
UniCoT
Uni-CoT: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Stars: 114

Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
README:
![]()
Luozheng Qin1*, Jia Gong1*, Yuqing Sun1*, Tianjiao Li3, Haoyu Pan1, Mengping Yang1, Xiaomeng Yang1, Chao Qu4, Zhiyu Tan1,2+#, Hao Li1,2#,
* equal contribution + project leader # Corresponding author
1Shanghai Academy of AI for Science, 2Fudan University, 3Nanyang Technological University, 4INFTech

To tackle this, we introduce Uni-CoT, a unified reasoning framework that extends CoT principles to the multimodal domain, empowering Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. The core idea is to decompose complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, enabling more scalable and systematic reasoning as shown above.
Note: We would like to thank the Bagel team for integrating strong text and image generation capabilities into a single model, which enables Uni-CoT to be implemented elegantly at current time.

-
Macro-Level CoT: Decomposes a complex task into simpler subtasks and synthesizes their outcomes to derive the final answer. We design three planning mechanism for different scenarios: Sequential Decomposition for causal, step-by-step planning; Parallel Decomposition for collaborative, multi-branch planning; Progressive Refinement for unknown or highly complex scenarios requiring iterative exploration.
-
Micro-Level CoT: Focuses on executing individual subtasks while filtering out irrelevant information. We incorporate a Self-Reflection mechanism to ensure stable and high-quality results in each subtask.
The Uni-CoT framework aims to solve complex multimodal tasks, including:
- 🎨 Reliable image generation and editing
- 🔍 Visual and physical reasoning
- 🧩 Visual planning
- 📖 Multimodal story understanding
- ✅ 2025.07.29 — We released UniCoT-7B-MoT v0.1 on Huggingface, which extends Bagel-7B-MoT model to perform text-to-image generation with self-reflection reasoning mechanism.
- ✅ 2025.08.08 — We released UniCoT v0.1 technical report on Arxiv and GitHub repository.
- 🔥 We are still working on this project to implement more kinds of Chain-of-Thought (CoT) mechanisms into a unified model. Please stay tuned!
A list of planned features and enhancements for the Uni-CoT framework:
✅ Release Micro-CoT Reasoning Machnism: self-reflection mechanism.
[ ] Release Macro-CoT Reasoning Machnism: sequential decomposition mechanism.
[ ] Release Macro-CoT Reasoning Machnism: parallel decomposition mechanism.
[ ] Release Macro-CoT Reasoning Machnism: progressive refinement mechanism.
[ ] Provide SFT (Supervised Fine-Tuning) framework for multimodal reasoning
[ ] Provide RL (Reinforcement Learning) framework for multimodal reasoning
✅ Evaluate Uni-CoT on a reasoning-based text-to-image generation benchmark WISE
✅ Evaluate Uni-CoT on reasoning-based image editing benchmarks: KRIS Bench and RISE Bench
[ ] Evaluate Uni-CoT on a reasoning-based understanding benchmark
The environment setup of Uni-CoT is consistent with its base model, Bagel.
git clone https://github.com/Fr0zenCrane/UniCoT.git
cd UniCoT
conda create -n unicot python=3.10 -y
conda activate unicot
pip install -r requirements.txt
pip install flash_attn==2.5.8 --no-build-isolation
You may directly download the huggingface checkpoint or use the following script:
from huggingface_hub import snapshot_download
save_dir = "models/UniCoT-7B-MoT"
repo_id = "Fr0zencr4nE/UniCoT-7B-MoT"
cache_dir = save_dir + "/cache"
snapshot_download(cache_dir=cache_dir,
local_dir=save_dir,
repo_id=repo_id,
local_dir_use_symlinks=False,
resume_download=True,
allow_patterns=["*.json", "*.safetensors", "*.bin", "*.py", "*.md", "*.txt"],
)To perform evaluation using UniCoT-7B-MoT, you need at least one GPU with 40GB or more VRAM. While lower GPU configurations are acceptable, they are not recommended due to potential performance limitations.
