
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey
Stars: 103
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
README:
Efficient Multimodal Large Language Models: A Survey [arXiv]
Yizhang Jin12, Jian Li1, Yexin Liu3, Tianjun Gu4, Kai Wu1, Zhengkai Jiang1, Muyang He3, Bo Zhao3, Xin Tan4, Zhenye Gan1, Yabiao Wang1, Chengjie Wang1, Lizhuang Ma2
1Tencent YouTu Lab, 2Shanghai Jiao Tong University, 3Beijing Academy of Artificial Intelligence, 4East China Normal University
@misc{jin2024efficient,
title={Efficient Multimodal Large Language Models: A Survey},
author={Yizhang Jin and Jian Li and Yexin Liu and Tianjun Gu and Kai Wu and Zhengkai Jiang and Muyang He and Bo Zhao and Xin Tan and Zhenye Gan and Yabiao Wang and Chengjie Wang and Lizhuang Ma},
year={2024},
eprint={2405.10739},
archivePrefix={arXiv},
primaryClass={cs.CV}
}

In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions.

| Model | Vision Encoder | Resolution | Vision Encoder Parameter Size | LLM | LLM Parameter Size | Vision-LLM Projector | Timeline |
|---|---|---|---|---|---|---|---|
| MobileVLM | CLIP ViT-L/14 | 336 | 0.3B | MobileLLaMA | 2.7B | LDP | 2023-12 |
| LLaVA-Phi | CLIP ViT-L/14 | 336 | 0.3B | Phi-2 | 2.7B | MLP | 2024-01 |
| Imp-v1 | SigLIP | 384 | 0.4B | Phi-2 | 2.7B | - | 2024-02 |
| TinyLLaVA | SigLIP-SO | 384 | 0.4B | Phi-2 | 2.7B | MLP | 2024-02 |
| Bunny | SigLIP-SO | 384 | 0.4B | Phi-2 | 2.7B | MLP | 2024-02 |
| MobileVLM-v2-3B | CLIP ViT-L/14 | 336 | 0.3B | MobileLLaMA | 2.7B | LDPv2 | 2024-02 |
| MoE-LLaVA-3.6B | CLIP-Large | 384 | - | Phi-2 | 2.7B | MLP | 2024-02 |
| Cobra | DINOv2, SigLIP-SO | 384 | 0.3B+0.4B | Mamba-2.8b-Zephyr | 2.8B | MLP | 2024-03 |
| Mini-Gemini | CLIP-Large | 336 | - | Gemma | 2B | MLP | 2024-03 |
| Vary-toy | CLIP | 224 | - | Qwen | 1.8B | - | 2024-01 |
| TinyGPT-V | EVA | 224/448 | - | Phi-2 | 2.7B | Q-Former | 2024-01 |
| SPHINX-Tiny | DINOv2 , CLIP-ConvNeXt | 448 | - | TinyLlama | 1.1B | - | 2024-02 |
| ALLaVA-Longer | CLIP-ViT-L/14 | 336 | 0.3B | Phi-2 | 2.7B | - | 2024-02 |
| MM1-3B-MoE-Chat | CLIP_DFN-ViT-H | 378 | - | - | 3B | C-Abstractor | 2024-03 |
| LLaVA-Gemma | DinoV2 | - | - | Gemma-2b-it | 2B | - | 2024-03 |
| Mipha-3B | SigLIP | 384 | - | Phi-2 | 2.7B | - | 2024-03 |
| VL-Mamba | SigLIP-SO | 384 | - | Mamba-2.8B-Slimpj | 2.8B | VSS-L2 | 2024-03 |
| MiniCPM-V 2.0 | SigLIP | - | 0.4B | MiniCPM | 2.7B | Perceiver Resampler | 2024-03 |
| DeepSeek-VL | SigLIP-L | 384 | 0.4B | DeepSeek-LLM | 1.3B | MLP | 2024-03 |
| KarmaVLM | SigLIP-SO | 384 | 0.4B | Qwen1.5 | 0.5B | - | 2024-02 |
| moondream2 | SigLIP | - | - | Phi-1.5 | 1.3B | - | 2024-03 |
| Bunny-v1.1-4B | SigLIP | 1152 | - | Phi-3-Mini-4K | 3.8B | - | 2024-02 |
⚡We will actively maintain this repository and incorporate new research as it emerges. If you have any questions, please feel free to contact [email protected].
