
maxtext
A simple, performant and scalable Jax LLM!
Stars: 1898
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
README:
![]()
MaxText is a high performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler.
MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.
We have used MaxText to demonstrate high-performance, well-converging training in int8 and scale training to ~51K chips.
Key supported features:
- TPUs and GPUs
- Training and Inference
- Models: Llama 2, Llama 3, Llama 4, Mistral and Mixtral family, Gemma, Gemma 2, Gemma 3, DeepSeek, Qwen3 Dense and MoE family
- [September 5, 2025] MaxText has moved to an
srclayout as part of RESTRUCTURE.md. For existing environments, please runpip install -e .from MaxText root. - [August 13, 2025] The Qwen3 MoE family of models is now supported. We are starting with Qwen3-235B-A22B-Thinking-2507, in addition to our existing Qwen3 Dense family of 0.6B, 4B, 8B, 14B, and 32B models.
- [July 27, 2025] We have updated our TFLOPS/s calculation to account for causal attention, dividing the attention flops in half in this PR. Also we account for sliding window and chunked attention reduced attention flops in PR and PR. These changes especially impact large sequence configs, since attention flops grow quadratically with sequence length, as explained in this ReadMe
- [July 16, 2025] We will be restructuring the MaxText repository for improved organization and clarity. Please review the proposed structure and provide feedback.
- [July 11, 2025] Multi-Token Prediction (MTP) training is now supported! This feature adds an auxiliary loss based on predicting multiple future tokens, inspired by the DeepSeek-V3 paper, to enhance training efficiency.
- [June 25, 2025] DeepSeek R1-0528 variant is now supported!
- [April 24, 2025] Llama 4 Maverick models are now supported!
- [April 14, 2025] Llama 4 Scout models are now supported. Context length is currently limited to 8k and we have many ideas for optimization but we're working on both these things. Note that models are text-only for now, but we're working on full multi-modal support!
- [April 7, 2025] 🚨🚨🚨 We support modular imports. This comes with an API change for
train.py: Now you should invoke the script viapython3 -m MaxText.train MaxText/configs/base.yml run_name=.... If you want the old behavior you can stick to an older commitgit checkout pre-module-v0.1.0and use the older APIpython MaxText/train.py src/MaxText/configs/base.yml run_name=.... - [April 2, 2025] DeepSeek v3-0324 variant is now supported!
- [March 24, 2025] We are excited to announce support for DeepSeek v3 (671B) and v2-Lite (16B), compatible with both TPUs and GPUs. We are actively working on further optimization.
- [March 12, 2025] We are excited to announce support for Gemma 3: 4B, 12B, and 27B in text-only formats. Please see Google Launch Blog and Developer Blog for more information on Gemma 3.
- [February, 2025] (Preview): We're excited to announce the preview of building Maxtext Docker images using the JAX AI Training Images, available for both TPUs and GPUs. This provides a more reliable and consistent build environment. Learn more Here
- Getting Started
- Runtime Performance Results
- Comparison To Alternatives
- Development
- Features and Diagnostics
For your first time running MaxText, we provide specific instructions.
MaxText supports training and inference of various open models. Follow user guides in the getting started folder to know more.
Some extra helpful guides:
- Gemma (generations 1-3): a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. You can run decode and finetuning using these instructions. For Gemma 2 and 3, use the corresponding gemma2 and gemma3 scripts for checkpoint convertion and decoding.
- Llama2: a family of open-weights Large Language Model (LLM) by Meta. You can run decode and finetuning using these instructions.
- Mixtral: a family of open-weights sparse mixture-of-experts (MoE) models by Mistral AI. You can run decode and finetuning using these instructions.
- DeepSeek: a novel family of open-weights sparse MoE models by DeepSeek AI. DeepSeek-V3 features advanced techniques, including Multi-Head Latent Attention (MLA), finer-grained and shared experts, Multi-Token Prediction (MTP), and FP8 mixed precision designed for enhanced efficiency and performance. You can run pre-training, finetuning, and decoding using these instructions.
In addition to the getting started guides, there are always other MaxText capabilities that are being constantly being added! The full suite of end-to-end tests is in end_to_end. We run them with a nightly cadence. They can be a good source for understanding MaxText Alternatively you can see the continuous unit tests which are run almost continuously.
