
llama-recipes
Scripts for fine-tuning Meta Llama with composable FSDP & PEFT methods to cover single/multi-node GPUs. Supports default & custom datasets for applications such as summarization and Q&A. Supporting a number of candid inference solutions such as HF TGI, VLLM for local or cloud deployment. Demo apps to showcase Meta Llama for WhatsApp & Messenger.
Stars: 15718
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.
README:
The 'llama-recipes' repository is a companion to the Meta Llama models. We support the latest version, Llama 3.2 Vision and Llama 3.2 Text, in this repository. This repository contains example scripts and notebooks to get started with the models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama and other tools in the LLM ecosystem. The examples here use Llama locally, in the cloud, and on-prem.
[!TIP] Get started with Llama 3.2 with these new recipes:
[!NOTE] Llama 3.2 follows the same prompt template as Llama 3.1, with a new special token
<|image|>representing the input image for the multimodal models.More details on the prompt templates for image reasoning, tool-calling and code interpreter can be found on the documentation website.
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes. See deployment for notes on how to deploy the project on a live system.
If you want to use PyTorch nightlies instead of the stable release, go to this guide to retrieve the right --extra-index-url URL parameter for the pip install commands on your platform.
Llama-recipes provides a pip distribution for easy install and usage in other projects. Alternatively, it can be installed from source.
[!NOTE] Ensure you use the correct CUDA version (from
nvidia-smi) when installing the PyTorch wheels. Here we are using 11.8 ascu118. H100 GPUs work better with CUDA >12.0
pip install llama-recipes
Llama-recipes offers the installation of optional packages. There are three optional dependency groups. To run the unit tests we can install the required dependencies with:
pip install llama-recipes[tests]
For the vLLM example we need additional requirements that can be installed with:
pip install llama-recipes[vllm]
To use the sensitive topics safety checker install with:
pip install llama-recipes[auditnlg]
Some recipes require the presence of langchain. To install the packages follow the recipe description or install with:
pip install llama-recipes[langchain]
Optional dependencies can also be combined with [option1,option2].
To install from source e.g. for development use these commands. We're using hatchling as our build backend which requires an up-to-date pip as well as setuptools package.
git clone [email protected]:meta-llama/llama-recipes.git
cd llama-recipes
pip install -U pip setuptools
pip install -e .
For development and contributing to llama-recipes please install all optional dependencies:
git clone [email protected]:meta-llama/llama-recipes.git
cd llama-recipes
pip install -U pip setuptools
pip install -e .[tests,auditnlg,vllm]
You can find Llama models on Hugging Face hub here, where models with hf in the name are already converted to Hugging Face checkpoints so no further conversion is needed. The conversion step below is only for original model weights from Meta that are hosted on Hugging Face model hub as well.
If you have the model checkpoints downloaded from the Meta website, you can convert it to the Hugging Face format with:
## Install Hugging Face Transformers from source
pip freeze | grep transformers ## verify it is version 4.45.0 or higher
git clone [email protected]:huggingface/transformers.git
cd transformers
pip install protobuf
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 3B --output_dir /output/pathMost of the code dealing with Llama usage is organized across 2 main folders: recipes/ and src/.
