
Journal-Club
The RISE Journal Club aims to create a friendly environment to discuss the latest state-of-the-art papers in the areas of medical image analysis, AI and computer vision. The moderators will briefly introduce the paper and then moderate a discussion where everyone is welcome to provide their thoughts and ask any questions on the paper.
Stars: 67
The RISE Journal Club is a bi-weekly reading group that provides a friendly environment for discussing state-of-the-art papers in medical image analysis, AI, and computer vision. The club aims to enhance critical and design thinking skills essential for researchers. Moderators introduce papers for discussion on various topics such as registration, segmentation, federated learning, fairness, and reinforcement learning. The club covers papers from machine and deep learning communities, offering a broad overview of cutting-edge methods.
README:
The RISE Journal Club aims to create a friendly environment to discuss the latest state-of-the-art papers in the areas of medical image analysis, AI and computer vision. The main objective of this bi-weekly reading group is to help you develop/improve your critical and design thinking skills, which are essential skills for researchers and will help you when presenting or writing your own work.
To date, we have held two editions in which participants joined us remotely from different continents in highly engaging and stimulating sessions.
During each session, the moderators briefly introduce the paper and then moderate a discussion where everyone is welcome to provide their thoughts and ask any questions on the paper. The topics of the papers will vary, and we will try to cover different areas of medical data analysis, e.g., registration, segmentation, federated learning, fairness, and reinforcement learning —among others. Similarly, we will review papers from the machine and deep learning communities, providing you with a broader overview of the state-of-the-art method.
For more about RISE-MICCAI and the RISE Journal Club, check our website at http://www.miccai.org/about-miccai/rise-miccai/
Follow us on GitHub at https://github.com/RISE-MICCAI
And join our mailing list to receive updates about our RISE activities at https://bit.ly/2VMPHXc
| No | Date | Moderator | Title | Link |
|---|---|---|---|---|
| 37 | 14/12/2024 | Mostafa Sharifzadeh | Mitigating Aberration-Induced Noise: A Deep Learning-Based Aberration-to-Aberration Approach | https://arxiv.org/pdf/2308.11149 |
| 36 | 30/11/2024 | Xinrui Yuan | Multi-task Joint Prediction of Infant Cortical Morphological and Cognitive Development | https://link.springer.com/content/pdf/10.1007/978-3-031-43996-4_52.pdf?pdf=inline%20link |
| 35 | 16/11/2024 | Yiyang Xu | Improved 3D Whole Heart Geometry from Sparse CMR Slices | https://www.arxiv.org/abs/2408.07532 |
| 34 | 02/11/2024 | Dewmini Hasara Wickremasinghe | Improving the Scan-rescan Precision of AI-based CMR Biomarker Estimation | https://arxiv.org/abs/2408.11754 |
| 33 | 21/09/2024 | Ahmed Nebli | GRAM: Graph Regularizable Assessment Metric | https://drive.google.com/file/d/1aFCpOkuLw06_bbERqXq6Tu_5mJtPPueL/view?usp=sharing |
| 32 | 07/09/2024 | Paula Feldman | VesselVAE: Recursive Variational Autoencoders for 3D Blood Vessel Synthesis | https://arxiv.org/abs/2307.03592 |
| 31 | 27/07/2024 | Nahal Mirzaie | Weakly-Supervised Drug Efficiency Estimation with Confidence Score: Application to COVID-19 Drug Discovery | https://link.springer.com/chapter/10.1007/978-3-031-43993-3_65 |
| 30 | 13/07/2024 | John Kalkhof | M3D-NCA: Robust 3D Segmentation with Built-In Quality Control | https://arxiv.org/pdf/2309.02954.pdf |
| 29 | 29/06/2024 | Gasper Podobnik | HDilemma: Are Open-Source Hausdorff Distance Implementations Equivalent? | https://link.springer.com/chapter/10.1007/978-3-031-72114-4_30 |
| 28 | 15/06/2024 | DongAo Ma | Foundation Ark: Accruing and Reusing Knowledge for Superior and Robust Performance | https://arxiv.org/abs/2310.09507 |
| 27 | 01/06/2024 | Alvaro Gonzalez-Jimenez | Robust T-Loss for Medical Image Segmentation | https://arxiv.org/abs/2306.00753 |