To reproduce our results on WISE benchmark, you can use script ./scripts/run_wise_self_reflection.sh, you may specify your local checkpoint of UniCoT-7B-MoT and output dir using --model_path and outdir.
gpu_num=8
for i in $(seq 0 $((gpu_num-1)));
do
CUDA_VISIBLE_DEVICES=$i python inference_mdp_self_reflection_wise.py \
--group_id $i \
--group_num $gpu_num \
--model_path "Fr0zencr4nE/UniCoT-7B-MoT" \
--data_path "./eval/gen/wise/final_data.json" \
--outdir "./results" \
--cfg_text_scale 4 > process_log_$i.log 2>&1 &
done
wait
echo "All background processes finished."For general inference, prepare your prompts by formatting them into a .txt file, with one prompt per line, with one prompt per line, you can find a demonstration of this in the repository as test_prompts.txt. Once your prompts are ready, use the script ./scripts/run_user_self_reflection.sh to generate images from your prompts with the added benefit of the self-reflection mechanism.
gpu_num=8
for i in $(seq 0 $((gpu_num-1)));
do
CUDA_VISIBLE_DEVICES=$i python inference_mdp_self_reflection.py \
--group_id $i \
--group_num $gpu_num \
--model_path "Fr0zencr4nE/UniCoT-7B-MoT" \
--data_path "./test_prompts.txt" \
--outdir "./results" \
--cfg_text_scale 4 > process_log_$i.log 2>&1 &
done
wait
echo "All background processes finished."


We first conduct experiments on the WISE dataset to evaluate the reasoning capabilities of our method. As shown in the table below, our model achieves state-of-the-art (SOTA) performance among existing open-source unified models. Our results are averaged over five independent runs to ensure robustness and reliability.
| Culture↑ | Time↑ | Space↑ | Biology↑ | Physics↑ | Chemistry↑ | Overall↑ | |
|---|---|---|---|---|---|---|---|
| Janus | 0.16 | 0.26 | 0.35 | 0.28 | 0.30 | 0.14 | 0.23 |
| MetaQuery | 0.56 | 0.55 | 0.62 | 0.49 | 0.63 | 0.41 | 0.55 |
| Bagel-Think | 0.76 | 0.69 | 0.75 | 0.65 | 0.75 | 0.58 | 0.70 |
| Uni-CoT | 0.76±0.009 | 0.70±0.0256 | 0.76±0.006 | 0.73±0.021 | 0.81±0.018 | 0.73±0.020 | 0.75±0.013 |
| GPT4O | 0.81 | 0.71 | 0.89 | 0.83 | 0.79 | 0.74 | 0.80 |
Furthermore, we apply our self-reflection mechanism to the images generated by the original Bagel model with think mode, aiming to evaluate our method’s ability to calibrate erroneous outputs. The results in the table below demonstrate that our model effectively refines the imperfect outputs generated by Bagel.
| Culture↑ | Time↑ | Space↑ | Biology↑ | Physics↑ | Chemistry↑ | Overall↑ | |
|---|---|---|---|---|---|---|---|
| Bagel-Think | 0.76 | 0.69 | 0.75 | 0.65 | 0.75 | 0.58 | 0.70 |
| Bagel-Think+Uni-CoT | 0.75 | 0.70 | 0.75 | 0.71 | 0.74 | 0.69 | 0.73 |
| Uni-CoT | 0.76±0.009 | 0.70±0.0256 | 0.76±0.006 | 0.73±0.021 | 0.81±0.018 | 0.73±0.020 | 0.75±0.013 |
| GPT4O | 0.81 | 0.71 | 0.89 | 0.83 | 0.79 | 0.74 | 0.80 |
Quantitative Results on KRIS Bench
We also achieve state-of-the-art (SOTA) performance on the KRIS benchmark, even surpassing the closed-source model Gemini2.0.
