
dive-into-llms
《动手学大模型Dive into LLMs》系列编程实践教程
Stars: 568
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.
README:



《动手学大模型》系列编程实践教程,由上海交通大学《人工智能安全技术》课程讲义拓展而来(教师:张倬胜),旨在提供大模型相关的入门编程参考。通过简单实践,帮助同学快速入门大模型,更好地开展课程设计或学术研究。
Gitbook阅读体验更佳。
| 教程内容 | 简介 | 地址 |
|---|---|---|
| 微调与部署 | 预训练模型微调与部署指南:想提升预训练模型在指定任务上的性能?让我们选择合适的预训练模型,在特定任务上进行微调,并将微调后的模型部署成方便使用的Demo! | [Slides] [Tutorial] |
| 提示学习与思维链 | 大模型的API调用与推理指南:“AI在线求鼓励?大模型对一些问题的回答令人大跌眼镜,但它可能只是想要一句「鼓励」” | [Slides] [Tutorial] |
| 知识编辑 | 语言模型的编辑方法和工具:想操控语言模型在对指定知识的记忆?让我们选择合适的编辑方法,对特定知识进行编辑,并将对编辑后的模型进行验证! | [Slides] [Tutorial] |
| 模型水印 | 语言模型的文本水印:在语言模型生成的内容中嵌入人类不可见的水印 | [Slides] [Tutorial] |
| 越狱攻击 | 想要得到更好的安全,要先从学会攻击开始。让我们了解越狱攻击如何撬开大模型的嘴! | [Slides] [Tutorial] |
| 多模态模型 | 作为能够更充分模拟真实世界的多模态大语言模型,其如何实现更强大的多模态理解和生成能力?多模态大语言模型是否能够帮助实现AGI? | [Slides] [Tutorial] |
| 大模型智能体与安全 | 大模型智能体迈向了未来操作系统之旅。然而,大模型在开放智能体场景中能意识到风险威胁吗? | [Slides] [Tutorial] |
本教程所有内容仅仅来自于贡献者的个人经验、互联网数据、日常科研工作中的相关积累。所有技巧仅供参考,不保证百分百正确。若有任何问题,欢迎提交 Issue 或 PR。另本项目所用徽章来自互联网,如侵犯了您的图片版权请联系我们删除,谢谢。
本教程目前是一个正在进行中的项目,如有疏漏在所难免,欢迎任何的PR及issue讨论。
感谢以下同学对本项目的支持与贡献:
上海交通大学 袁童鑫
上海交通大学 马欣贝
上海交通大学 何志威
上海交通大学 杜巍
新加坡国立大学 费豪
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dive-into-llms
Similar Open Source Tools
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
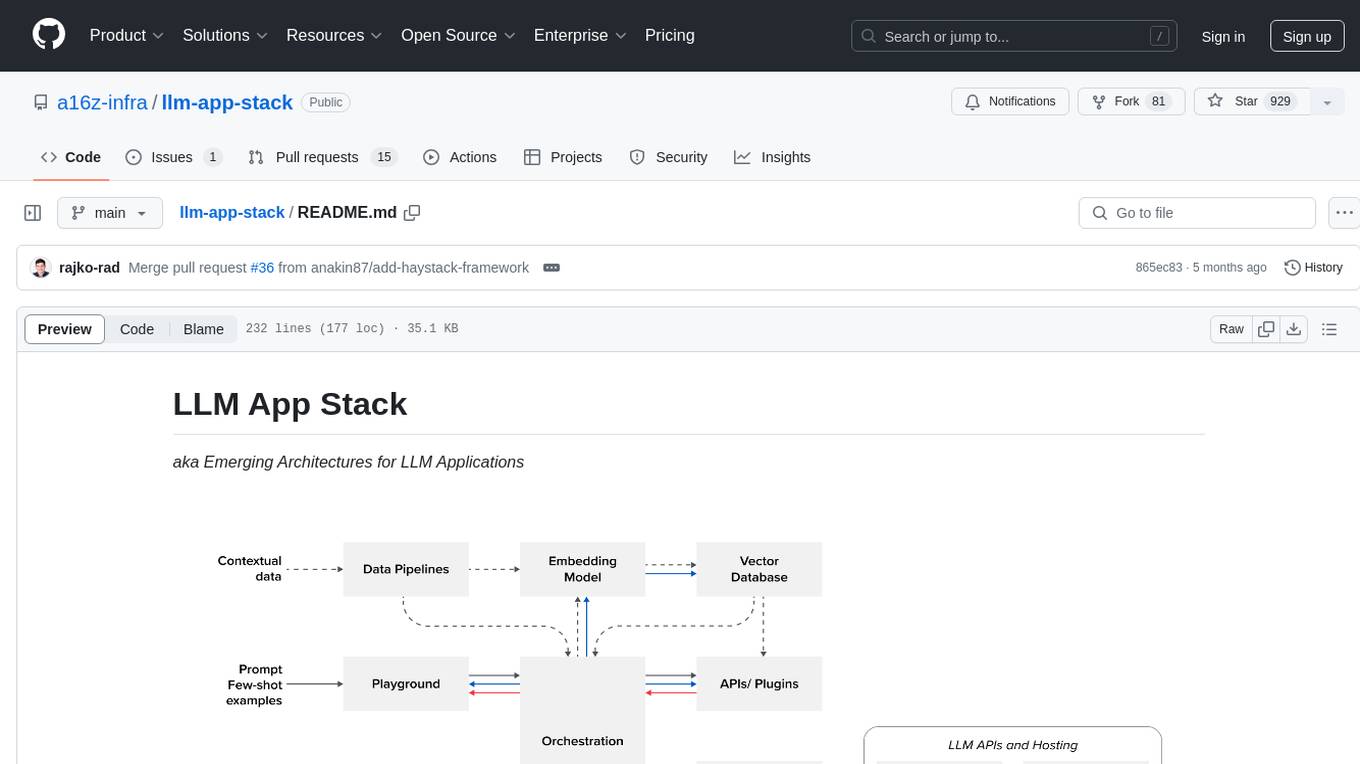
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.