More details on reproducing these results can be found in src/MaxText/configs/README.md.
| No. of params | Accelerator Type | TFLOP/chip/sec | Model flops utilization (MFU) |
|---|---|---|---|
| 32B | v5p-128 | 3.28e+02 | 67.76% |
| 64B | v5p-128 | 3.23e+02 | 70.31% |
| 128B | v5p-256 | 3.15e+02 | 68.68% |
| 128B | v5p-512 | 3.15e+02 | 68.53% |
| 256B | v5p-1024 | 3.16e+02 | 68.82% |
| 512B | v5p-1024 | 2.94e+02 | 63.99% |
| 1024B | v5p-2048 | 2.49e+02 | 64.05% |
| 1024B | v5p-4096 | 2.97e+02 | 64.80% |
| 1160B | v5p-7680 | 2.95e+02 | 64.27% |
| 1160B | v5p-12288 | 3.04e+02 | 66.23% |
For 16B, 32B, 64B, and 128B models. See full run configs in src/MaxText/configs/v5e/ as 16b.sh, 32b.sh, 64b.sh, 128b.sh.
| Hardware | 16B TFLOP/sec/chip | 16B MFU | 32B TFLOP/sec/chip | 32B MFU | 64B TFLOP/sec/chip | 64B MFU | 128B TFLOP/sec/chip | 128B MFU |
|---|---|---|---|---|---|---|---|---|
| 1x v5e-256 | 120 | 61.10% | 132 | 66.86% | 118 | 59.90% | 110 | 56.06% |
| 2x v5e-256 | 117 | 59.37% | 128 | 64.81% | 112 | 56.66% | 110 | 55.82% |
| 4x v5e-256 | 117 | 59.14% | 126 | 64.10% | 110 | 55.85% | 108 | 54.93% |
| 8x v5e-256 | 115 | 58.27% | 125 | 63.67% | 108 | 54.96% | 104 | 52.93% |
| 16x v5e-256 | 111 | 56.56% | 123 | 62.26% | 105 | 53.29% | 100 | 50.86% |
| 32x v5e-256 | 108 | 54.65% | 119 | 60.40% | 99 | 50.18% | 91 | 46.25% |
MaxText is heavily inspired by MinGPT/NanoGPT, elegant standalone GPT implementations written in PyTorch and targeting Nvidia GPUs. MaxText is more complex, supporting more industry standard models and scaling to tens of thousands of chips. Ultimately MaxText has an MFU more than three times the 17% reported most recently with that codebase, is massively scalable and implements a key-value cache for efficient auto-regressive decoding.
MaxText is more similar to Nvidia/Megatron-LM, a very well tuned LLM implementation targeting Nvidia GPUs. The two implementations achieve comparable MFUs. The difference in the codebases highlights the different programming strategies. MaxText is pure Python, relying heavily on the XLA compiler to achieve high performance. By contrast, Megatron-LM is a mix of Python and CUDA, relying on well-optimized CUDA kernels to achieve high performance.
MaxText is also comparable to Pax. Like Pax, MaxText provides high-performance and scalable implementations of LLMs in Jax. Pax focuses on enabling powerful configuration parameters, enabling developers to change the model by editing config parameters. By contrast, MaxText is a simple, concrete implementation of various LLMs that encourages users to extend by forking and directly editing the source code.
When running a Single Program, Multiple Data (SPMD) job on accelerators, the overall process can hang if there is any error or any VM hangs/crashes for some reason. In this scenario, capturing stack traces will help to identify and troubleshoot the issues for the jobs running on TPU VMs.
The following configurations will help to debug a fault or when a program is stuck or hung somewhere by collecting stack traces. Change the parameter values accordingly in src/MaxText/configs/base.yml:
- Set
collect_stack_trace: Trueto enable collection of stack traces on faults or when the program is hung. This setting will periodically dump the traces for the program to help in debugging. To disable this, setcollect_stack_trace: False. - Set
stack_trace_to_cloud: Falseto display stack traces on console.stack_trace_to_cloud: Truewill create a temporary file in/tmp/debuggingin the TPUs to store the stack traces. There is an agent running on TPU VMs that will periodically upload the traces from the temporary directory to cloud logging in the gcp project. You can view the traces in Logs Explorer on Cloud Logging using the following query:
logName="projects/<project_name>/logs/tpu.googleapis.com%2Fruntime_monitor"
jsonPayload.verb="stacktraceanalyzer"
-
stack_trace_interval_secondssignifies the duration in seconds between each stack trace collection event. Settingstack_trace_interval_seconds: 600will collect the stack traces every 600 seconds (10 minutes).
Here is the related PyPI package: https://pypi.org/project/cloud-tpu-diagnostics.
