Best AI tools for< Run Inference >
20 - AI tool Sites
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
GPUX
GPUX is a cloud platform that provides access to GPUs for running AI workloads. It offers a variety of features to make it easy to deploy and run AI models, including a user-friendly interface, pre-built templates, and support for a variety of programming languages. GPUX is also committed to providing a sustainable and ethical platform, and it has partnered with organizations such as the Climate Leadership Council to reduce its carbon footprint.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Qualcomm AI Hub
Qualcomm AI Hub is a platform that allows users to run AI models on Snapdragon® 8 Elite devices. It provides a collaborative ecosystem for model makers, cloud providers, runtime, and SDK partners to deploy on-device AI solutions quickly and efficiently. Users can bring their own models, optimize for deployment, and access a variety of AI services and resources. The platform caters to various industries such as mobile, automotive, and IoT, offering a range of models and services for edge computing.
Together AI
Together AI is an AI tool that offers a variety of generative AI services, including serverless models, fine-tuning capabilities, dedicated endpoints, and GPU clusters. Users can run or fine-tune leading open source models with only a few lines of code. The platform provides a range of functionalities for tasks such as chat, vision, text-to-speech, code/language reranking, and more. Together AI aims to simplify the process of utilizing AI models for various applications.

Tensordyne
Tensordyne is a generative AI inference compute tool designed and developed in the US and Germany. It focuses on re-engineering AI math and defining AI inference to run the biggest AI models for thousands of users at a fraction of the rack count, power, and cost. Tensordyne offers custom silicon and systems built on the Zeroth Scaling Law, enabling breakthroughs in AI technology.
TitanML
TitanML is a platform that provides tools and services for deploying and scaling Generative AI applications. Their flagship product, the Titan Takeoff Inference Server, helps machine learning engineers build, deploy, and run Generative AI models in secure environments. TitanML's platform is designed to make it easy for businesses to adopt and use Generative AI, without having to worry about the underlying infrastructure. With TitanML, businesses can focus on building great products and solving real business problems.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.

Tensoic AI
Tensoic AI is an AI tool designed for custom Large Language Models (LLMs) fine-tuning and inference. It offers ultra-fast fine-tuning and inference capabilities for enterprise-grade LLMs, with a focus on use case-specific tasks. The tool is efficient, cost-effective, and easy to use, enabling users to outperform general-purpose LLMs using synthetic data. Tensoic AI generates small, powerful models that can run on consumer-grade hardware, making it ideal for a wide range of applications.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.

Cortex Labs
Cortex Labs is a decentralized world computer that enables AI and AI-powered decentralized applications (dApps) to run on the blockchain. It offers a Layer2 solution called ZkMatrix, which utilizes zkRollup technology to enhance transaction speed and reduce fees. Cortex Virtual Machine (CVM) supports on-chain AI inference using GPU, ensuring deterministic results across computing environments. Cortex also enables machine learning in smart contracts and dApps, fostering an open-source ecosystem for AI researchers and developers to share models. The platform aims to solve the challenge of on-chain machine learning execution efficiently and deterministically, providing tools and resources for developers to integrate AI into blockchain applications.
Awan LLM
Awan LLM is an AI tool that offers an Unlimited Tokens, Unrestricted, and Cost-Effective LLM Inference API Platform for Power Users and Developers. It allows users to generate unlimited tokens, use LLM models without constraints, and pay per month instead of per token. The platform features an AI Assistant, AI Agents, Roleplay with AI companions, Data Processing, Code Completion, and Applications for profitable AI-powered applications.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.
SWE Kit
SWE Kit is an open-source headless IDE designed for building custom coding agents with state-of-the-art performance. It offers AI-native tools to streamline the coding review process, enhance code quality, and optimize development efficiency. The application supports various agentic frameworks and LLM inference providers, providing a flexible runtime environment for seamless codebase interaction. With features like code analysis, code indexing, and third-party service integrations, SWE Kit empowers developers to create and run coding agents effortlessly.
BentoML
BentoML is a platform for software engineers to build, ship, and scale AI products. It provides a unified AI application framework that makes it easy to manage and version models, create service APIs, and build and run AI applications anywhere. BentoML is used by over 1000 organizations and has a global community of over 3000 members.
LM Studio
LM Studio is an AI tool designed for discovering, downloading, and running local LLMs (Large Language Models). Users can run LLMs on their laptops offline, use models through an in-app Chat UI or a local server, download compatible model files from HuggingFace repositories, and discover new LLMs. The tool ensures privacy by not collecting data or monitoring user actions, making it suitable for personal and business use. LM Studio supports various models like ggml Llama, MPT, and StarCoder on Hugging Face, with minimum hardware/software requirements specified for different platforms.
Head AI
Head AI is an influencer marketing AI tool that streamlines the influencer marketing process by providing unique data on 50M+ vetted influencers, automatic matching, content production guidance, real-time tracking, and campaign launch-ready strategies. It uses AI to identify influencers that match brands, negotiate pricing, oversee content creation, and optimize campaign performance. Head AI caters to startups, enterprises, and agencies, offering a fast and efficient solution for influencer marketing campaigns.
Archive
Archive is an AI-first influencer marketing platform that drives results by automating the tracking, management, and repurposing of user-generated content (UGC). It offers features such as Campaign Dashboards, Social Listening, AI-powered Creator Search, Competitor Insights, Shoppable UGC Feeds, and detailed Reports. Archive helps brands streamline influencer marketing, improve conversion rates, and increase revenue through its innovative AI technology.
42 - Open Source AI Tools

