
llm-finetuning
Guide for fine-tuning Llama/Mistral/CodeLlama models and more
Stars: 483

llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.
README:
This guide will show you how to fine-tune any LLM quickly using modal and axolotl.
Modal gives the popular axolotl LLM fine-tuning library serverless superpowers.
If you run your fine-tuning jobs on Modal's cloud infrastructure, you get to train your models without worrying about juggling Docker images or letting expensive GPU VMs sit idle.
And any application written with Modal can be easily scaled across many GPUs -- whether that's several H100 servers running fine-tunes in parallel or hundreds of A100 or A10G instances running production inference.
Our sample configurations use many of the recommended, state-of-the-art optimizations for efficient, performant training that axolotl supports, including:
- Deepspeed ZeRO to utilize multiple GPUs during training, according to a strategy you configure.
- LoRA Adapters for fast, parameter-efficient fine-tuning.
- Flash attention for fast and memory-efficient attention calculations during training.
Our quickstart example overfits a 7B model on a very small subsample of a text-to-SQL dataset as a proof of concept. Overfitting is a great way to test training setups because it can be done quickly (under five minutes!) and with minimal data but closely resembles the actual training process.
It uses DeepSpeed ZeRO-3 Offload to shard model and optimizer state across 2 A100s.
Inference on the fine-tuned model displays conformity to the output structure ([SQL] ... [/SQL]). To achieve better results, you'll need to use more data! Refer to the Development section below.
-
Set up authentication to Modal for infrastructure, Hugging Face for models, and (optionally) Weights & Biases for training observability:
Setting up
- Create a Modal account.
- Install
modalin your current Python virtual environment (pip install modal) - Set up a Modal token in your environment (
python3 -m modal setup) - You need to have a secret named
huggingfacein your workspace. You can create a new secret with the HuggingFace template in your Modal dashboard, using the key from HuggingFace (in settings under API tokens) to populateHF_TOKENand changing the name frommy-huggingface-secrettohuggingface. - For some LLaMA models, you need to go to the Hugging Face page (e.g. this page for LLaMA 3 8B_ and agree to their Terms and Conditions for access (granted instantly).
- If you want to use Weights & Biases for logging, you need to have a secret named
wandbin your workspace as well. You can also create it from a template. Training is hard enough without good logs, so we recommend you try it or look intoaxolotl's integration with MLFlow!
-
Clone this repository:
git clone https://github.com/modal-labs/llm-finetuning.git cd llm-finetuning -
Launch a finetuning job:
export ALLOW_WANDB=true # if you're using Weights & Biases modal run --detach src.train --config=config/mistral-memorize.yml --data=data/sqlqa.subsample.jsonl
This example training script is opinionated in order to make it easy to get started. Feel free to adapt it to suit your needs.
- Run inference for the model you just trained:
# run one test inference
modal run -q src.inference --prompt "[INST] Using the schema context below, generate a SQL query that answers the question.
CREATE TABLE head (name VARCHAR, born_state VARCHAR, age VARCHAR)
List the name, born state and age of the heads of departments ordered by name. [/INST]"
# 🤖: [SQL] SELECT name, born_state, age FROM head ORDER BY name [/SQL] # or something like that!
# 🧠: Effective throughput of 36.27 tok/s# deploy a serverless inference service
modal deploy src.inference
curl https://YOUR_MODAL_USERNAME--example-axolotl-inference-web.modal.run?input=%5BINST%5Dsay%20hello%20in%20SQL%5B%2FINST%5D
# [SQL] Select 'Hello' [/SQL]One of the key features of axolotl is that it flattens your data from a JSONL file into a prompt template format you specify in the config. Tokenization and prompt templating are where most mistakes are made when fine-tuning.
See the nbs/inspect_data.ipynb notebook for guide on how to inspect your data and ensure it is being flattened correctly. We strongly recommend that you always inspect your data the first time you fine-tune a model on a new dataset.
This Modal app does not expose all configuration via the CLI, the way that axolotl does. You specify all your desired options in the config file instead.
The fine-tuning logic is in train.py. These are the important functions:
-
launchprepares a new folder in the/runsvolume with the training config and data for a new training job. It also ensures the base model is downloaded from HuggingFace. -
traintakes a prepared folder and performs the training job using the config and data. Some notes about thetraincommand: -
The
--dataflag is used to pass your dataset to axolotl. This dataset is then written to thedatasets.pathas specified in your config file. If you already have a dataset atdatasets.path, you must be careful to also pass the same path to--datato ensure the dataset is correctly loaded. -
Unlike
axolotl, you cannot pass additional flags to thetraincommand. However, you can specify all your desired options in the config file instead. -
--no-merge-lorawill prevent the LoRA adapter weights from being merged into the base model weights.