- Mobilevlm: A fast, reproducible and strong vision language assistant for mobile devices. arXiv, 2023 [Paper]
- Llava-phi: Efficient multi-modal assistant with small language model. arXiv, 2024 [Paper]
- Imp-v1: An emprical study of multimodal small language models. arXiv, 2024 [Paper]
- TinyLLaVA: A Framework of Small-scale Large Multimodal Models. arxiv, 2024 [Paper]
- (Bunny)Efficient multimodal learning from data-centric perspective.arXiv, 2024 [Paper]
- Gemini: a family of highly capable multimodal modelsarXiv, 2023 [Paper]
- Mobilevlm v2: Faster and stronger baseline for vision language model. arXiv, 2024 [Paper]
- Moe-llava: Mixture of experts for large vision-language models. arXiv, 2024 [Paper]
- Cobra:Extending mamba to multi-modal large language model for efficient inference. arXiv, 2024 [Paper]
- Mini-gemini: Mining the potential of multi-modality vision language models. arXiv, 2024 [Paper]
- (Vary-toy)Small language model meets with reinforced vision vocabulary. arXiv, 2024 [Paper]
- Tinygpt-v: Efficient multimodal large language model via small backbones.arXiv, 2023 [Paper]
- SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models.arXiv, 2024 [Paper]
- ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model.arXiv, 2024 [Paper]
- Mm1: Methods, analysis & insights from multimodal llm pre-training.arXiv, 2024 [Paper]
- LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model.arXiv, 2024 [Paper]
- Mipha: A Comprehensive Overhaul of Multimodal Assistant with Small Language Models.arXiv, 2024 [Paper]
- VL-Mamba: Exploring State Space Models for Multimodal Learning.arXiv, 2024 [Paper]
- MiniCPM-V 2.0: An Efficient End-side MLLM with Strong OCR and Understanding Capabilities.github, 2024 [Github]
- DeepSeek-VL: Towards Real-World Vision-Language Understanding .arXiv, 2024 [Paper]
- KarmaVLM: A family of high efficiency and powerful visual language model.github, 2024 [Github]
- moondream: tiny vision language model.github, 2024 [Github]
- Broadening the visual encoding of vision-language models, arXiv, 2024 [Paper]
- Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference, arXiv, 2024 [Paper]
- SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models, arXiv, 2024 [Paper]
- ViTamin: Designing Scalable Vision Models in the Vision-Language Era. arXiv, 2024 [Paper]
- Visual Instruction Tuning. arXiv, 2023 [Paper]
- Improved baselines with visual instruction tuning. arXiv, 2023 [Paper]
- Flamingo: a Visual Language Model for Few-Shot Learning, arXiv, 2022 [Paper]
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, arXiv, 2023 [Paper]
- Broadening the visual encoding of vision-language models, arXiv, 2024 [Paper]
- MobileVLM V2: Faster and Stronger Baseline for Vision Language Model, arXiv, 2023 [Paper]
- Mobilevlm: A fast, reproducible and strong vision language assistant for mobile devices. arXiv, 2023 [Paper]
- Vl-mamba: Exploring state space models for multimodal learning.arXiv, 2024 [Paper]
- Honeybee: Locality-enhanced projector for multimodal llm.arXiv, 2023 [Paper]
- Llama: Open and efficient foundation language models. arXiv, 2023 [Paper]
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.website, 2023 [[web](https://vicuna. lmsys. org)]
- Phi-2: The surprising power of small language models. blog 2023 [[blog](Microsoft Research Blog)]
- Gemma: Open models based on gemini research and technology. arXiv, 2024 [Paper]
- Phi-3 technical report: A highly capable language model locally on your phone. 2024
- Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. arXiv, 2024 [Paper]
- A pioneering large vision- language model handling resolutions from 336 pixels to 4k hd. arXiv, 2024 [Paper]
- Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. arXiv, 2024 [Paper]
- Texthawk: Exploring efficient fine-grained perception of multimodal large language models. arXiv, 2024 [Paper]
- Tiny- chart: Efficient chart understanding with visual token merging and program-of-thoughts learning.
