
HighPerfLLMs2024
None
Stars: 124
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.
README:
Build a full scale, high-performance LLM from scratch in Jax! We’ll cover training and inference, roofline analysis, compilation, sharding, profiling and more. You’ll leave the class comfortable in Jax and confident in your ability to design high-performance computing systems that reach near their physical limit.
Link to the Discord: https://discord.gg/2AWcVatVAw
- Build a Jax LLM Implementation From Scratch
- Analyze Single Chip Rooflines And Compilation
- Analyze Distributed Computing via Sharding
- Optimize LLM Training – what happens under the hood, rooflines, sharding
- Optimize LLM Inference – what happens under the hood, rooflines, sharding
- Deep Dive into flash, vLLM, continuous batching, etc.
- Some deep dives along the way:
- Attention, Flash Attention, vLLM, continuous batching
- ML: Quantization, Checkpointing, Data Loading, Numerics
- Practical Tips: Debugging, Overlapping Jax Kernels
- Larger scale: Goodput
- Fancy stuff: Ahead of Time Compilation
- Going deeper: shard map, pallas.
3:30PM Pacific on Wednesdays, starting 2/21/2024. See below for links
| Session | Time | Link to join (or recording) | Slides | Take-Home Exercises | Summary |
|---|---|---|---|---|---|
| 1 | 3:30PM US Pacific, 2/21/2024 | Youtube recording | slides | link | end-to-end Jax LLM |
| 2 | 3:30PM US Pacific, 2/28/2024 | Youtube recording | slides | link | single chip perf and rooflines |
| 3 | 3:30PM US Pacific, 3/13/2024 | Youtube recording | slides | link | multi chip perf and rooflines, 1 |
| 4 | 3:30PM US Pacific, 3/20/2024 | Youtube recording | slides | link | multi chip perf and rooflines, 1 |
| 5 | 3:30PM US Pacific, 3/27/2024 | Youtube recording | slides | link | attention |
| 6 | 3:30PM US Pacific, 4/10/2024 | Youtube recording | slides | link | optimized training |
| postponed | 3:30PM US Pacific, 4/17/2024 | postponed | |||
| 7 | 3:30PM US Pacific, 4/24/2024 | Youtube recording | slides | link | training e2e, inference analysis |
| postponed | 3:30PM US Pacific, 5/01/2024 | postponed | |||
| 8 | 3:30PM US Pacific, 5/08/2024 | Google Meet link |
About me: I’m Rafi Witten, a tech lead on Cloud TPU/GPU Multipod. We develop MaxText and aim to push the frontier on Perf/TCO. In 2023, we executed the "Largest ML Job" ever demonstrated in public and pioneered “Accurate Quantized Training”, a technique for training with 8-bit integers.
Contact me via Discord https://discord.gg/2AWcVatVAw
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for HighPerfLLMs2024
Similar Open Source Tools
HighPerfLLMs2024
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.
ml-road-map
The Machine Learning Road Map is a comprehensive guide designed to take individuals from various levels of machine learning knowledge to a basic understanding of machine learning principles using high-quality, free resources. It aims to simplify the complex and rapidly growing field of machine learning by providing a structured roadmap for learning. The guide emphasizes the importance of understanding AI for everyone, the need for patience in learning machine learning due to its complexity, and the value of learning from experts in the field. It covers five different paths to learning about machine learning, catering to consumers, aspiring AI researchers, ML engineers, developers interested in building ML applications, and companies looking to implement AI solutions.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
Journal-Club
The RISE Journal Club is a bi-weekly reading group that provides a friendly environment for discussing state-of-the-art papers in medical image analysis, AI, and computer vision. The club aims to enhance critical and design thinking skills essential for researchers. Moderators introduce papers for discussion on various topics such as registration, segmentation, federated learning, fairness, and reinforcement learning. The club covers papers from machine and deep learning communities, offering a broad overview of cutting-edge methods.
my-best-resources
my-best-resources is a curated list of resources for web developers and designers, aimed at making their lives easier. It includes sections on design inspiration, ready-made components, stock images, artificial intelligence tools for various use cases, and other useful sources. The repository provides links and descriptions for each resource, offering a valuable collection of tools and assets for web development and design projects.
