
krita-ai-diffusion
Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required.
Stars: 8248
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
README:
✨Features | ⭳ Download | 🛠️Installation | 🎞️ Video | 🖼️Gallery | 📖User Guide | 💬Discussion | 🗣️Discord
This is a plugin to use generative AI in image painting and editing workflows from within Krita. Visit www.interstice.cloud for an introduction. Learn how to install and use it on docs.interstice.cloud.
The main goals of this project are:
- Precision and Control. Creating entire images from text can be unpredictable. To get the result you envision, you can restrict generation to selections, refine existing content with a variable degree of strength, focus text on image regions, and guide generation with reference images, sketches, line art, depth maps, and more.
- Workflow Integration. Most image generation tools focus heavily on AI parameters. This project aims to be an unobtrusive tool that integrates and synergizes with image editing workflows in Krita. Draw, paint, edit and generate seamlessly without worrying about resolution and technical details.
- Local, Open, Free. We are committed to open source models. Customize presets, bring your own models, and run everything local on your hardware. Cloud generation is also available to get started quickly without heavy investment.

- Inpainting: Use selections for generative fill, expand, to add or remove objects
- Live Painting: Let AI interpret your canvas in real time for immediate feedback. Watch Video
- Upscaling: Upscale and enrich images to 4k, 8k and beyond without running out of memory.
- Diffusion Models: Supports Stable Diffusion 1.5, and XL. Partial support for Flux and SD3.
- ControlNet: Scribble, Line art, Canny edge, Pose, Depth, Normals, Segmentation, +more
- IP-Adapter: Reference images, Style and composition transfer, Face swap
- Regions: Assign individual text descriptions to image areas defined by layers.
- Job Queue: Queue and cancel generation jobs while working on your image.
- History: Preview results and browse previous generations and prompts at any time.
- Strong Defaults: Versatile default style presets allow for a streamlined UI.
- Customization: Create your own presets - custom checkpoints, LoRA, samplers and more.
See the Plugin Installation Guide for instructions.
A concise (more technical) version is below:
- Windows, Linux, MacOS
-
On Linux/Mac: Python + venv must be installed
- recommended version: 3.12 or 3.11
- usually available via package manager, eg.
apt install python3-venv
To run locally a powerful graphics card with at least 6 GB VRAM (NVIDIA) is recommended. Otherwise generating images will take very long or may fail due to insufficient memory!
| NVIDIA GPU | supported via CUDA (Windows/Linux) |
| AMD GPU | DirectML (Windows, limited features, 12+ GB VRAM recommended) ROCm (Linux, via custom ComfyUI) |
| Apple Silicon | community support, MPS on macOS 14+ |
| CPU | supported, but very slow |
- If you haven't yet, go and install Krita! Required version: 5.2.0 or newer
- Download the plugin.
- Start Krita and install the plugin via Tools ▸ Scripts ▸ Import Python Plugin from File...
- Point it to the ZIP archive you downloaded in the previous step.
- ⚠ This will delete any previous install of the plugin. If you are updating from 1.14 or older please read updating to a new version.
- Check Krita's official documentation for more options.
- Restart Krita and create a new document or open an existing image.
- To show the plugin docker: Settings ‣ Dockers ‣ AI Image Generation.
- In the plugin docker, click "Configure" to start local server installation or connect.
[!NOTE] If you encounter problems please check the FAQ / list of common issues for solutions.
Reach out via discussions, our Discord, or report an issue here. Please note that official Krita channels are not the right place to seek help with issues related to this extension!
The plugin uses ComfyUI as backend. As an alternative to the automatic installation, you can install it manually or use an existing installation. If the server is already running locally before starting Krita, the plugin will automatically try to connect. Using a remote server is also possible this way.
Please check the list of required extensions and models to make sure your installation is compatible.
If you're looking for a way to easily select objects in the image, there is a separate plugin which adds AI segmentation tools.
Contributions are very welcome! Check the contributing guide to get started.
Live painting with regions (Click for video)

Inpainting on a photo using a realistic model

Reworking and adding content to an AI generated image

Adding detail and iteratively refining small parts of the image

Modifying the pose vector layer to control character stances (Click for video)