To compile your training run ahead of time, we provide a tool train_compile.py. This tool allows you to compile the main train_step in train.py for target hardware (e.g. a large number of v5e devices) without using the full cluster.
You may use only a CPU or a single VM from a different family to pre-compile for a TPU cluster. This compilation helps with two main goals:
-
It will flag any out of memory (OOM) information, such as when the
per_device_batch_sizeis set too high, with an identical OOM stack trace as if it was compiled on the target hardware. -
The ahead of time compilation can be saved and then loaded for fast startup and restart times on the target hardware.
The tool train_compile.py is tightly linked to train.py and uses the same configuration file configs/base.yml. Although you don't need to run on a TPU, you do need to install jax[tpu] in addition to other dependencies, so we recommend running setup.sh to install these if you have not already done so.
After installing the dependencies listed above, you are ready to compile ahead of time:
# Run the below on a single machine, e.g. a CPU
python3 -m MaxText.train_compile src/MaxText/configs/base.yml compile_topology=v5e-256 compile_topology_num_slices=2 \
global_parameter_scale=16 per_device_batch_size=4
This will compile a 16B parameter MaxText model on 2 v5e pods.
Here is an example that saves then loads the compiled train_step, starting with the save:
Step 1: Run AOT and save compiled function
# Run the below on a single machine, e.g. a CPU
export LIBTPU_INIT_ARGS="--xla_enable_async_all_gather=true"
python3 -m MaxText.train_compile src/MaxText/configs/base.yml compile_topology=v5e-256 \
compile_topology_num_slices=2 \
compiled_trainstep_file=my_compiled_train.pickle global_parameter_scale=16 \
per_device_batch_size=4 steps=10000 learning_rate=1e-3
Step 2: Run train.py and load the compiled function
To load the compiled train_step, you just need to pass compiled_trainstep_file=my_compiled_train.pickle into train.py:
# Run the below on each host of the target hardware, e.g. each host on 2 slices of v5e-256
export LIBTPU_INIT_ARGS="--xla_enable_async_all_gather=true"
python3 -m MaxText.train src/MaxText/configs/base.yml run_name=example_load_compile \
compiled_trainstep_file=my_compiled_train.pickle \
global_parameter_scale=16 per_device_batch_size=4 steps=10000 learning_rate=1e-3 \
base_output_directory=gs://my-output-bucket dataset_path=gs://my-dataset-bucket
In the save step of example 2 above we included exporting the compiler flag LIBTPU_INIT_ARGS and learning_rate because those affect the compiled object my_compiled_train.pickle. The sizes of the model (e.g. global_parameter_scale, max_sequence_length and per_device_batch) are fixed when you initially compile via compile_train.py, you will see a size error if you try to run the saved compiled object with different sizes than you compiled with. However a subtle note is that the learning rate schedule is also fixed when you run compile_train - which is determined by both steps and learning_rate. The optimizer parameters such as adam_b1 are passed only as shaped objects to the compiler - thus their real values are determined when you run train.py, not during the compilation. If you do pass in different shapes (e.g. per_device_batch), you will get a clear error message reporting that the compiled signature has different expected shapes than what was input. If you attempt to run on different hardware than the compilation targets requested via compile_topology, you will get an error saying there is a failure to map the devices from the compiled to your real devices. Using different XLA flags or a LIBTPU than what was compiled will probably run silently with the environment you compiled in without error. However there is no guaranteed behavior in this case; you should run in the same environment you compiled in.
Ahead-of-time compilation is also supported for GPUs with some differences from TPUs:
-
GPU does not support compilation across hardware: A GPU host is still required to run AoT compilation, but a single GPU host can compile a program for a larger cluster of the same hardware.
-
For A3 Cloud GPUs, the maximum "slice" size is a single host, and the
compile_topology_num_slicesparameter represents the number of A3 machines to precompile for.
This example illustrates the flags to use for a multihost GPU compilation targeting a cluster of 4 A3 hosts:
Step 1: Run AOT and save compiled function
# Run the below on a single A3 machine
export XLA_FLAGS="--xla_gpu_enable_async_collectives=true"
python3 -m MaxText.train_compile src/MaxText/configs/base.yml compile_topology=a3 \
compile_topology_num_slices=4 \
compiled_trainstep_file=my_compiled_train.pickle global_parameter_scale=16 \
attention=dot_product per_device_batch_size=4 steps=10000 learning_rate=1e-3
Step 2: Run train.py and load the compiled function
To load the compiled train_step, you just need to pass compiled_trainstep_file=my_compiled_train.pickle into train.py:
# Run the below on each of the 4 target A3 hosts.
export XLA_FLAGS="--xla_gpu_enable_async_collectives=true"
python3 -m MaxText.train src/MaxText/configs/base.yml run_name=example_load_compile \
compiled_trainstep_file=my_compiled_train.pickle \
attention=dot_product global_parameter_scale=16 per_device_batch_size=4 steps=10000 learning_rate=1e-3 \
base_output_directory=gs://my-output-bucket dataset_path=gs://my-dataset-bucket
As in the TPU case, note that the compilation environment must match the execution environment, in this case by setting the same XLA_FLAGS.
