
uvadlc_notebooks
Repository of Jupyter notebook tutorials for teaching the Deep Learning Course at the University of Amsterdam (MSc AI), Fall 2023
Stars: 2506
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.
README:
Note: To look at the notebooks in a nicer format, visit our RTD website: https://uvadlc-notebooks.readthedocs.io/en/latest/
Course website: https://uvadlc.github.io/
Course edition: Fall 2023 (Nov. 01 - Dec. 24) - Being kept up to date
Recordings: YouTube Playlist
Author: Phillip Lippe
For this year's course edition, we created a series of Jupyter notebooks that are designed to help you understanding the "theory" from the lectures by seeing corresponding implementations. We will visit various topics such as optimization techniques, transformers, graph neural networks, and more (for a full list, see below). The notebooks are there to help you understand the material and teach you details of the PyTorch framework, including PyTorch Lightning. Further, we provide one-to-one translations of the notebooks to JAX+Flax as alternative framework.
The notebooks are presented in the first hour of every group tutorial session. During the tutorial sessions, we will present the content and explain the implementation of the notebooks. You can decide yourself whether you just want to look at the filled notebook, want to try it yourself, or code along during the practical session. The notebooks are not directly part of any mandatory assignments on which you would be graded or similarly. However, we encourage you to get familiar with the notebooks and experiment or extend them yourself. Further, the content presented will be relevant for the graded assignment and exam.
The tutorials have been integrated as official tutorials of PyTorch Lightning. Thus, you can also view them in their documentation.
On this website, you will find the notebooks exported into a HTML format so that you can read them from whatever device you prefer. However, we suggest that you also give them a try and run them yourself. There are three main ways of running the notebooks we recommend:
-
Locally on CPU: All notebooks are stored on the github repository that also builds this website. You can find them here: https://github.com/phlippe/uvadlc_notebooks/tree/master/docs/tutorial_notebooks. The notebooks are designed so that you can execute them on common laptops without the necessity of a GPU. We provide pretrained models that are automatically downloaded when running the notebooks, or can manually be downloaded from this Google Drive. The required disk space for the pretrained models and datasets is less than 1GB. To ensure that you have all the right python packages installed, we provide a conda environment in the same repository (choose the CPU or GPU version depending on your system).
-
Google Colab: If you prefer to run the notebooks on a different platform than your own computer, or want to experiment with GPU support, we recommend using Google Colab. Each notebook on this documentation website has a badge with a link to open it on Google Colab. Remember to enable GPU support before running the notebook (
Runtime -> Change runtime type). Each notebook can be executed independently, and doesn't require you to connect your Google Drive or similar. However, when closing the session, changes might be lost if you don't save it to your local computer or have copied the notebook to your Google Drive beforehand. -
Snellius cluster: If you want to train your own (larger) neural networks based on the notebooks, you can make use of the Snellius cluster. However, this is only suggested if you really want to train a new model, and use the other two options to go through the discussion and analysis of the models. Snellius might not allow you with your student account to run Jupyter notebooks directly on the gpu_shared partition. Instead, you can first convert the notebooks to a script using
jupyter nbconvert --to script ...ipynb, and then start a job on Snellius for running the script. A few advices when running on Snellius:- Disable the tqdm statements in the notebook. Otherwise your slurm output file might overflow and be several MB large. In PyTorch Lightning, you can do this by setting
progress_bar_refresh_rate=0in the trainer. - Comment out the matplotlib plotting statements, or change :code:
plt.show()toplt.savefig(...).
- Disable the tqdm statements in the notebook. Otherwise your slurm output file might overflow and be several MB large. In PyTorch Lightning, you can do this by setting
We will discuss 7 of the tutorials in the course, spread across lectures to cover something from every area. You can align the tutorials with the lectures based on their topics. The list of tutorials is:
- Guide 1: Working with the Snellius cluster
- Tutorial 2: Introduction to PyTorch
- Tutorial 3: Activation functions
- Tutorial 4: Optimization and Initialization
- Tutorial 5: Inception, ResNet and DenseNet
- Tutorial 6: Transformers and Multi-Head Attention
- Tutorial 7: Graph Neural Networks
- Tutorial 8: Deep Energy Models
- Tutorial 9: Autoencoders
- Tutorial 10: Adversarial attacks
- Tutorial 11: Normalizing Flows on image modeling
- Tutorial 12: Autoregressive Image Modeling
- Tutorial 15: Vision Transformers
- Tutorial 16: Meta Learning - Learning to Learn
- Tutorial 17: Self-Supervised Contrastive Learning with SimCLR
This is the first time we present these tutorials during the Deep Learning course. As with any other project, small bugs and issues are expected. We appreciate any feedback from students, whether it is about a spelling mistake, implementation bug, or suggestions for improvements/additions to the notebooks. Please use the following link to submit feedback, or feel free to reach out to me directly per mail (p dot lippe at uva dot nl), or grab me during any TA session.