InternLM
InternLM is a powerful language model series with features such as 200K context window for long-context tasks, outstanding comprehensive performance in reasoning, math, code, chat experience, instruction following, and creative writing, code interpreter & data analysis capabilities, and stronger tool utilization capabilities. It offers models in sizes of 7B and 20B, suitable for research and complex scenarios. The models are recommended for various applications and exhibit better performance than previous generations. InternLM models may match or surpass other open-source models like ChatGPT. The tool has been evaluated on various datasets and has shown superior performance in multiple tasks. It requires Python >= 3.8, PyTorch >= 1.12.0, and Transformers >= 4.34 for usage. InternLM can be used for tasks like chat, agent applications, fine-tuning, deployment, and long-context inference.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.

helicone
Helicone is an open-source observability platform designed for Language Learning Models (LLMs). It logs requests to OpenAI in a user-friendly UI, offers caching, rate limits, and retries, tracks costs and latencies, provides a playground for iterating on prompts and chat conversations, supports collaboration, and will soon have APIs for feedback and evaluation. The platform is deployed on Cloudflare and consists of services like Web (NextJs), Worker (Cloudflare Workers), Jawn (Express), Supabase, and ClickHouse. Users can interact with Helicone locally by setting up the required services and environment variables. The platform encourages contributions and provides resources for learning, documentation, and integrations.

CameraChessWeb
Camera Chess Web is a tool that allows you to use your phone camera to replace chess eBoards. With Camera Chess Web, you can broadcast your game to Lichess, play a game on Lichess, or digitize a chess game from a video or live stream. Camera Chess Web is free to download on Google Play.
Topu-ai
TOPU Md is a simple WhatsApp user bot created by Topu Tech. It offers various features such as multi-device support, AI photo enhancement, downloader commands, hidden NSFW commands, logo commands, anime commands, economy menu, various games, and audio/video editor commands. Users can fork the repo, get a session ID by pairing code, and deploy on Heroku. The bot requires Node version 18.x or higher for optimal performance. Contributions to TOPU-MD are welcome, and the tool is safe for use on WhatsApp and Heroku. The tool is licensed under the MIT License and is designed to enhance the WhatsApp experience with diverse features.
lobe-cli-toolbox
Lobe CLI Toolbox is an AI CLI Toolbox designed to enhance git commit and i18n workflow efficiency. It includes tools like Lobe Commit for generating Gitmoji-based commit messages and Lobe i18n for automating the i18n translation process. The toolbox also features Lobe label for automatically copying issues labels from a template repo. It supports features such as automatic splitting of large files, incremental updates, and customization options for the OpenAI model, API proxy, and temperature.
EverMemOS
EverMemOS is an AI memory system that enables AI to not only remember past events but also understand the meaning behind memories and use them to guide decisions. It achieves 93% reasoning accuracy on the LoCoMo benchmark by providing long-term memory capabilities for conversational AI agents through structured extraction, intelligent retrieval, and progressive profile building. The tool is production-ready with support for Milvus vector DB, Elasticsearch, MongoDB, and Redis, and offers easy integration via a simple REST API. Users can store and retrieve memories using Python code and benefit from features like multi-modal memory storage, smart retrieval mechanisms, and advanced techniques for memory management.
For similar tasks
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.