| 26 | 18/05/2024 | Pamela Guevara | Superficial white matter bundle atlas based on hierarchical fiber clustering over probabilistic tractography data | https://www.sciencedirect.com/science/article/pii/S1053811922006656 |
| 25 | 04/05/2024 | Tareen Dawood | Evaluating the Fairness of Deep Learning Uncertainty Estimates in Medical Image Analysis | https://arxiv.org/pdf/2303.03242 |
| 24 | 20/04/2024 | Islem Rekik | Special session: The journey of a research paper: from writing to review | |
| 23 | 06/04/2024 | Zhen Yuan | Orthogonal annotation benefits barely-supervised medical image segmentation | https://arxiv.org/abs/2303.13090 |
| 22 | 23/03/2024 | Charles Delahunt | Consistent Individualized Feature Attribution for Tree Ensembles | https://arxiv.org/abs/1802.03888 |
| 21 | 09/03/2024 | Charles Delahunt | Understanding metric-related pitfalls in image analysis validation | https://arxiv.org/abs/2302.01790 |
| 20 | 24/02/2024 | Qiang Zhang | Toward Replacing Late Gadolinium Enhancement With Artificial Intelligence Virtual Native Enhancement for Gadolinium-Free Cardiovascular Magnetic Resonance Tissue Characterization in Hypertrophic Cardiomyopathy and Artificial intelligence for contrast-free MRI: Scar assessment in myocardial infarction using deep learning–based virtual native enhancement | https://www.ahajournals.org/doi/10.1161/CIRCULATIONAHA.122.060137 and https://www.ahajournals.org/doi/10.1161/CIRCULATIONAHA.121.054432 |
| 19 | 13/01/2024 | Charles, Andrea, Ahmed, Tareen and Esther | Opening session multi-linguistic: french, spanish, english, arabic | |
| 18 | 13/12/2023 | Tiarna Lee | An investigation into the impact of deep learning model choice on sex and race bias in cardiac MR segmentation | https://arxiv.org/abs/2308.13415 |
| 17 | 29/11/2023 | Prosper Oyibo | Two-stage automated diagnosis framework for urogenital schistosomiasis in microscopy images from low-resource settings | https://doi.org/10.1117/1.JMI.10.4.044005 |
| 16 | 15/11/2023 | Tareen Dawood | Uncertainty aware training to improve deep learning model calibration for classification of cardiac MR images | https://www.sciencedirect.com/science/article/pii/S1361841523001214 |
| 15 | 01/11/2023 | Prerak Mody and Mortiz Fuchs | Prediction Variability to Identify Reduced AI Performance in Cancer Diagnosis at MRI and CT | https://doi.org/10.1148/radiol.230275 |
| 14 | 20/09/2023 | Ayantika Das | Diffusion Autoencoders: Toward a Meaningful and Decodable Representation | https://openaccess.thecvf.com/content/CVPR2022/papers/Preechakul_Diffusion_Autoencoders_Toward_a_Meaningful_and_Decodable_Representation_CVPR_2022_paper.pdf |
| 13 | 06/09/2023 | Charles | Metrics to guide development of machine learning algorithms for malaria diagnosis | https://arxiv.org/abs/2209.06947 |
| 12 | 26/07/2023 | Miguel López-Pérez | Disentangling human error from the ground truth in segmentation of medical images | https://arxiv.org/abs/2007.15963 |
| 11 | 12/07/2023 | Yasar Mehmood | Geometric Visual Similarity Learning in 3D Medical Image Self-supervised Pre-training | https://arxiv.org/abs/2303.00874 |
| 10 | 28/06/2023 | Samra Irshad | STEEX: Steering Counterfactual Explanations with semantics | https://arxiv.org/abs/2111.09094 |
| 9 | 14/06/2023 | Islem Rekik | HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients | https://arxiv.org/pdf/2010.01264 |
| 8 | 03/06/2023 | Charles | Attention Is All You Need | https://arxiv.org/abs/1706.03762 |
| 7 | 20/05/2023 | Islem Rekik | On Predicting Generalization using GANs | https://openreview.net/pdf?id=eW5R4Cek6y6 |
| 6 | 06/05/2023 | Charles and Andrea | Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization | https://arxiv.org/abs/1404.1100 |
| 5 | 22/04/2023 | Charles Delahunt | A tutorial on Principal Component Analysis | https://arxiv.org/abs/1404.1100 |
| 4 | 08/04/2023 | Charles and Islem | A dirty dozen: 12 p-value misconceptions | http://mcb112.org/w06/Goodman08.pdf |
