
IDvs.MoRec
End-to-end Training for Multimodal Recommendation Systems
Stars: 119

This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.
README:
Quick links: 📋Talk | 🗃️Dataset | 📭Citation | 🛠️Reproduce |
This repository contains the source code for the SIGIR 2023 paper ''Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited''.
Full version in [Arxiv] or [SIGIR2023].

Invited Talk by Google DeepMind (Slides)
🤗New Resources: 5 Large-scale datasets for evaluating foundation / transferable / multi-modal / LLM recommendaiton models.
-
PixelRec(SDM): https://github.com/westlake-repl/PixelRec
-
MicroLens: https://github.com/westlake-repl/MicroLens
-
NineRec(TPAMI): https://github.com/westlake-repl/NineRec
-
Tenrec(NeurIPS): https://github.com/yuangh-x/2022-NIPS-Tenrec
-
AntM2C(SIGIR): https://dl.acm.org/doi/abs/10.1145/3626772.3657865
- torch == 1.7.1+cu110
- torchvision==0.8.2+cu110
- transformers==4.20.1
The complete news recommendation dataset (MIND) is visible under the dataset/MIND, and the dataset with vision (HM and Bili) requires the following actions:
Download the image file "hm_images.zip" (100,000 images in 3x224x224 size) for HM dataset from this link.
Unzip the downloaded model file hm_images.zip, then put the unzipped directory hm_images into dataset/Hm/ for the further processing.
Bili Link: https://drive.google.com/file/d/1k0t3rA4LDVe3RoadoQwU9KPUeG5q8sw4/view?usp=sharing
You need to process the images file of HM dataset to a LMDB database for efficient loading during training.
cd dataset/HM
python run_lmdb_hm.py
We report details of the pre-trained ME we used in Table. Download the pytorch-version of them, and put the checkpoint pytorch_model.bin into the corresponding path under pretrained_models/
| Pre-trained model | #Param. | URL |
|---|---|---|
| BERTtiny | 4M | https://huggingface.co/prajjwal1/bert-tiny |
| BERTsmall | 29M | https://huggingface.co/prajjwal1/bert-small |
| BERTbase | 109M | https://huggingface.co/bert-base-uncased |
| RoBERTabase | 125M | https://huggingface.co/roberta-base |
| OPT125M | 125M | https://huggingface.co/facebook/opt-125M |
| ResNet18 | 12M | https://download.pytorch.org/models/resnet18-5c106cde.pth |
| ResNet34 | 22M | https://download.pytorch.org/models/resnet34-333f7ec4.pt |
| ResNet50 | 26M | https://download.pytorch.org/models/resnet50-19c8e357.pth |
| Swin-T | 28M | https://huggingface.co/microsoft/swin-tiny-patch4-window7-224 |
| Swin-B | 88M | https://huggingface.co/microsoft/swin-base-patch4-window7-224 |
| MAEbase | 86M | https://huggingface.co/facebook/vit-mae-base |
An example: For training text MoRec with SASRec in end2end manner, and using bert-base as the modality encoder:
cd bce_text/main-end2end
python train_bert_base.py
After training, you will get the checkpoint of the MoRec model, then set the parameters in test_bert_base.py and run it for the test result.
Mentions:
You can change the train_xxx.py and the test_xxx.py to set the hyperparameters.
The recommended GPU resource can be found in Table 6 in the paper.