Control layers: Scribble, Line art, Depth map, Pose




- Image generation: Stable Diffusion, Flux
- Diffusion backend: ComfyUI
- Inpainting: ControlNet, IP-Adapter
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for krita-ai-diffusion
Similar Open Source Tools
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
MagicMirror
MagicMirror is an AI-powered tool that allows users to instantly try on new faces, hairstyles, and outfits with a simple drag and drop interface. It runs smoothly on standard computers without the need for dedicated GPU hardware, ensuring privacy with completely offline processing. The tool is ultra-lightweight with a small installer size and model files, providing a fun and easy way to experiment with different looks.
AiTextDetectionBypass
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
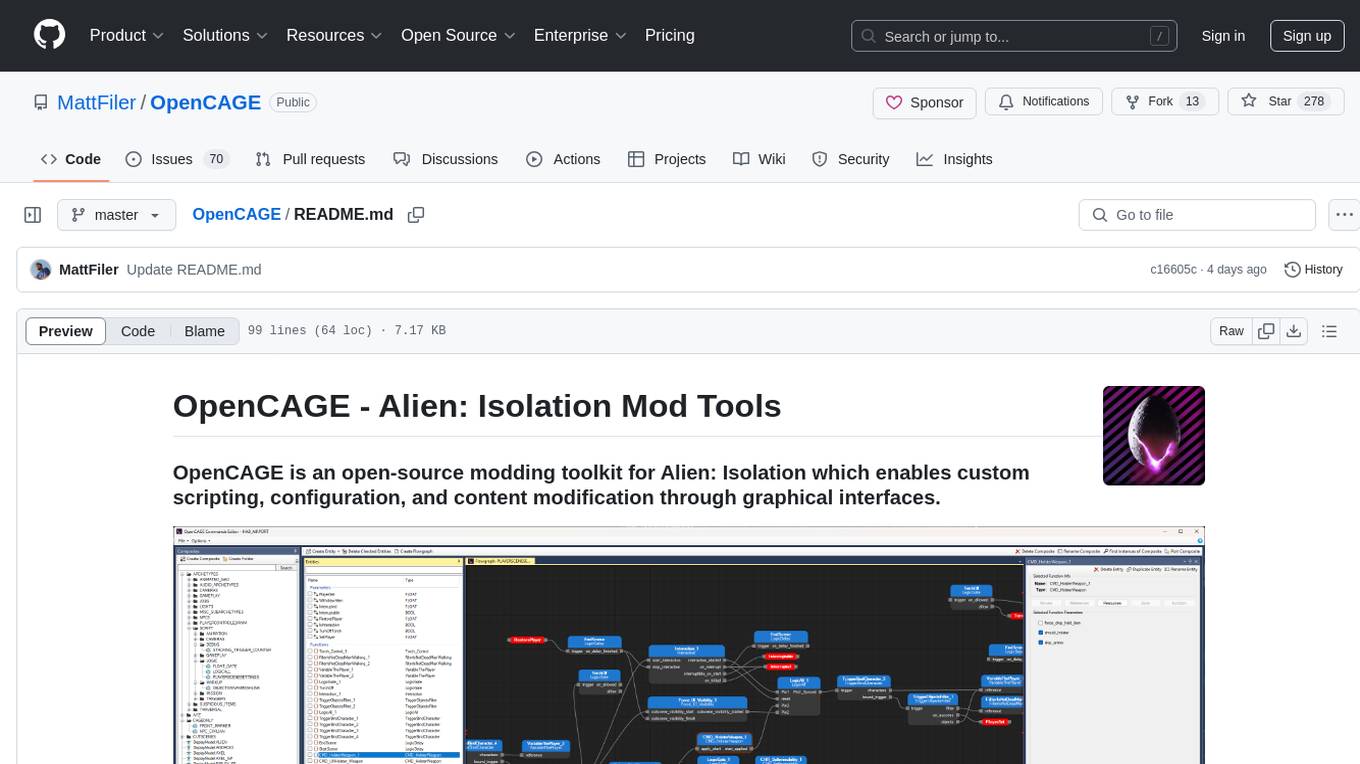
OpenCAGE
OpenCAGE is an open-source modding toolkit for Alien: Isolation, enabling custom scripting, configuration, and content modification through graphical interfaces. It includes tools for editing assets, configurations, scripts, behaviour trees, launching the game, and managing backups. The project is constantly evolving with a roadmap that includes features like contextual script editing, content porter, new level creator, mod installers, 3D viewer improvements, navmesh generation, skinned meshes support, sound import/export, and more. OpenCAGE is supported financially by the community and welcomes code contributions.