| 3 | 25/03/2023 | Islem and Charles | Coherent Gradients: An Approach to Understanding Generalization in Gradient Descent-based Optimization | https://openreview.net/pdf?id=ryeFY0EFwS |
| 2 | 11/03/2023 | Charles and Andrea | Imagenet classification with deep convolutional neural networks | https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf |
| 1 | 25/02/2023 | Islem Rekik | Hierarchical Reconstruction of 7T-like Images from 3T MRI Using Multi-level CCA and Group Sparsity | https://link.springer.com/chapter/10.1007/978-3-319-24571-3_79 |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Journal-Club
Similar Open Source Tools
Journal-Club
The RISE Journal Club is a bi-weekly reading group that provides a friendly environment for discussing state-of-the-art papers in medical image analysis, AI, and computer vision. The club aims to enhance critical and design thinking skills essential for researchers. Moderators introduce papers for discussion on various topics such as registration, segmentation, federated learning, fairness, and reinforcement learning. The club covers papers from machine and deep learning communities, offering a broad overview of cutting-edge methods.
SurveyX
SurveyX is an advanced academic survey automation system that leverages Large Language Models (LLMs) to generate high-quality, domain-specific academic papers and surveys. Users can request comprehensive academic papers or surveys tailored to specific topics by providing a paper title and keywords for literature retrieval. The system streamlines academic research by automating paper creation, saving users time and effort in compiling research content.
HighPerfLLMs2024
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
aip-community-registry
AIP Community Registry is a collection of community-built applications and projects leveraging Palantir's AIP Platform. It showcases real-world implementations from developers using AIP in production. The registry features various solutions demonstrating practical implementations and integration patterns across different use cases.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
farel-bench
The 'farel-bench' project is a benchmark tool for testing LLM reasoning abilities with family relationship quizzes. It generates quizzes based on family relationships of varying degrees and measures the accuracy of large language models in solving these quizzes. The project provides scripts for generating quizzes, running models locally or via APIs, and calculating benchmark metrics. The quizzes are designed to test logical reasoning skills using family relationship concepts, with the goal of evaluating the performance of language models in this specific domain.
my-best-resources
my-best-resources is a curated list of resources for web developers and designers, aimed at making their lives easier. It includes sections on design inspiration, ready-made components, stock images, artificial intelligence tools for various use cases, and other useful sources. The repository provides links and descriptions for each resource, offering a valuable collection of tools and assets for web development and design projects.
redis-ai-resources
A curated repository of code recipes, demos, and resources for basic and advanced Redis use cases in the AI ecosystem. It includes demos for ArxivChatGuru, Redis VSS, Vertex AI & Redis, Agentic RAG, ArXiv Search, and Product Search. Recipes cover topics like Getting started with RAG, Semantic Cache, Advanced RAG, and Recommendation systems. The repository also provides integrations/tools like RedisVL, AWS Bedrock, LangChain Python, LangChain JS, LlamaIndex, Semantic Kernel, RelevanceAI, and DocArray. Additional content includes blog posts, talks, reviews, and documentation related to Vector Similarity Search, AI-Powered Document Search, Vector Databases, Real-Time Product Recommendations, and more. Benchmarks compare Redis against other Vector Databases and ANN benchmarks. Documentation includes QuickStart guides, official literature for Vector Similarity Search, Redis-py client library docs, Redis Stack documentation, and Redis client list.
