
farel-bench
Testing LLM reasoning abilities with family relationship quizzes.
Stars: 57
The 'farel-bench' project is a benchmark tool for testing LLM reasoning abilities with family relationship quizzes. It generates quizzes based on family relationships of varying degrees and measures the accuracy of large language models in solving these quizzes. The project provides scripts for generating quizzes, running models locally or via APIs, and calculating benchmark metrics. The quizzes are designed to test logical reasoning skills using family relationship concepts, with the goal of evaluating the performance of language models in this specific domain.
README:
This project is a family relationship (FaRel) benchmark for testing LLM reasoning abilities with family relationship quizzes.
Note: this benchmark suffers from saturation that made it obsolete. If you are interested in logical reasoning performance of LLM models then check out its successor, lineage-bench: https://github.com/fairydreaming/lineage-bench
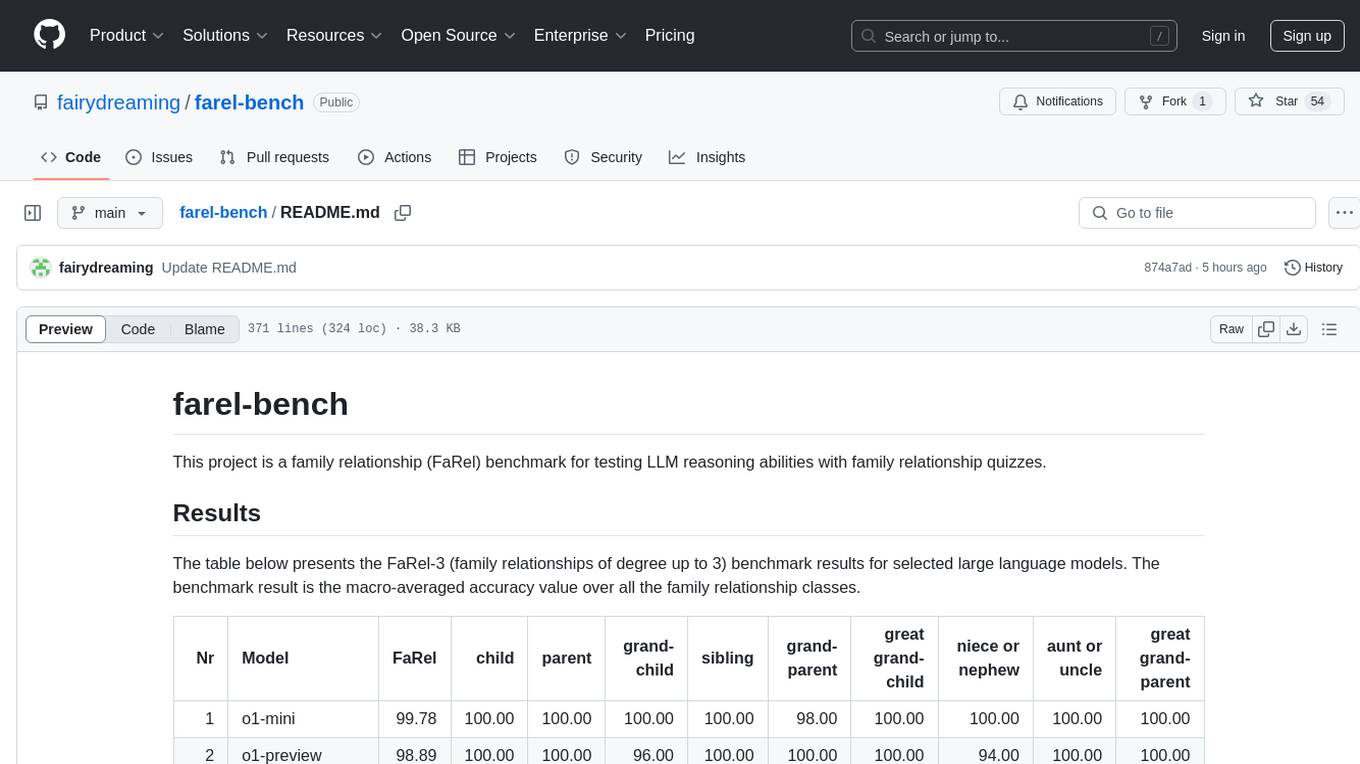
The table below presents 20 best FaRel-3 (family relationships of degree up to 3) benchmark results. The benchmark result is the macro-averaged accuracy value over all the family relationship classes.