The inference.py file includes a vLLM inference server for any pre-trained or fine-tuned model from a previous training job.
You can view some example configurations in config for a quick start with different models. See an overview of axolotl's config options here.
The most important options to consider are:
Model
base_model: mistralai/Mistral-7B-v0.1Dataset (You can see all dataset options here)
datasets:
# This will be the path used for the data when it is saved to the Volume in the cloud.
- path: data.jsonl
ds_type: json
type:
# JSONL file contains question, context, answer fields per line.
# This gets mapped to instruction, input, output axolotl tags.
field_instruction: question
field_input: context
field_output: answer
# Format is used by axolotl to generate the prompt.
format: |-
[INST] Using the schema context below, generate a SQL query that answers the question.
{input}
{instruction} [/INST]LoRA
adapter: lora # for qlora, or leave blank for full finetune (requires much more GPU memory!)
lora_r: 16
lora_alpha: 32 # alpha = 2 x rank is a good rule of thumb.
lora_dropout: 0.05
lora_target_linear: true # target all linear layersCustom Datasets
axolotl supports many dataset formats. We recommend adding your custom dataset as a .jsonl file in the data folder and making the appropriate modifications to your config.
Logging with Weights and Biases
To track your training runs with Weights and Biases, add your wandb config information to your config.yml:
wandb_project: code-7b-sql-output # set the project name
wandb_watch: gradients # track histograms of gradientsand set the ALLOW_WANDB environment variable to true when launching your training job:
ALLOW_WANDB=true modal run --detach src.train --config=... --data=...We recommend DeepSpeed for multi-GPU training, which is easy to set up. axolotl provides several default deepspeed JSON configurations and Modal makes it easy to attach multiple GPUs of any type in code, so all you need to do is specify which of these configs you'd like to use.
First edit the DeepSpeed config in your .yml:
deepspeed: /root/axolotl/deepspeed_configs/zero3_bf16.jsonand then when you launch your training job,
set the GPU_CONFIG environment variable to the GPU configuration you want to use:
GPU_CONFIG=a100-80gb:4 modal run --detach src.train --config=... --data=...You can find the results of all your runs via the CLI with
modal volume ls example-runs-volor view them in your Modal dashboard.
You can browse the artifacts created by your training run with the following command, which is also printed out at the end of your training run in the logs:
modal volume ls example-runs-vol <run id>
# example: modal volume ls example-runs-vol axo-2024-04-13-19-13-05-0fb0By default, the Modal axolotl trainer automatically merges the LoRA adapter weights into the base model weights.
The directory for a finished run will look like something this:
$ modal volume ls example-runs-vol axo-2024-04-13-19-13-05-0fb0/
Directory listing of 'axo-2024-04-13-19-13-05-0fb0/' in 'example-runs-vol'
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┓
┃ filename ┃ type ┃ created/modified ┃ size ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━┩
│ axo-2024-04-13-19-13-05-0fb0/last_run_prepared │ dir │ 2024-04-13 12:13:39-07:00 │ 32 B │
│ axo-2024-04-13-19-13-05-0fb0/mlruns │ dir │ 2024-04-13 12:14:19-07:00 │ 7 B │
│ axo-2024-04-13-19-13-05-0fb0/lora-out │ dir │ 2024-04-13 12:20:55-07:00 │ 178 B │
│ axo-2024-04-13-19-13-05-0fb0/logs.txt │ file │ 2024-04-13 12:19:52-07:00 │ 133 B │
│ axo-2024-04-13-19-13-05-0fb0/data.jsonl │ file │ 2024-04-13 12:13:05-07:00 │ 1.3 MiB │
│ axo-2024-04-13-19-13-05-0fb0/config.yml │ file │ 2024-04-13 12:13:05-07:00 │ 1.7 KiB │
└────────────────────────────────────────────────┴──────┴───────────────────────────┴─────────┘
The LoRA adapters are stored in lora-out. The merged weights are stored in lora-out/merged . Note that many inference frameworks can only load the merged weights!
To run inference with a model from a past training job, you can specify the run name via the command line:
modal run -q src.inference --run-name=...CUDA Out of Memory (OOM)
This means your GPU(s) ran out of memory during training. To resolve, either increase your GPU count/memory capacity with multi-GPU training, or try reducing any of the following in your config.yml: micro_batch_size, eval_batch_size, gradient_accumulation_steps, sequence_len
self.state.epoch = epoch + (step + 1 + steps_skipped) / steps_in_epoch ZeroDivisionError: division by zero
This means your training dataset might be too small.