awesome-generative-ai-apis
Awesome Generative AI & LLM APIs is a curated list of useful APIs that allow developers to integrate generative models into their applications without building the models from scratch. These APIs provide an interface for generating text, images, or other content, and include pre-trained language models for various tasks. The goal of this project is to create a hub for developers to create innovative applications, enhance user experiences, and drive progress in the AI field.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
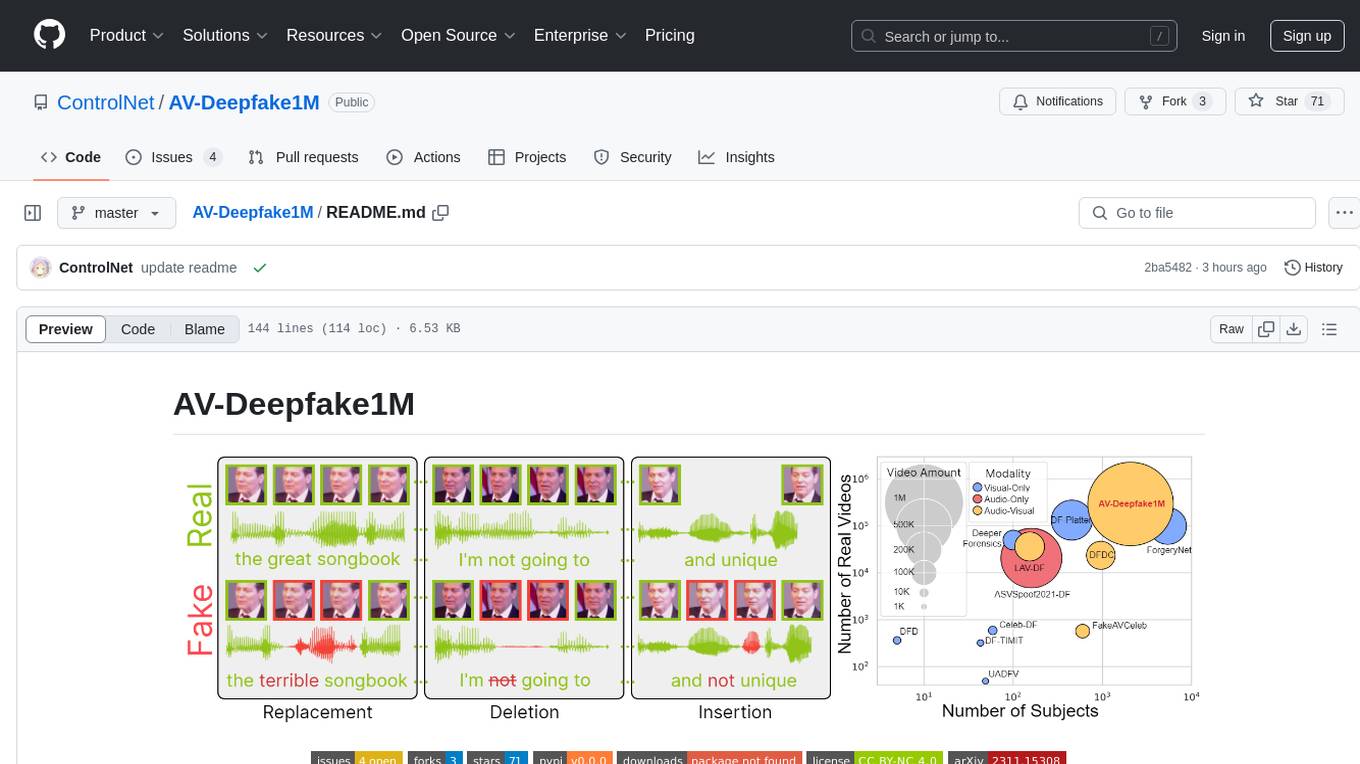
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.