MaxText supports automatic upload of logs collected in a directory to a Tensorboard instance in Vertex AI. Follow user guide to know more.
If you are interested in monitoring Goodput metrics of your workload, follow this user guide.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for maxtext
Similar Open Source Tools
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.
swt-bench
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
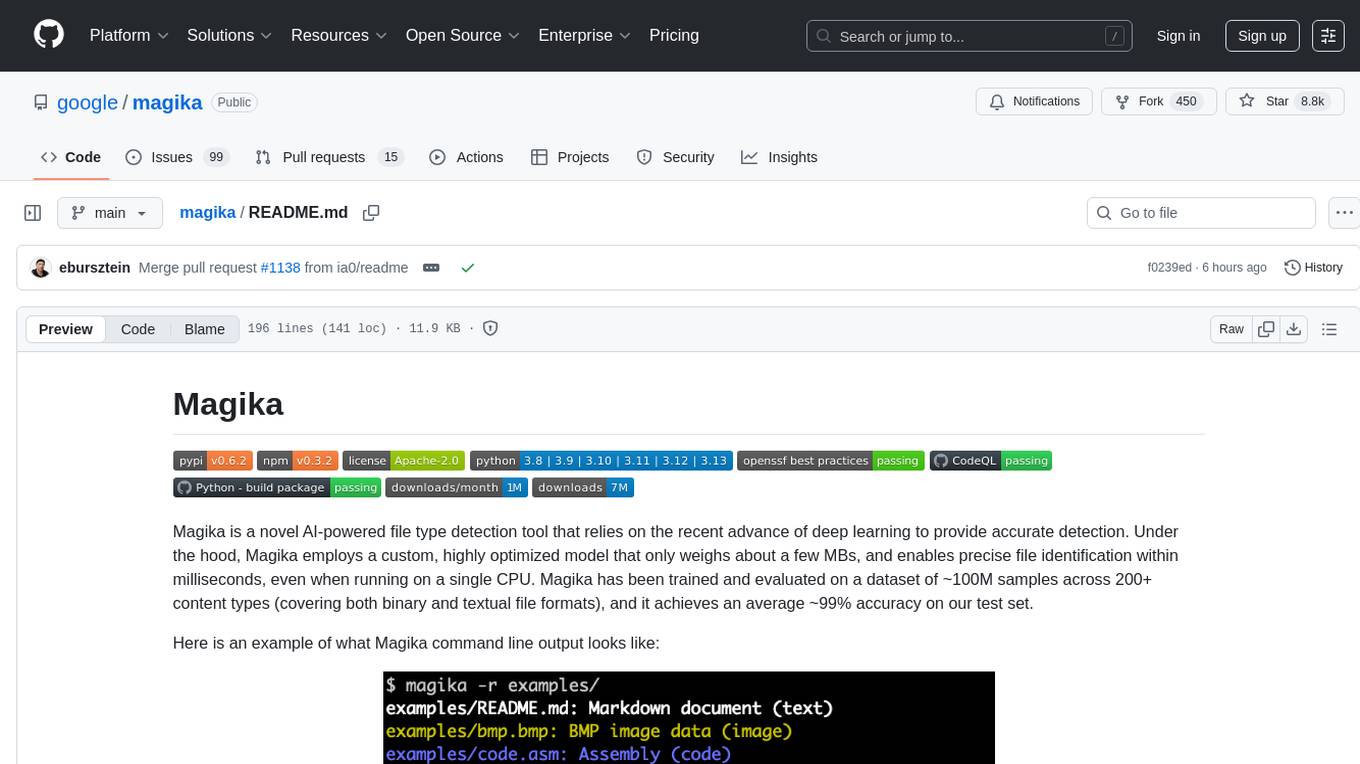
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
zipnn
ZipNN is a lossless and near-lossless compression library optimized for numbers/tensors in the Foundation Models environment. It automatically prepares data for compression based on its type, allowing users to focus on core tasks without worrying about compression complexities. The library delivers effective compression techniques for different data types and structures, achieving high compression ratios and rates. ZipNN supports various compression methods like ZSTD, lz4, and snappy, and provides ready-made scripts for file compression/decompression. Users can also manually import the package to compress and decompress data. The library offers advanced configuration options for customization and validation tests for different input and compression types.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.