Missing config option when using
modal runin the CLI
Make sure your modal client >= 0.55.4164 (upgrade to the latest version using pip install --upgrade modal)
AttributeError: 'Accelerator' object has no attribute 'deepspeed_config'
Try removing the wandb_log_model option from your config. See #4143.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-finetuning
Similar Open Source Tools
llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.
web-codegen-scorer
Web Codegen Scorer is a tool designed to evaluate the quality of web code generated by Large Language Models (LLMs). It allows users to make evidence-based decisions related to AI-generated code by iterating on system prompts, comparing code quality from different models, and monitoring code quality over time. The tool focuses specifically on web code and offers various features such as configuring evaluations, specifying system instructions, using built-in checks for code quality, automatically repairing issues, and viewing results with an intuitive report viewer UI.

reader
Reader is a tool that converts any URL to an LLM-friendly input with a simple prefix `https://r.jina.ai/`. It improves the output for your agent and RAG systems at no cost. Reader supports image reading, captioning all images at the specified URL and adding `Image [idx]: [caption]` as an alt tag. This enables downstream LLMs to interact with the images in reasoning, summarizing, etc. Reader offers a streaming mode, useful when the standard mode provides an incomplete result. In streaming mode, Reader waits a bit longer until the page is fully rendered, providing more complete information. Reader also supports a JSON mode, which contains three fields: `url`, `title`, and `content`. Reader is backed by Jina AI and licensed under Apache-2.0.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

sage
Sage is a tool that allows users to chat with any codebase, providing a chat interface for code understanding and integration. It simplifies the process of learning how a codebase works by offering heavily documented answers sourced directly from the code. Users can set up Sage locally or on the cloud with minimal effort. The tool is designed to be easily customizable, allowing users to swap components of the pipeline and improve the algorithms powering code understanding and generation.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.
mlx-lm
MLX LM is a Python package designed for generating text and fine-tuning large language models on Apple silicon using MLX. It offers integration with the Hugging Face Hub for easy access to thousands of LLMs, support for quantizing and uploading models to the Hub, low-rank and full model fine-tuning capabilities, and distributed inference and fine-tuning with `mx.distributed`. Users can interact with the package through command line options or the Python API, enabling tasks such as text generation, chatting with language models, model conversion, streaming generation, and sampling. MLX LM supports various Hugging Face models and provides tools for efficient scaling to long prompts and generations, including a rotating key-value cache and prompt caching. It requires macOS 15.0 or higher for optimal performance.
fsdp_qlora
The fsdp_qlora repository provides a script for training Large Language Models (LLMs) with Quantized LoRA and Fully Sharded Data Parallelism (FSDP). It integrates FSDP+QLoRA into the Axolotl platform and offers installation instructions for dependencies like llama-recipes, fastcore, and PyTorch. Users can finetune Llama-2 70B on Dual 24GB GPUs using the provided command. The script supports various training options including full params fine-tuning, LoRA fine-tuning, custom LoRA fine-tuning, quantized LoRA fine-tuning, and more. It also discusses low memory loading, mixed precision training, and comparisons to existing trainers. The repository addresses limitations and provides examples for training with different configurations, including BnB QLoRA and HQQ QLoRA. Additionally, it offers SLURM training support and instructions for adding support for a new model.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.
ai-models
The `ai-models` command is a tool used to run AI-based weather forecasting models. It provides functionalities to install, run, and manage different AI models for weather forecasting. Users can easily install and run various models, customize model settings, download assets, and manage input data from different sources such as ECMWF, CDS, and GRIB files. The tool is designed to optimize performance by running on GPUs and provides options for better organization of assets and output files. It offers a range of command line options for users to interact with the models and customize their forecasting tasks.

honcho
Honcho is a platform for creating personalized AI agents and LLM powered applications for end users. The repository is a monorepo containing the server/API for managing database interactions and storing application state, along with a Python SDK. It utilizes FastAPI for user context management and Poetry for dependency management. The API can be run using Docker or manually by setting environment variables. The client SDK can be installed using pip or Poetry. The project is open source and welcomes contributions, following a fork and PR workflow. Honcho is licensed under the AGPL-3.0 License.