| Model | Attribute Perception | Spatial Perception | Temporal Perception | Factual Avg | Social Science | Natural Science | Conceptual Avg | Logical Reasoning | Instruction Decomposition | Procedural Avg | Overall Score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 2.0 (Google) | 66.33 | 63.33 | 63.92 | 65.26 | 68.19 | 56.94 | 59.65 | 54.13 | 71.67 | 62.90 | 62.41 |
| Step 3∅ vision (StepFun) | 69.67 | 61.08 | 63.25 | 66.70 | 66.88 | 60.88 | 62.32 | 49.06 | 54.92 | 51.99 | 61.43 |
| Doubao (ByteDance) | 70.92 | 59.17 | 40.58 | 63.30 | 65.50 | 61.19 | 62.23 | 47.75 | 60.58 | 54.17 | 60.70 |
| BAGEL (ByteDance) | 64.27 | 62.42 | 42.45 | 60.26 | 55.40 | 56.01 | 55.86 | 52.54 | 50.56 | 51.69 | 56.21 |
| BAGEL-Think (ByteDance) | 67.42 | 68.33 | 58.67 | 66.18 | 63.55 | 61.40 | 61.92 | 48.12 | 50.22 | 49.02 | 60.18 |
| Uni-Cot | 72.76 | 72.87 | 67.10 | 71.85 | 70.81 | 66.00 | 67.16 | 53.43 | 73.93 | 63.68 | 68.00 |
| GPT-4o (OpenAI) | 83.17 | 79.08 | 68.25 | 79.80 | 85.50 | 80.06 | 81.37 | 71.56 | 85.08 | 78.32 | 80.09 |
@misc{qin2025unicot,
title={Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision},
author={Luozheng Qin and Jia Gong and Yuqing Sun and Tianjiao Li and Mengping Yang and Xiaomeng Yang and Chao Qu and Zhiyu Tan and Hao Li},
year={2025},
eprint={2508.05606},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.05606},
}
- Bagel proposed by ByteDance-Seed team. Bagel is a powerful and popular unified model for multimodal understanding and generation, making it an ideal foundation and startup for this project. We thank the ByteDance-Seed team for their outstanding work, which has made Uni-CoT possible.
- WISE proposed by PKU-YuanGroup. WISE provides a comprehensive benchmark for evaluating text-to-image models on complex semantic understanding and world knowledge integration. By requiring advanced reasoning capabilities, WISE serves as a valuable playground for chain-of-thought (CoT) self-reflection.
- KRIS-Bench proposed by Stepfun. KRIS-Bench serves as a comprehensive benchmark for evaluating both instruction-based image editing and knowledge-guided reasoning capabilities for unified models.
- RISE-Bench proposed by Shanghai AI Lab. RISE-Bench serves as a comprehensive benchmark for reasoning-informed visual editing. RISEBench focuses on four key reasoning types: Temporal, Causal, Spatial, and Logical Reasoning.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for UniCoT
Similar Open Source Tools
UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.
LlamaV-o1
LlamaV-o1 is a Large Multimodal Model designed for spontaneous reasoning tasks. It outperforms various existing models on multimodal reasoning benchmarks. The project includes a Step-by-Step Visual Reasoning Benchmark, a novel evaluation metric, and a combined Multi-Step Curriculum Learning and Beam Search Approach. The model achieves superior performance in complex multi-step visual reasoning tasks in terms of accuracy and efficiency.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

llm4ad
LLM4AD is an open-source Python-based platform leveraging Large Language Models (LLMs) for Automatic Algorithm Design (AD). It provides unified interfaces for methods, tasks, and LLMs, along with features like evaluation acceleration, secure evaluation, logs, GUI support, and more. The platform was originally developed for optimization tasks but is versatile enough to be used in other areas such as machine learning, science discovery, game theory, and engineering design. It offers various search methods and algorithm design tasks across different domains. LLM4AD supports remote LLM API, local HuggingFace LLM deployment, and custom LLM interfaces. The project is licensed under the MIT License and welcomes contributions, collaborations, and issue reports.
eko
Eko is a lightweight and flexible command-line tool for managing environment variables in your projects. It allows you to easily set, get, and delete environment variables for different environments, making it simple to manage configurations across development, staging, and production environments. With Eko, you can streamline your workflow and ensure consistency in your application settings without the need for complex setup or configuration files.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.
unoplat-code-confluence
Unoplat-CodeConfluence is a universal code context engine that aims to extract, understand, and provide precise code context across repositories tied through domains. It combines deterministic code grammar with state-of-the-art LLM pipelines to achieve human-like understanding of codebases in minutes. The tool offers smart summarization, graph-based embedding, enhanced onboarding, graph-based intelligence, deep dependency insights, and seamless integration with existing development tools and workflows. It provides a precise context API for knowledge engine and AI coding assistants, enabling reliable code understanding through bottom-up code summarization, graph-based querying, and deep package and dependency analysis.