AI-For-Beginners
AI-For-Beginners is a comprehensive 12-week, 24-lesson curriculum designed by experts at Microsoft to introduce beginners to the world of Artificial Intelligence (AI). The curriculum covers various topics such as Symbolic AI, Neural Networks, Computer Vision, Natural Language Processing, Genetic Algorithms, and Multi-Agent Systems. It includes hands-on lessons, quizzes, and labs using popular frameworks like TensorFlow and PyTorch. The focus is on providing a foundational understanding of AI concepts and principles, making it an ideal starting point for individuals interested in AI.

FFAIVideo
FFAIVideo is a lightweight node.js project that utilizes popular AI LLM to intelligently generate short videos. It supports multiple AI LLM models such as OpenAI, Moonshot, Azure, g4f, Google Gemini, etc. Users can input text to automatically synthesize exciting video content with subtitles, background music, and customizable settings. The project integrates Microsoft Edge's online text-to-speech service for voice options and uses Pexels website for video resources. Installation of FFmpeg is essential for smooth operation. Inspired by MoneyPrinterTurbo, MoneyPrinter, and MsEdgeTTS, FFAIVideo is designed for front-end developers with minimal dependencies and simple usage.
ai-hands-on
A complete, hands-on guide to becoming an AI Engineer. This repository is designed to help you learn AI from first principles, build real neural networks, and understand modern LLM systems end-to-end. Progress through math, PyTorch, deep learning, transformers, RAG, and OCR with clean, intuitive Jupyter notebooks guiding you at every step. Suitable for beginners and engineers leveling up, providing clarity, structure, and intuition to build real AI systems.
willow-inference-server
Willow Inference Server (WIS) is a highly optimized language inference server implementation focused on enabling performant, cost-effective self-hosting of state-of-the-art models for speech and language tasks. It supports ASR and TTS tasks, runs on CUDA with low-end device support, and offers various transport options like REST, WebRTC, and Web Sockets. WIS is memory optimized, leverages CTranslate2 for Whisper support, and enables custom TTS voices. The server automatically detects available CUDA VRAM and optimizes functionality accordingly. Users can programmatically select Whisper models and parameters for each request to balance speed and quality.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.
mcp-for-beginners
The Model Context Protocol (MCP) Curriculum for Beginners is an open-source framework designed to standardize interactions between AI models and client applications. It offers a structured learning path with practical coding examples and real-world use cases in popular programming languages like C#, Java, JavaScript, Rust, Python, and TypeScript. Whether you're an AI developer, system architect, or software engineer, this guide provides comprehensive resources for mastering MCP fundamentals and implementation strategies.

together-cookbook
The Together Cookbook is a collection of code and guides designed to help developers build with open source models using Together AI. The recipes provide examples on how to chain multiple LLM calls, create agents that route tasks to specialized models, run multiple LLMs in parallel, break down tasks into parallel subtasks, build agents that iteratively improve responses, perform LoRA fine-tuning and inference, fine-tune LLMs for repetition, improve summarization capabilities, fine-tune LLMs on multi-step conversations, implement retrieval-augmented generation, conduct multimodal search and conditional image generation, visualize vector embeddings, improve search results with rerankers, implement vector search with embedding models, extract structured text from images, summarize and evaluate outputs with LLMs, generate podcasts from PDF content, and get LLMs to generate knowledge graphs.
llm-engineer-toolkit
The LLM Engineer Toolkit is a curated repository containing over 120 LLM libraries categorized for various tasks such as training, application development, inference, serving, data extraction, data generation, agents, evaluation, monitoring, prompts, structured outputs, safety, security, embedding models, and other miscellaneous tools. It includes libraries for fine-tuning LLMs, building applications powered by LLMs, serving LLM models, extracting data, generating synthetic data, creating AI agents, evaluating LLM applications, monitoring LLM performance, optimizing prompts, handling structured outputs, ensuring safety and security, embedding models, and more. The toolkit covers a wide range of tools and frameworks to streamline the development, deployment, and optimization of large language models.