For similar tasks

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.
unsloth
Unsloth is a tool that allows users to fine-tune large language models (LLMs) 2-5x faster with 80% less memory. It is a free and open-source tool that can be used to fine-tune LLMs such as Gemma, Mistral, Llama 2-5, TinyLlama, and CodeLlama 34b. Unsloth supports 4-bit and 16-bit QLoRA / LoRA fine-tuning via bitsandbytes. It also supports DPO (Direct Preference Optimization), PPO, and Reward Modelling. Unsloth is compatible with Hugging Face's TRL, Trainer, Seq2SeqTrainer, and Pytorch code. It is also compatible with NVIDIA GPUs since 2018+ (minimum CUDA Capability 7.0).

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.
ipex-llm
IPEX-LLM is a PyTorch library for running Large Language Models (LLMs) on Intel CPUs and GPUs with very low latency. It provides seamless integration with various LLM frameworks and tools, including llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, and more. IPEX-LLM has been optimized and verified on over 50 LLM models, including LLaMA, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, and RWKV. It supports a range of low-bit inference formats, including INT4, FP8, FP4, INT8, INT2, FP16, and BF16, as well as finetuning capabilities for LoRA, QLoRA, DPO, QA-LoRA, and ReLoRA. IPEX-LLM is actively maintained and updated with new features and optimizations, making it a valuable tool for researchers, developers, and anyone interested in exploring and utilizing LLMs.
llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.
HighPerfLLMs2024
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
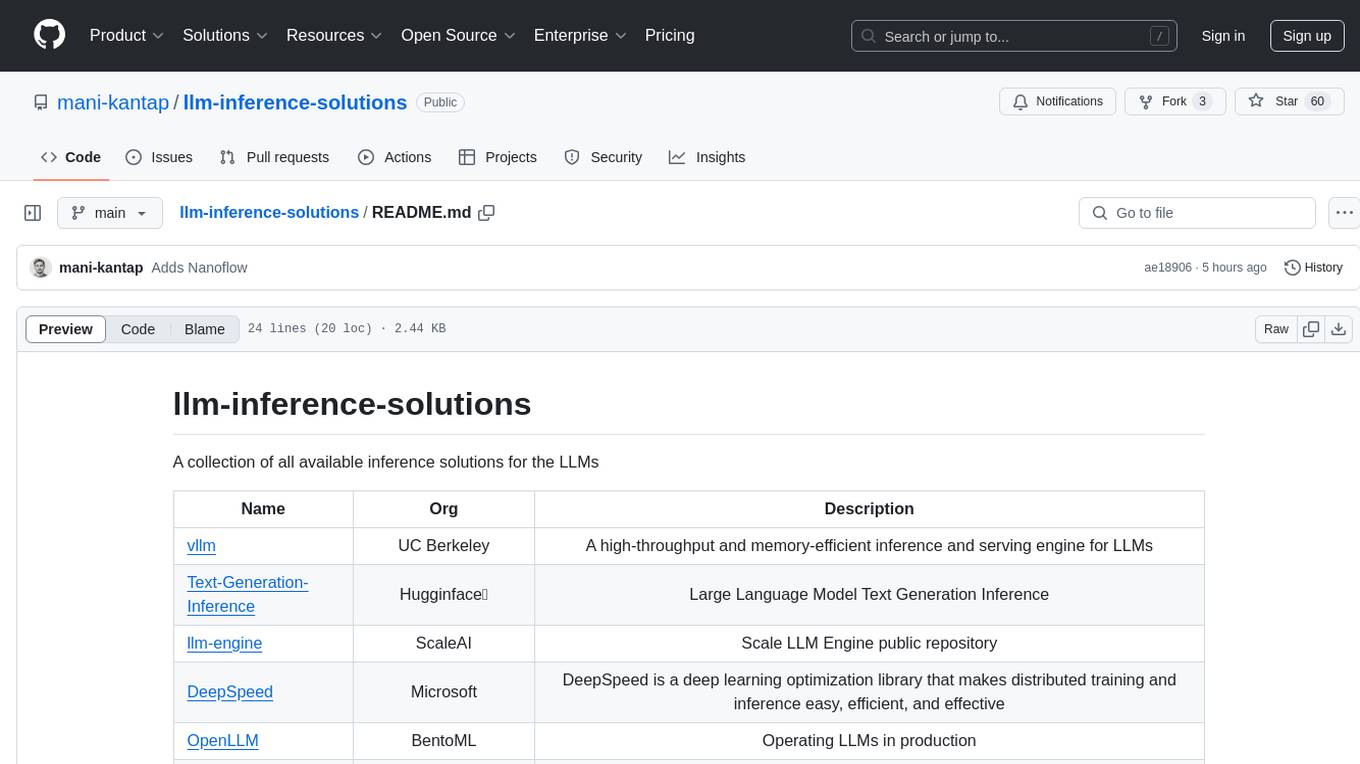
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.