| Nr | Model | FaRel | child | parent | grand-child | sibling | grand-parent | great grand-child | niece or nephew | aunt or uncle | great grand-parent |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | deepseek-r1 | 99.78 | 100.00 | 100.00 | 100.00 | 98.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 1 | o1-mini | 99.78 | 100.00 | 100.00 | 100.00 | 100.00 | 98.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 3 | o1-preview | 98.89 | 100.00 | 100.00 | 96.00 | 100.00 | 100.00 | 100.00 | 94.00 | 100.00 | 100.00 |
| 4 | qwq-32b-preview | 96.67 | 100.00 | 100.00 | 100.00 | 98.00 | 100.00 | 98.00 | 90.00 | 88.00 | 96.00 |
| 5 | deepseek-v3 | 96.44 | 100.00 | 100.00 | 100.00 | 96.00 | 100.00 | 100.00 | 82.00 | 92.00 | 98.00 |
| 6 | claude-3.5-sonnet-1022 | 93.33 | 100.00 | 100.00 | 100.00 | 92.00 | 100.00 | 98.00 | 76.00 | 74.00 | 100.00 |
| 7 | qvq-72b-preview | 91.56 | 100.00 | 100.00 | 98.00 | 92.00 | 96.00 | 86.00 | 84.00 | 76.00 | 92.00 |
| 8 | mistral-large-2411-Q8_0 | 88.44 | 100.00 | 100.00 | 94.00 | 92.00 | 100.00 | 90.00 | 70.00 | 54.00 | 96.00 |
| 8 | Sky-T1-32B-Preview-Q8_0 | 88.44 | 100.00 | 100.00 | 80.00 | 96.00 | 98.00 | 90.00 | 82.00 | 50.00 | 100.00 |
| 10 | deepseek-v2-chat-0628-Q8_0 | 87.78 | 100.00 | 100.00 | 98.00 | 86.00 | 94.00 | 94.00 | 60.00 | 60.00 | 98.00 |
| 11 | gemini-pro-1.5-002 | 87.11 | 100.00 | 100.00 | 74.00 | 88.00 | 100.00 | 84.00 | 70.00 | 72.00 | 96.00 |
| 12 | mistral-large-2411 | 86.89 | 100.00 | 100.00 | 68.00 | 88.00 | 98.00 | 96.00 | 64.00 | 68.00 | 100.00 |
| 12 | mistral-large-2 | 86.89 | 100.00 | 100.00 | 70.00 | 92.00 | 100.00 | 94.00 | 60.00 | 66.00 | 100.00 |
| 12 | claude-3.5-sonnet | 86.89 | 100.00 | 100.00 | 98.00 | 80.00 | 98.00 | 94.00 | 60.00 | 56.00 | 96.00 |
| 15 | llama-3.3-70b-instruct | 86.44 | 100.00 | 100.00 | 90.00 | 92.00 | 100.00 | 76.00 | 68.00 | 56.00 | 96.00 |
| 16 | gpt-4-turbo | 86.22 | 100.00 | 100.00 | 92.00 | 84.00 | 96.00 | 90.00 | 56.00 | 60.00 | 98.00 |
| 17 | llama-3.1-405b-instruct | 85.78 | 100.00 | 100.00 | 88.00 | 92.00 | 98.00 | 88.00 | 54.00 | 52.00 | 100.00 |
| 18 | minimax-01 | 85.56 | 100.00 | 100.00 | 96.00 | 82.00 | 100.00 | 72.00 | 52.00 | 68.00 | 100.00 |
| 19 | gpt-4o-2024-11-20 | 84.22 | 100.00 | 100.00 | 84.00 | 78.00 | 98.00 | 82.00 | 62.00 | 56.00 | 98.00 |
| 20 | gemini-2.0-flash-exp | 84.00 | 100.00 | 100.00 | 84.00 | 78.00 | 94.00 | 86.00 | 66.00 | 50.00 | 98.00 |
To see results for all models benchmarked so far check the results.md file.