- Llava-prumerge: Adaptive token reduction for efficient large multimodal models. arXiv, 2024 [Paper]
- Madtp: Multi- modal alignment-guided dynamic token pruning for accelerating vision-language transformer. arXiv, 2024 [Paper]
- CROSSGET: CROSS-GUIDED ENSEMBLE OF TOKENS FOR ACCELERATING VISION-LANGUAGE TRANSFORMERS. ICML, 2024 [Paper]
- Matryoshka Query Transformer for Large Vision-Language Models. arxiv, 2024 [Paper]
- Mini-gemini: Mining the potential of multi-modality vision language models. arXiv, 2024 [Paper]
- When do we not need larger vision models? arXiv, 2024 [Paper] arXiv, 2023 [Paper]
- Plug-and-play grounding of reasoning in multimodal large language models. arXiv, 2024 [Paper]
- Mova: Adapting mixture of vision experts to multimodal context. arXiv, 2024 [Paper]
- Elysium: Exploring object-level perception in videos via mllm. arXiv, 2024 [Paper]
- Extending video-language pretraining to n-modality by language-based semantic alignment. arXiv, 2023 [Paper]
- Video-llava: Learning united visual representation by alignment before projection. arXiv, 2023 [Paper]
- Moe-llava: Mixture of experts for large vision-language models. arXiv, 2024 [Paper]
- Mm1: Methods, analysis & insights from multimodal llm pre-training. arXiv, 2024 [Paper]
- Mixtral of experts. arXiv, 2024 [Paper]
- Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference, arXiv, 2024 [Paper]
- Mamba: Linear-time sequence modeling with selective state spaces. arXiv, 2023 [Paper]
- Vl-mamba: Exploring state space models for multimodal learning. arXiv, 2024 [Paper]
- On speculative decoding for multimodal large language models. arXiv, 2024 [Paper]
- An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. arXiv, 2024 [Paper]
- Boosting multimodal large language models with visual tokens withdrawal for rapid inference. arXiv, 2024 [Paper]
- Tinyllava: A framework of small-scale large multimodal models. arXiv, 2024 [Paper]
- Vila: On pre-training for visual language models. arXiv, 2023 [Paper]
- Sharegpt4v: Improving large multi-modal models with better captions. arXiv, 2023 [Paper]
- What matters when building vision- language models? arXiv, 2024 [Paper]
- Cheap and quick: Efficient vision-language instruction tuning for large language models. nips, 2023 [Paper]
- Hyperllava: Dynamic visual and language expert tuning for multimodal large language models. arXiv, 2024 [Paper]
- SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models.arXiv, 2024 [Paper]
- Cobra:Extending mamba to multi-modal large language model for efficient inference. arXiv, 2024 [Paper]
- Tinygpt-v: Efficient multimodal large language model via small backbones.arXiv, 2023 [Paper]
- Not All Attention is Needed: Parameter and Computation Efficient Transfer Learning for Multi-modal Large Language Models. arXiv, 2024 [Paper]
- Memory-space visual prompting for efficient vision-language fine-tuning. arXiv, 2024 [Paper]
- Training small multimodal models to bridge biomedical competency gap: A case study in radiology imaging. arXiv, 2024 [[Paper]]
- Moe-tinymed: Mixture of experts for tiny medical large vision-language models. arXiv, 2024 [Paper]
- Texthawk: Exploring efficient fine-grained perception of multimodal large language models. arXiv, 2024 [Paper]
- Tiny- chart: Efficient chart understanding with visual token merging and program-of-thoughts learning. arXiv, 2024 [Paper]
- Monkey: Image resolution and text label are important things for large multi-modal models. arXiv, 2024 [Paper]
- Hrvda: High-resolution visual document assistant. arXiv, 2023 [Paper]
- mplug-2: A modular- ized multi-modal foundation model across text, image and video. arXiv, 2023 [Paper]
- Video-llava: Learning united visual representation by alignment before projection. arXiv, 2023 [Paper]
- Ma-lmm: Memory-augmented large multimodal model for long-term video under- standing. arXiv, 2024 [Paper]
- Llama-vid: An image is worth 2 tokens in large language models. arXiv, 2023 [Paper]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Efficient-Multimodal-LLMs-Survey
Similar Open Source Tools