We find that using in-batch debiased cross-entropy loss (Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations (RecSys 2019)) can significantly enhance the performance of IDRec and MoRec compared with the binary cross-entropy loss:
-\sum\limits_{u \in \mathcal{U}} \sum\limits_{ i \in [2,...,L]} \log \frac{\exp(\hat{y}_{ui} - \log(p_i))}{\exp(\hat{y}_{ui} - \log(p_i)) + \sum_{j \in [B], j \notin I_u} \exp(\hat{y}_{uj} - \log(p_j))}
where $p_i$ represents the popularity of item $i$ in the dataset. We conducted experiments on in-batch debiased cross-entropy loss using SASRec and report the results:
| Dataset | Metrics | IDRec | BERTsmall | RoBERTabase | Improv. |
|---|---|---|---|---|---|
| MIND | HR@10 | 22.60 | 22.96 | 23.00 | +1.77% |
| MIND | NDCG@10 | 12.57 | 12.82 | 12.82 | +1.99% |
| Dataset | Metrics | IDRec | ResNet50 | Swin-B | Improv. |
| HM | HR@10 | 11.94 | 11.90 | 12.26 | +2.68% |
| HM | NDCG@10 | 7.75 | 7.46 | 7.70 | -0.65% |
| Bili | HR@10 | 4.91 | 5.62 | 5.73 | +16.70% |
| Bili | NDCG@10 | 2.71 | 3.08 | 3.14 | +15.87% |
It can be seen from the results that both IDRec and MoRec have been greatly improved compared with the binary loss used in our paper. The experiments also showed that the convergence speed was significantly accelerated when using the in-batch debias loss. It is worth noting that under this training setting, the viewpoints in our paper are still confirmed.
We release the code of SASRec with the in-batch debias cross-entropy loss in inbatch_sasrec_e2e_text and inbatch_sasrec_e2e_vision, the way of running the codes is the same as described above.
If you use our code or find IDvs.MoRec useful in your work, please cite our paper as:
@inproceedings{yuan2023go,
title = {Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited},
author = {Yuan, Zheng and Yuan, Fajie and Song, Yu and Li, Youhua and Fu, Junchen and Yang, Fei and Pan, Yunzhu and Ni, Yongxin},
booktitle = {Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2639–2649},
year = {2023}
}If you have an innovative idea for building a foundational recommendation model but require a large dataset and computational resources, consider joining our lab as an intern. We can provide access to 100 NVIDIA 80G A100 GPUs and a billion-level dataset of user-video/image/text interactions.
The laboratory is hiring research assistants, interns, doctoral students, and postdoctoral researchers. Please contact the corresponding author for details.
实验室招聘科研助理,实习生,博士生和博士后,请联系通讯作者。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for IDvs.MoRec
Similar Open Source Tools
IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.

llm4ad
LLM4AD is an open-source Python-based platform leveraging Large Language Models (LLMs) for Automatic Algorithm Design (AD). It provides unified interfaces for methods, tasks, and LLMs, along with features like evaluation acceleration, secure evaluation, logs, GUI support, and more. The platform was originally developed for optimization tasks but is versatile enough to be used in other areas such as machine learning, science discovery, game theory, and engineering design. It offers various search methods and algorithm design tasks across different domains. LLM4AD supports remote LLM API, local HuggingFace LLM deployment, and custom LLM interfaces. The project is licensed under the MIT License and welcomes contributions, collaborations, and issue reports.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
Liger-Kernel
Liger Kernel is a collection of Triton kernels designed for LLM training, increasing training throughput by 20% and reducing memory usage by 60%. It includes Hugging Face Compatible modules like RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy. The tool works with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed, aiming to enhance model efficiency and performance for researchers, ML practitioners, and curious novices.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
nncf
Neural Network Compression Framework (NNCF) provides a suite of post-training and training-time algorithms for optimizing inference of neural networks in OpenVINO™ with a minimal accuracy drop. It is designed to work with models from PyTorch, TorchFX, TensorFlow, ONNX, and OpenVINO™. NNCF offers samples demonstrating compression algorithms for various use cases and models, with the ability to add different compression algorithms easily. It supports GPU-accelerated layers, distributed training, and seamless combination of pruning, sparsity, and quantization algorithms. NNCF allows exporting compressed models to ONNX or TensorFlow formats for use with OpenVINO™ toolkit, and supports Accuracy-Aware model training pipelines via Adaptive Compression Level Training and Early Exit Training.
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.