Contains examples organized in folders by topic:
| Subfolder | Description |
|---|---|
| quickstart | The "Hello World" of using Llama, start here if you are new to using Llama. |
| use_cases | Scripts showing common applications of Meta Llama3 |
| 3p_integrations | Partner owned folder showing common applications of Meta Llama3 |
| responsible_ai | Scripts to use PurpleLlama for safeguarding model outputs |
| experimental | Meta Llama implementations of experimental LLM techniques |
Contains modules which support the example recipes:
| Subfolder | Description |
|---|---|
| configs | Contains the configuration files for PEFT methods, FSDP, Datasets, Weights & Biases experiment tracking. |
| datasets | Contains individual scripts for each dataset to download and process. Note |
| inference | Includes modules for inference for the fine-tuned models. |
| model_checkpointing | Contains FSDP checkpoint handlers. |
| policies | Contains FSDP scripts to provide different policies, such as mixed precision, transformer wrapping policy and activation checkpointing along with any precision optimizer (used for running FSDP with pure bf16 mode). |
| utils | Utility files for: - train_utils.py provides training/eval loop and more train utils.- dataset_utils.py to get preprocessed datasets.- config_utils.py to override the configs received from CLI.- fsdp_utils.py provides FSDP wrapping policy for PEFT methods.- memory_utils.py context manager to track different memory stats in train loop. |
The recipes and modules in this repository support the following features:
| Feature | |
|---|---|
| HF support for inference | ✅ |
| HF support for finetuning | ✅ |
| PEFT | ✅ |
| Deferred initialization ( meta init) | ✅ |
| Low CPU mode for multi GPU | ✅ |
| Mixed precision | ✅ |
| Single node quantization | ✅ |
| Flash attention | ✅ |
| Activation checkpointing FSDP | ✅ |
| Hybrid Sharded Data Parallel (HSDP) | ✅ |
| Dataset packing & padding | ✅ |
| BF16 Optimizer (Pure BF16) | ✅ |
| Profiling & MFU tracking | ✅ |
| Gradient accumulation | ✅ |
| CPU offloading | ✅ |
| FSDP checkpoint conversion to HF for inference | ✅ |
| W&B experiment tracker | ✅ |
Please read CONTRIBUTING.md for details on our code of conduct, and the process for submitting pull requests to us.
See the License file for Meta Llama 3.2 here and Acceptable Use Policy here
See the License file for Meta Llama 3.1 here and Acceptable Use Policy here
See the License file for Meta Llama 3 here and Acceptable Use Policy here
See the License file for Meta Llama 2 here and Acceptable Use Policy here
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama-recipes
Similar Open Source Tools
llama-recipes
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.
open-assistant-api
Open Assistant API is an open-source, self-hosted AI intelligent assistant API compatible with the official OpenAI interface. It supports integration with more commercial and private models, R2R RAG engine, internet search, custom functions, built-in tools, code interpreter, multimodal support, LLM support, and message streaming output. Users can deploy the service locally and expand existing features. The API provides user isolation based on tokens for SaaS deployment requirements and allows integration of various tools to enhance its capability to connect with the external world.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.
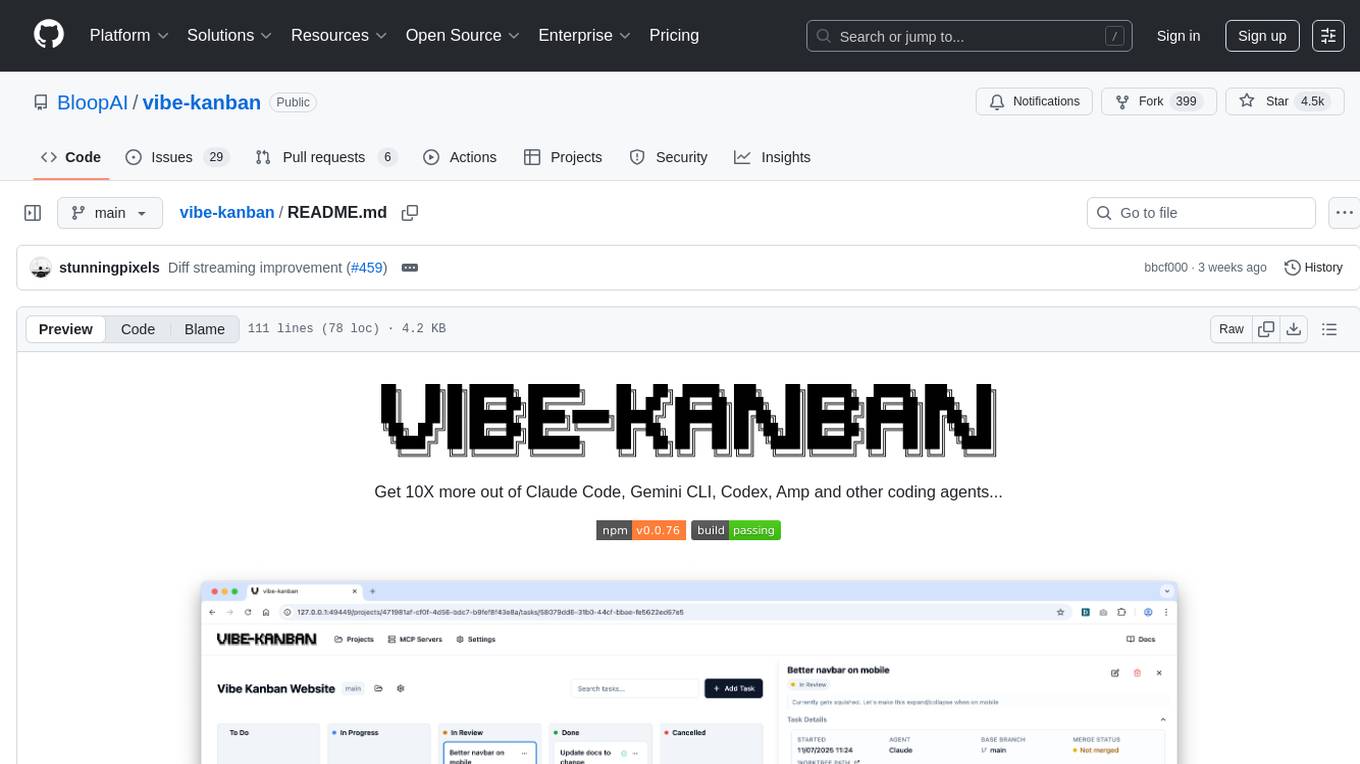
vibe-kanban