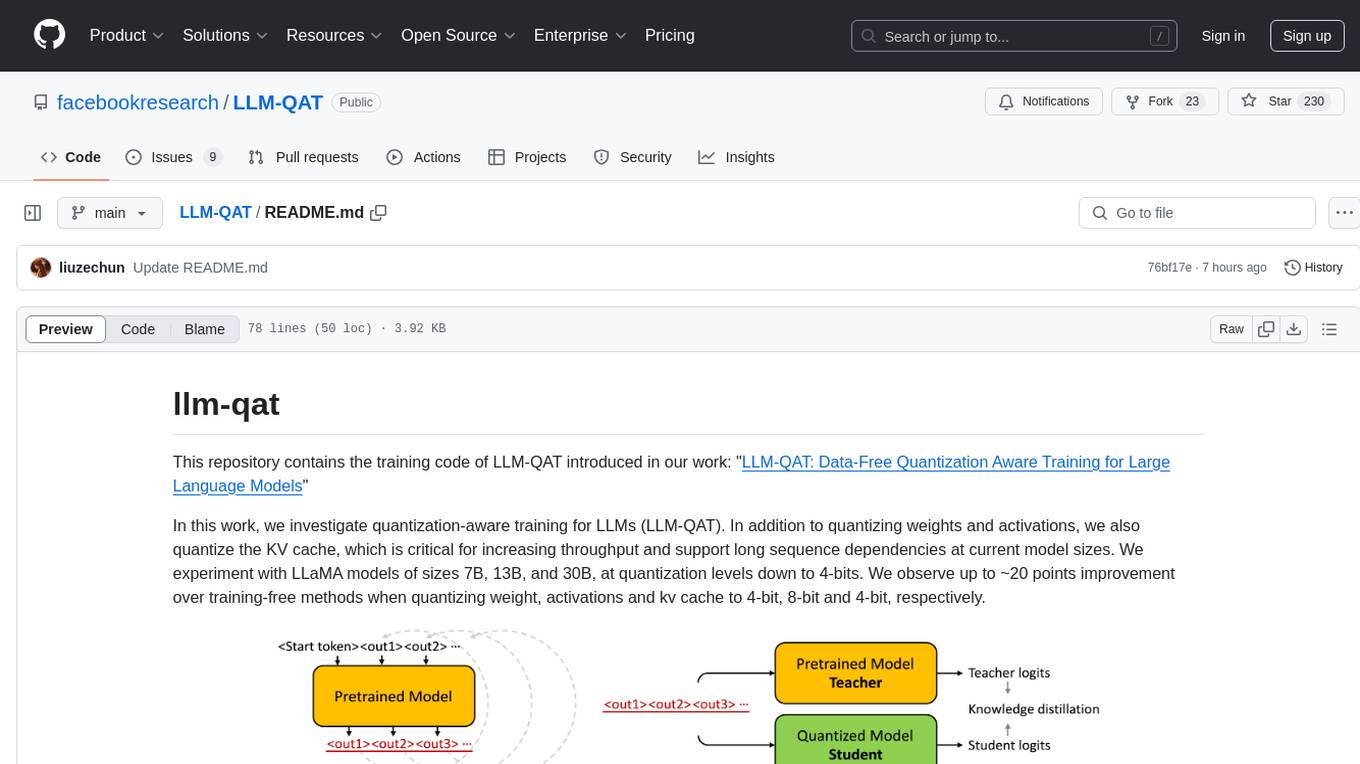
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
recommenders
Recommenders is a project under the Linux Foundation of AI and Data that assists researchers, developers, and enthusiasts in prototyping, experimenting with, and bringing to production a range of classic and state-of-the-art recommendation systems. The repository contains examples and best practices for building recommendation systems, provided as Jupyter notebooks. It covers tasks such as preparing data, building models using various recommendation algorithms, evaluating algorithms, tuning hyperparameters, and operationalizing models in a production environment on Azure. The project provides utilities to support common tasks like loading datasets, evaluating model outputs, and splitting training/test data. It includes implementations of state-of-the-art algorithms for self-study and customization in applications.
For similar tasks
Journal-Club
The RISE Journal Club is a bi-weekly reading group that provides a friendly environment for discussing state-of-the-art papers in medical image analysis, AI, and computer vision. The club aims to enhance critical and design thinking skills essential for researchers. Moderators introduce papers for discussion on various topics such as registration, segmentation, federated learning, fairness, and reinforcement learning. The club covers papers from machine and deep learning communities, offering a broad overview of cutting-edge methods.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.