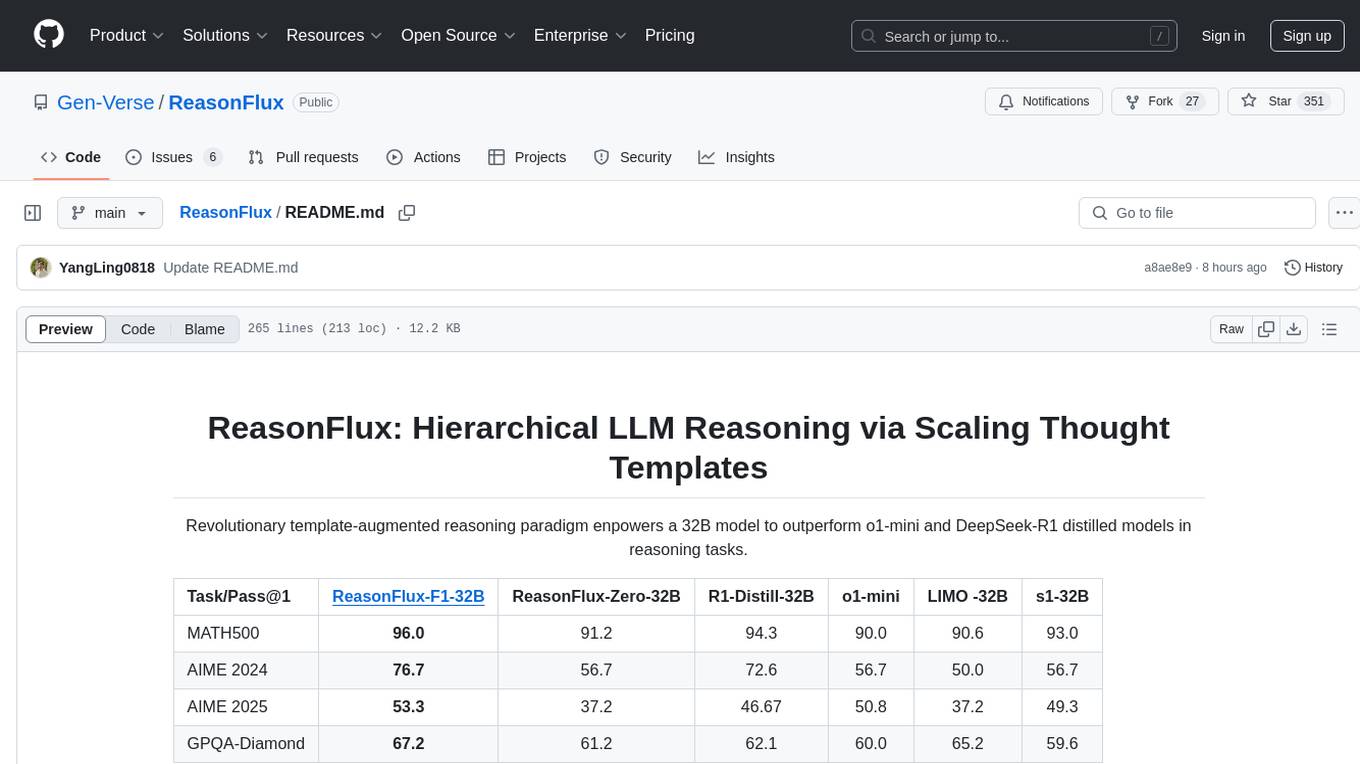
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