If you find the tutorials helpful and would like to cite them, you can use the following bibtex:
@misc{lippe2024uvadlc,
title = {{UvA Deep Learning Tutorials}},
author = {Phillip Lippe},
year = 2024,
howpublished = {\url{https://uvadlc-notebooks.readthedocs.io/en/latest/}}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for uvadlc_notebooks
Similar Open Source Tools
uvadlc_notebooks
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.
MediaAI
MediaAI is a repository containing lectures and materials for Aalto University's AI for Media, Art & Design course. The course is a hands-on, project-based crash course focusing on deep learning and AI techniques for artists and designers. It covers common AI algorithms & tools, their applications in art, media, and design, and provides hands-on practice in designing, implementing, and using these tools. The course includes lectures, exercises, and a final project based on students' interests. Students can complete the course without programming by creatively utilizing existing tools like ChatGPT and DALL-E. The course emphasizes collaboration, peer-to-peer tutoring, and project-based learning. It covers topics such as text generation, image generation, optimization, and game AI.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
aicodeguide
AI Code Guide is a comprehensive guide that covers everything you need to know about using AI to help you code or even code for you. It provides insights into the changing landscape of coding with AI, new tools, editors, and practices. The guide aims to consolidate information on AI coding and AI-assisted code generation in one accessible place. It caters to both experienced coders looking to leverage AI tools and beginners interested in 'vibe coding' to build software products. The guide covers various topics such as AI coding practices, different ways to use AI in coding, recommended resources, tools for AI coding, best practices for structuring prompts, and tips for using specific tools like Claude Code.
obsidian-Smart2Brain
Your Smart Second Brain is a free and open-source Obsidian plugin that serves as your personal assistant, powered by large language models like ChatGPT or Llama2. It can directly access and process your notes, eliminating the need for manual prompt editing, and it can operate completely offline, ensuring your data remains private and secure.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.
nlp-zero-to-hero
This repository provides a comprehensive guide to Natural Language Processing (NLP), covering topics from Tokenization to Transformer Architecture. It aims to equip users with a solid understanding of NLP concepts, evolution, and core intuition. The repository includes practical examples and hands-on experience to facilitate learning and exploration in the field of NLP.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
ClipboardConqueror
Clipboard Conqueror is a multi-platform omnipresent copilot alternative. Currently requiring a kobold united or openAI compatible back end, this software brings powerful LLM based tools to any text field, the universal copilot you deserve. It simply works anywhere. No need to sign in, no required key. Provided you are using local AI, CC is a data secure alternative integration provided you trust whatever backend you use. *Special thank you to the creators of KoboldAi, KoboldCPP, llamma, openAi, and the communities that made all this possible to figure out.
llm_engineering
LLM Engineering is an 8-week course designed to help learners master AI and LLMs through a series of projects that gradually increase in complexity. The course covers setting up the environment, working with APIs, using Google Colab for GPU processing, and building an autonomous Agentic AI solution. Learners are encouraged to actively participate, run code cells, tweak code, and share their progress with the community. The emphasis is on practical, educational projects that teach valuable business skills.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.
start-llms
This repository is a comprehensive guide for individuals looking to start and improve their skills in Large Language Models (LLMs) without an advanced background in the field. It provides free resources, online courses, books, articles, and practical tips to become an expert in machine learning. The guide covers topics such as terminology, transformers, prompting, retrieval augmented generation (RAG), and more. It also includes recommendations for podcasts, YouTube videos, and communities to stay updated with the latest news in AI and LLMs.
trackmania_rl_public
This repository contains the reinforcement learning training code for Trackmania AI with Reinforcement Learning. It is a research work-in-progress project that aims to apply reinforcement learning principles to play Trackmania. The code is constantly evolving and may not be clean or easily usable. The training hyperparameters are intentionally changed in the public repository to encourage understanding of reinforcement learning principles. The project may not receive active support for setup or usage at the moment.
Smart-Connections-Visualizer
The Smart Connections Visualizer Plugin is a tool designed to enhance note-taking and information visualization by creating dynamic force-directed graphs that represent connections between notes or excerpts. Users can customize visualization settings, preview notes, and interact with the graph to explore relationships and insights within their notes. The plugin aims to revolutionize communication with AI and improve decision-making processes by visualizing complex information in a more intuitive and context-driven manner.
For similar tasks
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
uvadlc_notebooks
The UvA Deep Learning Tutorials repository contains a series of Jupyter notebooks designed to help understand theoretical concepts from lectures by providing corresponding implementations. The notebooks cover topics such as optimization techniques, transformers, graph neural networks, and more. They aim to teach details of the PyTorch framework, including PyTorch Lightning, with alternative translations to JAX+Flax. The tutorials are integrated as official tutorials of PyTorch Lightning and are relevant for graded assignments and exams.