Notes:
- Models having quantization suffix in their name were run locally on llama.cpp, remaining models were run via OpenAI or OpenRouter APIs.
- Models with -sys suffix had system prompt set to 'You are a master of logical thinking. You carefully analyze the premises step by step, take detailed notes and draw intermediate conclusions based on which you can find the final answer to any question.'.
- Very low benchmark results for gemma-2b, qwen1_5-7b, and WizardLM-2-7B are caused by the inability of the models to mark the selected answer option as specified in the prompt.
- After running the benchmark for nemotron-4-340b-instruct I noticed that in several cases the model response was cut short by the activation of inference timeout set to 10 minutes. If not for that, the score could be even better.
- gemma-2-9b and gemma-2-27b model results are courtesy of Reddit user Healthy-Nebula-3603
I also tested some models in Polish language:
| Nr | Model | FaRel | child | parent | grand-child | sibling | grand-parent | great grand-child | niece or nephew | aunt or uncle | great grand-parent |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | llama-3.1-405b-instruct-sys-pl | 92.89 | 100.00 | 100.00 | 98.00 | 94.00 | 100.00 | 94.00 | 72.00 | 80.00 | 98.00 |
| 2 | qwen-2.5-72b-instruct-pl | 88.44 | 100.00 | 100.00 | 98.00 | 90.00 | 100.00 | 88.00 | 76.00 | 46.00 | 98.00 |
| 3 | llama-3.1-405b-instruct-pl | 83.33 | 100.00 | 100.00 | 100.00 | 74.00 | 100.00 | 78.00 | 50.00 | 56.00 | 92.00 |
| 4 | Bielik-11B-v2.3-Instruct-Q8_0-sys-pl | 81.56 | 100.00 | 98.00 | 88.00 | 88.00 | 98.00 | 76.00 | 68.00 | 34.00 | 84.00 |
| 5 | qwen-2.5-72b-instruct-sys-pl | 80.00 | 100.00 | 100.00 | 96.00 | 92.00 | 100.00 | 82.00 | 52.00 | 32.00 | 66.00 |
| 6 | Bielik-11B-v2.3-Instruct-Q8_0-pl | 76.00 | 100.00 | 100.00 | 92.00 | 42.00 | 100.00 | 56.00 | 72.00 | 34.00 | 88.00 |
All tested models perform better in Polish compared to results for English language. Is it easier to "reason" in Polish language?
The purpose of this project is to test LLM reasoning abilities with family relationship quizzes. Why use family relationships?
- Family relationships are commonly known concepts.
- They allow to create quizzes of scalable difficulty by increasing the relationship degree.
- Easy randomization of the quizzes by changing the names of family members and the order of listed relations.
Consider the following graph of family relationships:

We can observe that:
- child and parent relationships have distance 1 from self,
- grandchild, grandparent, and sibling relationships have distance 2 from self,
- great grandchild, niece or nephew, aunt or uncle, and great grandparent relationships have distance 3 from self, and so on.
We use such relationship graphs to programmatically generate family quizzes. Generated quizzes have the following properties:
- Connections between family members are specified by using only the parental relationship.
- Family member connections specify a graph of all family relationships of degree up to N.
- The quiz question is to differentiate between family relationships of degree N.
- LLM is instructed to select the i-th quiz answer option by enclosing the selected answer number with the
<ANSWER>i</ANSWER>tag.
Given the family relationships:
* Ralph is Anthony's parent.
* Albert is Ralph's parent.
What is Anthony's relationship to Ralph?
Select the correct answer:
1. Anthony is Ralph's child.
2. Anthony is Ralph's parent.
Enclose the selected answer number in the <ANSWER> tag, for example: <ANSWER>1</ANSWER>.
Given the family relationships:
* Wayne is Brittany's parent.