flow-like
Flow-Like is an enterprise-grade workflow operating system built upon Rust for uncompromising performance, efficiency, and code safety. It offers a modular frontend for apps, a rich set of events, a node catalog, a powerful no-code workflow IDE, and tools to manage teams, templates, and projects within organizations. With typed workflows, users can create complex, large-scale workflows with clear data origins, transformations, and contracts. Flow-Like is designed to automate any process through seamless integration of LLM, ML-based, and deterministic decision-making instances.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.
peridyno
PeriDyno is a CUDA-based, highly parallel physics engine targeted at providing real-time simulation of physical environments for intelligent agents. It is designed to be easy to use and integrate into existing projects, and it provides a wide range of features for simulating a variety of physical phenomena. PeriDyno is open source and available under the Apache 2.0 license.

pyqt-openai
VividNode is a cross-platform AI desktop chatbot application for LLM such as GPT, Claude, Gemini, Llama chatbot interaction and image generation. It offers customizable features, local chat history, and enhanced performance without requiring a browser. The application is powered by GPT4Free and allows users to interact with chatbots and generate images seamlessly. VividNode supports Windows, Mac, and Linux, securely stores chat history locally, and provides features like chat interface customization, image generation, focus and accessibility modes, and extensive customization options with keyboard shortcuts for efficient operations.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.
img-prompt
IMGPrompt is an AI prompt editor tailored for image and video generation tools like Stable Diffusion, Midjourney, DALL·E, FLUX, and Sora. It offers a clean interface for viewing and combining prompts with translations in multiple languages. The tool includes features like smart recommendations, translation, random color generation, prompt tagging, interactive editing, categorized tag display, character count, and localization. Users can enhance their creative workflow by simplifying prompt creation and boosting efficiency.
agent-zero
Agent Zero is a personal and organic AI framework designed to be dynamic, organically growing, and learning as you use it. It is fully transparent, readable, comprehensible, customizable, and interactive. The framework uses the computer as a tool to accomplish tasks, with no single-purpose tools pre-programmed. It emphasizes multi-agent cooperation, complete customization, and extensibility. Communication is key in this framework, allowing users to give proper system prompts and instructions to achieve desired outcomes. Agent Zero is capable of dangerous actions and should be run in an isolated environment. The framework is prompt-based, highly customizable, and requires a specific environment to run effectively.
BloxAI
Blox AI is a platform that allows users to effortlessly create flowcharts and diagrams, collaborate with teams, and receive explanations from the Google Gemini model. It offers rich text editing, versatile visualizations, secure workspaces, and limited files allotment. Users can install it as an app and use it for wireframes, mind maps, and algorithms. The platform is built using Next.Js, Typescript, ShadCN UI, TailwindCSS, Convex, Kinde, EditorJS, and Excalidraw.
Conversation-Knowledge-Mining-Solution-Accelerator
The Conversation Knowledge Mining Solution Accelerator enables customers to leverage intelligence to uncover insights, relationships, and patterns from conversational data. It empowers users to gain valuable knowledge and drive targeted business impact by utilizing Azure AI Foundry, Azure OpenAI, Microsoft Fabric, and Azure Search for topic modeling, key phrase extraction, speech-to-text transcription, and interactive chat experiences.
AI-Office-Translator
AI-Office-Translator is a free, fully localized, user-friendly translation tool that helps you translate Office files (Word, PowerPoint, and Excel) between different languages. It supports .docx, .pptx, and .xlsx files and allows translation between English, Chinese, and Japanese. Users can run the tool after installing CUDA, downloading Ollama dependencies and models, setting up a virtual environment (optional), and installing requirements. The tool provides a UI where users can select languages, models, upload files for translation, start translation, and download translated files. It also supports an online mode with API key integration. The software is open-source under GPL-3.0 license and only provides AI translation services, with users expected to engage in legal translation activities.

ClicShopping_V3
ClicShoppingAI is a powerful open-source Ecommerce solution that supports B2B, B2C, and B2B-B2C. Integrated with cutting-edge generative artificial intelligence systems like Gpt and Ollama, it helps merchants increase turnover and competitiveness for free. With AI capabilities, it optimizes inventory, offers personalized recommendations, and provides top-notch customer service. The solution is modular, lightweight, and user-friendly, with a seamless, responsive design for all devices. Installation is easy, empowering ongoing development through community support. Features include GPT API integration, generative AI functionalities, real-time safety stock predictive, WYSIWYG product description creation, image editor management, full SEO optimization, payment and shipping modules, extension system, GDPR compliance, multi-language support, and more.
For similar tasks

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
For similar jobs
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.
ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.