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
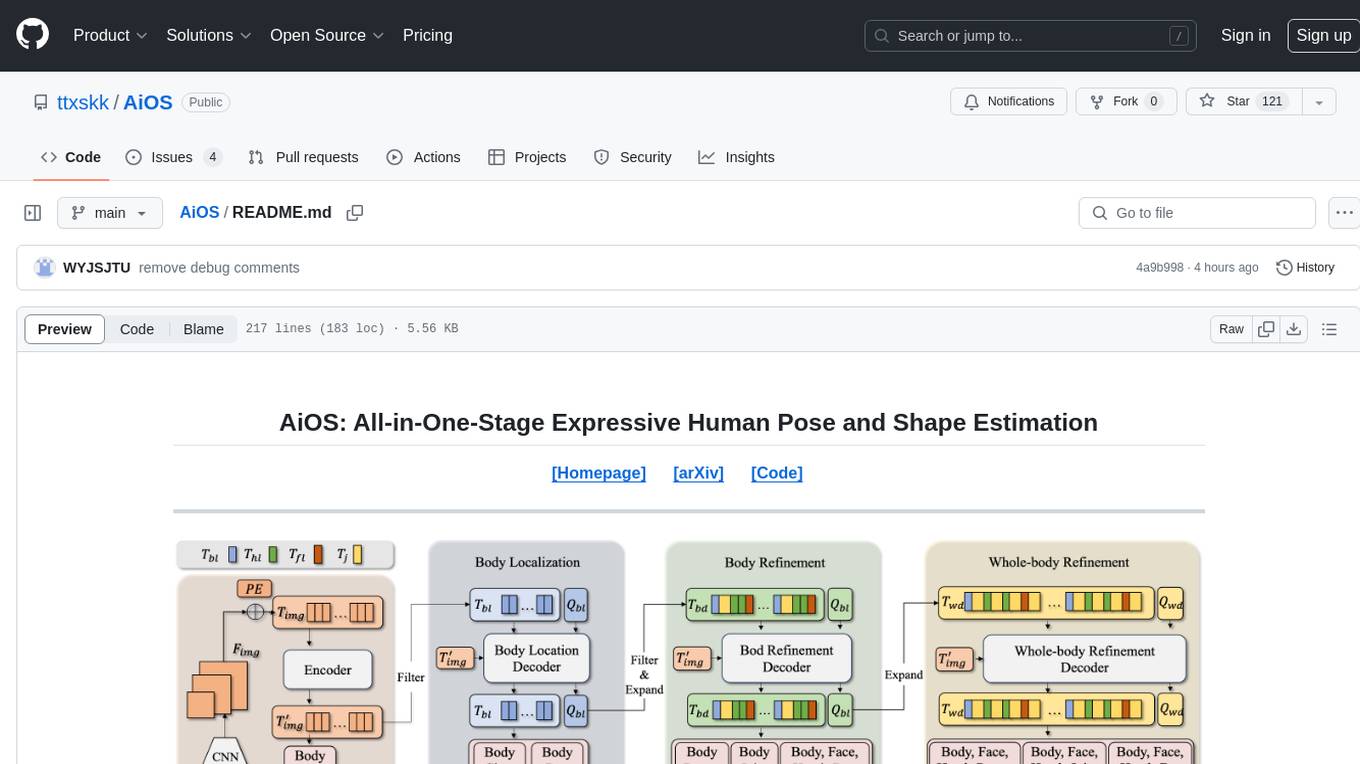
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.
KsanaLLM
KsanaLLM is a high-performance engine for LLM inference and serving. It utilizes optimized CUDA kernels for high performance, efficient memory management, and detailed optimization for dynamic batching. The tool offers flexibility with seamless integration with popular Hugging Face models, support for multiple weight formats, and high-throughput serving with various decoding algorithms. It enables multi-GPU tensor parallelism, streaming outputs, and an OpenAI-compatible API server. KsanaLLM supports NVIDIA GPUs and Huawei Ascend NPU, and seamlessly integrates with verified Hugging Face models like LLaMA, Baichuan, and Qwen. Users can create a docker container, clone the source code, compile for Nvidia or Huawei Ascend NPU, run the tool, and distribute it as a wheel package. Optional features include a model weight map JSON file for models with different weight names.