* Billy is Madison's parent.
* Madison is Wayne's parent.
* Brittany is Amanda's parent.
* Madison is Michael's parent.
What is Amanda's relationship to Wayne?
Select the correct answer:
1. Amanda is Wayne's grandparent.
2. Amanda is Wayne's sibling.
3. Amanda is Wayne's grandchild.
Enclose the selected answer number in the <ANSWER> tag, for example: <ANSWER>1</ANSWER>.
Given the family relationships:
* Brittany is Jeremy's parent.
* Peter is Lauren's parent.
* Peter is Madison's parent.
* Brittany is Peter's parent.
* Madison is Betty's parent.
* Richard is Andrea's parent.
* Lauren is Gabriel's parent.
* Gabriel is Richard's parent.
* Janet is Brittany's parent.
What is Andrea's relationship to Lauren?
Select the correct answer:
1. Andrea is Lauren's niece or nephew.
2. Andrea is Lauren's aunt or uncle.
3. Andrea is Lauren's great grandchild.
4. Andrea is Lauren's great grandparent.
Enclose the selected answer number in the <ANSWER> tag, for example: <ANSWER>1</ANSWER>.
We measure the performance of the LLM by macro-averaging the classification accuracy of all family relationships present in the dataset. So for example if a given LLM has the following accuracy values for family relationship quizzes of degrees up to 3:
- child: 100.00
- parent: 100.00
- grandchild: 96.00
- sibling: 22.00
- grandparent: 72.00
- great grandchild: 46.00
- niece or nephew: 46.00
- aunt or uncle: 18.00
- great grandparent: 68.00
then the overall macro-averaged accuracy is (100 + 100 + 96 + 22 + 72 + 46 + 46 + 18 + 68) / 9 = ~63.11 To differentiate between benchmark results calculated for datasets with different maximum family relationship lengths, we propose to include the maximum family relationship length in the benchmark result label. So if an accuracy of 63.11 was computed for family relationships of length up to 3, the overall result would be labeled as FaRel-3 and would have a value of 63.11.
There are five Python scripts in the FaRel benchmark:
- The farel_bench.py script generates family relationship quizzes in a CSV format.
- The run_model.py script generates answers for the quizzes by using llama.cpp and selected LLM and calculates the accuracy values for all family relationships.
- The run_openai.py script generates answers for the quizzes by using OpenAI API and calculates the accuracy values for all family relationships.
- The run_openrouter.py script generates answers for the quizzes by using OpenRouter API and calculates the accuracy values for all family relationships.
- The compute_metrics.py script analyzes log files in a given directory, calculates the macro-averaged accuracy value that is the FaRel benchmark result, and outputs a result table.
Generating quizzes and storing model answers:
./farel_bench.py --shuffle -l 1 -n 50 -r 42|./run_model.py -b ~/projects/llama.cpp/main -m ~/projects/llama.cpp/models/llama-2-7b-chat.Q8_0.gguf|tee ./results/llama-2-7b-chat.Q8_0.log
./farel_bench.py --shuffle -l 3 -n 50 -r 42|./run_openai.py -m gpt-4|tee ./results/gpt-4.log
Calculating FaRel benchmark metrics:
./compute_metrics.py ./results/
The farel_bench.py is the quiz generator script. It has the following options:
usage: farel_bench.py [-h] -l LENGTH [-p PROMPT] [-s] [-n NUMBER] [-r SEED]
options:
-h, --help show this help message and exit
-l LENGTH, --length LENGTH
Maximum length of family relationship paths.
-p PROMPT, --prompt PROMPT
Prompt template of the quiz. The default prompt template is: 'Given the family
relationships:\n$QUIZ_RELATIONS\n$QUIZ_QUESTION\nSelect the correct
answer:\n$QUIZ_ANSWERS\nEnclose the selected answer number in the <ANSWER> tag, for
example: <ANSWER>1</ANSWER>.'
-s, --shuffle Shuffle the order of parental relations and answer options in the quiz.
-n NUMBER, --number NUMBER
Number of quizzes generated for each family relationship.