For similar tasks
HighPerfLLMs2024
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.
bee
Bee is an easy and high efficiency ORM framework that simplifies database operations by providing a simple interface and eliminating the need to write separate DAO code. It supports various features such as automatic filtering of properties, partial field queries, native statement pagination, JSON format results, sharding, multiple database support, and more. Bee also offers powerful functionalities like dynamic query conditions, transactions, complex queries, MongoDB ORM, cache management, and additional tools for generating distributed primary keys, reading Excel files, and more. The newest versions introduce enhancements like placeholder precompilation, default date sharding, ElasticSearch ORM support, and improved query capabilities.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
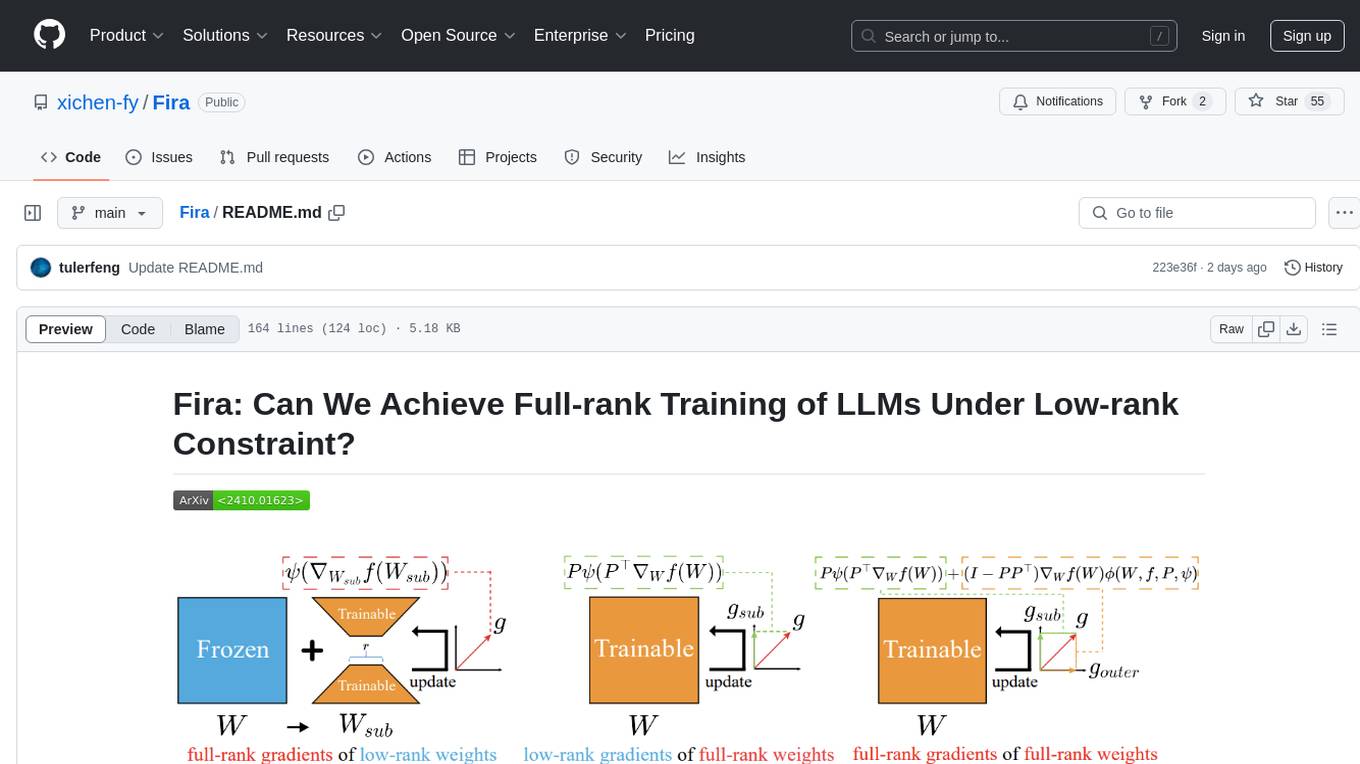
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.