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and their applications, while also discussing current limitations and future directions.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.

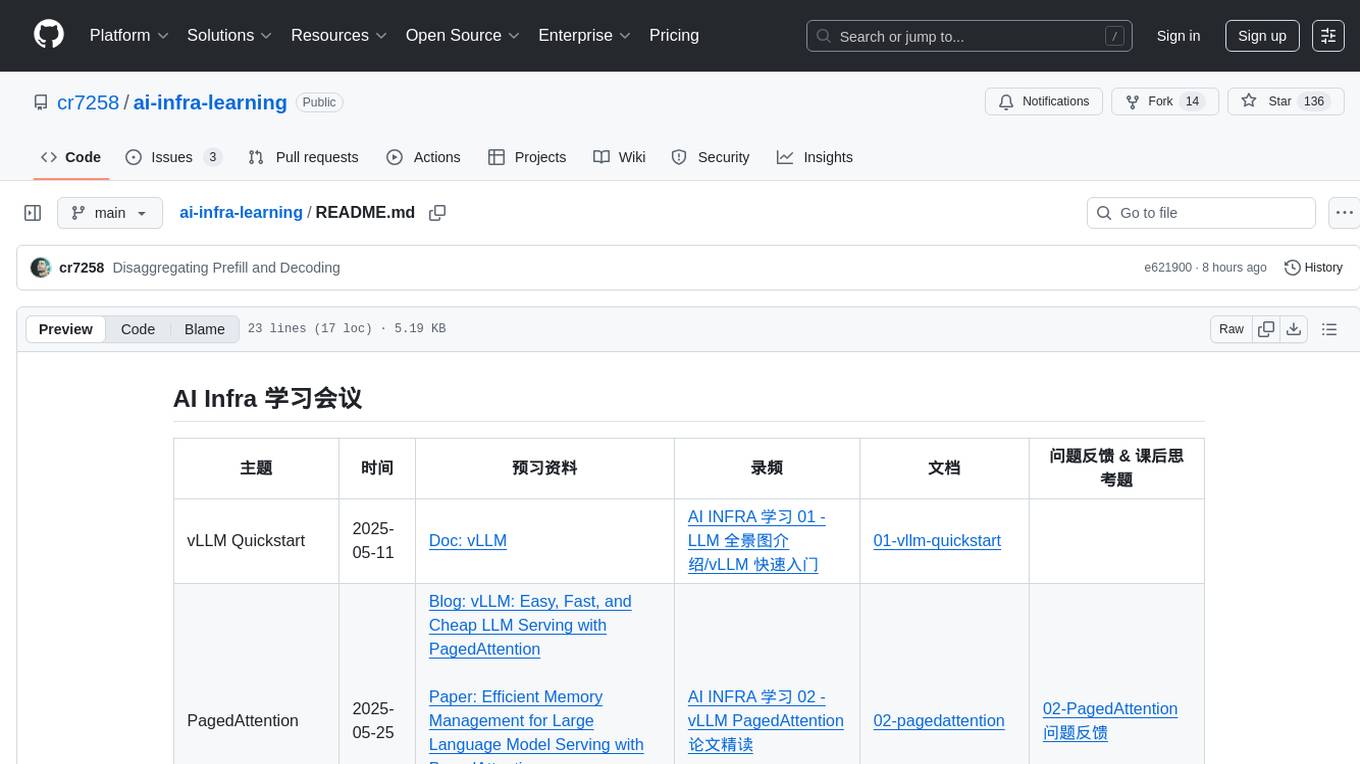
ai-infra-learning
AI Infra Learning is a repository focused on providing resources and materials for learning about various topics related to artificial intelligence infrastructure. The repository includes documentation, papers, videos, and blog posts covering different aspects of AI infrastructure, such as large language models, memory management, decoding techniques, and text generation. Users can access a wide range of materials to deepen their understanding of AI infrastructure and improve their skills in this field.
Awesome-GUI-Agents
Awesome-GUI-Agents is a curated list for GUI Agents, focusing on updates, contributing guidelines, modules of GUI Agents, paper lists, datasets, and benchmarks. It provides a comprehensive overview of research papers, models, and projects related to GUI automation, reinforcement learning, and grounding. The repository covers a wide range of topics such as perception, exploration, planning, interaction, memory, online reinforcement learning, GUI navigation benchmarks, and more.
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.
Awesome-Code-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, in lowercase letters: 'description' (detailed description of the repo, must be less than 400 words,Ensure that no line breaks and quotation marks.),'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,user may use those keyword to find the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in lowercase letters), 'answer' (in english languages)
Awesome-LWMs
Awesome Large Weather Models (LWMs) is a curated collection of articles and resources related to large weather models used in AI for Earth and AI for Science. It includes information on various cutting-edge weather forecasting models, benchmark datasets, and research papers. The repository serves as a hub for researchers and enthusiasts to explore the latest advancements in weather modeling and forecasting.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.
info8006-introduction-to-ai
INFO8006 Introduction to Artificial Intelligence is a course at ULiège that covers various topics in AI such as intelligent agents, problem-solving, games, probabilistic reasoning, machine learning, neural networks, reinforcement learning, and decision-making. The course includes lectures, exercises, and programming projects using Python. Students can access course materials, previous exams, and archived lectures to enhance their understanding of AI concepts.

MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
For similar tasks
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
uvadlc_notebooks
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.
farel-bench
The 'farel-bench' project is a benchmark tool for testing LLM reasoning abilities with family relationship quizzes. It generates quizzes based on family relationships of varying degrees and measures the accuracy of large language models in solving these quizzes. The project provides scripts for generating quizzes, running models locally or via APIs, and calculating benchmark metrics. The quizzes are designed to test logical reasoning skills using family relationship concepts, with the goal of evaluating the performance of language models in this specific domain.
LLMcalc
LLM Calculator is a script that estimates the memory requirements and performance of Hugging Face models based on quantization levels. It fetches model parameters, calculates required memory, and analyzes performance with different RAM/VRAM configurations. The tool supports Windows and Linux, AMD, Intel, and Nvidia GPUs. Users can input a Hugging Face model ID to get its parameter count and analyze memory requirements for various quantization schemes. The tool provides estimates for GPU offload percentage and throughput in tk/s. It requires dependencies like python, uv, pciutils for AMD + Linux, and drivers for Nvidia. The tool is designed for rough estimates and may not work with MultiGPU setups.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.