-r SEED, --seed SEED Random seed value
The run_model.py script uses llama.cpp to generate answers for family relationship quizzes generated by farel_bench.py for a selected LLM.
usage: run_model.py [-h] -b BINARY [-t TIMEOUT] -m MODEL [-s [SYSTEM_PROMPT]]
options:
-h, --help show this help message and exit
-b BINARY, --binary BINARY
Path to the llama.cpp executable binary.
-t TIMEOUT, --timeout TIMEOUT
llama.cpp execution timeout (seconds)
-m MODEL, --model MODEL
Path to the GGUF model file.
-s [SYSTEM_PROMPT], --system-prompt [SYSTEM_PROMPT]
Use given system prompt. By default, the system prompt is not used. When this option is
passed without a value, the default system prompt value is used: 'You are a master of
logical thinking. You carefully analyze the premises step by step, take detailed notes and
draw intermediate conclusions based on which you can find the final answer to any
question.'
The run_model.py script uses OpenAI API to generate answers for family relationship quizzes generated by farel_bench.py for a selected LLM.
usage: run_openai.py [-h] -m MODEL [-s [SYSTEM_PROMPT]]
options:
-h, --help show this help message and exit
-m MODEL, --model MODEL
OpenAI model name.
-s [SYSTEM_PROMPT], --system-prompt [SYSTEM_PROMPT]
Use given system prompt. By default, the system prompt is not used. When this option is
passed without a value, the default system prompt value is used: 'You are a master of
logical thinking. You carefully analyze the premises step by step, take detailed notes and
draw intermediate conclusions based on which you can find the final answer to any
question.'
The run_model.py script uses OpenRouter API to generate answers for family relationship quizzes generated by farel_bench.py for a selected LLM.
usage: run_openrouter.py [-h] -m MODEL [-s [SYSTEM_PROMPT]]
options:
-h, --help show this help message and exit
-m MODEL, --model MODEL
OpenRouter model name.
-s [SYSTEM_PROMPT], --system-prompt [SYSTEM_PROMPT]
Use given system prompt. By default, the system prompt is not used. When this option is
passed without a value, the default system prompt value is used: 'You are a master of
logical thinking. You carefully analyze the premises step by step, take detailed notes and
draw intermediate conclusions based on which you can find the final answer to any
question.'
The compute_metrics.py script reads .log files from a given directory, calculates the FaRel benchmark metrics, and prints a result table in a markdown format.
usage: compute_metrics.py [-h] dir
positional arguments:
dir Directory containing farel-bench log files.
options:
-h, --help show this help message and exit
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for farel-bench
Similar Open Source Tools
farel-bench
The 'farel-bench' project is a benchmark tool for testing LLM reasoning abilities with family relationship quizzes. It generates quizzes based on family relationships of varying degrees and measures the accuracy of large language models in solving these quizzes. The project provides scripts for generating quizzes, running models locally or via APIs, and calculating benchmark metrics. The quizzes are designed to test logical reasoning skills using family relationship concepts, with the goal of evaluating the performance of language models in this specific domain.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.
