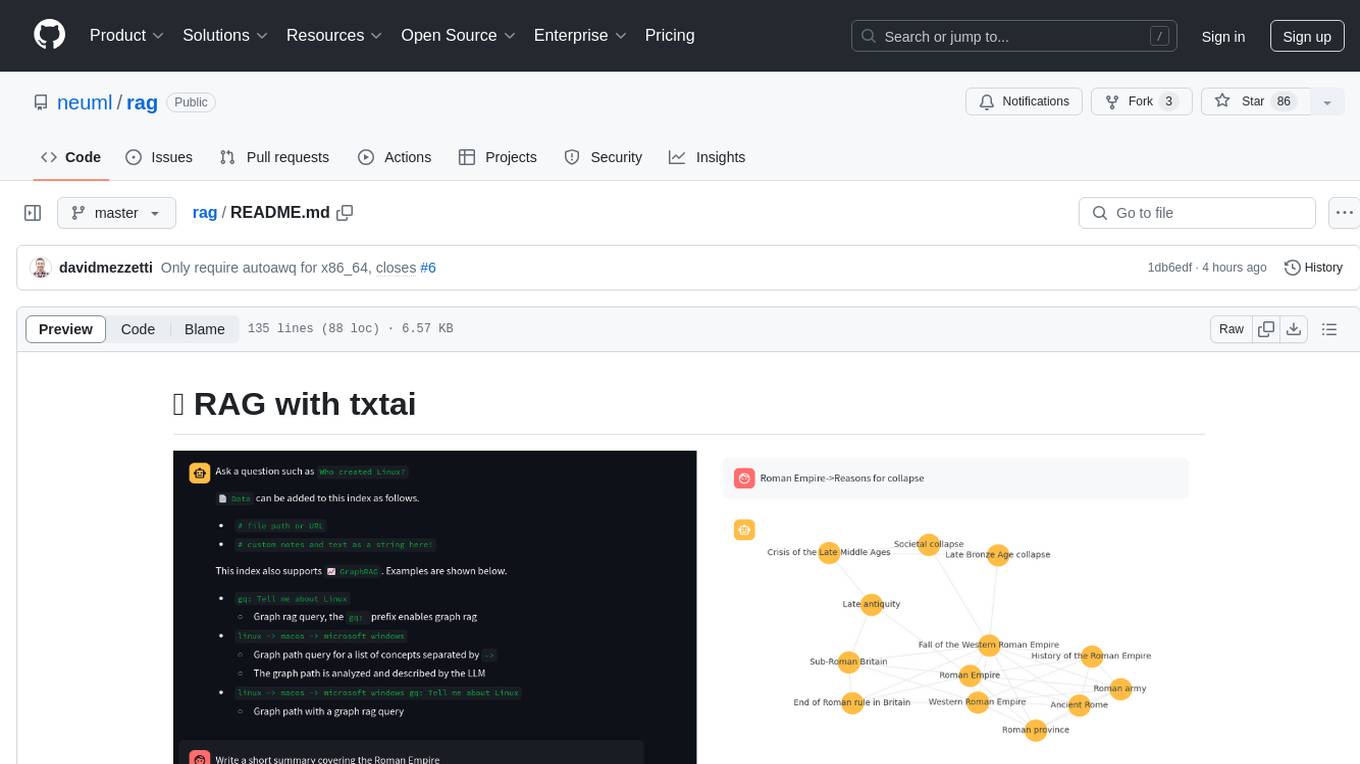
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
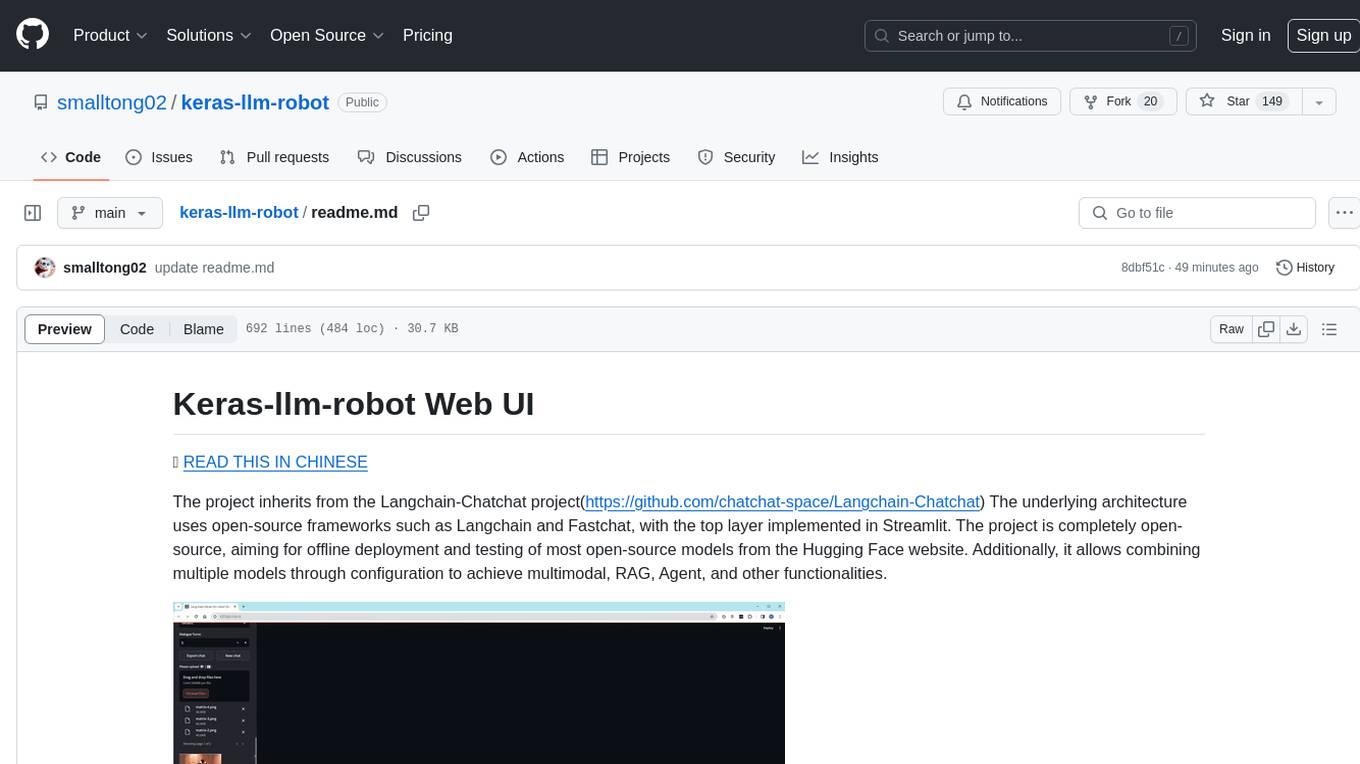
keras-llm-robot
The Keras-llm-robot Web UI project is an open-source tool designed for offline deployment and testing of various open-source models from the Hugging Face website. It allows users to combine multiple models through configuration to achieve functionalities like multimodal, RAG, Agent, and more. The project consists of three main interfaces: chat interface for language models, configuration interface for loading models, and tools & agent interface for auxiliary models. Users can interact with the language model through text, voice, and image inputs, and the tool supports features like model loading, quantization, fine-tuning, role-playing, code interpretation, speech recognition, image recognition, network search engine, and function calling.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.
llama-recipes
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.
langkit
LangKit is an open-source text metrics toolkit for monitoring language models. It offers methods for extracting signals from input/output text, compatible with whylogs. Features include text quality, relevance, security, sentiment, toxicity analysis. Installation via PyPI. Modules contain UDFs for whylogs. Benchmarks show throughput on AWS instances. FAQs available.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.