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.
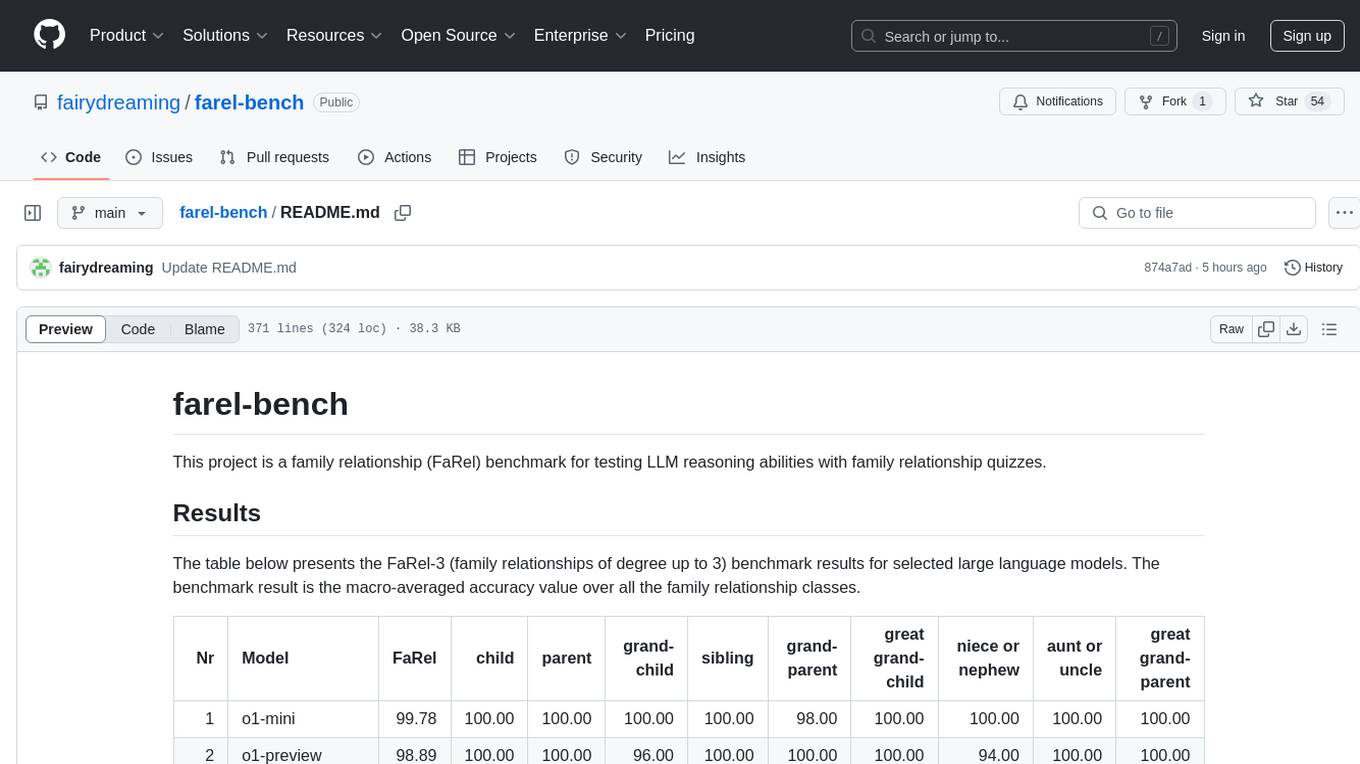
farel-bench
The 'farel-bench' project is a benchmark tool for testing LLM reasoning abilities with family relationship quizzes. It generates quizzes based on family relationships of varying degrees and measures the accuracy of large language models in solving these quizzes. The project provides scripts for generating quizzes, running models locally or via APIs, and calculating benchmark metrics. The quizzes are designed to test logical reasoning skills using family relationship concepts, with the goal of evaluating the performance of language models in this specific domain.