pint-benchmark
The Lakera PINT Benchmark provides a neutral evaluation method for prompt injection detection systems, offering a dataset of English inputs with prompt injections, jailbreaks, benign inputs, user-agent chats, and public document excerpts. The dataset is designed to be challenging and representative, with plans for future enhancements. The benchmark aims to be unbiased and accurate, welcoming contributions to improve prompt injection detection. Users can evaluate prompt injection detection systems using the provided Jupyter Notebook. The dataset structure is specified in YAML format, allowing users to prepare their datasets for benchmarking. Evaluation examples and resources are provided to assist users in evaluating prompt injection detection models and tools.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord

OneKE
OneKE is a flexible dockerized system for schema-guided knowledge extraction, capable of extracting information from the web and raw PDF books across multiple domains like science and news. It employs a collaborative multi-agent approach and includes a user-customizable knowledge base to enable tailored extraction. OneKE offers various IE tasks support, data sources support, LLMs support, extraction method support, and knowledge base configuration. Users can start with examples using YAML, Python, or Web UI, and perform tasks like Named Entity Recognition, Relation Extraction, Event Extraction, Triple Extraction, and Open Domain IE. The tool supports different source formats like Plain Text, HTML, PDF, Word, TXT, and JSON files. Users can choose from various extraction models like OpenAI, DeepSeek, LLaMA, Qwen, ChatGLM, MiniCPM, and OneKE for information extraction tasks. Extraction methods include Schema Agent, Extraction Agent, and Reflection Agent. The tool also provides support for schema repository and case repository management, along with solutions for network issues. Contributors to the project include Ningyu Zhang, Haofen Wang, Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, and Huajun Chen.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.
For similar tasks
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
gpt-pilot
GPT Pilot is a core technology for the Pythagora VS Code extension, aiming to provide the first real AI developer companion. It goes beyond autocomplete, helping with writing full features, debugging, issue discussions, and reviews. The tool utilizes LLMs to generate production-ready apps, with developers overseeing the implementation. GPT Pilot works step by step like a developer, debugging issues as they arise. It can work at any scale, filtering out code to show only relevant parts to the AI during tasks. Contributions are welcome, with debugging and telemetry being key areas of focus for improvement.
claude-coder
Claude Coder is an AI-powered coding companion in the form of a VS Code extension that helps users transform ideas into code, convert designs into applications, debug intuitively, accelerate development with automation, and improve coding skills. It aims to bridge the gap between imagination and implementation, making coding accessible and efficient for developers of all skill levels.
palico-ai
Palico AI is a tech stack designed for rapid iteration of LLM applications. It allows users to preview changes instantly, improve performance through experiments, debug issues with logs and tracing, deploy applications behind a REST API, and manage applications with a UI control panel. Users have complete flexibility in building their applications with Palico, integrating with various tools and libraries. The tool enables users to swap models, prompts, and logic easily using AppConfig. It also facilitates performance improvement through experiments and provides options for deploying applications to cloud providers or using managed hosting. Contributions to the project are welcomed, with easy ways to get involved by picking issues labeled as 'good first issue'.
gemini-cli
Gemini CLI is an open-source AI agent that provides lightweight access to Gemini, offering powerful capabilities like code understanding, generation, automation, integration, and advanced features. It is designed for developers who prefer working in the command line and offers extensibility through MCP support. The tool integrates directly into GitHub workflows and offers various authentication options for individual developers, enterprise teams, and production workloads. With features like code querying, editing, app generation, debugging, and GitHub integration, Gemini CLI aims to streamline development workflows and enhance productivity.
dev3000
dev3000 captures your web app's complete development timeline including server logs, browser events, console messages, network requests, and automatic screenshots in a unified, timestamped feed for AI debugging. It creates a comprehensive log of your development session that AI assistants can easily understand, monitoring your app in a real browser and capturing server logs, console output, browser console messages and errors, network requests and responses, and automatic screenshots on navigation, errors, and key events. Logs are saved with timestamps and rotated to keep the 10 most recent per project, with the current session symlinked for easy access. The tool integrates with AI assistants for instant debugging and provides advanced querying options through the MCP server.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.