WildBench
WildBench is a tool designed for benchmarking Large Language Models (LLMs) with challenging tasks sourced from real users in the wild. It provides a platform for evaluating the performance of various models on a range of tasks. Users can easily add new models to the benchmark by following the provided guidelines. The tool supports models from Hugging Face and other APIs, allowing for comprehensive evaluation and comparison. WildBench facilitates running inference and evaluation scripts, enabling users to contribute to the benchmark and collaborate on improving model performance.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.
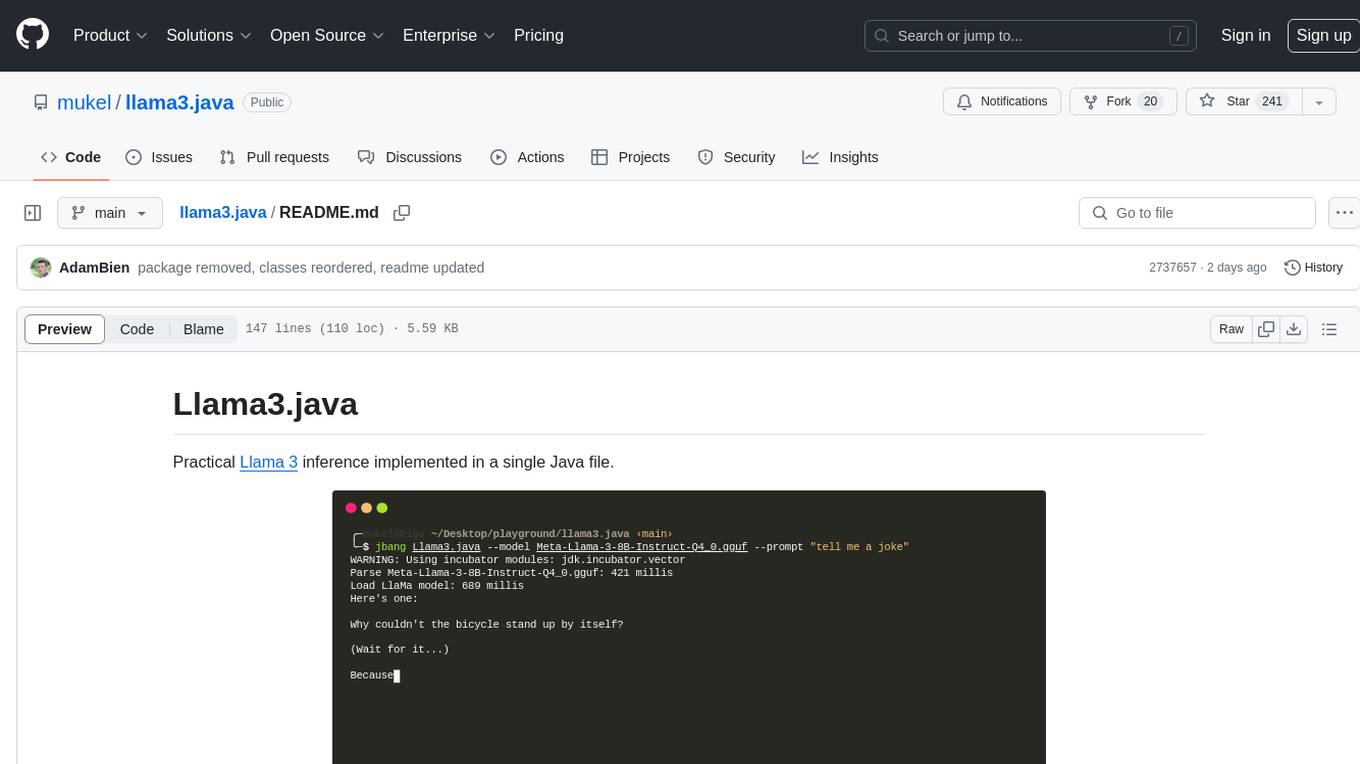
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
LLaMa2lang
LLaMa2lang is a repository containing convenience scripts to finetune LLaMa3-8B (or any other foundation model) for chat towards any language that isn't English. The repository aims to improve the performance of LLaMa3 for non-English languages by combining fine-tuning with RAG. Users can translate datasets, extract threads, turn threads into prompts, and finetune models using QLoRA and PEFT. Additionally, the repository supports translation models like OPUS, M2M, MADLAD, and base datasets like OASST1 and OASST2. The process involves loading datasets, translating them, combining checkpoints, and running inference using the newly trained model. The repository also provides benchmarking scripts to choose the right translation model for a target language.
crossfire-yolo-TensorRT
This repository supports the YOLO series models and provides an AI auto-aiming tool based on YOLO-TensorRT for the game CrossFire. Users can refer to the provided link for compilation and running instructions. The tool includes functionalities for screenshot + inference, mouse movement, and smooth mouse movement. The next goal is to automatically set the optimal PID parameters on the local machine. Developers are welcome to contribute to the improvement of this tool.