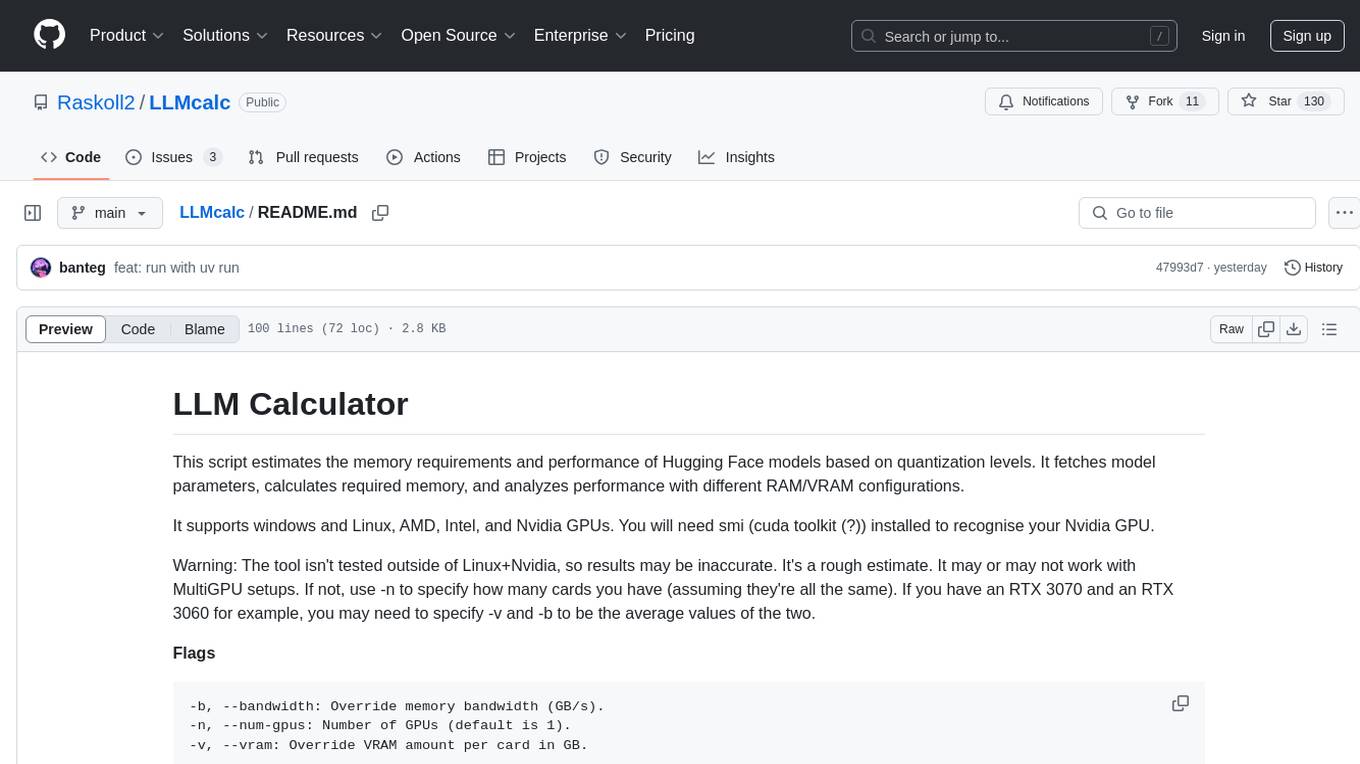
LLMcalc
LLM Calculator is a script that estimates the memory requirements and performance of Hugging Face models based on quantization levels. It fetches model parameters, calculates required memory, and analyzes performance with different RAM/VRAM configurations. The tool supports Windows and Linux, AMD, Intel, and Nvidia GPUs. Users can input a Hugging Face model ID to get its parameter count and analyze memory requirements for various quantization schemes. The tool provides estimates for GPU offload percentage and throughput in tk/s. It requires dependencies like python, uv, pciutils for AMD + Linux, and drivers for Nvidia. The tool is designed for rough estimates and may not work with MultiGPU setups.
aws-genai-llm-chatbot
This repository provides code to deploy a chatbot powered by Multi-Model and Multi-RAG using AWS CDK on AWS. Users can experiment with various Large Language Models and Multimodal Language Models from different providers. The solution supports Amazon Bedrock, Amazon SageMaker self-hosted models, and third-party providers via API. It also offers additional resources like AWS Generative AI CDK Constructs and Project Lakechain for building generative AI solutions and document processing. The roadmap and authors are listed, along with contributors. The library is licensed under the MIT-0 License with information on changelog, code of conduct, and contributing guidelines. A legal disclaimer advises users to conduct their own assessment before using the content for production purposes.
gemini-pro-vision-playground
Gemini Pro Vision Playground is a simple project aimed at assisting developers in utilizing the Gemini Pro Vision and Gemini Pro AI models for building applications. It provides a playground environment for experimenting with these models and integrating them into apps. The project includes instructions for setting up the Google AI API key and running the development server to visualize the results. Developers can learn more about the Gemini API documentation and Next.js framework through the provided resources. The project encourages contributions and feedback from the community.

simpleAI
SimpleAI is a self-hosted alternative to the not-so-open AI API, focused on replicating main endpoints for LLM such as text completion, chat, edits, and embeddings. It allows quick experimentation with different models, creating benchmarks, and handling specific use cases without relying on external services. Users can integrate and declare models through gRPC, query endpoints using Swagger UI or API, and resolve common issues like CORS with FastAPI middleware. The project is open for contributions and welcomes PRs, issues, documentation, and more.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.