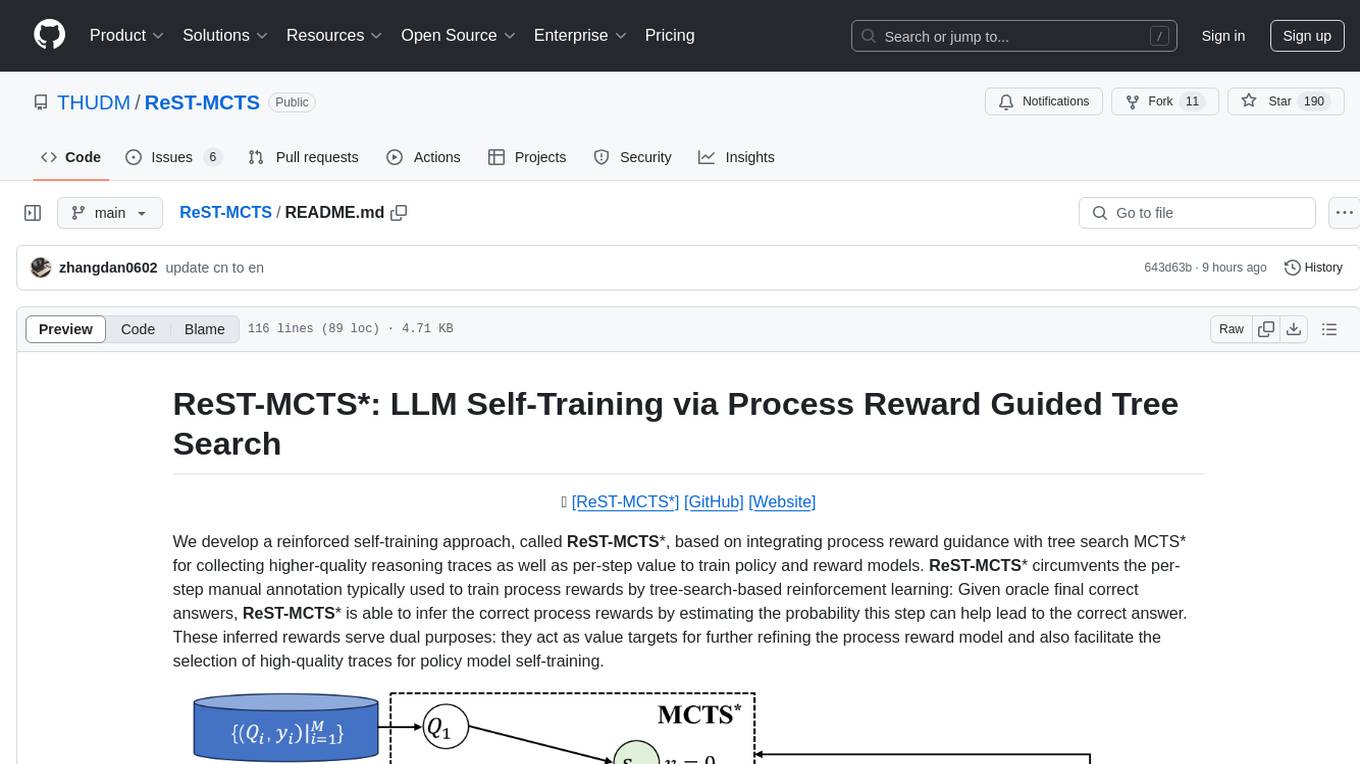
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.