OlympicArena
OlympicArena is a comprehensive benchmark designed to evaluate advanced AI capabilities across various disciplines. It aims to push AI towards superintelligence by tackling complex challenges in science and beyond. The repository provides detailed data for different disciplines, allows users to run inference and evaluation locally, and offers a submission platform for testing models on the test set. Additionally, it includes an annotation interface and encourages users to cite their paper if they find the code or dataset helpful.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.
rakis
Rakis is a decentralized verifiable AI network in the browser where nodes can accept AI inference requests, run local models, verify results, and arrive at consensus without servers. It is open-source, functional, multi-model, multi-chain, and browser-first, allowing anyone to participate in the network. The project implements an embedding-based consensus mechanism for verifiable inference. Users can run their own node on rakis.ai or use the compiled version hosted on Huggingface. The project is meant for educational purposes and is a work in progress.
models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. It aims to replicate the best-known performance of target model/dataset combinations in optimally-configured hardware environments. The repository will be deprecated upon the publication of v3.2.0 and will no longer be maintained or published.
airllm
AirLLM is a tool that optimizes inference memory usage, enabling large language models to run on low-end GPUs without quantization, distillation, or pruning. It supports models like Llama3.1 on 8GB VRAM. The tool offers model compression for up to 3x inference speedup with minimal accuracy loss. Users can specify compression levels, profiling modes, and other configurations when initializing models. AirLLM also supports prefetching and disk space management. It provides examples and notebooks for easy implementation and usage.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
cortex.cpp
Cortex is a C++ AI engine with a Docker-like command-line interface and client libraries. It supports running AI models using ONNX, TensorRT-LLM, and llama.cpp engines. Cortex can function as a standalone server or be integrated as a library. The tool provides support for various engines and models, allowing users to easily deploy and interact with AI models. It offers a range of CLI commands for managing models, embeddings, and engines, as well as a REST API for interacting with models. Cortex is designed to simplify the deployment and usage of AI models in C++ applications.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.

TPI-LLM
TPI-LLM (Tensor Parallelism Inference for Large Language Models) is a system designed to bring LLM functions to low-resource edge devices, addressing privacy concerns by enabling LLM inference on edge devices with limited resources. It leverages multiple edge devices for inference through tensor parallelism and a sliding window memory scheduler to minimize memory usage. TPI-LLM demonstrates significant improvements in TTFT and token latency compared to other models, and plans to support infinitely large models with low token latency in the future.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.

nesa
Nesa is a tool that allows users to run on-prem AI for a fraction of the cost through a blind API. It provides blind privacy, zero latency on protected inference, wide model coverage, cost savings compared to cloud and on-prem AI, RAG support, and ChatGPT compatibility. Nesa achieves blind AI through Equivariant Encryption (EE), a new security technology that provides complete inference encryption with no additional latency. EE allows users to perform inference on neural networks without exposing the underlying data, preserving data privacy and security.
loras-dev
Loras is an open source real-time AI image generator powered by Flux through Together.ai. It utilizes Flux Dev from BFL for the image model, Together AI for inference, Next.js app router with Tailwind, Helicone for observability, and Plausible for website analytics. Users can clone the repository, add their Together AI API key to a .env.local file, install dependencies, and run the tool locally to generate AI images in real-time.