Vibe Kanban is a tool designed to streamline the process of planning, reviewing, and orchestrating tasks for human engineers working with AI coding agents. It allows users to easily switch between different coding agents, orchestrate their execution, review work, start dev servers, and track task statuses. The tool centralizes the configuration of coding agent MCP configs, providing a comprehensive solution for managing coding tasks efficiently.
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.

OpenFactVerification
Loki is an open-source tool designed to automate the process of verifying the factuality of information. It provides a comprehensive pipeline for dissecting long texts into individual claims, assessing their worthiness for verification, generating queries for evidence search, crawling for evidence, and ultimately verifying the claims. This tool is especially useful for journalists, researchers, and anyone interested in the factuality of information.
we0
We0 is a web project generation tool that offers browser-based debugging, high-fidelity design restoration, importing historical projects, integration with WeChat Mini Program Developer Tools, and multi-platform support. It supports code generation, design-to-code conversion, open-source projects, WeChat Mini Program Tools preview, existing projects, and Deepseek. The tool uses pnpm as the package management tool and requires Node.js version 18.20. Users can install and configure the tool for web development and utilize quick start methods for building the web editor. Additionally, instructions are provided for installing and using the client version on Mac, along with troubleshooting tips. For any questions or support, users can contact [email protected] or join the WeChat group chat.
flowgen
FlowGen is a tool built for AutoGen, a great agent framework from Microsoft and a lot of contributors. It provides intuitive visual tools that streamline the construction and oversight of complex agent-based workflows, simplifying the process for creators and developers. Users can create Autoflows, chat with agents, and share flow templates. The tool is fully dockerized and supports deployment on Railway.app. Contributions to the project are welcome, and the platform uses semantic-release for versioning and releases.

docker-aio
The docker-aio repository provides an accelerated mirror service for Docker users, allowing them to speed up image pulls by replacing original domains with corresponding accelerated domains. Users in Asia are advised to comply with local laws and regulations when using this service. The repository offers installation scripts and instructions on how to modify Docker configurations to utilize the accelerated mirrors effectively.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
For similar tasks
llama-recipes
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.
llmware
LLMWare is a framework for quickly developing LLM-based applications including Retrieval Augmented Generation (RAG) and Multi-Step Orchestration of Agent Workflows. This project provides a comprehensive set of tools that anyone can use - from a beginner to the most sophisticated AI developer - to rapidly build industrial-grade, knowledge-based enterprise LLM applications. Our specific focus is on making it easy to integrate open source small specialized models and connecting enterprise knowledge safely and securely.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.