For similar tasks
IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
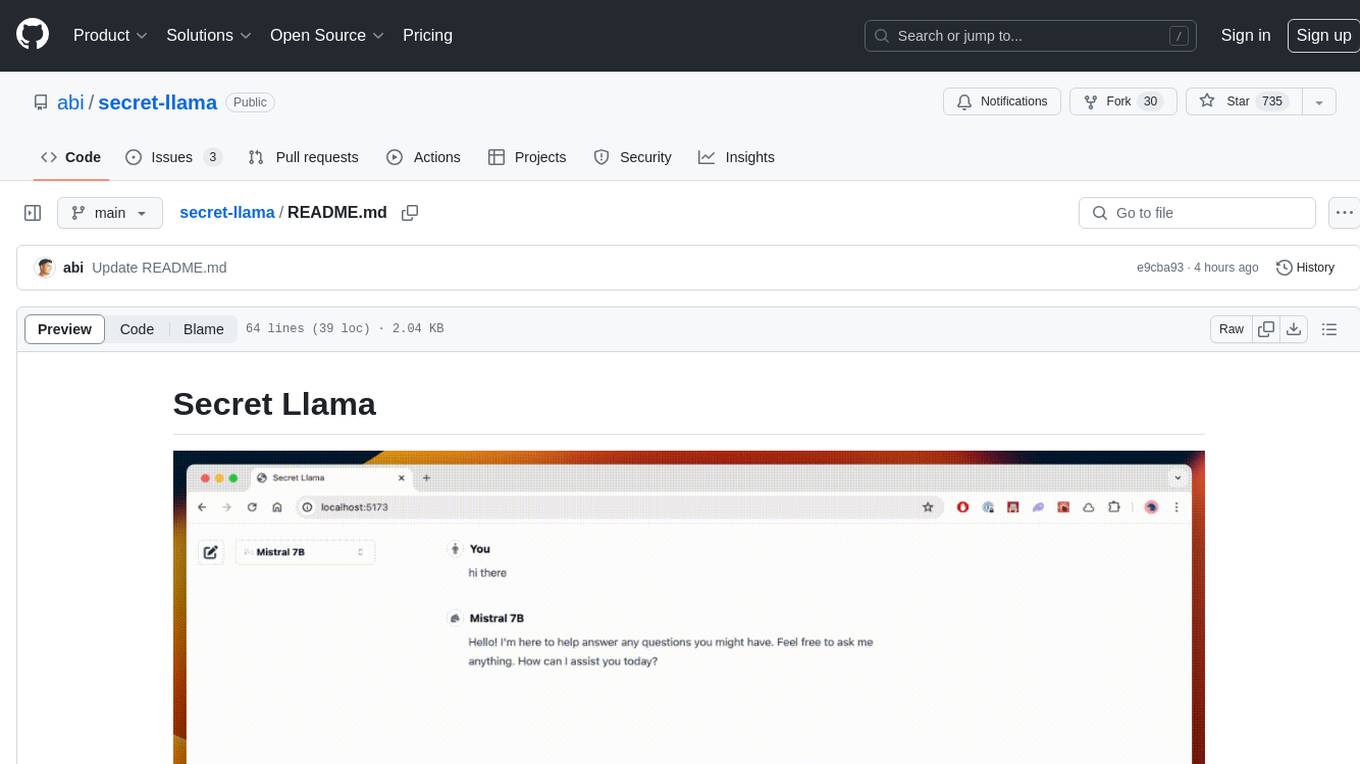
secret-llama
Entirely-in-browser, fully private LLM chatbot supporting Llama 3, Mistral and other open source models. Fully private = No conversation data ever leaves your computer. Runs in the browser = No server needed and no install needed! Works offline. Easy-to-use interface on par with ChatGPT, but for open source LLMs. System requirements include a modern browser with WebGPU support. Supported models include TinyLlama-1.1B-Chat-v0.4-q4f32_1-1k, Llama-3-8B-Instruct-q4f16_1, Phi1.5-q4f16_1-1k, and Mistral-7B-Instruct-v0.2-q4f16_1. Looking for contributors to improve the interface, support more models, speed up initial model loading time, and fix bugs.

baal
Baal is an active learning library that supports both industrial applications and research use cases. It provides a framework for Bayesian active learning methods such as Monte-Carlo Dropout, MCDropConnect, Deep ensembles, and Semi-supervised learning. Baal helps in labeling the most uncertain items in the dataset pool to improve model performance and reduce annotation effort. The library is actively maintained by a dedicated team and has been used in various research papers for production and experimentation.
LLM-Fine-Tuning
This GitHub repository contains examples of fine-tuning open source large language models. It showcases the process of fine-tuning and quantizing large language models using efficient techniques like Lora and QLora. The repository serves as a practical guide for individuals looking to optimize the performance of language models through fine-tuning.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.