llama.cpp
The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide range of hardware - locally and in the cloud. It provides a Plain C/C++ implementation without any dependencies, optimized for Apple silicon via ARM NEON, Accelerate and Metal frameworks, and supports various architectures like AVX, AVX2, AVX512, and AMX. It offers integer quantization for faster inference, custom CUDA kernels for NVIDIA GPUs, Vulkan and SYCL backend support, and CPU+GPU hybrid inference. llama.cpp is the main playground for developing new features for the ggml library, supporting various models and providing tools and infrastructure for LLM deployment.
JittorLLMs
JittorLLMs is a large model inference library that allows running large models on machines with low hardware requirements. It significantly reduces hardware configuration demands, enabling deployment on ordinary machines with 2GB of memory. It supports various large models and provides a unified environment configuration for users. Users can easily migrate models without modifying any code by installing Jittor version of torch (JTorch). The framework offers fast model loading speed, optimized computation performance, and portability across different computing devices and environments.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.
LLM-Engineers-Handbook
The LLM Engineer's Handbook is an official repository containing a comprehensive guide on creating an end-to-end LLM-based system using best practices. It covers data collection & generation, LLM training pipeline, a simple RAG system, production-ready AWS deployment, comprehensive monitoring, and testing and evaluation framework. The repository includes detailed instructions on setting up local and cloud dependencies, project structure, installation steps, infrastructure setup, pipelines for data processing, training, and inference, as well as QA, tests, and running the project end-to-end.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and fostering collaboration. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, configuration management, training job monitoring, media upload, and prediction. The repository also includes tutorial-style Jupyter notebooks demonstrating SDK usage.
dspy.rb
DSPy.rb is a Ruby framework for building reliable LLM applications using composable, type-safe modules. It enables developers to define typed signatures and compose them into pipelines, offering a more structured approach compared to traditional prompting. The framework embraces Ruby conventions and adds innovations like CodeAct agents and enhanced production instrumentation, resulting in scalable LLM applications that are robust and efficient. DSPy.rb is actively developed, with a focus on stability and real-world feedback through the 0.x series before reaching a stable v1.0 API.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.
modular
The Modular Platform is a unified suite of AI libraries and tools designed for AI development and deployment. It abstracts hardware complexity to enable running popular open models with high GPU and CPU performance without code changes. The repository contains over 450,000 lines of code from 6000+ contributors, making it one of the largest open-source repositories for CPU and GPU kernels. Key components include the Mojo standard library, MAX GPU and CPU kernels, MAX inference server, MAX model pipelines, and code examples. The repository has main and stable branches for nightly builds and stable releases, respectively. Contributions are accepted for the Mojo standard library, MAX AI kernels, code examples, and Mojo docs.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
exllamav3
ExLlamaV3 is an inference library for running local LLMs on modern consumer GPUs. It features a new EXL3 quantization format based on QTIP, flexible tensor-parallel and expert-parallel inference, OpenAI-compatible server via TabbyAPI, continuous dynamic batching, HF Transformers plugin, speculative decoding, multimodal support, and more. The library supports various architectures and aims to simplify and optimize the quantization process for large models, offering efficient conversion with reduced GPU-hours and cost. It provides a streamlined variant of QTIP, enabling fast and memory-bound latency for inference on GPUs.
20 - OpenAI Gpts


Consulting & Investment Banking Interview Prep GPT
Run mock interviews, review content and get tips to ace strategy consulting and investment banking interviews

Dungeon Master's Assistant
Your new DM's screen: helping Dungeon Masters to craft & run amazing D&D adventures.
Database Builder
Hosts a real SQLite database and helps you create tables, make schema changes, and run SQL queries, ideal for all levels of database administration.
Restaurant Startup Guide
Meet the Restaurant Startup Guide GPT: your friendly guide in the restaurant biz. It offers casual, approachable advice to help you start and run your own restaurant with ease.

Community Design™
A community-building GPT based on the wildly popular Community Design™ framework from Mighty Networks. Start creating communities that run themselves.
Code Helper for Web Application Development
Friendly web assistant for efficient code. Ask the wizard to create an application and you will get the HTML, CSS and Javascript code ready to run your web application.

Creative Director GPT
I'm your brainstorm muse in marketing and advertising; the creativity machine you need to sharpen the skills, land the job, generate the ideas, win the pitches, build the brands, ace the awards, or even run your own agency. Psst... don't let your clients find out about me! 😉
Pace Assistant
Provides running splits for Strava Routes, accounting for distance and elevation changes