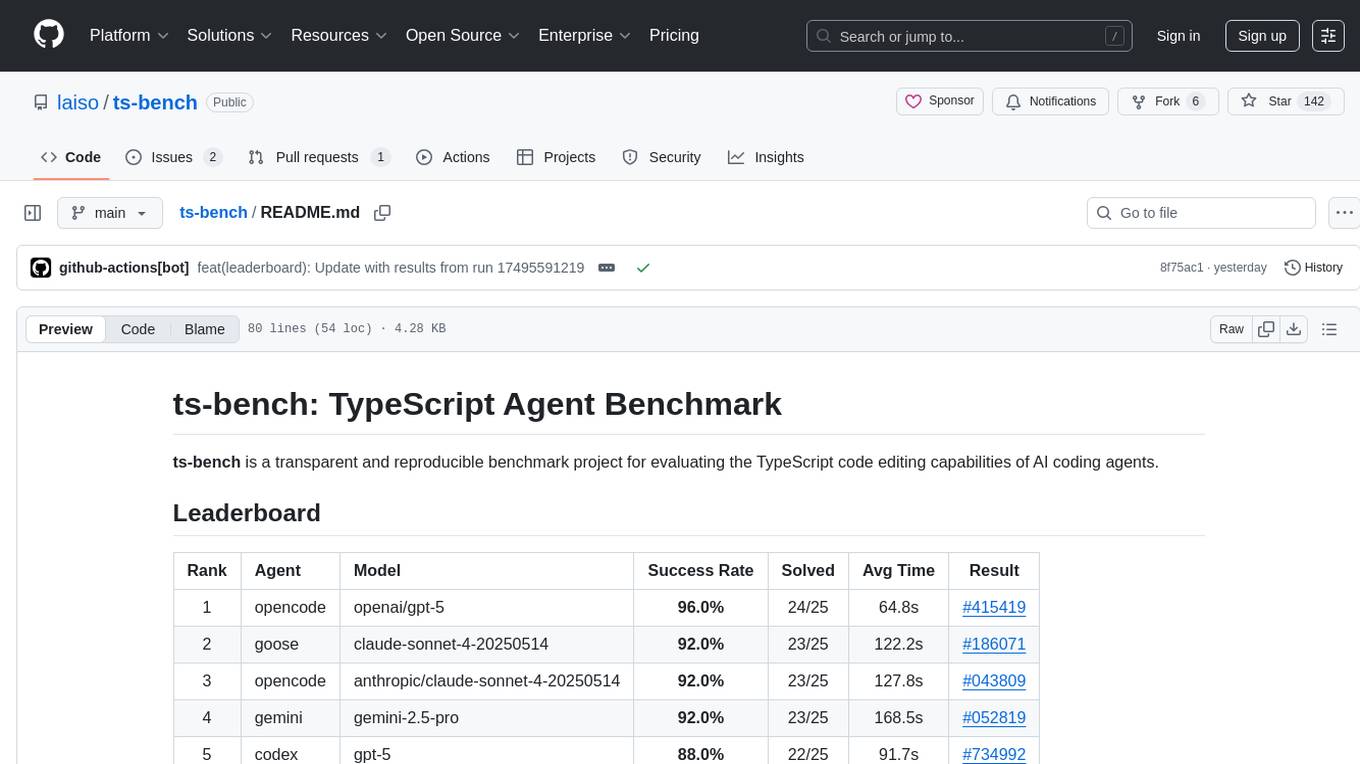
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.
For similar tasks

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.