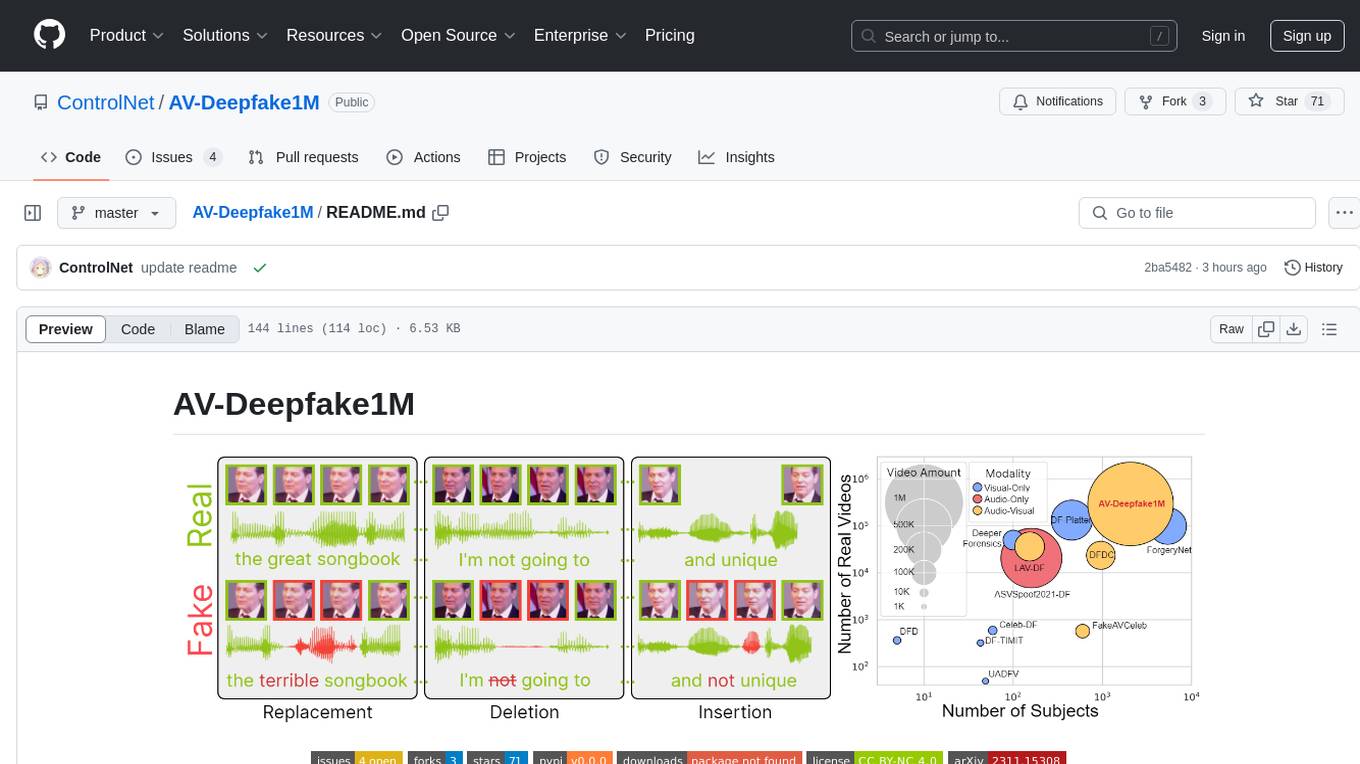
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
RouterArena
RouterArena is an open evaluation platform and leaderboard for LLM routers, aiming to provide a standardized evaluation framework for assessing the performance of routers in terms of accuracy, cost, and other metrics. It offers diverse data coverage, comprehensive metrics, automated evaluation, and a live leaderboard to track router performance. Users can evaluate their routers by following setup steps, obtaining routing decisions, running LLM inference, and evaluating router performance. Contributions and collaborations are welcome, and users can submit their routers for evaluation to be included in the leaderboard.
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.
For similar tasks
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
uvadlc_notebooks
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.
farel-bench
The 'farel-bench' project is a benchmark tool for testing LLM reasoning abilities with family relationship quizzes. It generates quizzes based on family relationships of varying degrees and measures the accuracy of large language models in solving these quizzes. The project provides scripts for generating quizzes, running models locally or via APIs, and calculating benchmark metrics. The quizzes are designed to test logical reasoning skills using family relationship concepts, with the goal of evaluating the performance of language models in this specific domain.
LLMcalc
LLM Calculator is a script that estimates the memory requirements and performance of Hugging Face models based on quantization levels. It fetches model parameters, calculates required memory, and analyzes performance with different RAM/VRAM configurations. The tool supports Windows and Linux, AMD, Intel, and Nvidia GPUs. Users can input a Hugging Face model ID to get its parameter count and analyze memory requirements for various quantization schemes. The tool provides estimates for GPU offload percentage and throughput in tk/s. It requires dependencies like python, uv, pciutils for AMD + Linux, and drivers for Nvidia. The tool is designed for rough estimates and may not work with MultiGPU setups.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.